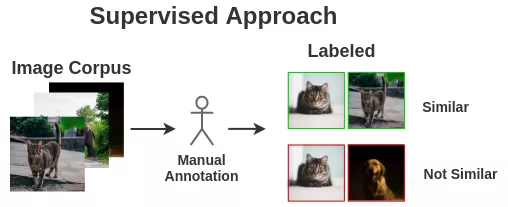
图解框架用对比学习得到一个好的视觉预训练模型
作者:amitness
编译:ronghuaiyang
导读: 有点像词向量预训练模型,这个框架可以作为很多视觉相关的任务的预训练模型,可以在少量标注样本的情况下,拿到比较好的结果。
The Illustrated SimCLR Framework
Published March 04, 2020 in illustration
https://amitness.com/2020/03/illustrated-simclr/
近年来,众多的自我监督学习方法被提出用于学习图像表示,每一种方法都比前一种更好。但是,他们的表现仍然低于有监督的方法。当 Chen等人 在他们的研究论文“SimCLR:A Simple Framework for Contrastive Learning of Visual Representations”中提出一个新的框架时,这种情况改变了。SimCLR论文不仅改进了现有的自监督学习方法,而且在ImageNet分类上也超越了监督学习方法。在这篇文章中,我将用图解的方式来解释研究论文中提出的框架的关键思想。
来自儿时的直觉
当我还是个孩子的时候,我记得我们需要在课本上解决这些难题。

孩子们解决这个问题的方法是通过看左边动物的图片,知道它是一只猫,然后寻找右边的猫。

“这样的练习是为了让孩子能够识别一个物体,并将其与其他物体进行对比。我们能用类似的方式教机器吗?”
事实证明,我们可以通过一种叫做对比学习的方法来学习。它试图教会机器区分相似和不同的东西。

对机器进行问题公式化
要为机器而不是孩子来对上述练习进行建模,我们需要做三件事:
1、 相似和不同图像的样本
我们需要相似和不同的图像样本对来训练模型。

监督学习的思想学派需要人类手工创造这样的配对。为了实现自动化,我们可以利用自监督学习。但是我们如何表示它呢?
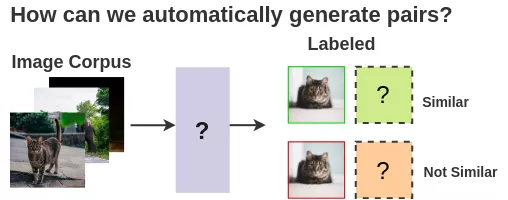
2、 了解图像所表示的内容的能力
我们需要某种机制来得到能让机器理解图像的表示。
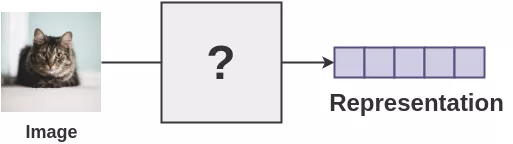
3、 量化两个图像是否相似的能力
我们需要一些机制来计算两个图像的相似性。

SimCLR框架的方法
本文提出了一个框架“ SimCLR”来对上述问题进行自监督建模。它将“对比学习”的概念与一些新颖的想法混合在一起,在没有人类监督的情况下学习视觉的表示。
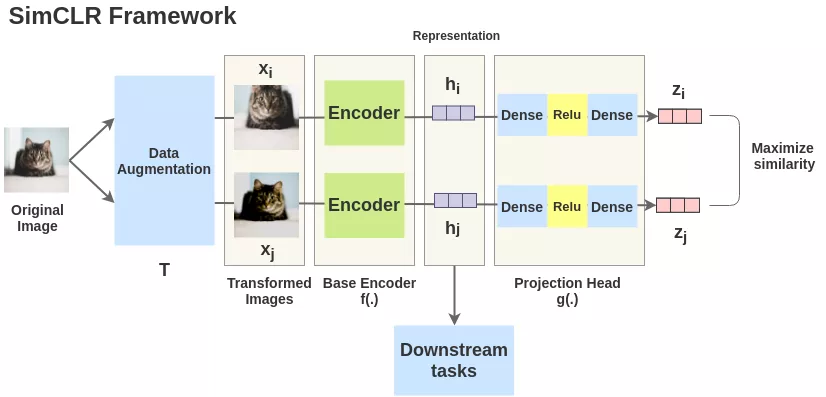
SimCLR框架
SimCLR框架,正如全文所示,非常简单。取一幅图像,对其进行随机变换,得到一对增广图像x_i和x_j。该对中的每个图像都通过编码器以获得图像的表示。然后用一个非线性全连通层来获得图像表示z,其任务是最大化相同图像的z_i和z_j两种表征之间的相似性。
手把手的例子
让我们通过一个示例来研究SimCLR框架的各个组件。假设我们有一个包含数百万未标记图像的训练库。

