周玉驰因果分析在贝壳的探索实践

分享嘉宾:周玉驰 贝壳 资深算法工程师
编辑整理:吴祺尧
出品平台:DataFunTalk
导读: 因果推断的应用范围十分广泛,例如气候变暖、新药研发、物理研究、经济学等。AI领域,特别是互联网产业,如何科学的进行因果分析,是一个重要的议题。本次分享的主题是因果分析在贝壳的探索和实践。
今天的介绍会围绕下面三点展开:
- 因果分析在研究什么
- 如何科学地做因果分析
- 因果分析在贝壳的探索与实践
01 因果分析在研究什么
首先,因果分析在研究什么。

2021年诺贝尔经济学奖授予了从事因果推断研究相关的经济学家David Card、Joshua D. Angrist和Guido W. Imbens。因果的研究范围非常广泛,例如:气候变暖、新药研发、牛顿定律、劳动经济学等。在AI领域,特别是产业互联网,例如社区团购的团长管理,房产领域的经纪人管理与赋能等,作为AI工程师,我们经常会面对下面这样的问题:我们项目的价值是什么?怎么样来证明价值是项目产生的?
通过因果分析来论证价值,是一个必要但很难的过程。马克吐温曾经说过:“世界上有三种谎言:谎言、该死的谎言和统计数据。”数据可以帮我们更好地分析问题,但也可以成为愚弄他人的帮凶。如果没有使用正确的方法,那么可能导致因果推断出现偏差,甚至悖论。
为什么因果分析很难?在因果分析过程中面临很多挑战,其中常见的三个挑战是:
- 相关性与因果性:相关性是进行因果分析的重要方法,但是相关性不代表因果性;
- 混杂因素:干扰因素或外来因素;
- 选择偏差:样本选择偏差或实验分组偏差等。
挑战一:相关性与因果性
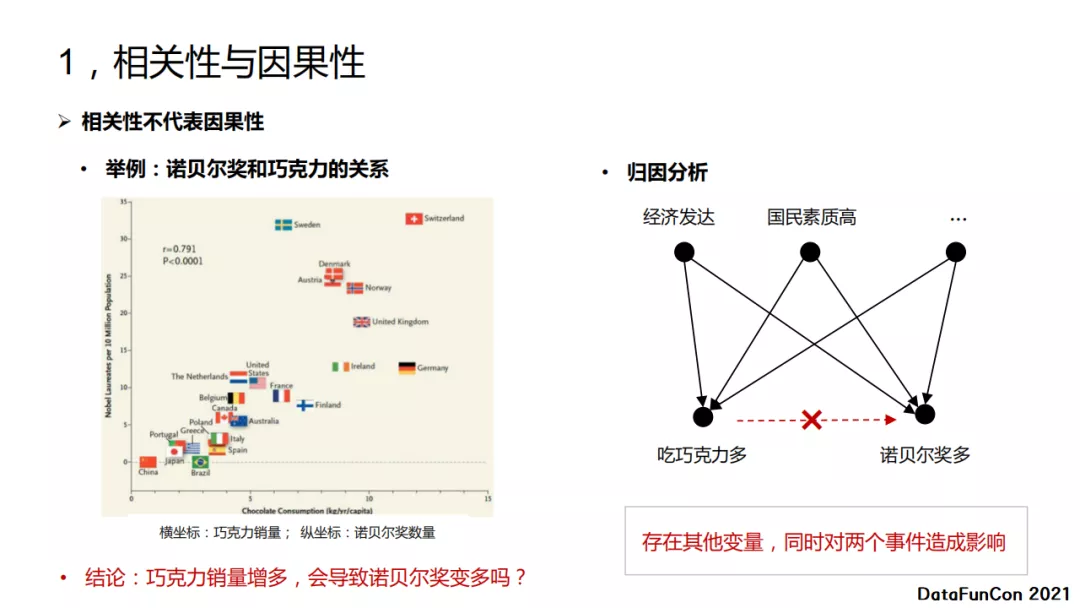
