同城多样性算法在部落的实践和思考

文章作者:刘发帅、周建斌 58同城
内容来源:公众号“58技术”
导读: 本文在明确“推荐系统个体多样性优化”主题后,由整体架构出发,清楚阐述了在召回层、规则层、多样性层的优化细节。在MMR和DPP算法部分既有原理也有实践,最后用图表方式展示出了效果对比,并且结合自身业务特点做了针对性的距离设计。
01 背景
在推荐系统中,衡量系统好坏的指标,除了相关性之外,多样性也是重要的指标之一。但多样性和相关性之间往往存在一些矛盾的地方,本文从业务指标的角度,探讨了多样性和相关性之间如何权衡的思想方法,介绍了多样性算法的落地实践方案,最终达到了通过多样性手段提升业务指标的目的。
1. 多样性算法的意义和难点
推荐系统中,准确度一直是衡量系统好坏最重要的指标,大多数的工作都是在研究如何提高准确度。然而,推荐结果的质量是通过多个维度来衡量的,越来越多研究表明,仅依赖准确度的推荐已经不能对用户的体验和满意度有所提升,反而容易促进信息茧房的产生。于是,如何在准确性和多样性之间进行权衡和协同优化,从而提高业务的整体数据指标成为了现在推荐系统的又一个优化方向。
在实践中,我们总结了多样性算法落地的几个难点:
① 模型的优化目标模糊
众所周知,各种用户行为(点击、转化、停留、分享等等)都可以作为优化准确度的目标,我们可以明确的收集用户的行为作为模型的目标标签,从而设计模型并优化。因为多样性本身是一个集合统计量,很难找到直接的用户行为来作为模型优化的目标。
② 业务指标和多样性指标的冲突
业务关注的指标(转化率、停留时长等)和多样性指标并不是简单的正向或者负向的关系。如果单纯为了提高多样性指标而做多样性,反而会导致最终结果与业务目标偏离,使推荐的质量下降。
