半监督深度学习小结类协同训练和一致性正则化
作者丨陈家铭
学校丨中山大学硕士生
研究方向丨半监督深度图像分类
本文来源: PaperWeekly
协同训练 Co-training
Co-training 是基于分歧的方法,其假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。
由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
该方法虽然理论很强,但却有一定的假设条件(事实上半监督学习都是在一定的假设条件下进行的),引用周志华大大《基于分歧的半监督学习》中的描述:
协同训练法要求数据具有两个充分冗余且满足条件独立性的视图:
1. “充分(Sufficient)” 是指每个视图都包含足够产生最优学习器的信息, 此时对其中任一视图来说,另一个视图则是“冗余(Redundant)” 的;
2. 对类别标记来说这两个视图条件独立。
这个数据假设就很强力了,既要求数据信息充分还冗余,你还要找到两个独立互补的视图。但是,在一定程度上满足条件的情况下,co-training 的效果也是非常给力。
那么,在半监督深度学习里,co-training 会以什么方式呈现呢?问题的关键自然在于,如何去构建两个(或多个) 近似 代表充分独立的视图的深度模型,两个比较直观的方法就是:
-
使用不同的网络架构(据我看过的论文 [1] [2] 中指出,哪怕是对同一个数据集,不同的网络架构学习到的预测分布是不一样的);
-
使用特殊的训练方法来得到多样化的深度模型。
注:以下工作的推荐,是我自认为其思想类似于 co-training,因此称为类协同训练,不是说下面的工作就一定是 co-training。


这是一篇 ECCV 2018 的文章,论文首先指出, 直接对同一个数据集训练两个网络,会有两个弊端:
-
对同一个数据集训练两个网络,并不能保证两个网络具有不同的视图,更不能保证具有不同且互补的信息;
-
协同训练会使得两个网络在训练过程中趋于一致,会导致 collapsed neural networks,进而使得协同训练失效。
为了解决上述问题,论文主要做了两个工作:
1. 提出了一个新的代价函数,进行协同训练,其形式如下:
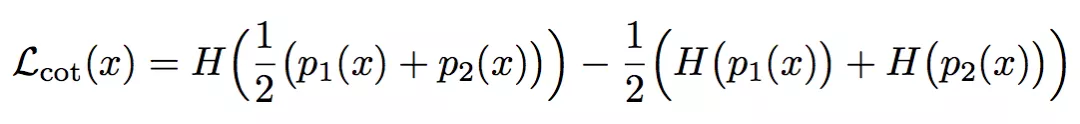
信息论学得不好请多见谅,大概就是均匀分布的熵最大,当两个预测分布不一致时,这两个预测分布求和取平均会使得熵增大。相反,如果预测一致熵就不会增加多少。
论文中还明确强调,该代价函数只用在无标签数据上,因为有标签数据的监督代价函数(论文用的交叉熵)已经使得预测趋于一致(趋于真实标签),用在有标签数据上没有必要,但是好像没说明也用在有标签数据上的后果。
2. (关键)提出了 View Difference Constraint。其思路是:我们只有一个数据集 D,但我们不能再同一个数据集上训练两个网络,因此需要从 D 中派生出另一个数据集 D’,而这个派生方法就是计算 D 的对抗样本。具体即使用对方的对抗样本来训练自己:
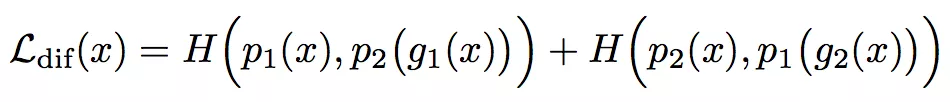