例如诺贝尔奖和巧克力的例子,上图左侧的关系图可以发现一个国家巧克力销量越多,这个国家的诺贝尔奖获奖数量越多,那是否可以得到这样的结论:增加巧克力销量会导致诺贝尔奖数量变多吗?显然这是错误的。我们可以通过上图右侧的因果图来进行分析。如果一个国家的经济发达或者国民素质高,那么这个国家的人吃巧克力会多,同时这个国家能获得诺贝尔奖的数量也会很多,但是巧克力和诺贝尔奖之间是没有相关性的。通过这个例子,我们可以看出:存在其他变量可以对两个变量同时造成影响。
挑战二:混杂因素
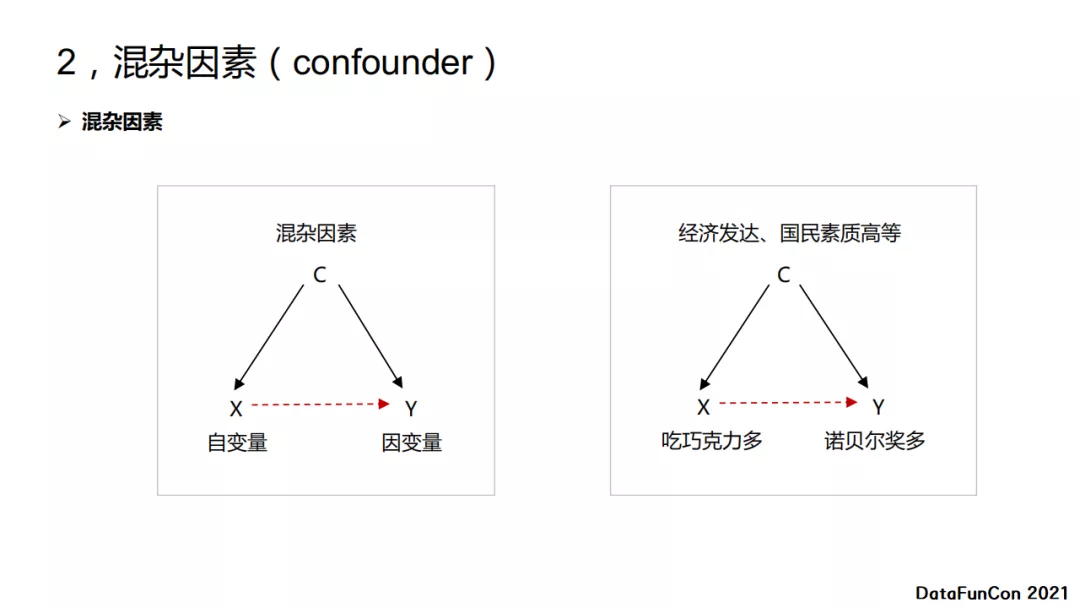
什么是混杂因素?是当我们在研究自变量和因变量之间的关系的时候,出现其他干扰因素,这些其他干扰因素就是混杂因素。在刚才的例子里,巧克力是自变量,诺贝尔奖是因变量,国家的经济和国民素质等是混杂因素。
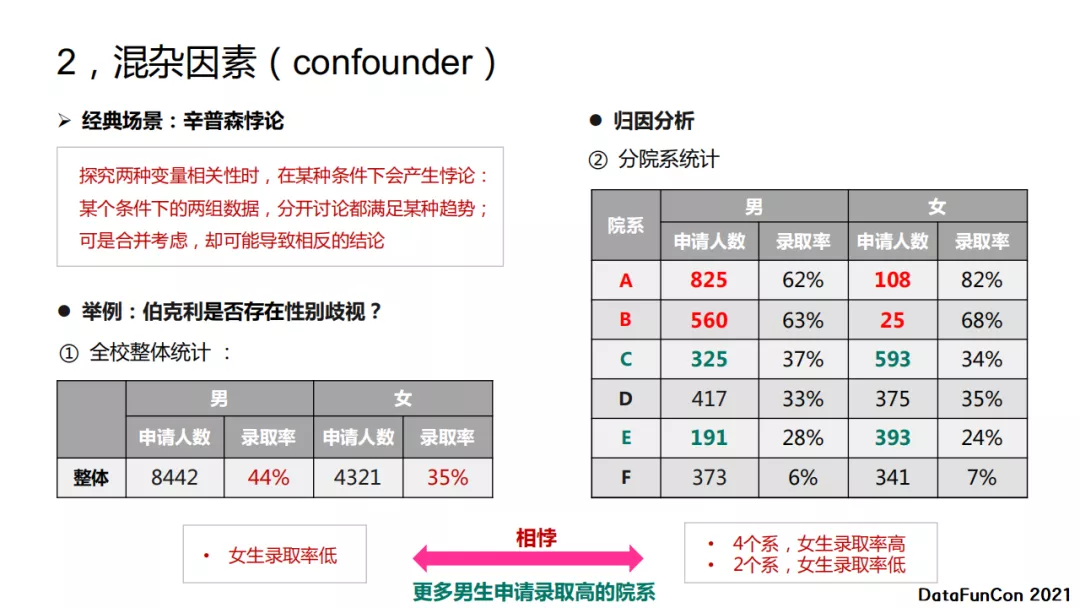
混杂因素有个经典的场景:辛普森悖论。当我们探究两种变量相关性时,在某种条件下会产生悖论:某个条件下的两组数据,分开讨论会满足某种趋势,但是合并考虑就会得到一个相反的结论。比如,针对伯克利大学新生录取率做过一个统计,发现女生录取率比男生录取率低,看起来好像是存在性别歧视。但是如果我们分院系进行统计,就会发现有4个系女生录取率高,而只有2个系女生录取率低于男生录取率。两个结论是相反的,存在悖论。这因为录取率较高的两个系男生申请人数非常多,而女生申请人数非常少;而C系和E系录取率相对偏低,但女生申请人数较多。
挑战三:选择偏差
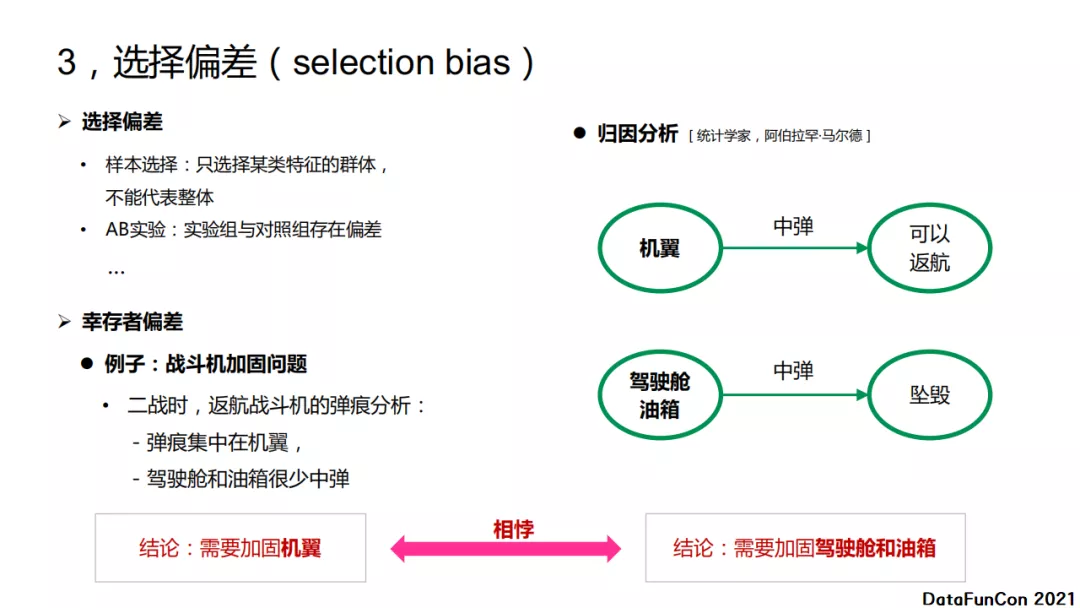