综上所述,我们在58部落推荐系统的多样性实践中,排除了单纯使用多样性指标作为评估算法好坏的方法。结合部落的业务特点,我们定下了这样的目标:把多样性作为一个提高业务指标的手段,通过多个业务指标和多样性指标来综合评估算法的效果,最终达到两种指标共同提升,进而提高用户体验的目的。
02 58部落的多样性算法实践
在多样性算法的研究中,通常把多样性分成两种:
- 基于个体用户的多样性,旨在避免给单一用户推荐相似的物品,从而提高用户体验和增加用户满意度
- 基于全部用户的多样性,旨在优化长尾的物品分发效果
因为我们现阶段的主要目标是针对个体用户体验,所以选择了基于个体用户的多样性作为实践方向。
1. 推荐系统架构图
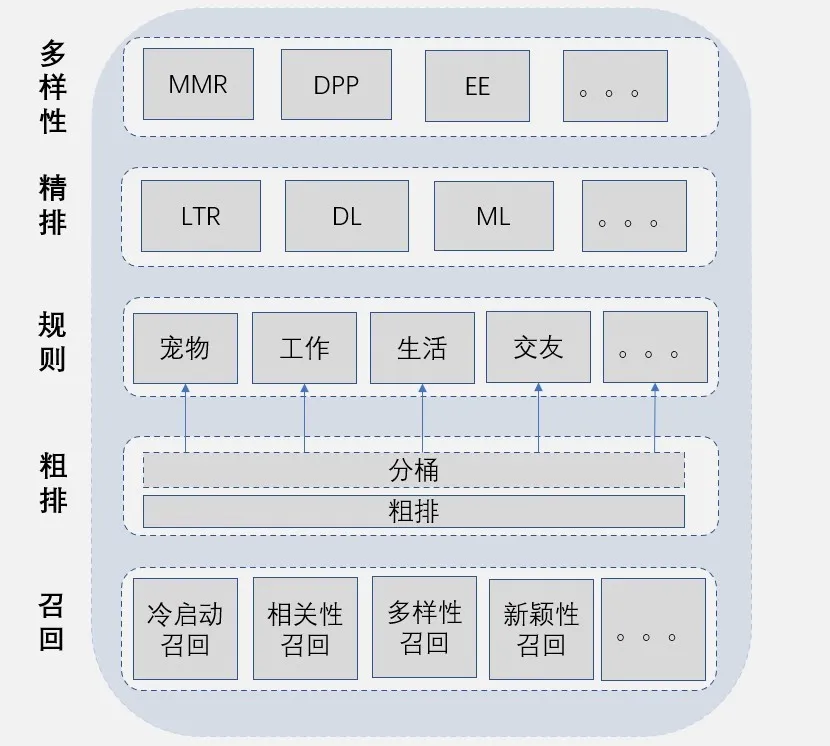
推荐系统在线分层架构图
为了保证推荐数据的多元化,我们在三个地方进行了优化:
**① ****召回层:**从数据源提供多样性的候选集合,通过提高粗排候选池中主题、类别和作者的覆盖度来保证数据源的多样化;
**② 规则层:**在相关性损失不大的情况下,通过提高精排候选池中主题和类别的覆盖度来保证进入精排数据的多样化;
**③ 多样性层:**对数据统一做多样化处理,保证数据输出多样化。
数据决定了效果的上限,而算法只是逼近这个上限。在多样性层,只是尽可能保证了精排后的数据多样性,由于结果受精排候选池数据多样性的影响,所以如果能在召回层数据源保持候选集合的多样性,效果会更好。
2. 数据源多样化
①召回层多样化的实现
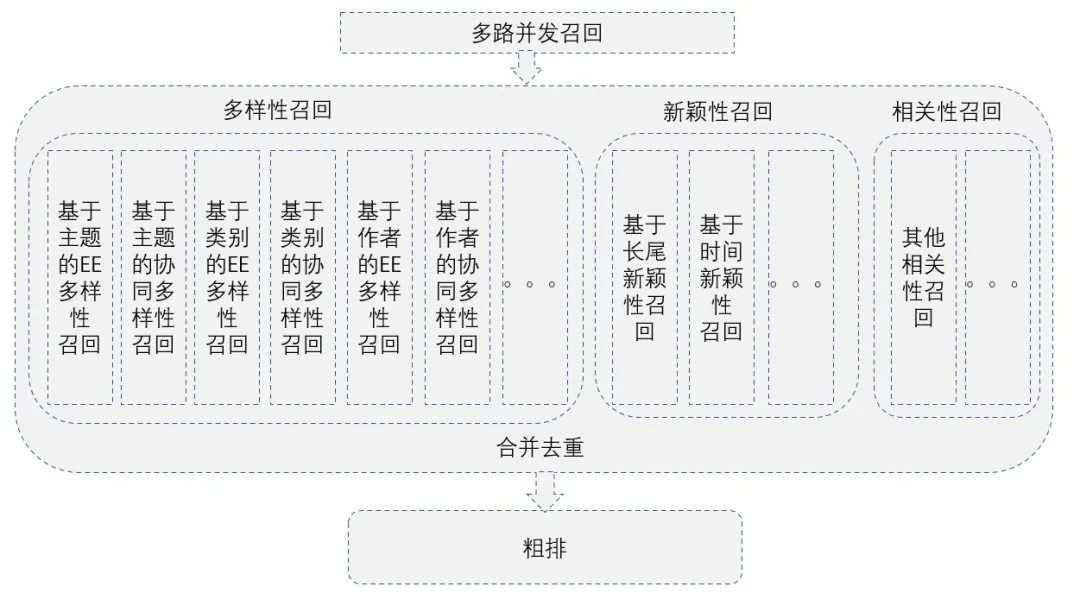
召回层架构图
在召回阶段,我们采用的是多路召回。为了保证数据多样性,通过增加若干多样性的召回策略来丰富数据源,例如:
- 通过多样性算法,获取用户个性化和多样化的主题、类别、作者进行召回,以保证召回兼顾多样性和相关性;
- 通过一些长尾、时间、惊喜的召回分路,来增加数据新颖性和多样性;