其中, g1(x) 表示网络 p1 的对抗样本, H(·) 是某种代价函数(KL 散度),该约束的设计期望是使得两个网络具备不同却互补信息。我个人觉得这是一个 very amazing 的想法。尽管我不知道理论上是否能保证两个网络不同却互补,但直观上……
实验效果非常好,两个(或多个)网络使用的是同一种架构,就是感觉没有和集成方法比较感觉有点遗憾,毕竟论文用了多个网络。


Tri-net 是 IJCAI 2018 的论文,挂着周志华大大的名字,用的思想也是周志华提出来的 tri-training,可谓阵容豪华。
论文称类协同训练为 disagreement-based semi-supervised learning,其关键在于训练多个分类器,已经对不同视图上的不一致性的探索。为此,论文从三个方面改进:model initialization,diversity augmentation 和 pseudo-label editing。
在展开这三个贡献点之前,我们先来看看 Tri-net 的网络架构:
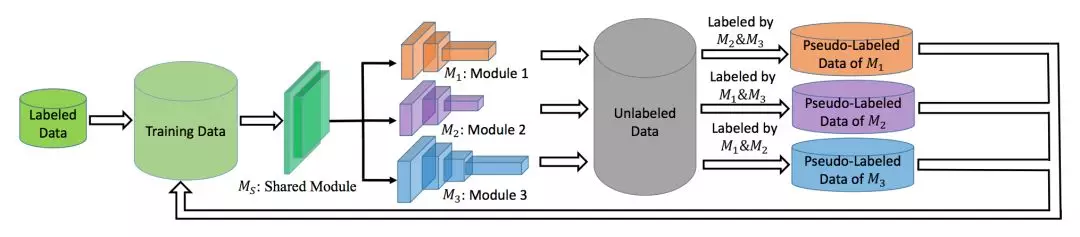
按照把网络架构分为低层抽象和高层抽象部分,Tri-net 架构中的 Ms 是一个共享的低层抽象部分,而 Tri-net 的高层抽象部分是用三个不同的网络架构组成。
刚开始我看到这个架构时,一脸懵逼,但后来想想,这样设计也有一定道理。
首先,根据我了解的迁移学习理论,低层抽象部分确实是可以共用,用预训练模型进行迁移学习时,低层抽象部分是建议使用很小的学习率或者不学习的。
其次,不同的高层部分对低层抽象还是有一定程度不同的影响,作为共享低层部分,能学习到满足不同高层部分的低层抽象,即更具泛化性的低层抽象(当然这是我猜的)。
然后其训练过程主要分为两部分:
1. 使用 Output Smearing 处理的有标签数据初始化网络,可以使不同的高层抽象具有不同的预测分布;
2. Tri-training 网络:如果有两个高层抽象对一个样本具有一致预测,且该预测可信且稳定,则把该样本作为加入到第三个高层抽象的训练数据中。同时,为了防止 collapsed neural networks 问题(Deep Co-Training 提到),还会在某些 epoch 中继续使用 Output Smearing 训练网络,以增加不同高层抽象的 diversity。
**现在来看看论文的三个贡献点: **
**1. Output Smearing:**同上文的 Deep Co-Training 的论文一样,该论文也认为不能直接在同一个数据集 D 上直接训练网络,Output Smearing 通过向有标签数据的添加随机噪声来构造不同的数据集 D1,D2,D3,分别用来初始化对应的高层抽象部分 M1,M2,M3,这样就能使用高层抽象部分多样化(即代表不同视图)。
**2. Diversity Augmentation:**为了解决 collapsed neural networks 问题,在特定的 epoch 继续使用 output smearing 数据集来 fine-tune 网络,以继续增强多样化;