选择偏差可能出现在很多场景,比如在样本选择中,可能只选择了某类特征的群体,他们不能代表整体;再比如AB实验中,实验组与对照组存在偏差。举个幸存者偏差的例子,在二战的时候对返航战斗机的弹痕分析,发现弹痕集中在机翼,而驾驶舱和油箱很少中弹,那他们就得到需要加固机翼的结论。可是通过进一步分析,如果飞机的机翼中弹,那么它还是有一定几率可以返航的,但是如果驾驶舱和油箱中弹了,那么飞机大概率就坠毁了。所以结论应该是加固驾驶舱和油箱。这两个结论是相悖的。
所以,因果分析的过程挑战多困难大,那应该如何科学地做因果分析?
02 如何科学地做因果分析
首先,基本思路是什么?贝叶斯之父Judea Pearl在《为什么》中提到了一种科学的因果分析方法,它通过三个层级揭示因果关系的本质:
- 关联: 变量之间的关联是怎么样的?
- 干预: 如果实施X行动,那么Y会怎么样?
- 反事实: 是X引起Y吗?假如X没发生会如何?
下面通过一个关于吸烟致癌的争论的例子来解释三个层级。

第一步关联 。多尔和希尔在1948年做过一个调研,发现649名肺癌患者中只有2人不吸烟,肺癌患者基本都吸烟。结论:吸烟导致肺癌。

第二步干预 ,常用的方法是实验。多尔和希尔对六万名医生发放了问卷,发现重度吸烟者死于肺癌的概率是不吸烟的人的24倍。同时,美国的癌症协会进行了更大规模的研究,发现重度吸烟的人与不吸烟的人死于肺癌的概率相差了90倍,而吸烟的人死于肺癌的几率是不吸烟的人的29倍。这些结果都表明吸烟死于肺癌的概率远高于不吸烟的,那么结论是吸烟确实导致肺癌。
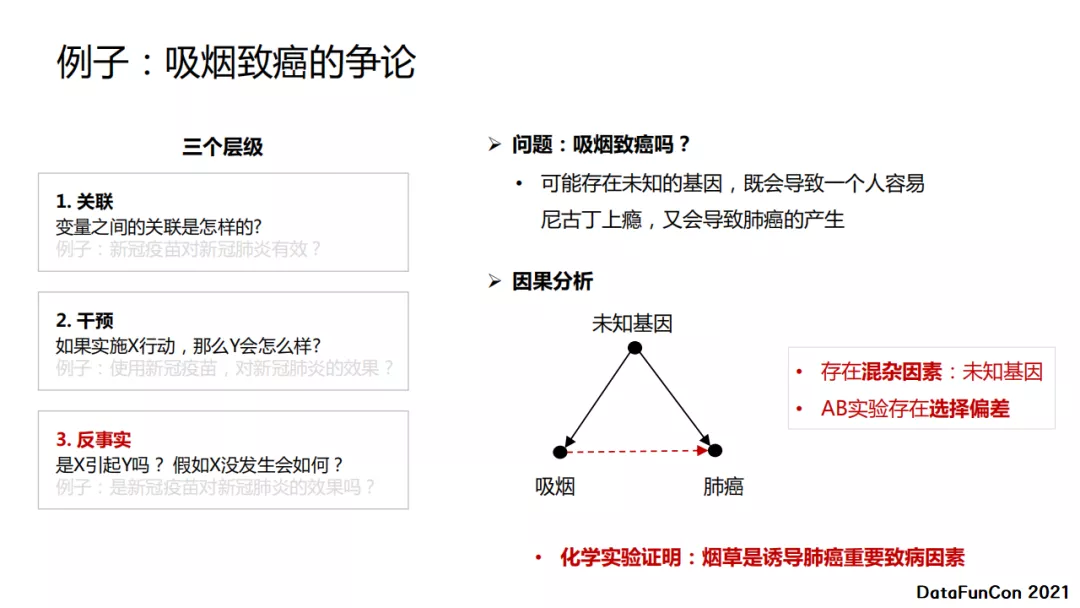