- 通过一些基于关系、属性的协同召回分路,提高数据多样性。
- 通过增加多样性和新颖性召回,粗排候选池中的数据基于主题的覆盖度提高了120%左右,基于类别覆盖度提高了100%左右。
② 规则层多样化的实现
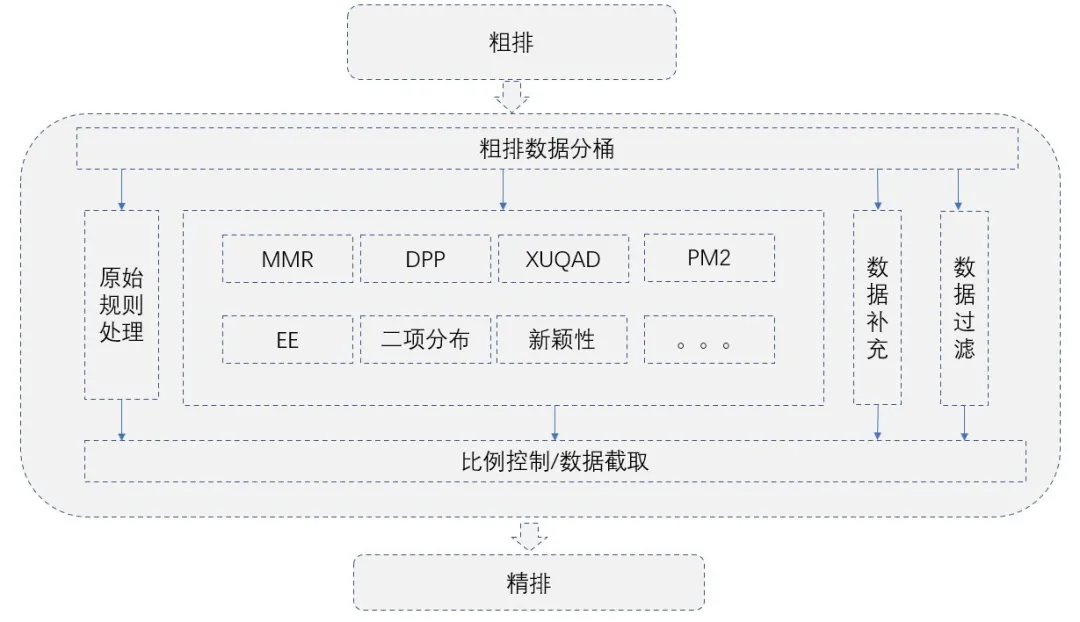
规则层架构图
我们推荐的数据是多种异构类型的实体,因此进入精排前(规则层)会对类型进行分桶处理。每种类型从粗排到精排都要经过一个数据截取阶段,主要截取指标一般是粗排的相关性分数。为了防止截断操作破坏召回层对数据源所做的多样性优化,我们通过对该类型的粗排结果先按照类别进行分桶,然后在做多样性控制。最后对各种类型进行比例调整、数据补充以及一些必要的过滤。在相关性影响不大的情况下提高精排数据的多样性。
因为规则层多样性算法是按照类型分桶,因此不受多种异构类型的实体混排的影响,适合于各种多样性算法。
规则层添加多样性算法干预之后,精排候选池中的数据基于主题的覆盖度提高了80%左右,基于类别覆盖度提高了70%左右。
规则层加入多样性后的线上ctr和uvctr转化效果,如下图:
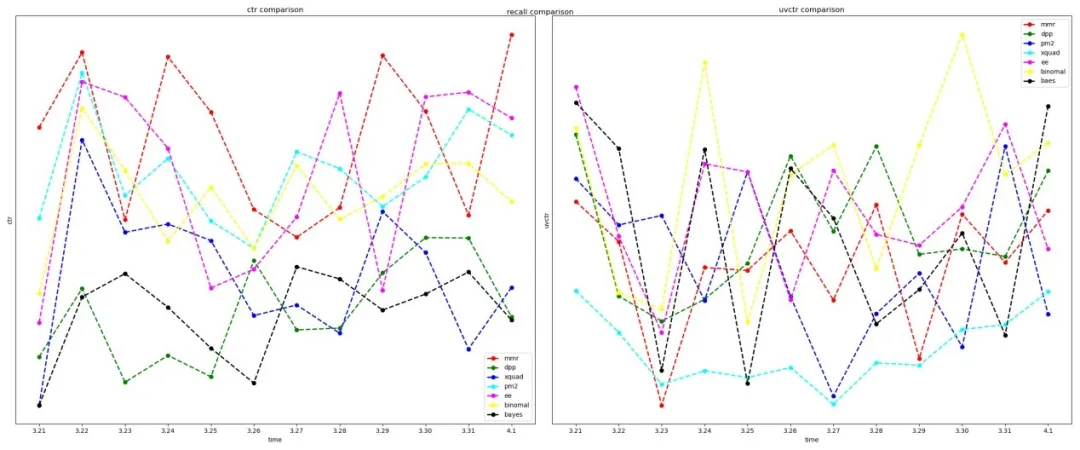
规则层算法效果对比
从上图可以看出,就而言,各个算法差异度并不是很大,和表现略好。就而言,算法表现稍微好一点。规则层主要是通过多样性算法替换之前的启发式规则,使据源多样性自动化。
3. 基于重排序方法的多样层
算法调参,我们主要参考三个业务指标:
- pvctr表示pv点击率
- uvctr表示uv点击率
- avgpv表示人均展示数
