从文本中进行关系抽取的几种不同的方法
作者:Andreas Herman
编译:ronghuaiyang
导读: 信息抽取是 NLP 中非常重要的内容,而关系的抽取在知识图谱等领域应用广泛,也是非常基础的 NLP 任务,今天给大家介绍一下。

关系提取是指从文本中提取语义关系,这种语义关系通常发生在两个或多个实体之间。这些关系可以是不同类型的。" Paris is in France “表示巴黎与法国之间的” is in “关系。这可以用三元组(Paris, is in, France)来表示。
信息抽取(Information Extraction, IE)是从自然语言文本中抽取结构化信息的领域。该领域用于各种 NLP 任务,如创建知识图、问答系统、文本摘要等。关系抽取本身就是 IE 的一个子域。
关系提取有五种不同的方法:
- 基于规则的关系提取
- 弱监督关系提取
- 监督关系提取
- 模糊监督关系提取
- 无监督的关系提取
我们将在一个较高的层次上讨论所有这些问题,并讨论每个问题的优缺点。
基于规则的关系提取
许多实体的关系可以通过手工模式的方式来提取,寻找三元组(X,α,Y),X 是实体,α是实体之间的单词。比如,“Paris is in France”的例子中,α=“is”。这可以用正则表达式来提取。

句子中的命名实体
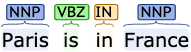
句子中的词性标记
仅查看关键字匹配也会检索出许多假阳性。我们可以通过对命名实体进行过滤,只检索(CITY、is in、COUNTRY)来缓解这种情况。我们还可以考虑词性(POS)标记来删除额外的假阳性。
这些是使用 word sequence patterns 的例子,因为规则指定了一个遵循文本顺序的模式。不幸的是,这些类型的规则对于较长范围的模式和具有更大多样性的序列来说是不适用的。例如:“Fred and Mary got married”就不能用单词序列模式来成功地处理。
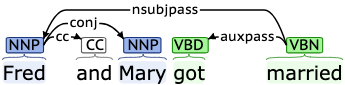
句子中的依赖路径
相反,我们可以利用句子中的从属路径,知道哪个词在语法上依赖于另一个词。这可以极大地增加规则的覆盖率,而不需要额外的努力。
我们也可以在应用规则之前对句子进行转换。例如:“The cake was baked by Harry”或者“The cake which Harry baked”可以转化成“Harry bake The cake”。然后我们改变顺序来使用我们的“线性规则”,同时去掉中间多余的修饰词。
优点
- 人类可以创造出具有高准确率的模式
- 可以为特定的领域定制
缺点
- 人类模式的召回率仍然很低(语言种类太多)
- 需要大量的人工工作来创建所有可能的规则
- 必须为每个关系类型创建规则
弱监督的关系提取
这里的思想是从一组手工编写的规则开始,通过迭代的方式从未标记的文本数据中自动找到新的规则。或者,你可以从一个种子元组开始,用特定的关系描述实体。例如,seed={(ORG:IBM, LOC:Armonk), (ORG:Microsoft, LOC:Redmond)}表示具有“based in”关系的实体。
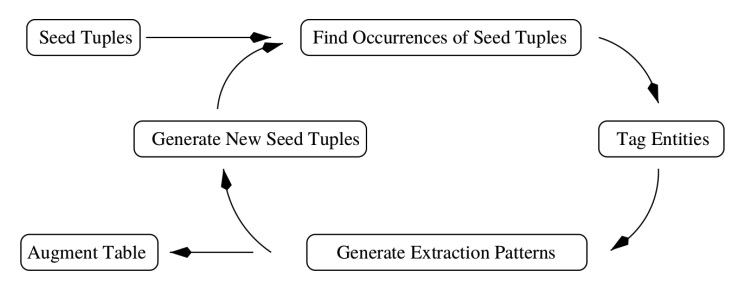
Snowball 是一个相当古老的算法示例,它可以实现以下功能:
- 从一组种子元组开始(或使用一些手工规则从未标记的文本中提取一组种子)。
- 从未标记的文本中提取和元组匹配的共现词,并用 NER(命名实体识别器)标记它们。
- 为这些事件创建模式,例如“ORG is based in LOC”。
- 从文本中生成新的元组,例如(ORG:Intel, LOC: Santa Clara),并添加到种子集中。
- 执行步骤 2 或终止并使用创建的模式进行进一步提取
优点
- 可以发现比基于规则的关系提取更多的关系(更高的召回率)
- 更少的人力投入(只需要高质量的种子)
缺点
- 随着每次迭代,模式的集合更容易出错
- 在通过元组共现生成新模式时必须小心,例如“IBM shut down an office in Hursley”可能被错误的认为是“based in”关系。