-
自监督的公式 [数据增强]
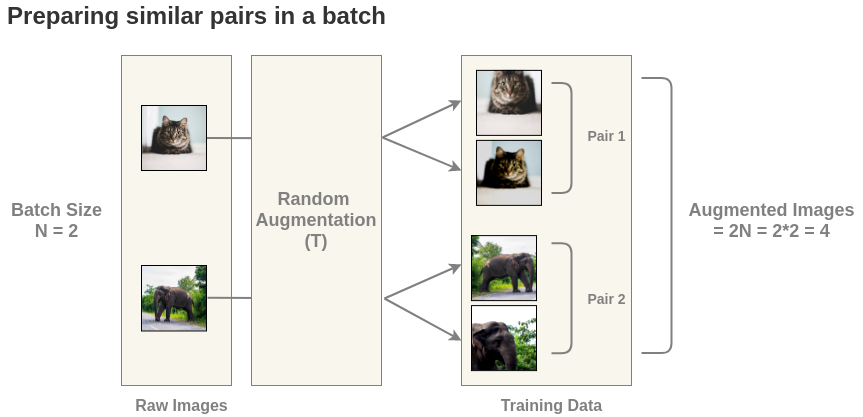
首先,我们从原始图像生成批大小为N的batch。为了简单起见,我们取一批大小为N = 2的数据。在论文中,他们使用了8192的大batch。

论文中定义了一个随机变换函数T,该函数取一幅图像并应用 <span>random (crop + flip + color jitter + grayscale)</span.
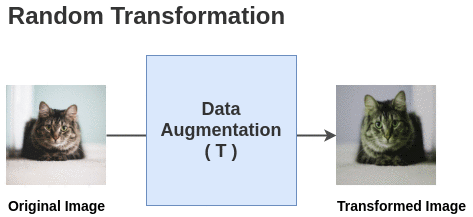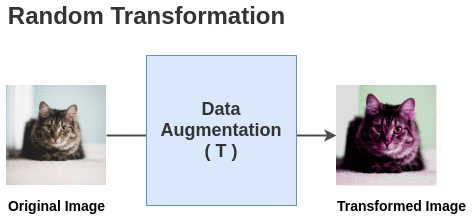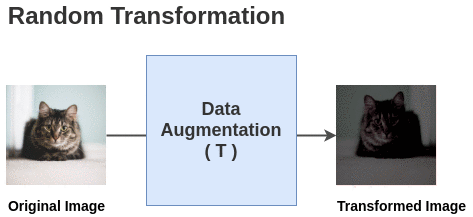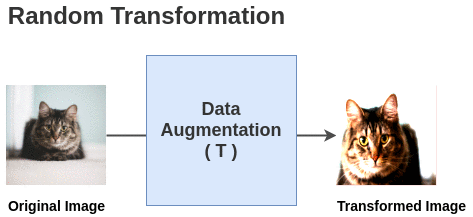
对于这个batch中的每一幅图像,使用随机变换函数得到一对图像。因此,对于batch大小为2的情况,我们得到2 N = 4张总图像。
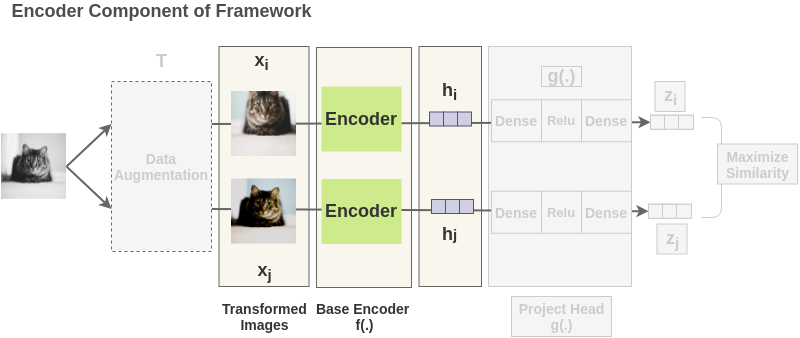
2、 得到图像的表示 [基础编码器]
每一对中的增强过的图像都通过一个编码器来获得图像表示。所使用的编码器是通用的,可与其他架构替换。下面显示的两个编码器有共享的权值,我们得到向量h_i和h_j。
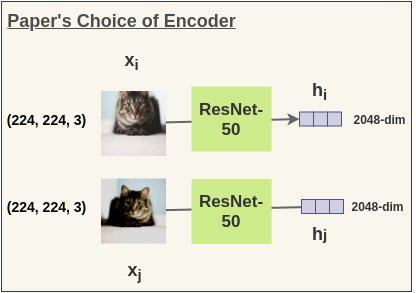
在本文中,作者使用ResNet-50架构作为ConvNet编码器。输出是一个2048维的向量h。
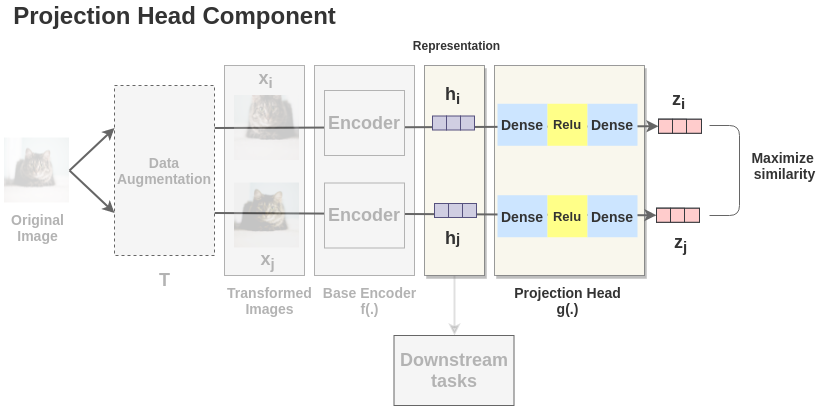
3、 投影头
两个增强过的图像的h_i和h_j表示经过一系列非线性 Dense -> Relu -> Dense 层应用非线性变换,并将其投影到z_i和z_j中。本文用g(.)表示,称为投影头。
- 模型调优: [把相似图像的拉的更近一些]
因此,对于batch中的每个增强过的图像,我们得到其嵌入向量z。
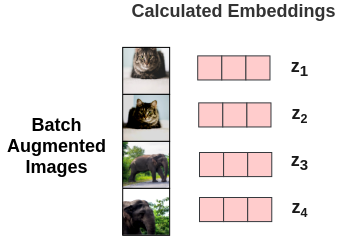
从这些嵌入,我们计算损失的步骤如下:
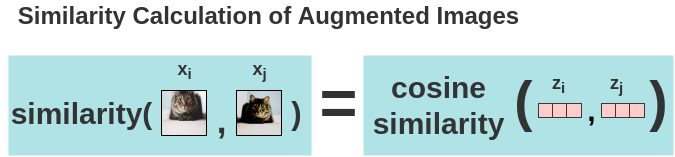
a. 计算余弦相似性
现在,用余弦相似度计算图像的两个增强的图像之间的相似度。对于两个增强的图像x_i和x_j,在其投影表示z_i和z_j上计算余弦相似度。
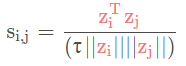
其中
- τ是可调参数。它可以缩放输入,并扩大余弦相似度的范围[- 1,1]。
- ||z_i||是该矢量的模
使用上述公式计算batch中每个增强图像之间的两两余弦相似度。如图所示,在理想情况下,增强后的猫的图像之间的相似度会很高,而猫和大象图像之间的相似度会较低。