对于多样性算法应用的场景,在规则层单类型上使用了常用的多样性算法:binomal、EE、DPP、XQUAD、PM2、Bayes、MMR,在多样性层多种异构类型的实体上常用算法并不是合适,因为58部落物品类型多样而且异构,很难用单一的向量生成方法把异构物品放在一个稠密空间度量,而且不同类型的实体兴趣分布重叠度并不是很高,所以我们使用了基于自定义距离的MMR,DPP算法以及不是基于距离的EE算法。
①多样性架构图
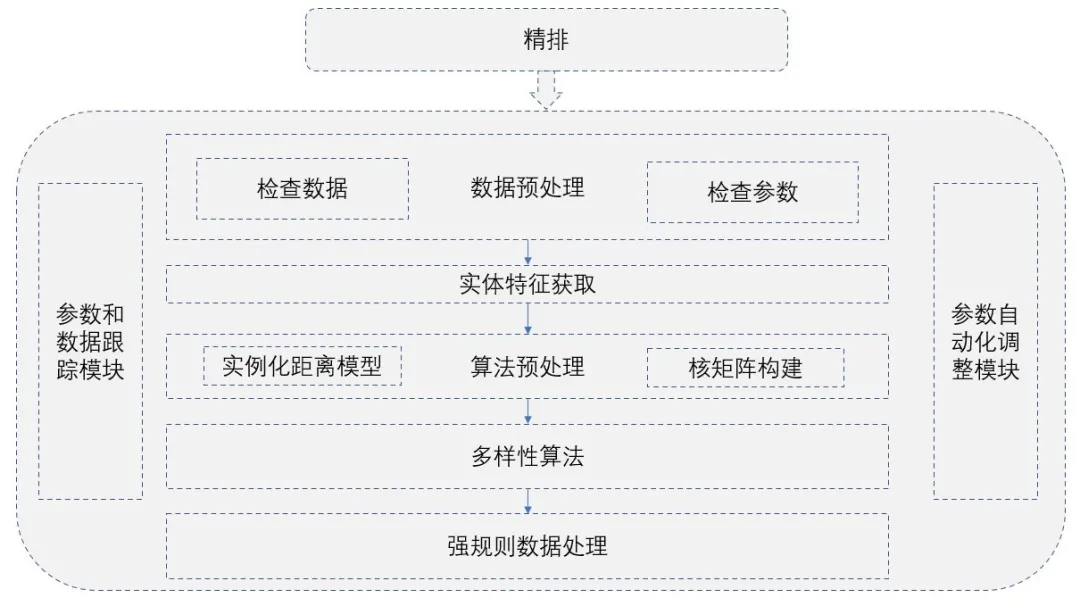
多样性层架构图
限于篇幅、业务结合的重要性、时效性等原因,下面重点介绍MMR和DPP这两种算法在工程实践中的应用。
② MMR的原理
MMR 的原理的全称为MaximalMarginal Relevance,是一种以减少冗余、保证相关的贪心排序算法。在推荐场景体现在,给用户推荐相关商品的同时,保证推荐结果的多样性。公式:
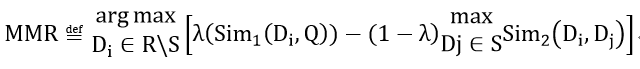
S是已经选择的文档有序集合,一般是相关性排序结果;
R表示下一个候选文档;
D_i表示下一个候选文档;
D_j表示S中的文档;
sim函数:是相似度度量函数,例如相似度;
- λ(Sim_1(D_i,Q))表示候选文档与查询文档的相关性;
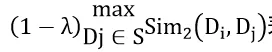 表示该文档与已有文档的相似性最大值;
表示该文档与已有文档的相似性最大值;
权重系数,调节推荐结果相关性与多样性。
作为一种贪婪算法,同样是每次计算出公式中最大值,放入有序结果集,同时从候选集中删除选中的物品,然后更新参数,进而进行下一轮继续选择,直到结果集中数据量满足需要或者没有数据可选择为止。
实现流程:
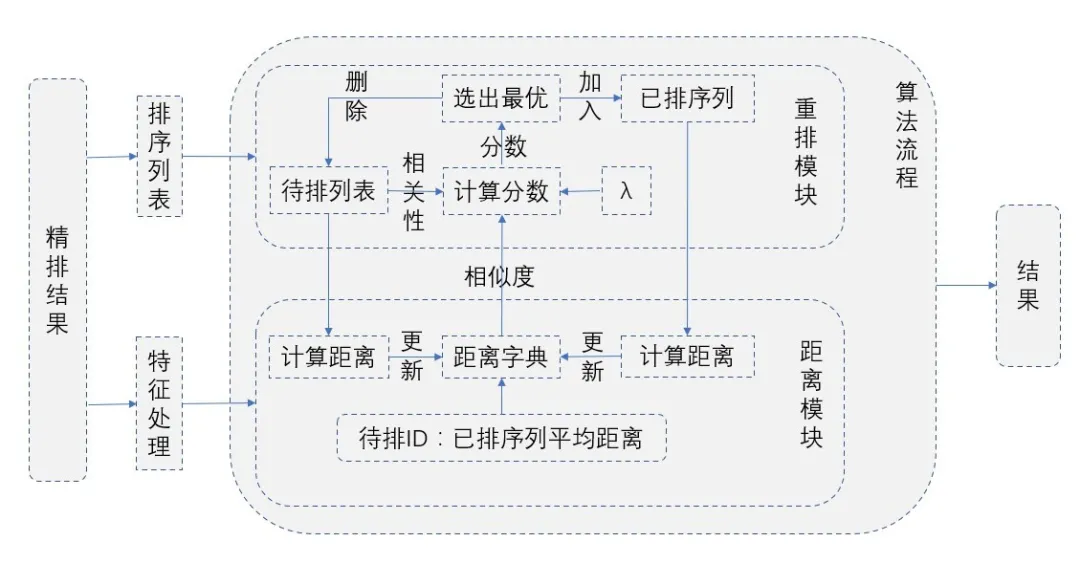
MMR算法流程图
实验效果:
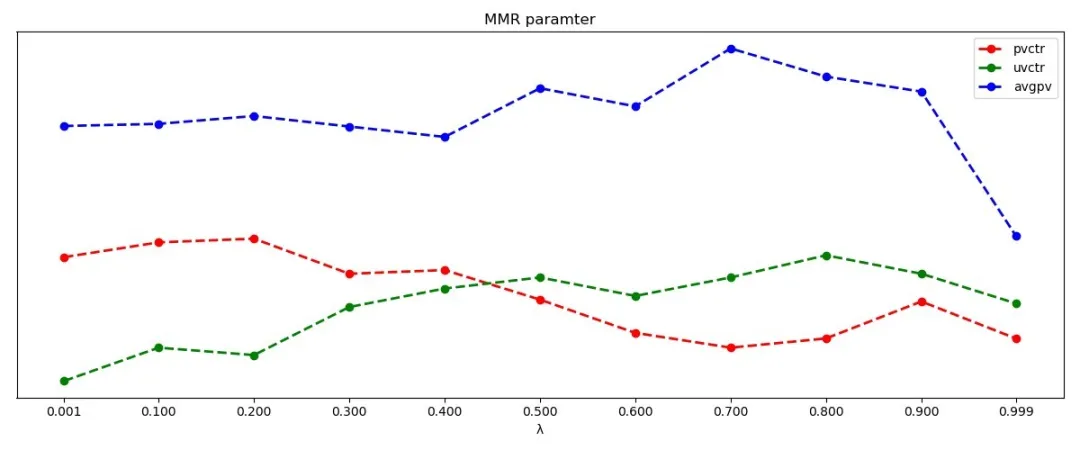
MMR参数效果对照图