- 新的关系类型需要新的种子(必须手动提供)
有监督的关系提取
进行监督关系提取的一种常见方法是训练一个层叠的二分类器(或常规的二分类器)来确定两个实体之间是否存在特定的关系。这些分类器将文本的相关特征作为输入,从而要求文本首先由其他 NLP 模型进行标注。典型的特征有:上下文单词、词性标注、实体间的依赖路径、NER 标注、tokens、单词间的接近距离等。
我们可以通过下面的方式训练和提取:
- 根据句子是否与特定关系类型相关或不相关来手动标注文本数据。例如“CEO”关系:“Apple CEO Steve Jobs said to Bill Gates.” 是相关的,“Bob, Pie Enthusiast, said to Bill Gates.”是不相关的。
- 如果相关句子表达了这种关系,就对正样本/负样本进行手工的标注。“Apple CEO Steve Jobs said to Bill Gates.”:(Steve Jobs, CEO, Apple) 是正样本,(Bill Gates, CEO, Apple)是负样本。
- 学习一个二分类器来确定句子是否与关系类型相关
- 在相关的句子上学习一个二分类器,判断句子是否表达了关系
- 使用分类器检测新文本数据中的关系。
有些人选择不训练“相关分类器”,而是让一个单一的二分类器一次性确定这两件事。
优点
- 高质量的监督信号(确保所提取的关系是相关的)
- 我们有明确的负样本
缺点
- 标注样本很贵
- 增加新的关系又贵又难(需要训练一个新的分类器)
- 对于新的领域不能很好的泛化
- 只对一小部分相关类型可用
模糊监督的关系提取
我们可以将使用种子数据(比如弱监督的 RE)和训练分类器(比如有监督的 RE)的思想结合起来。但是,我们可以从现有的知识库(KB),比如 Wikipedia、DBpedia、Wikidata、Freebase、Yago 中得到种子,而不是自己提供一组种子元组。
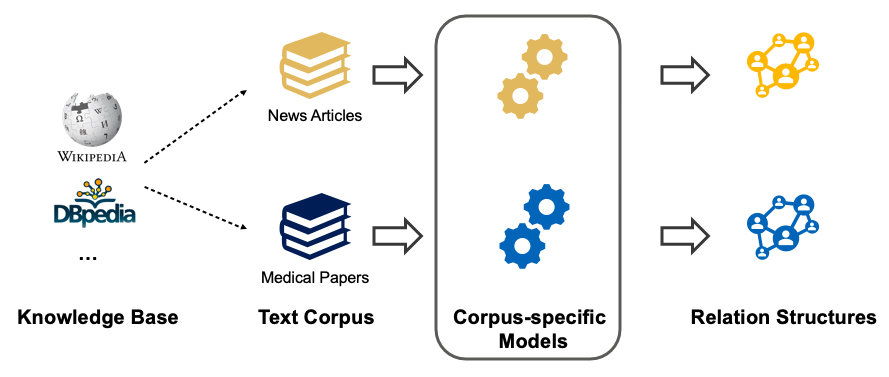
模糊监督的关系抽取方法:
- 对于知识库中我们感兴趣的每个关系类型进行循环
- 对于知识库中该关系的每个元组进行循环
- 从我们的未标记文本数据中选择可以匹配到这些元组的句子(元组的两个单词在句子中是共现的),并假设这些句子是这种关系类型的正样本
- 从这些句子中提取特征(如词性、上下文词等)
- 训练一个有监督的分类器
优点
- 更少的人力
- 可以扩展使用大量的标注数据和大量的关系
- 不需要迭代(相比于弱监督关系抽取)
缺点
- 训练语料库的标注噪声(句子中同时具有这两个单词可能并没有描述这种关系)
- 没有明显的负样本(可以通过匹配没有关系的实体来解决)
- 受限于知识库
- 需要在任务上进行非常仔细的调试
无监督的关系提取
在这里,我们从文本中提取关系,而不需要标注任何训练数据、提供一组种子元组或编写规则来捕获文本中不同类型的关系。相反,我们依赖于一组非常普遍的约束和启发。这算不算是无监督的,是有点争议的,因为我们使用的“规则”是在一个更普遍的层面上。此外,在某些情况下,甚至可以利用小的标注文本数据集来设计和调整系统。然而,这些系统一般需要较少的监督。开放信息提取(Open Information Extraction, Open IE)通常指的是这种范式。
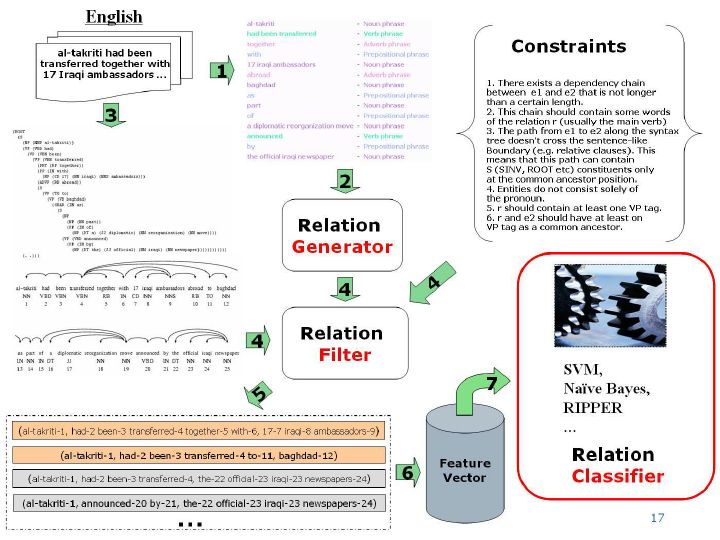
TextRunner 是属于这类关系提取方案的一种算法。其算法可以描述为:
**1. 在一个小语料库上训练一个自监督分类�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BB%8E%E6%96%87%E6%9C%AC%E4%B8%AD%E8%BF%9B%E8%A1%8C%E5%85%B3%E7%B3%BB%E6%8A%BD%E5%8F%96%E7%9A%84%E5%87%A0%E7%A7%8D%E4%B8%8D%E5%90%8C%E7%9A%84%E6%96%B9%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