**3. Pseudo-Label Editing:**Tri-training 训练时, 需要挑选可靠且稳定的无标签样本加入训练集,如何确定预测的样本是可靠且稳定?
本身 Tri-training 这种类协同训练挑选的样本就具有很强的可靠,论文提出一个的方法 Pseudo-label editing:通过 Dropout 的随机性,对样本进行多次预测,如果多次预测的结果都几乎一样,则认为是稳定的。
模型的缺点也相对明显,训练过程相对复杂,感觉靠经验设计;Pseudo-label editing 需要进行多次预测,估计计算负担也挺重的。


这篇 ECCV 2018 的论文是做人脸识别的,主要提出了一个 Consensus-driven propagation 的算法,该算法主要由三部分:Committee,Mediator 和 Pseudo Label Propagation 组成。
**1. Commitee:**需要用有标签数据训练一个 base model 和 N 个 committee models,而且这些 models 都需要使用不同的网络架构,以保证 diversity (信息的多样性)。然后使用这些 models 提取深度特征,构建 KNN 图,并进一步获取三种信息:
**Relationship:**0-1 邻接图,若两个节点在所有的 committee models 的 KNN图中都邻接,则为 1(为什么要排除 base model?)。
**Affinity:**节点间的相似性信息,论文用余弦相似度。
**Local structures w.r.t each node:**一个节点与其他所有节点的相似性信息,论文用余弦相似度。
**2. Mediator:**一个全连接网络,用来融合上面的多视图信息,来判断正的样本对,和负的样本对。
**3. Pseudo Label Propagation:**一个对无标签数据赋 pseudo label 的算法,通过 mediator 给出的正样本对的概率作为相似度量,貌似通过一种类似聚类的方法,给样本赋 pseudo label。
论文里面提到的一些概念和想法挺有意思,实验上也很充分,一定程度上佐证了我的一些思考。
小结
最后,我们来总结一下类协同训练在深度学习中应用的三个关键点:
**1. 怎么训练具有不同视图信息的分类器?**目前看到的方法有二:1)构建不同的数据集;2)使用不同的网络架构。看起来两种方法一起用效果会更好;
2. 如何解决 collapsed neural networks 问题,即如何保持分类器的 diversity,这问题非常重要。
**3. 如何训练“好”的无标签样本加入训练集?**虽然协同训练本身通过一致性原则选择的样本就具有一定的可靠性,但是否有很好的挑选方法?如稳定性。
最后的最后,再安利另一篇文章,是中大凌亮老师团队的 Deep Co-Space: Sample Mining Across Feature Transformation for Semi-Supervised Learning,利用样本间关系的时序差异,来挑选“好”的无标签样本。这想法非常赞,值得研读。
Consistency Regularization
说到一致(Consistency),其实很多代价都有这个内涵,如 MSE 代价,最小化预测与标签的差值,也就是希望预测与标签能够一致。其他的代价,如 KL 散度、交叉熵代价也类似。所以一致性,是一种非常内在而本质的目标,可以让深度网络进行有效学习。
但是在半监督中,无标签数据并没有标签,因而勤劳而美丽的科研工作者们就想出了各种无需标签信息的 Consistency Regularization,随着 Consistency Regularizaton 的不断发展,一度成为半监督深度学习发展史上耀眼的 SOTA。
**Consistency Regularization 的主要思想是:对于一个输入,即使受到微小干扰,其预测都应该是一致的。 **
例如,某人的裸照(干净的输入)和其有穿衣服的照片(受到干扰的照片),你也应该能知道这是同一个人(一致性)。 当然,这个干扰不能太大(例如衣服把整个人都遮住了)。
Consistency Regularization 虽然做法简单,但是却具有很多良好的作用,将会在下面的文章中阐述。


这是 NIPS 2014 年发表的工作,其提出了一个概念:pseudo-ensemble,一个 pseudo-ensemble 是一系列子模型(child model),这些子模型通过某种噪声过程(noise process)扰动父模型(parent model)得到。
Pseudo-ensemble 与其他的有关扰动的方法的区别在于:其他的方法只考虑在输入空间的扰动,而 pseudo-ensemble 还考虑在模型空间(model space)上的扰动。
一个典型的 pseudo-ensemble 就是 Dropout。 但是,除了dropout 以外,我没怎么想到其他的模型空间上的扰动,看论文的公式貌似是在网络的中间表示添加噪声?论文有代码,但我没怎么看,有不同意见的同学可以评论里提出。
