同城帮帮商家版智能问答模型优化实践
来源: 郭宗沂 58技术
导读: 58同城是国内最大的生活服务信息服务平台,连接着数千万C端用户和数百万B端商家,为了提升B端商家和C端用户的有效连接,基于智能对话机器人我们构建了帮帮智能客服商家版,其中一项功能为在微聊中对用户问题进行智能回复。
背景
智能回复流程由QABot机器人和Taskbot机器人两部分构成,如图所示,第一部分QABot机器人用于解答用户问题,第二部分Taskbot机器人用于引导用户留下更多信息以及商机,当前智能回复已接入黄页多个二级类目,本文我们主要讲述QABot机器人相关实践探索。
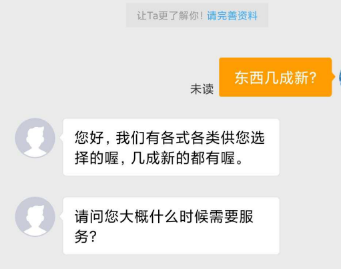
智能问答在黄页业务中的难点
黄页场景业务线数量相对较多,不同业务线之间消息分布差别较大,用户消息相比智能客服简短,存在大量陈述句。这些陈述消息难以归为某一类问题咨询,因此相对智能客服场景有结果率较低。为此我们首先采用了分类模型进行线上迭代,之后实验了分类模型+检索的方法。
分类模型整体架构
QABot问答机器人目前由分类模型实现,分类模型冷启动和线上迭代过程构成。冷启动期间,我们拉取线上各业务线的微聊数据日志,抽取C端用户消息通过BERT[1]或者word2Vec[2]的方式生成用户消息句向量。采用Bi-KMeans方法进行聚类,将相似语义的用户消息聚集到一起。
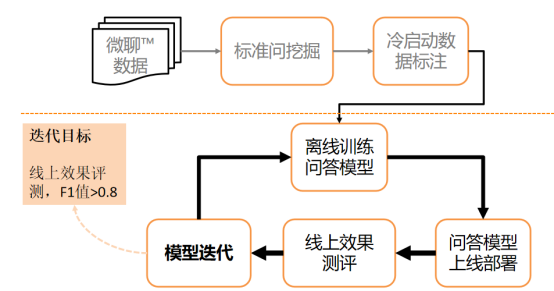
对聚类结果标注,相似语义消息归为一类(例:“价格是多少”、“多少钱”、“钱怎么算”是一类问题,均是对商品价格的询问),分类模型预测频次出现较高的类别,能够覆盖用户的高频问题。为方便编辑同学进行标注,我们对每类问题抽象出一条标准问题来概括该类,而该类下的具体用户消息称为扩展问题,是标准问题的具体表现形式。获取数据后,通过不断模型的迭代和线上评测,最终达到对用户消息有效分类。

分类模型选择
在分类模型的选择上,我们考虑了多种工业界常用的算法:
(1)FastText
FastText[3]是由FaceBook于2016年发布的文本分类模型,具有结构简单,训练及推理速度较快的特点。FastText与生成词向量的CBOW方法结构很像,并且采用了N-gram的方法,在预测过程中使用了分层SoftMax来加速训练。
FastText能够在文本分类任务中迅速达成baseline,达到相对较好的效果,并且推理耗时较少,适用于项目启动时期的快速上线。
(2)LSTM+DSSM
DSSM[4]即Deep Structured Semantic Model,模型出自微软研究院,主要方法是将query和doc通过深度网络映射到相同维度的空间中,通过最大化其余弦相似度来进行训练。
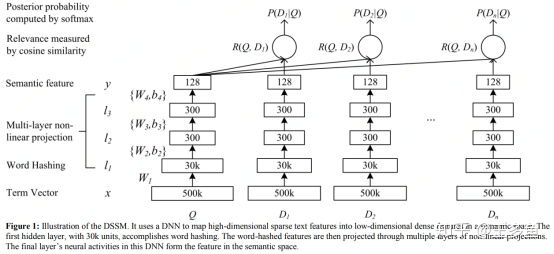
LSTM-DSSM是对DSSM的优化,原生DSSM的基础上,引入LSTM作为句子表征,提取更多的语义级别的信息。
(3)BERT
BERT是由谷歌发布的预训练模型,采用了12层transformer和多头注意力机制,使用大量数据进行预训练,得到了通用模型,在大量数据集上创造了最佳成绩。实际应用的过程中仅需要将原有模型在当前任务上进行Fintiune即可。
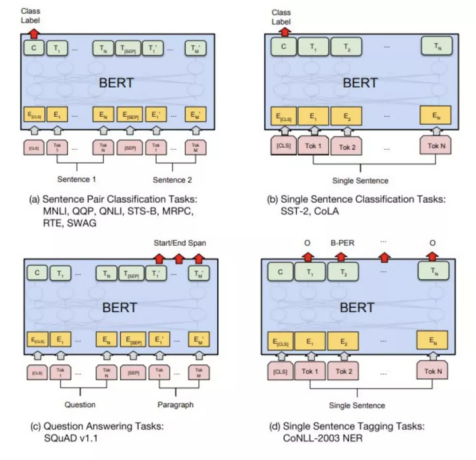
(4)SPTM
SPTM是58自研框架,该框架与BERT采用相同的预训练数据方法,第一版SPTM删除了NSP训练任务,使用字粒度的数据,随机掩码15%的字。并将Bert中的TransFormer替换为残差Bi-LSTM进行预训练,完成预训练之后保留模型参数。在微调时替换最后的全连接层,采用不同场景的标注数据对预训练模型进行微调,整体结构如图所示:
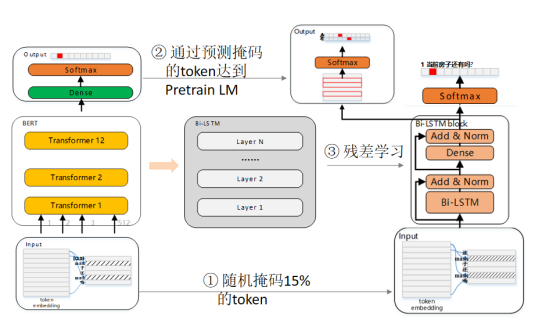