我们工程实现上为了算法流程统一,把原始论文中的公式里面的和调换了一下位置,为了保证几个指标在同一张图中对比,图中把和进行一定程度的放大和缩小。从图上可以看出,逐渐调整多样性参数, 逐渐降低,在的时候达到最高点,因为越小,结果越偏向于相关性。和人均浏览数稳定提高,说明随着多样性的增加会吸引一些人产生点击行为,并且会使得他们浏览更多的内容,并且在的时候效果最好,在的时候达到最高点。
工程实现问题:
距离计算的时候,我们的实现是当前文档与已选文档之间的平均距离,来避免使用最大距离而导致推荐结果中后续加入的文档之间有高的相似性。
物品之间相似度函数的定义,可以根据论文里提到的用相似度。但是这样就要求候选列表之间必须要有一个统一的物品向量,以保证该向量是anything-to-anything。因为推荐结果有多种类型,并且是异构的,这种情况下相似度并没有很好的可解释性。我们的做法是使用和业务结合的自定义距离,下文会详细介绍自定义距离。
③ DPP的原理
全称determinantal point process,是在一个离散的点集的幂集上定义的概率分布。是随机采样得到的一个子集,对于任意,有
p(A⊆Y)=det(KA)
公式中变量含义:
Y行列式点过程随机采样得到的一个随机子集;
A⊆Y 是Y的任意子集;
p(A⊆Y) 表示中所有元素在采样中被命中的概率;
K是一个的实对称方阵,也是被称为的核矩阵,每个元素可以认为是集合中第个元素之间的相似度,与采样概率成反比。可以看做物品与用户的相关性,和采样概率成正比。
K_A是K的主子式,阶数是中元素个数。
行列式点过程,通过下图可以形象的描述:
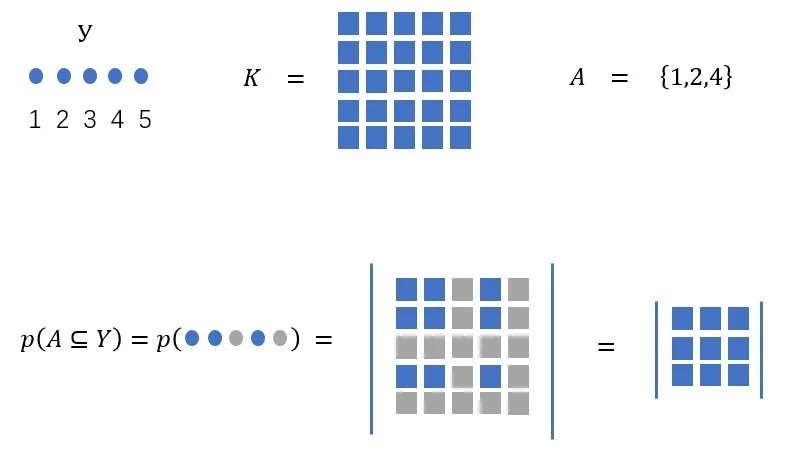
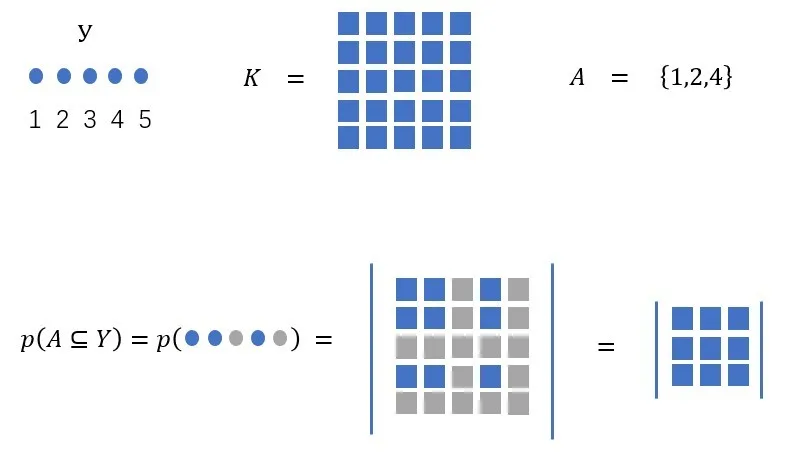
行列式点过程示意图