第三步反事实 ,吸烟导致肺癌吗?是否可能存在一种未知基因,它会导致一个人容易对尼古丁上瘾,又会导致肺癌的产生,但是吸烟不一定能导致肺癌。未知基因是实验中潜在的混杂因素,刚才的实验中也存在选择偏差。当然,最终通过化学实验证明了烟草确实是诱导肺癌的重要致病因素。
03 因果分析在贝壳的探索与实践
回到贝壳,我们是如何做因果分析的?贝壳是提供新居住服务的平台,核心要素是人、房、客。人就是经纪人,房就是商品,客就是客户。对于经纪人,重要的事情是维护房源和客源。今天的重点是介绍在智能客源维护方向,如何进行科学的因果分析。
首先,如何维护客户?在过去,经纪人主要通过微信或者电话来了解客户的意愿,我们有一个客源信息中台,是经纪人记录维护客户记录的线上笔记本。现在,我们搭建了智能客源管理工具,帮助经纪人或者门店维护客源。
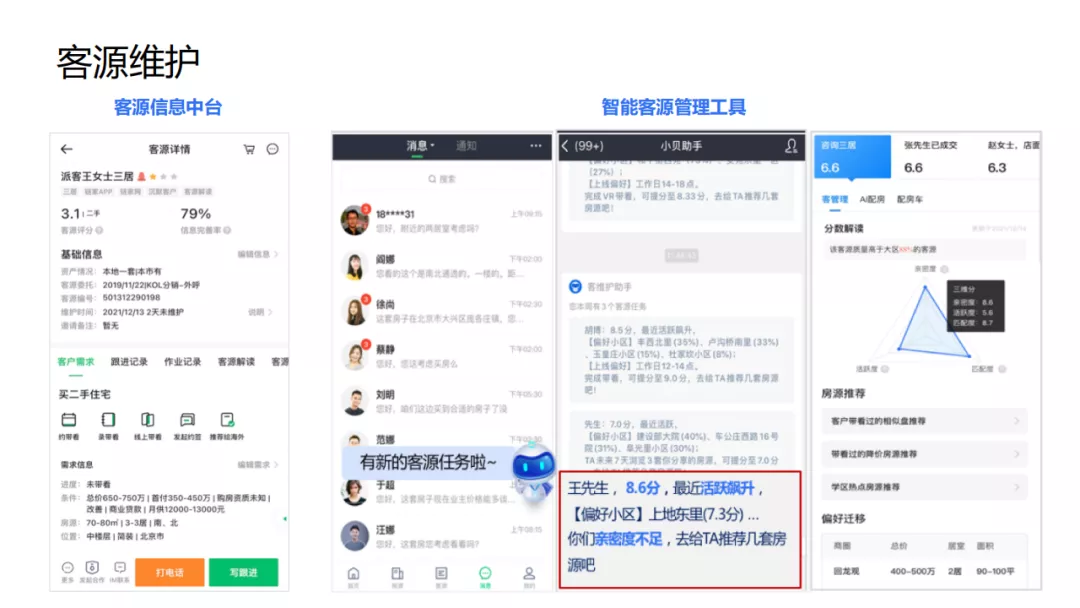
上图左侧就是我们的客源信息中台,经纪人会记录客户信息,例如:通过微信或者电话了解的客户需求,对客户的跟进情况等。上图右侧是智能客源管理工具的示例。经纪人会收到一条信息,包含客户的质量分数、状态、偏好,经纪人与客户的亲密度等等。当经纪人点击这个信息后会进入产品详情页,可以看到更多解读信息。
**如何科学论证工具的价值呢?**在贝壳,核心的目标就是提升成交,但是成交会受到很多因素的影响。看一下,如何通过三个层级来逐步分析。
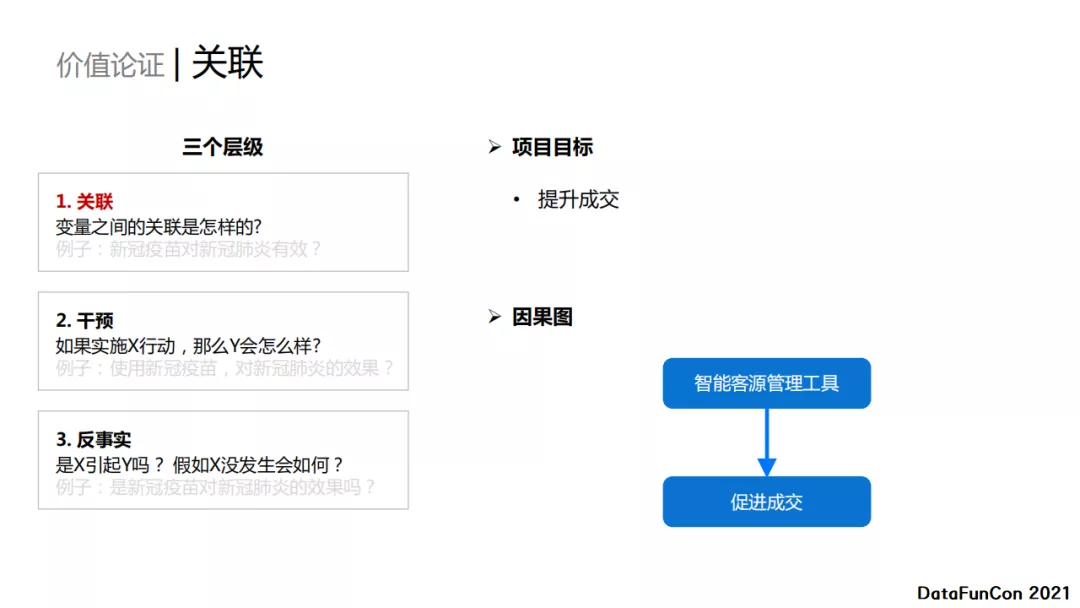
第一步关联 ,我们认为智能客源管理工具可以促进成交。

第二步干预 ,结合项目来介绍一下我们是如何进行实验的。我们的项目主要分为两个阶段:试点阶段,核心目标是让经纪人愿意使用这个工具,这个工具是有价值的;在推广阶段,我们会将工具推广到更多城市。