在分类模型的选择中,我们参考了其他业务线的实验结果,采用了自研的SPTM框架。SPTM在离线实验中能够保持较高的分类精度,满足问答匹配过程中对准确率召回率的总体要求。同时在耗时方面仍旧能够有相对较快的推理速度。以FastText为baseline,LSTM+DSSM能够在baseline的基础上提高6.07%的F1值,而BERT和SPTM能够分别提升21.37%和20.79%的F1,效果明显较好。在推理耗时方面,CPU场景下SPTM耗时11.74ms,相比BERT的81ms能大大减少预测耗时,达到线上预测要求。
检索模型探索
在问答场景中,有结果率是一个重要的指标,计算方法为: AI回复的用户消息量/用户发送的消息总量。有结果率较低,会造成大量的用户消息没有被回复,产生用户问答体验下降。而在黄页场景中,用户消息中存在大量陈述句和琐碎短句,难以归类于某一类问题,造成了有结果率较低。
人工客服与用户有着大量的历史交互数据,为了有效的利用这一部分人工客服数据,提高有结果率和用户体验,我们尝试了检索模型和分类模型相结合的方法来提高有结果率。检索模型将线上用户和客服的微聊数据构建离线的问答对<用户问题,客服回复>,当线上用户咨询时,检索距用户消息距离最近的消息,并取对应的客服回复来回答用户。
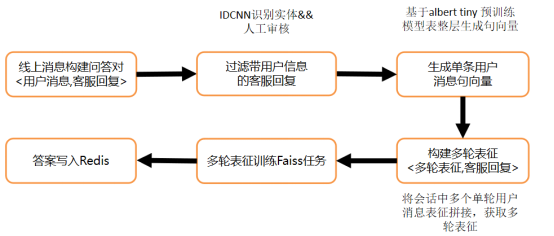
离线构建表征模型的流程如下图所示,
(1)通过IDCNN实体识别过滤带有电话、地址、时间等信息的回复,通过规则和人工审核过滤带有姓氏和不恰当回复。
(2)采用ALBert tiny[5]作为用户消息表征模型,将用户消息表征为312维的向量并横向拼接,构建<多轮表征,回复>的格式。
(3)多轮消息表征训练Faiss任务,用于线上检索最近邻消息,回复写入Redis用于线上回答。
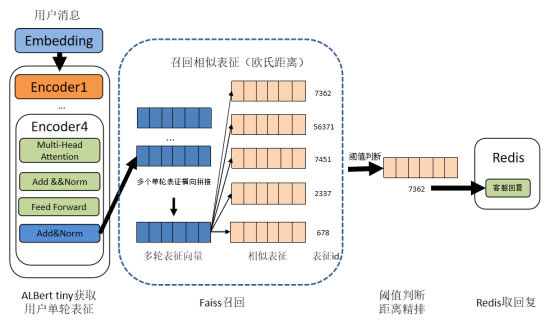
线上预测流程如图所示:
(1)用户消息通过ALBert tiny输出第四层Encoder的312维的表征向量,拼接后获取多轮表征
(2)通过Faiss检索召回多条相似表征向量
(3)阈值过滤,距离精排选取top1相似表征
(4)以相似表征对应ID为Key获取对应的人工客服回复
模型融合
检索模型模型和分类模型在回复消息的分布上存在差异,为此我们融合了检索模型和分类模型。以检索模型优先,分类模型作为兜底,当检索模型无结果时由分类模型来回复。
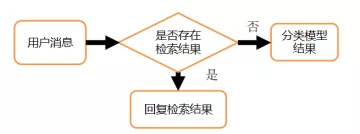
融合模型提高了对于用户的有结果率,相比分类模型,仅使用检索模型能够提高7.68%的有结果率,而融合检索模型和分类模型之后能够提高26.21%的有结果率,同时在结果的准确率方面并没有下降。
在模型融合方面,当前的融合方法逻辑相对简单,仅仅当检索结果不满足要求的时候再调用分类模型。但实际线上的检索回答结果并不一定优于分类模型回答,这里可以构建一个精排模型,将分类模型答案与检索答案一起精排来决定最终选择。但检索模型仍旧存在一些问题,历史数据并不一定恰当,需要进行大量的人工审核。并且由于人工客服回复中也存在商机引导内容,检索结果与智能回复中的taskbot存在冲突。
总结和展望
帮帮商家版是有效连接商家和用户的平台,QABot作为与用户直接交互的渠道,关系着用户的使用体验。我们通过不断优化实践提高QABot问答效果,在不同的业
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E5%B8%AE%E5%B8%AE%E5%95%86%E5%AE%B6%E7%89%88%E6%99%BA%E8%83%BD%E9%97%AE%E7%AD%94%E6%A8%A1%E5%9E%8B%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


