国美大促场景下的国美智能推荐系统演进之路
作者: 杨骥
时间: 2017 年 11 月 10 日
国美早期的推荐产品,90% 以上的场景是靠平台运营人员和工程师依靠业务知识进行手工配置,策略投放也是基于场景相关性的固定槽位展示,千人一面。近几年,伴随着业务的发展,尤其是实现线上线下打通后,国美互联网基于双线平台、商品和服务,利用互联网技术,以“社交 + 商务 + 利益共享”的共享零售战略向用户赋能,在后电商时代走出共享零售的新路径。同时,作为与用户交互的排头兵,国美的推荐系统也嵌入到了商品、美媒、美店等核心场景,将实时个性化推荐的购物体验带给用户。而业务场景的迅速展开和大数据的积累也促使推荐架构和机器学习算法进行了持续地升级和迭代。
本文详细地介绍了 2016 年以来,由 11.11 大促驱动的国美个性化推荐系统中核心技术的演进历程。
另外,由 InfoQ 举办的 AICon 全球人工智能技术大会 将于 2018 年 1 月 11-14 日在北京举行,本文作者杨骥将会带来《国美推荐引擎与算法持续部署实践》的精彩分享,想要了解更多国美智能推荐技术细节的,欢迎报名参加 AICon,与杨老师进一步交流。
一、实时系统铸成个性化推荐基石
2016 年 11.11 大促,我们当时的实时计算平台采用比较主流的 Kafka+Storm、辅以 Spark Streaming 的架构。在 11.11 当天,用户实时行为分析、商品 & 店铺多维度信息更新等功能支撑了实时推荐。虽然实现了推荐结果的实时性,但是从 11.11 使用过程中来看,这种架构还是有较多的不足,比如:
- Kafka、Storm、Spark Streaming 支持“实时 / 近实时”信息收集和计算(此外推荐系统还需要 Hive/Hadoop 平台进行一些离线数据和模型的生产),但是整个数据生产的链路太长,组件太多,在稳定性、灵活性和扩展性方面问题很多。大促过程中出现了几次因为计算任务堆积而造成系统资源吃紧,不得不临时降级的情况。
- Spark Streaming 和 Storm 由于各自的特点,不适合做机器学习模型所需要的低延时实时特征计算。
- 系统组件太多,维护成本很高。
因此 2016 年 11.11 大促之后,我们就根据实时计算平台暴露出的问题,规划了下一步的研发方向,即实现统一的实时 & 离线计算引擎,将数据生产、特征计算和模型训练放到一起来做。通过调研,相比于 Spark、Storm 等平台单一的数据处理方式,Apache Flink 同时支持数据批处理和流式处理。因此采用 Flink,就能够同时支持在线和离线数据生产,大大简化了多系统部署和运维的成本。
今年 4 月份,我们确定了 Apache Flink 作为实时计算引擎的技术选型,并且在 Flink 上进行了二次开发,以满足国美推荐和搜索的业务需求。
经过半年多的开发和测试,新的实时计算引擎于今年 8 月底上线,实现了如下几个重要功能:
- 用户行为亚秒级反馈:这个功能在推荐系统中的重要性不言而喻,包括商品 / 店铺召回、特征计算、展示过滤、用户画像更新等,都需用户行为数据作为支撑。
- 实时特征计算:无论是候选集训练,还是线上排序(Offline/Online Ranking Model),要想提高模型精准度,必需引入实时特征。如果采用传统的方式进行处理,不但需要在后端服务引擎中多次调用各种数据接口,从而增加了系统整体的 I/O 开销;同时特征计算还很耗费推荐引擎的响应时间,造成线上服务延时较大。因此我们开发了一套特征计算框架,将底层特征(即初级特征)生产这种计算相对密集的任务放到 Flink 平台上进行,不但降低了算法工程师的开发难度,同时也有效降低了推荐引擎的负载。