两个阶段采用了不同的实验方案:
- 在试点阶段,实验组和对照组按照人群进行分组,根据使用工具的频率进行分组(使用工具多的人群vs不使用的人群);
- 在第二阶段,进行随机分组,对10个城市的门店随机分成了两组。观测方法采用双重差分法,指标采用的是平均成交量。
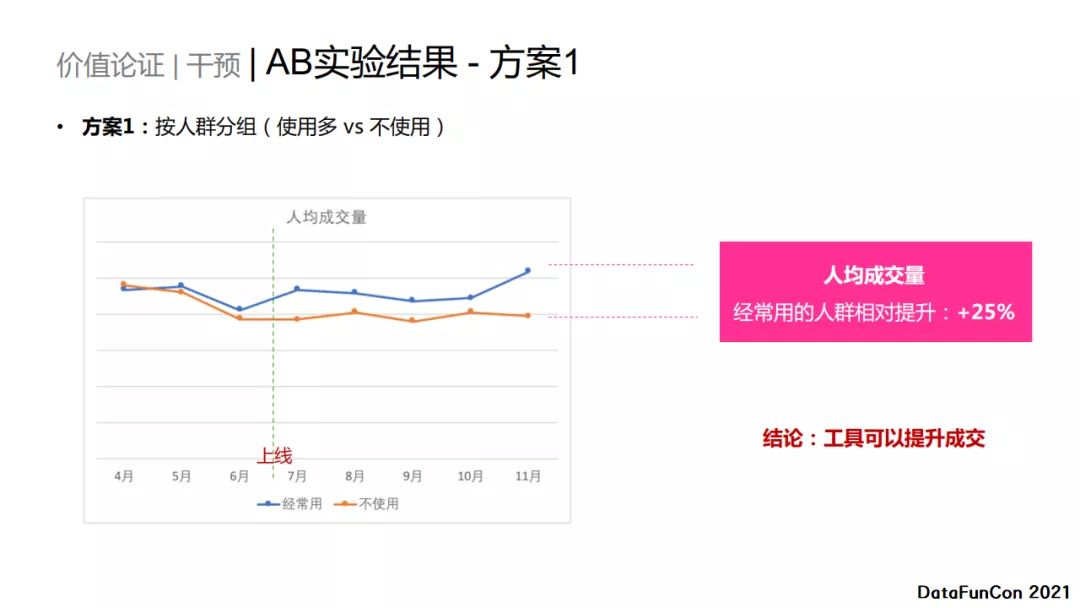
方案1 ,根据使用工具的频率进行分组(使用工具多的人群vs不使用的人群)。图中蓝色的曲线是使用多人群的平均成交量,橙色的线是不使用人群的平均成交量,可以看出:上线前实验组和对照组差异不大,但是上线后使用多的人群明显高于不使用的人群,提升了25%。 结论是工具可以提升成交。
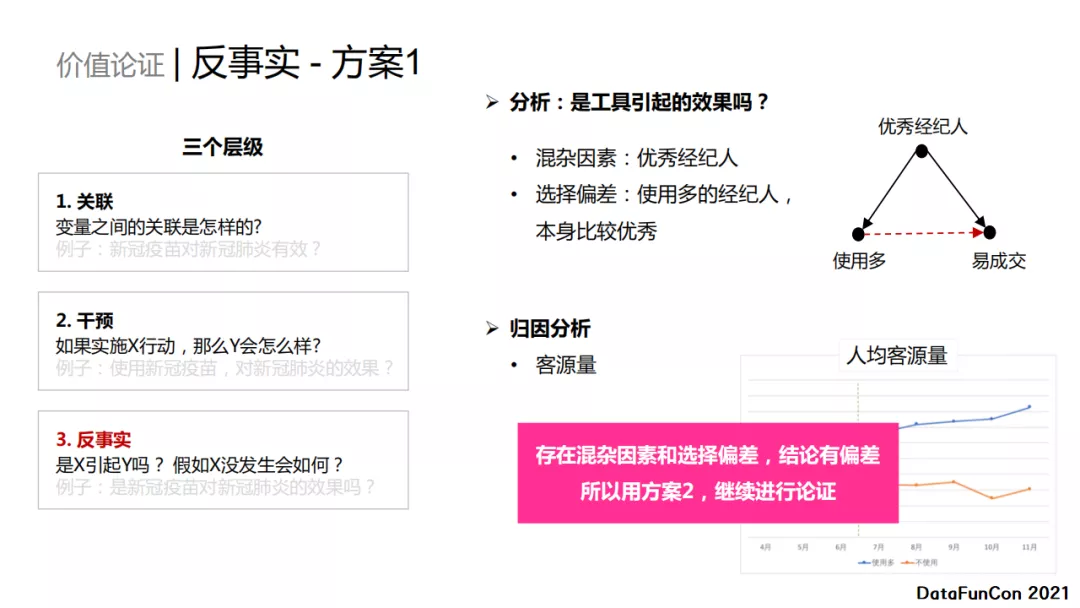
方案1的第三步反事实分析 ,思考:是工具引起的效果吗?是否可能优秀的经纪人会乐于使用新技术与新工具,这会导致他们使用工具的频率较高,他们提升也更多,但是无法说明工具可以使成交提升。为了论证是否存在优秀经纪人,看一下两个人群的资源量:人均客源量。上图右下方的蓝色曲线代表使用多人群的平均客源量,橙色曲线则是不使用人群的平均客源量。很明显,使用多的经纪人客源量远高于不使用工具的,说明:使用多的经纪人本身是比较优秀的。 所以得出结论,存在混杂因素和选择偏差,方案1的结论可能存在偏差。 因此,我们使用方案2继续进行验证。
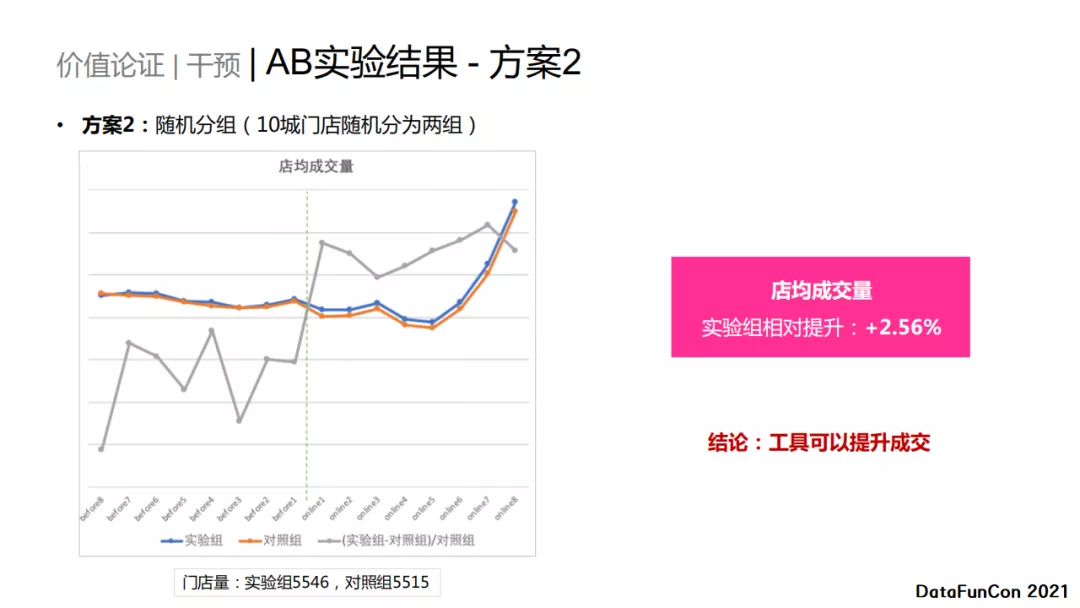