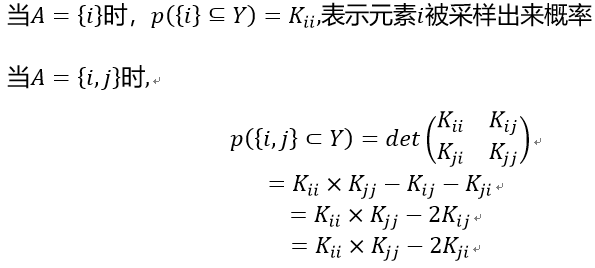
表示物品i、j同时被采样出来的概率。从公式可以看出,越是相似的物品,被同时采样出来的概率就越小。
该算法思路是把重排序问题看成一个子集选择问题,目标是从原始数据集合中选择具有高质量但又多样化的的子集,通过DPP来保持高质量和多样性的平衡。DPP是一个性能较高的概率模型,通过行列式将复杂的概率计算简单化。DPP还可以理解为一个抽样的过程,两个元素作为子集被抽取的概率与单一元素被抽取的概率以及这两个元素的相似度有关。
DDP实现方案:
第一种是Google提出一种基于窗口的重排序方案,论文中提到的核矩阵构建方案是:
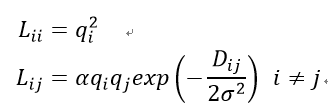
D_{ij}表示物品i、j的距离,是自由变量。当α=1时,等价于标准RBF内核。当α∈[0,1]时,按比例缩小矩阵的非对角线,这基本上对应于将所有物品更多样化。当α>1时,按比例放大矩阵的对角线,其相反的效果是使所有项更相似。
随着集合的增长,小集合的概率增大,而大集合的概率减小。由于α>1时,可能导致L非半正定,为了保证每次计算的核矩阵半正定,论文对核矩阵做了一个映射,计算L的特征分解并用0代替任何负的特征值。
同时也提出了基于深度格拉姆核矩阵的深度学习模型优化方法,减少网格搜索参数的复杂度。
第二种是宾夕法尼亚大学提供的方案,该方案是一个通用的DDP最大后验推断求解方案,但是每获取一个物品,都要经过计算而重新构建核矩阵,延迟不太乐观。
第三种是Huhu视频提出最大后验推断解决方案,该论文提出了一种改进的贪心算法能够快速的求解以解决传统MAP时间复杂度很高的问题:
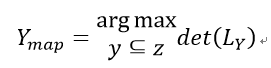