- 算法效果实时评测:通常 A/B 测试都是以天为粒度进行,效果反馈不及时,影响策略的及时调整。使用实时计算引擎,我们能够在 11.11 大促期间对策略投放的效果进行小时级的跟踪分析,显著地提升了流量的使用效率。
通过国美 2017 年 9 月和 10 月期间的几次促销活动实践反馈,新的基于 Flink 开发的实时计算引擎达到了预期的设计目标,并且会在今年 11.11 大促期间发挥出重要的基础支撑作用。
二、特征系统重塑引擎核心
排序是个性化推荐展示非常重要的一环。尤其在国美互联网三百多个推荐场景中,如何将候选集中的商品放入合理的槽位,将直接影响用户的购物体验。国美在排序方面也经历了从人工运营到规则排序,再到机器学习算法排序的演进。在实践过程中,我们发现 特征生产、存储和调用 三个环节直接影响算法排序的最终效果。
2016 年上半年,我们在完成推荐引擎架构升级的同时,也进行了规则排序的大规模迭代和优化,取得了非常明显的效果,关键展位(比如首页猜你喜欢、详情页搭配购、加购成功页等)整体 CTR 提升 31.6%,CVR 提升 11%。在此基础上,我们加紧研发三个月,并在 2016 年 11.11 大促期间上线了基于机器学习的 CTR 预估排序模型, 大促期间关键展位整体 CTR 同比提升幅度 91.2%,CVR 转化率提升 34.3%,效果提升可以说非常显著。
但是在整个大促期间,我们也发现特征生产方面的问题给系统带来的瓶颈:彼时特征生产的任务都压在引擎本身,也就是说,推荐服务首先调用用户行为,然后根据用户行为取商品、店铺、活动的相关信息,最后根据线上部署的机器学习模型(此时还没上线 Online Learning 排序模型),将这些信息转换成需要的特征,这个过程中要反复调用多个数据接口。如果模型维度较大,则进一步加大引擎本身的负载,所以流量很大时,算法排序的性能就有些吃不消了,为了保证推荐服务的可用,必须进行相应级别的降级处理。另外,响应用户请求之后,特征就相当于被“抛弃”了,接下来进行模型训练和更新的时候,还需要从仓库中重新抽取数据,重新“恢复”一遍特征,浪费了宝贵的计算资源,也影响了算法工程师的迭代速度。
2016 年 11.11 大促之后,我们立即着手进行特征计算和存储系统的搭建,并将这个项目和实时平台的开发同步进行。
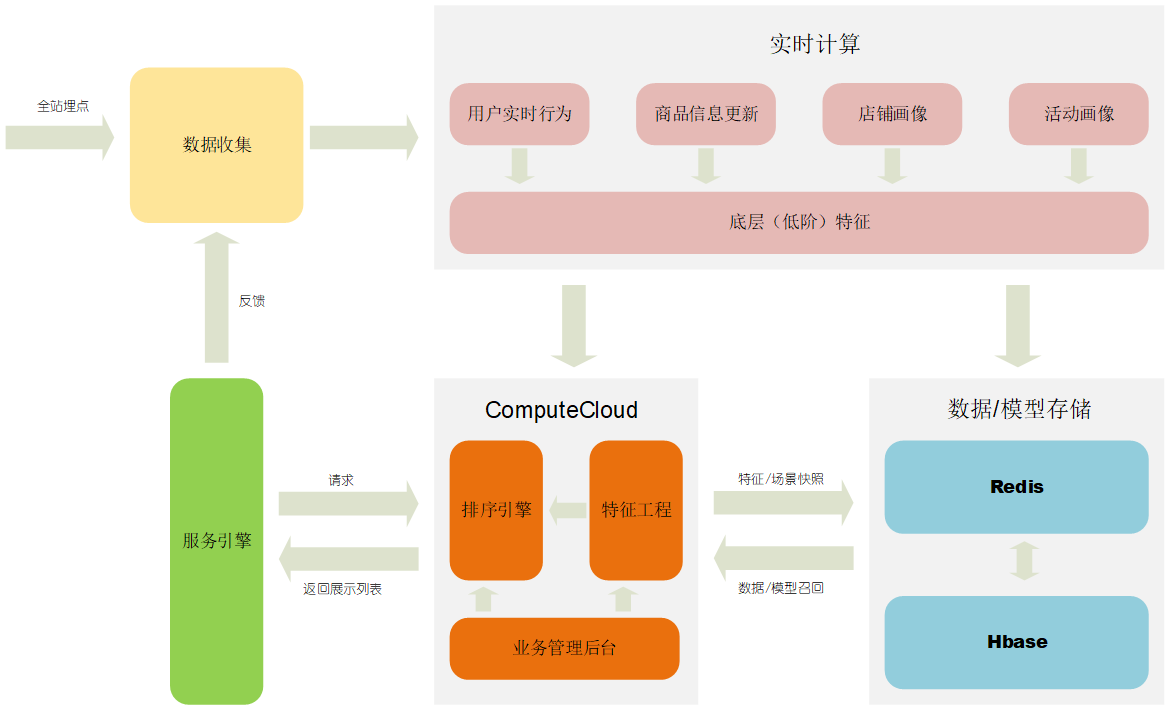
图 1. 国美个性化推荐数据流转简图
我们对特征系统的性能要求就是高并发、低延迟、高可用,同时兼顾实时、近实时和离线特征的计算和存取。经过了一段时间的探索性尝试,我们最终确定了 自研计算中间件 +KV 存储 的方案。特征系统和实时计算引擎共同组成了特征生产平台。整个平台的数据计算流程为:
- 其中以上文提到的以 Flink 为主的实时计算平台收集各种消息并进行初步处理,同时计算出一些 底层特征(主要是一些统计性和描述性的特征,不产出二阶以上的特征),然后将这些实时信息和特征“Push”给计算中间件——“ComputeCloud”。
- ComputeCloud 会和模型 & 特征管理后台时刻同步,然后根据收到的实时信息和底层特征计算出更高阶的特征。比如我们某个场景使用的排序模型,会利用 GBDT 的特征产出作为中间特征,那么计算模块会将相应的底层特征(包括从实时引擎推过来的实时底层特征,缓存在计算中间件中的近实时和离线特征等)输入 GBDT 模型,然后将各子树的叶子节点输出作为特征向量(相当于做了特征嵌入处理),提供给最终的排序模型使用。
