同城推荐系统架构设计与实现
主题
58同城推荐系统架构设计与实现
一、推荐系统架构介绍
推荐系统是一个微庞大的工程、算法与业务综合的系统,其主要分为三大子系统:
1) 线下 推荐子系统;
2) 线上 推荐子系统;
3) 效果评估 子系统;
后文将重点讨论以上三大子系统的设计与实现。
二、线下推荐子系统
线下推荐子系统又主要分为 线下挖掘模块、 数据管理工具 两大部分。
线下挖掘模块
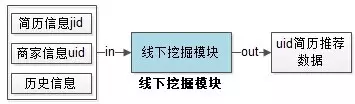
线下挖掘模块,是各类 线下挖掘算法实施的核心,它读取各种数据源,运用各种算法实施线下数据挖掘,产出初步的挖掘结果,并将挖掘结果以一定格式保存下来。典型的,实施这些挖掘策略的是一些跑在hadoop平台上的job,并行实施策略,并将挖掘结果保存到hadoop上。
数据管理工具
数据管理工具,即DataMgrTools,它是一个工具(或者服务),它能够接受一些管理命令,读取某些特定格式的线下数据,将这些数据实时或者周期性的打到线上的redis或者内存中,供线上服务读取。
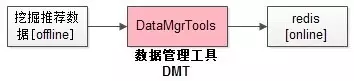
数据管理工具是一个与业务无关的通用工具,它需要支持多种特定格式数据的上传,因为线下挖掘模块产出的数据可能存储在文件里,HDFS上,数据库里,甚至是特定二进制数据。
该工具的实现要点是:定义好线下数据格式,线上数据格式,通过上下游API做数据的迁移和转换。
三、线上推荐子系统
线上推荐子系统主要分为 展示服务、分流服务、推荐内核、策略 module 服务 等几个部分。
展示服务
展示服务,或者说是接入服务,它是整个推荐系统线上部分的入口,即整个推荐系统的接入层,它向上游提供接口,供上游业务方调用。
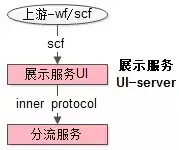
展示服务是无状态的服务(线上子系统各个服务都是无状态的服务),可以任意水平扩展,该服务的实现要点是:定义好通用的接口格式。
分流服务
分流服务,它是推荐系统中一个非常有特色也非常重要的一个服务,它的作用是将上游过来的请求,按照不同的策略,以不同的比例,分流到不同的推荐算法实验平台(也就是下游的推荐内核)中去。
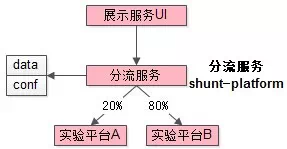
分流服务如何判断上游过来的一个请求分配到那个推荐算法实验平台呢? 答案是通过策略和配置。从架构图中可以看到,几乎所有的服务都需要读取数据(data)和配置(conf),这些data可能是在线的动态变化的数据(例如:从redis中读取的数据),亦可能是相对静态的数据(例如:城市列表),conf比较好理解,即一些配置(例如:所有请求80%流量必须走A算法实验平台)。通过这些策略和配置,配合请求带过来的参数,分流服务计算出流量分配到哪个实验平台。
该服务的实现要点是:实现通用的支持与或非关系的可配置的分流规则,与下游实验平台定义好通用的接口以实现将流量按需打往不同的实验平台。
推荐内核
推荐内核,是各类 线上推荐算法实施的核心,它其实只是一个通用的实验平台容器,每个推荐服务内部可能跑的是不同类型的推荐算法。
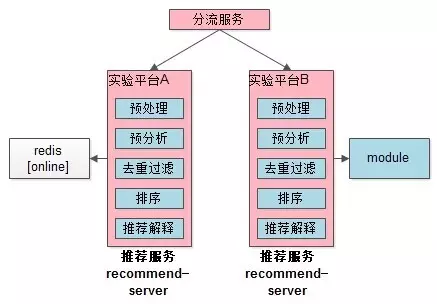
虽然推荐服务中跑着不同的推荐算法,但每个算法的实施步骤都是相同的,都需要经过:
(1)预处理;
(2)预分析;
(3)去重过滤
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