通过构造f(Y)=logdet(L_Y)的次模函数把MAP求解问题转化为次模函数最大化为题。并通过贪心算法来解决次模函数最大化带来的NP-hard问题。
每次选择商品添加到结果集中Y_g中,Y_g初始化为空集,直到满足条件为止,商品需要满足下面的等式:
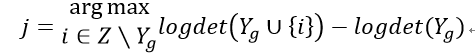
由于计算行列式复杂度较高,论文对的进行Cholesky分解,初始化为空,并通过一些列转化得到:
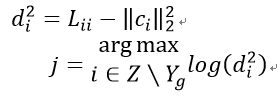
作者又提出了增量更新,通过推导(具体推导过程请参考原论文)得到最终增量更新公式:
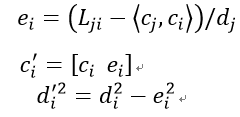
我们实现了三种方案,方案二延迟较大,无法应用到线上。方案一我们实现的简单模式,是直接计算行列式,延迟比方案三大。方案三没有核矩阵就行修复,会出现排序结果小于预期数据量的情况。实际应用中,结合数据量的需求以及效率,我们最终选择的是第三种hulu提出的实现方案。
DPP实现流程:
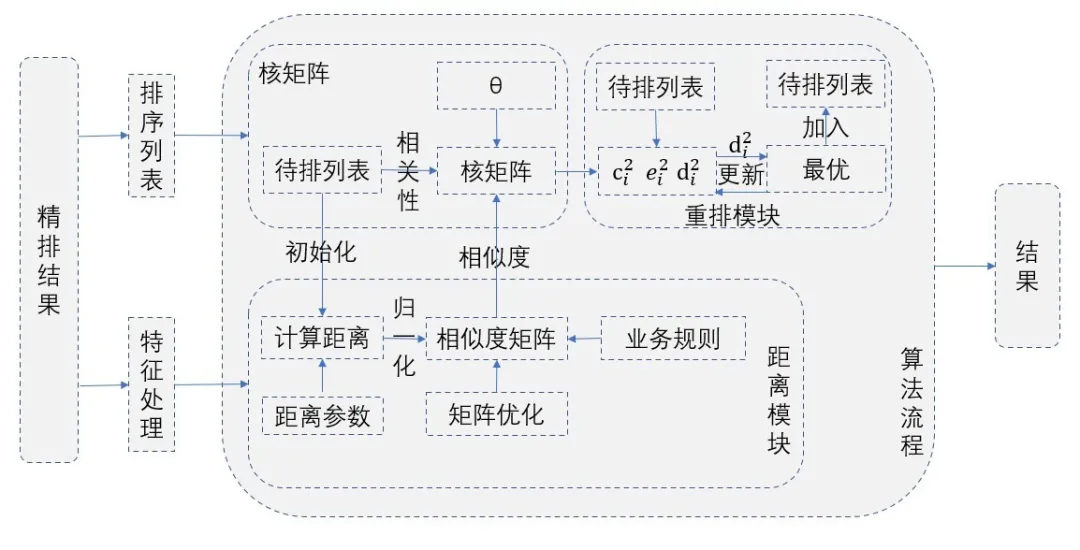
DPP算法流程图
实验效果:
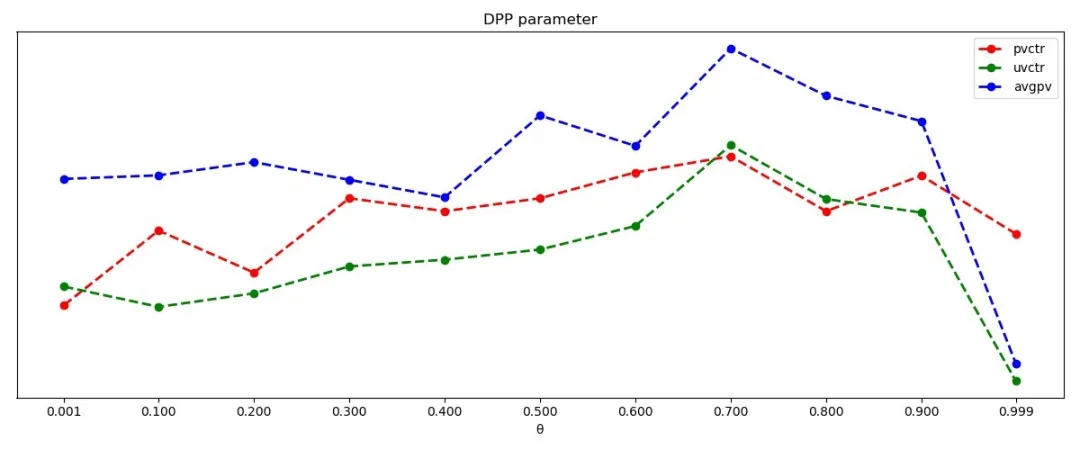
DPP参数变化对应效果图
为了保证几个指标在同一张图中相互对比,图中把pvctr和avgpv进行一定程度的放大和缩小。从上图可以看出,逐渐调整多样性参数, pvctr在变大,在0.7左右的时候达到最高。uvctr和人均浏览数稳定提高,说明随着多样性的增加会吸引不点击的人产生点击行为,并且会使得人们浏览更多的内容,并且uvctr在0.7的时候达到最高点,在0.7时的时候效果最好。DDP每条曲线最后一个参数值都很低,是因为在0.999的时候,在构建核矩阵的时候a的值变得很大,在经过指数变化,导致很多核矩阵的值为最大值,矩阵不满秩,数据只返回几个,属于非正常情况,各种指标都下降,这也是算法调试过程中需要避开的点。