- KV 存储主要使用 Redis+Hbase 集群,作用是保存 ComputeCloud 中生产的特征,有两个主要目的:对 ComputeCloud 中的各种数据和特征进行备份;进行“特征快照”,将特征的每一次更新都打上时间戳,然后批量导入数据仓库,这样接下来进行模型更新或者新模型训练的时候就不用再次进行数据和场景恢复了。
目前特征计算和存储系统已经上线,并且在国美最近的几次大促中经历了考验,从效果上看,上线之后个性化推荐服务的 平均响应延时降低了 40% 以上。
三、机器学习模型稳步升级
上面两项内容都是个性化推荐系统的基础设施,有了稳定可靠的系统,那么在模型层面上,国美如何应对 11.11 大促场景的考验?众所周知,推荐系统在模型方面主要分为两个比较重要的范畴,即“召回”和“排序”。
3.1 多样化的召回模型
因为电商平台有着海量商品,在千万甚至亿级的商品池中如何“选品”,是非常关键的一个环节。国美推荐最早的召回模型大部分都是基于规则,比如品牌、品类等维度的热销、新品排行等,但是这些候选集数量较少、类型单一。为了提供更为丰富的召回结果,我们进行了大批量快速的迭代试验,最终确定了“item2item”、“搭配购”、“Low-rank Model”三大类模型。
其中“Low-rank Matrix”模型(比如 SVD、SVD++、RBM 等),我们在实践中也走了一些弯路: 真实场景中的商品推荐,不可能只用一个模型就能搞定,需要针对不同的商品或者不同的人群进行训练。比如我们会针对“3C 大类”或者“日用百货”分别训练模型,因为不同大类的用户行为样本数量在量级上有差异,同时用户在不同大类的“协同”行为可比性不强。此外在 召回时还需要考虑用户的历史信息(包括用户画像),从而减少召回的计算量,避免巨量的笛卡尔积运算造成模型不可用。
2016 年 11.11 大促有近 50 个召回模型投入使用,有效地提升了推荐效果的多样性。目前,我们又在原先模型的基础上加入上下文特征,即根据用户和商品构建特征,然后进行训练。根据近一年的迭代优化与线上测试,召回模型池的整体效果又有提升,同时我们对一些效果一般的模型进行了下线处理。目前,国美推荐系统中常用的召回模型大致有 30 个左右,今年 11.11 大促会是这些模型一个非常好的“演兵场”。
3.2 E&E 机制加快选品速度
上文提到推荐召回物料池的构建工作非常重要,无论我们采用规则方法或者机器学习方法(SVD、FM、RBM 等),大都是采用离线的方式进行计算的。换句话说,我们使用的是“历史数据”,当然得到的召回物料就是已经得到过充分曝光展示的商品。但是在 11.11 大促场景下,会有大量新商品、新活动上线,甚至有些商品会频繁地上架或者下架。由于没得到充分的曝光机会,这些长尾商品无法进入推荐候选池,自然也就无法在展位上进行推荐。为了解决这个问题,我们采用了 Explore&Exploit 的方法进行处理。顾名思义,Explore 意思是探索,Exploit 就是利用得到的少部分信息预测新物料的“质量”,判断其是否值得推荐给用户,从而将其迅速加入候选池。
由于 2016 年 11.11 大促时,工作重点是个性化推荐算法的上线,在 Explore&Exploit 方面没有太多的资源可以投入,因此我们先使用了一种简单的规则方法,即首先从 长尾商品(大多数为新品)中选出一个较小的子集,按“品类|品牌|中心词”建立索引,然后在不影响个性化排序的前提下,选择流量比较大的关键展位(包括首页猜你喜欢、详情页相似推荐、详情页搭配推荐等)进行展示,收集用户对新商品的反馈数据,如果达到展示次数的阈值,该商品的 CTR 达标,就将其放入到候选物料池;反之 CTR 较低,则立即停止该商品的展示。
从反馈的结果来看,还是有相当数量的新品得到了及时地筛选,在 11.11 大促期间进行了投放展示。虽然这种方法简单直接,但需要用一部分流量 Explore,特别是一些冷门品类的长尾商品,需要更多比例的流量去尝试,一定程度上降低了大促流量的利用效率。