其有监督代价函数如下:
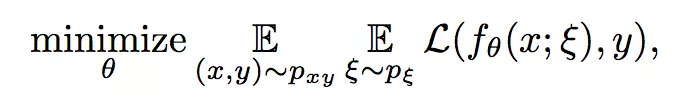
其中 θ 是网络参数,ξ 表示某种噪声过程,该有监督代价函数就是让扰动得到的子模型与标签 y 一致。
论文中还提出其半监督形式: The Pseudo-Ensemble Agreement regularizer (PEA),其形式如下:
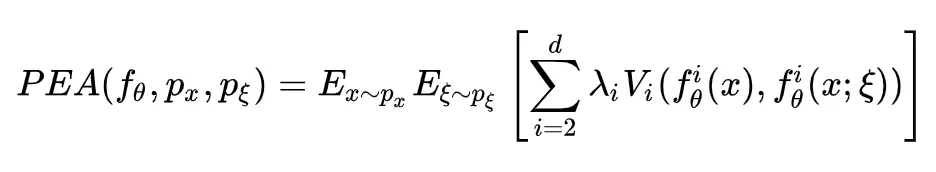
其中 d 是网络的层数,其含义应该是把父模型的每一层中间表示,与子模型的进行一致正则, V 是某种惩罚函数,如 MSE 代价(注:最后一层的中间表示即网络的预测)。
现在回顾一下 Consistency regularization 的思想:对于一个输入,受扰微小扰动后,其预测应该是一致的。
PEA 的含义我认为就是,对于一个输入,受到扰动后,其所有的中间表示,都应该一致。其实根据后面更多的论文,这个约束可能强力些。
PEA 的目的是,使得模型对扰动具有鲁棒性,因为鲁棒的模型泛化性能更好,同时还能学习数据的内在不变性( 作用 1)。


这是 NIPS 2016 年发表的工作。随机性在大部分的学习系统中起到重要的作用,深度学习系统也如此。一些随机技术,如随机数据增强、Dropout、随机最大池化等,可以使得使用 SGD 训练的分类器具有更好的泛化性和鲁棒性。
而且这种不确定性的存在,使得模型对同一个样本的多次预测结果可能不同。因此论文提出一个无监督代价(即我说的半监督正则),其通过最小化对同一个样本的多次预测,利用这种随机性来达到更好的泛化性能。该无监督代价形式如下:
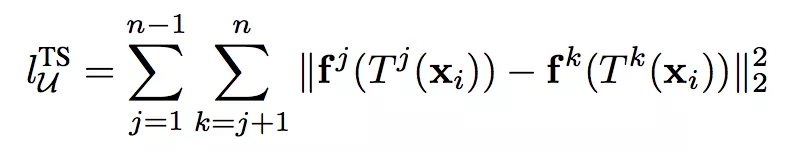
其中
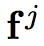 代表对输入
代表对输入
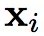 的第 j 次预测, T 表示某种数据变换。除了对样本做变换,在网络内也使用类似 Dropout 或随机池化等技术产生随机性。
的第 j 次预测, T 表示某种数据变换。除了对样本做变换,在网络内也使用类似 Dropout 或随机池化等技术产生随机性。
似泥?Pseudo-Ensemble!对不起,你俩有点像。
虽然感觉很类似,但是这两篇论文很值得一读啊,论文里提出许多的观点和想法,一直延续至今,信息量挺大。


这篇在 ICLR 2017 年的工作提出了一个我称之为 peer-consistency 的正则项,即 π 模型,也是我最开始对 Consistency Regularization 的认知的由来。
π 模型认为,同一个输入,在不同的正则和数据增强条件下,网络对其预测应该是一致的。其无监督代价部分如下:
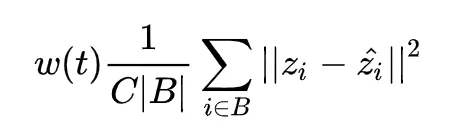
其中 zi 是网络的一个预测,而
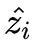 是网络对同一个样本在不同的正则和数据增强条件下的一个预测,然后让着两个预测一致。看起来很像前面两篇文章的简化版,但是效果好啊,这也是我说前面的约束太强的原因。
是网络对同一个样本在不同的正则和数据增强条件下的一个预测,然后让着两个预测一致。看起来很像前面两篇文章的简化版,但是效果好啊,这也是我说前面的约束太强的原因。
w(t) 是权重函数,是迭代次数的函数。由于在网络的初始阶段,网络的预测十分不准(尤其是半监督中有标签数据有限的情况),这时的网络预测靠不住的,因此这无监督代价在初始时的权重应该设置得比较小,到后期再慢慢增大。
w(t) 非常关键,论文中使用了一个高斯爬升函数,具体可以看论文。我的理解是,这种 peer-consistency 鼓励一个样本点的扰动不变性,其实鼓励了预测函数(即网络)对样本的邻域具有光滑性( 作用 2)。
而且把 peer-consistency 看做是一种标签正则,可以从最大熵模型来理解 peer-consistency,具体可参考 Regularizing Neural Networks by Penalizing Confident Output Distributions ,_** **_ICLR 17。
�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8D%8A%E7%9B%91%E7%9D%A3%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%B0%8F%E7%BB%93%E7%B1%BB%E5%8D%8F%E5%90%8C%E8%AE%AD%E7%BB%83%E5%92%8C%E4%B8%80%E8%87%B4%E6%80%A7%E6%AD%A3%E5%88%99%E5%8C%96/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