方案2 采用随机分组的方法,按照门店进行随机分组。上图蓝色的折线是实验组,橙色的线是对照组,灰色的线是(实验组-对照组)/对照组,绿色的虚线表示上线时间。可以很明显地看出,上线之前,实验组和对照组的人均成交量近似相等,而上线之后实验组明显高于对照组,大约提升2.5%。 结论:工具可以提升成交。
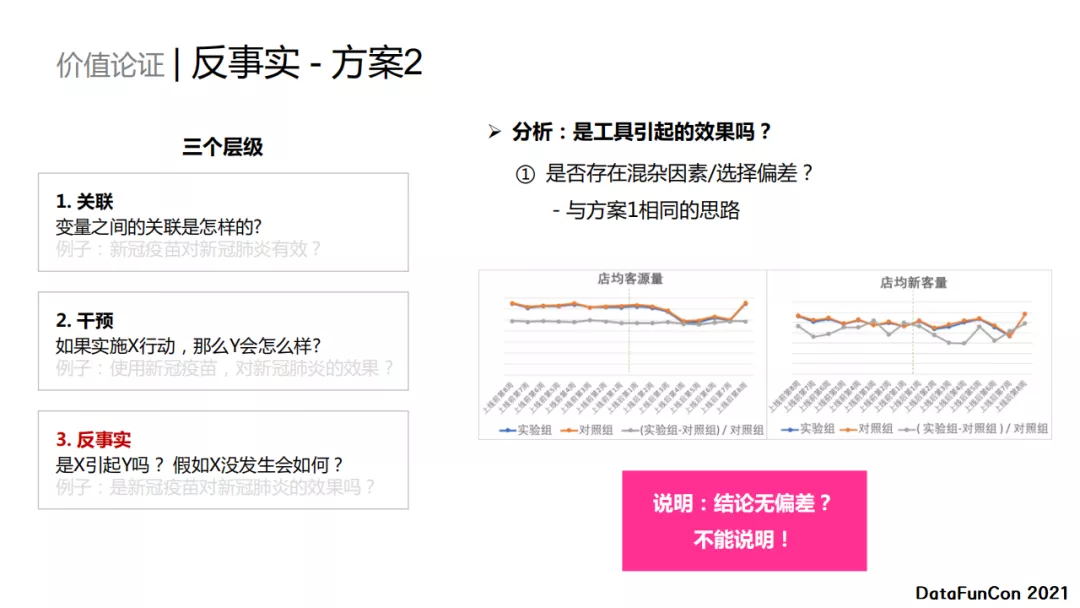
方案2的反事实分析 ,与方案1相同的思路,我们考虑是否存在混杂因素或者选择偏差。首先,我们分析了两组人群的平均客源量和新增客源量,发现实验组和对照组在上线前后近似相等。但这无法说明结论不存在偏差。现实中的混杂因素是无法一一穷举的,我们无法通过探索混杂因素来严格证明最终的结论。

我们转换了思路,思考工具可以改变什么,我们从工具影响路径的过程进行分析。首先,如何进行客管理?我们的管理思路是对客进行分层处理。顶部是即接近成交的优质客户,中部是质量较好的客户,底部是大量储备客户。我们希望对于顶部客户快速去化,中部客户向上催熟。因此,我们的智能管理工具想要促进最终成交,首先需要让经纪人付出更多精力维护顶部优质客户,使得高分客户能被服务得更好,最后促成高分客户的更多成交。
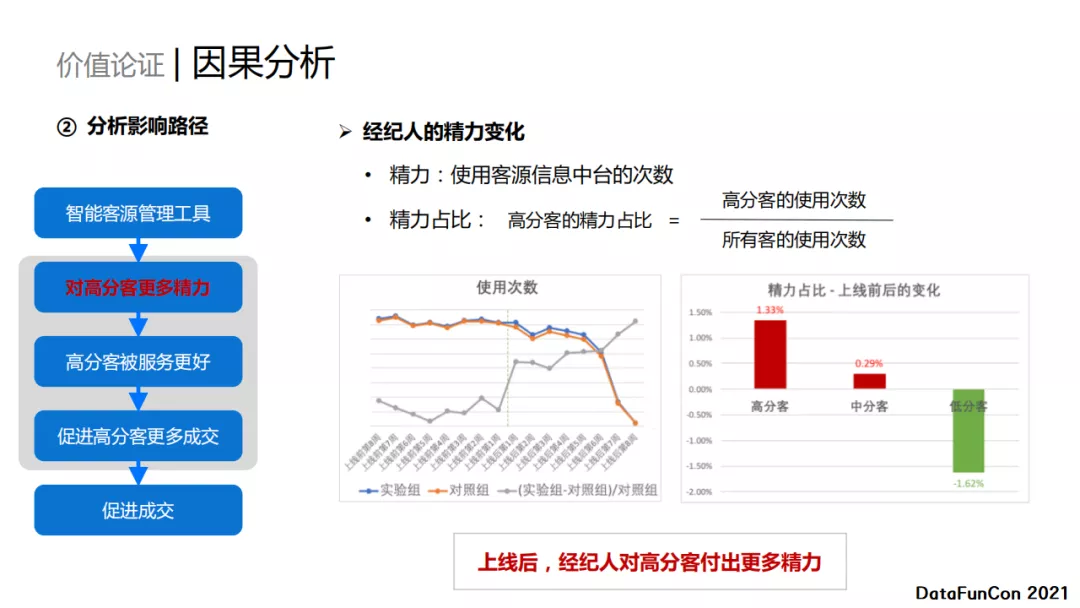
第一步经纪人付出更多精力维护顶部优质客户。经纪人对于高分客户的精力变化。我们使用客源信息中台(经纪人的线上记录的笔记本)的使用次数来衡量精力。从上面的折线图可以看出上线之后经纪人对客源信息中台的使用次数有所增加。进一步,我们也观察了经纪人对高分客户的精力占比,即对高分客户使用信息中台的次数占总使用次数的比例。我们发现在上线之后,对于高分客户和中分客户,经纪人精力占比有所提升。说明,经纪人对高分客付出了更多精力。