大促之后,为了让 E&E 机制变得更迅速、更精准,我们进行了一些新的尝试。从比较简单的 Thompson sampling、Epsilon-greedy strategy 开始,接下来又尝试了 UCB、CMAB 等算法,这些方法从实现的角度来看,是要刻画出用户对商品(或者店铺、活动等)感兴趣程度的概率分布,和上述简单直接的阈值规则方法相比,大大增强了模型的描述能力,同时也缩短了长尾商品的遴选时间,有效利用了流量。
目前我们这些 bandit 工具库已经上线,并且部署在推荐产品的全业务线上,尤其是 CMAB 相关算法会把展位位置、流量多少等场景特征也加入,主要原因是:不同展位的曝光次数、对用户的影响程度、种类限制等因素差异巨大,因此同一个商品在不同展位的曝光带来 E&E 效果是不同的。
3.3 排序模型逐步升级
除了上文所述的召回模型,个性化推荐最重要的就是排序了,如何将召回的商品放入推荐位的槽位中,将直接影响到用户的最终选择。
国美推荐排序的“方法论”通常是根据场景的需要,从规则排序开始,逐步上线机器学习排序方法。算法工程师也会从规则排序中先熟悉推荐场景的特点和用户反馈,在“吃掉”规则排序带来的红利之后,接下来逐步从简单的线性模型过渡到非线性模型,步步为营,不断地寻求特征层面和模型训练层面的突破。
2016 年 11.11 大促我们主要使用的是点击率预估的方法进行排序,特征的整体规模较小,模型也相对简单。但是在效果上,大促期间关键展位(猜你喜欢、详情页搭配购、加购成功页等)整体 CTR 与 2015 年 11.11 同比增长 110%,CVR 提升 63%。
2016 年 11.11 大促之后,我们构建了整个排序模型流程的 Pipeline,将数据抽取、处理、标注、训练等环节进行严格意义上的流程化,让算法工程师能够准确的定位问题,专注于某一点进行优化,同时能够让 A/B 测试中各分组的逻辑界限更为明晰。
今年以来,我们将主要精力放在排序模型的优化上面,先后上线了 Mcrank、RankNet、RankSVM、FM、FFM 等方法。同时,我们在实践中尝试了用点击率预估(LR、GBDT 等)进行离线模型融合,然后再利用 Pairwise L2R 进行最终排序的方案,取得了很好的效果。在排序时还有一个问题也非常关键,比如 App 首页猜你喜欢瀑布流展位,直接将排序的结果按顺序展示,很多情况下会出现某个品类的商品“聚集”在一起,严重影响用户体验。因此我们进行了 品类穿插打散(如果考虑更多的维度进行穿插,会直接削弱排序模型的效果),满足用户对推荐结果多样性的要求。
此外,我们还在一些个性化楼层、卖场等场景下,使用了 LambdaMART 等方法。
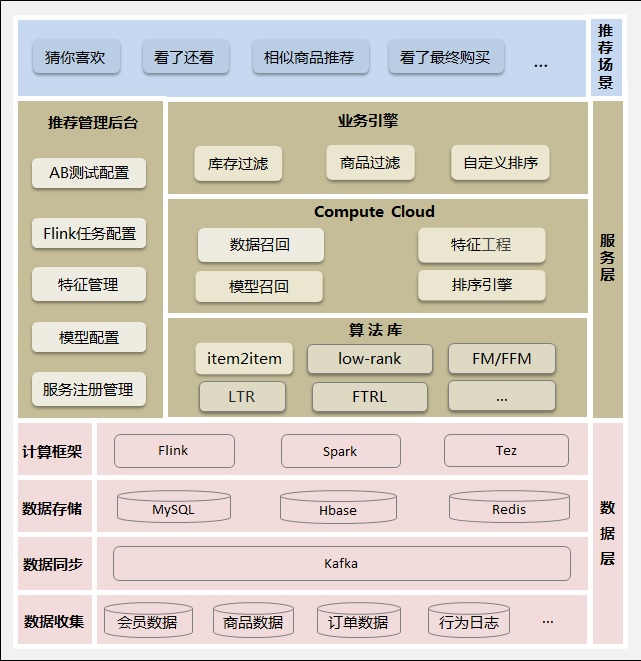
图 2. 国美推荐分层架构
3.4 在线学习初探
上面各种方法都属于离线方法的范畴,即我们通过若干时间的历史数据训练出一�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%BD%E7%BE%8E%E5%A4%A7%E4%BF%83%E5%9C%BA%E6%99%AF%E4%B8%8B%E7%9A%84%E5%9B%BD%E7%BE%8E%E6%99%BA%E8%83%BD%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E6%BC%94%E8%BF%9B%E4%B9%8B%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