工程实现问题:
实现上,我们主要使用EJML这个高效的开源的Java矩阵运算库实现的,这个库是目前尝试过程中效率比较高的库。
工程实现上,主要参考论文中提到的使用
exp(αr_u )
代替Ru,通过对多样性和相关性进行调节,
α=θ/((2(1-θ))
)
论文中提到的保证半正定性就行修正
S_ij=(1+⟨f_i,f_j ⟩)/2
在我们应用中影响并不是很大,主要是我们的相似度矩阵是自定义的。
DPP主要优化点在效率,我们采用huhu视频的优化方案,通过增量求解的方式代替遍历求行列式的方式,平均100个物品整个重排序过程延迟只有4ms。
核矩阵的构建,因为我们需要一个可解释性比较强并且能和业务结合比较紧密的自定义距离,因此相似度矩阵、核矩阵也是自定义。
采用窗口的方式对整个列表分批排序。针对次模函数性质,小的数据集排斥性比大的数据集更大,采用窗口效果更好。
针对DPP调参,首先固定自定义距离参数,找到一个合适的,然后固定,循环调节距离参数,网格搜索的方式优化参数。
由于核矩阵不满秩,导致返回数据量可能会小于预期的数据量,在对业务影响不大的情况下,可以正常使用。如
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E5%A4%9A%E6%A0%B7%E6%80%A7%E7%AE%97%E6%B3%95%E5%9C%A8%E9%83%A8%E8%90%BD%E7%9A%84%E5%AE%9E%E8%B7%B5%E5%92%8C%E6%80%9D%E8%80%83/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