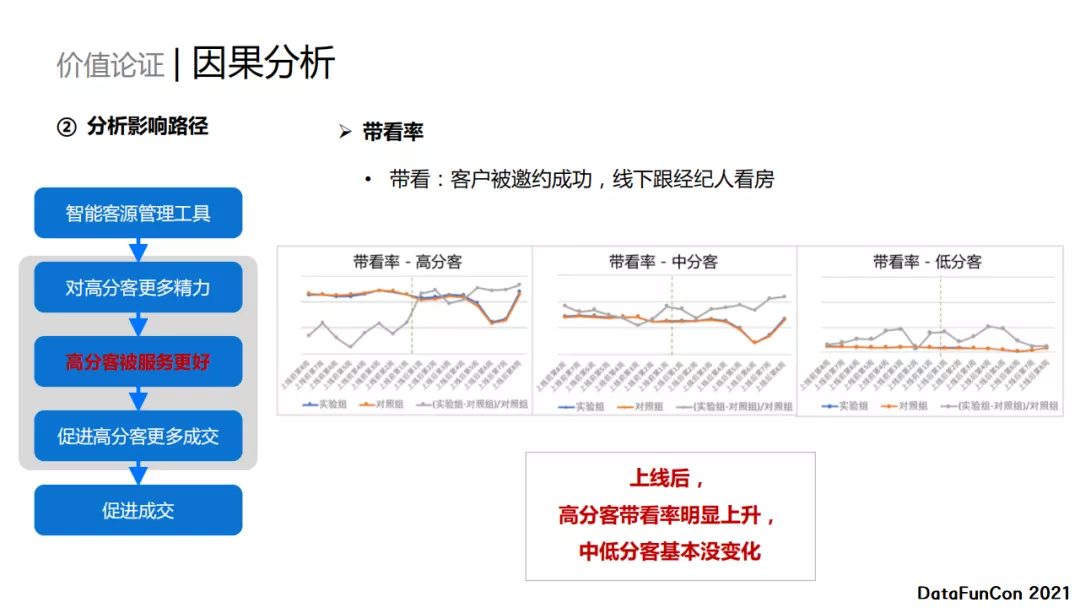
第二,高分客户被服务得更好。我们使用了“带看率”,即客户接受经纪人的邀约请求去线下看房子的比例。分别观察了高分客户、中分客户和低分客户的带看率,实验结果图如上图所示。很明显,在工具上线之后,高分客户的带看率有明显上升,中低分客户的带看率则基本没有变化。这就说明高分客户确实邀约成功的次数变多了,也就是被经纪人服务得更好了。
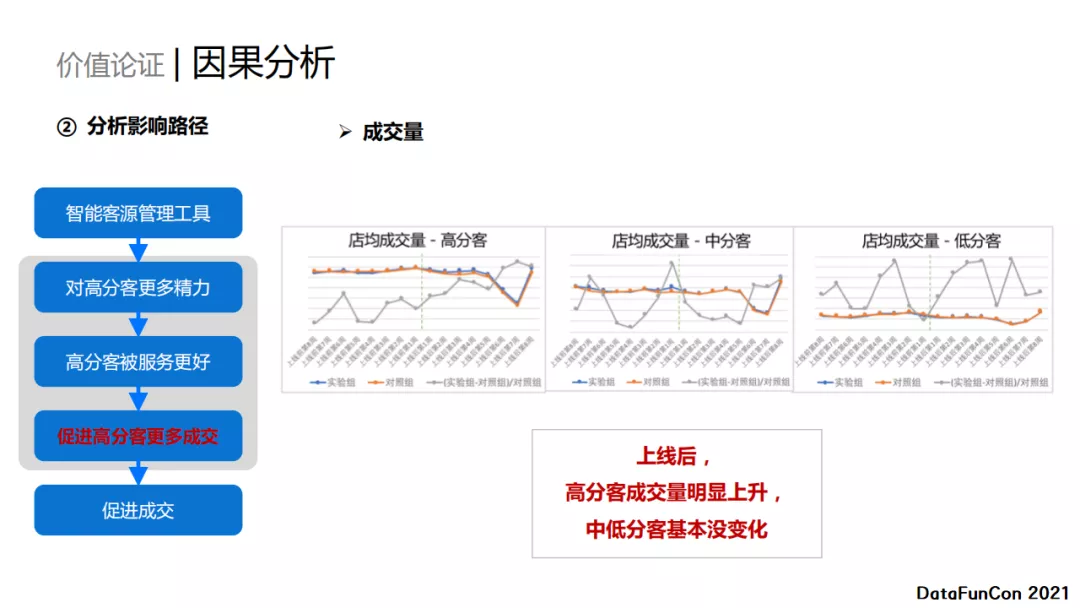
最后,促进高分客更多成交。观察三个分数段的客户在工具上线之后是否产生了成交量的上升。如上图所示,通过对比明显发现,上线之后高分客户的成交量有明显上升,而中低分客户的成交量没有明显变化。 所以,我们认为智能客源管理工具确实促进了高分客户的更多成交,进而促进了整体的成交。
最后做一个总结:
- 如何科学地进行因果分析?基本思路是通过三个层级进行因果分析:关联->干预->反事实;
- 在干预阶段,如何论证项目的价值?我们对两种常见方案进行了分析。方案1是按人群进行分组,方案2是随机分组;
- 在反事实阶段,如何进行归因分析?因为大部分的场景很难分析混杂因素的影响,所以我们的思路是考虑项目改变了什么,从影响路径的过程进行分析。
04 精彩问答
Q:价值论证中的因果图是怎么构造的?因为图中只给出了一个影响因素,如何说明是考虑了全部的影响因素?
A:现实中的混杂因素是无法一一穷举的,我们无法通过探索混杂因素来严格证明最终的结论。所以,我们的思路是考虑项目改变了什么,从影响路径的过程进行分析,工具是否对经纪人的行为发生了改变进而改变了整个过程,来论证项目是否最终促进了提升。
Q:因果分析中有没有考虑统计的显著性?
A:没有特意进行分析。我们的AB实验周期比较长,上线前实验组和对照组的差异不大,上线后实验组明显优于对照组。
Q:如何避免抽样过程中的选择偏差?
A:从两个方面看:数量方面,观察了分组内不同城市的门店数量、不同等级经纪人的数量(例如经纪人的能力、业绩等);质量方面,观察两个分组中经纪人的行程量(例如成交量、带看量等)是否有差异。分城市来看这两个方面的数据,实验组和对照组的差异都不大。
Q:有没有因果分析的工具库?
A:这个目前是没有的。我们在项目落地时遇到了项目价值论证的问题,恰好2021年的诺奖获得者从事的是因果推断方面的工作,所把我们项目中,在因果分析的过程中将遇到的问题做了整理和总结,借助本次机会和大家分享经验。
Q:方案2的随机分组是否可以去除如优秀经纪人这类混杂因素的影响?
A:在产业互联网很多场景下,AB实验的数据量可能并不是很大。其次,即使得到最终的结果,我们也应该反思一下结果是否真的是由项目造成的,即使用反事实的思路去论证结论。
Q:方案1如何向老板说明项目的价值?
A:无法说服。我们列出方案1的目的是因为很多团队在使用因果
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%91%A8%E7%8E%89%E9%A9%B0%E5%9B%A0%E6%9E%9C%E5%88%86%E6%9E%90%E5%9C%A8%E8%B4%9D%E5%A3%B3%E7%9A%84%E6%8E%A2%E7%B4%A2%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