b. 损失的计算
SimCLR使用了一种对比损失,称为“ NT-Xent损失”( 归一化温度-尺度交叉熵损失)。让我们直观地看看它是如何工作的。
首先,将batch的增强对逐个取出。

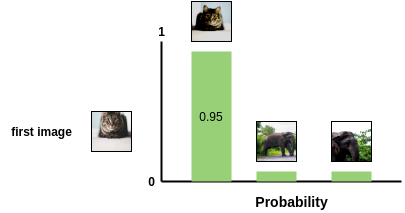
接下来,我们使用softmax函数来得到这两个图像相似的概率。
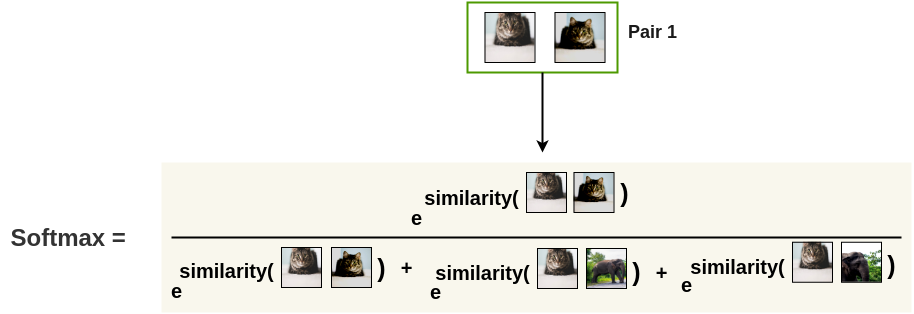
这个softmax计算等价于第二个增强的猫图像与图像对中的第一个猫图像最相似的概率。这里,batch中所有剩余的图像都被采样为不相似的图像(负样本对)。
然后,通过取上述计算的对数的负数来计算这一对图像的损失。这个公式就是噪声对比估计(NCE)损失:
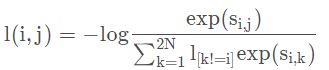

在图像位置互换的情况下,我们再次计算同一对图像的损失。

最后,我们计算Batch size N=2的所有配对的损失并取平均值。
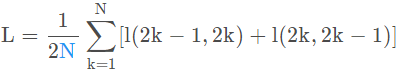
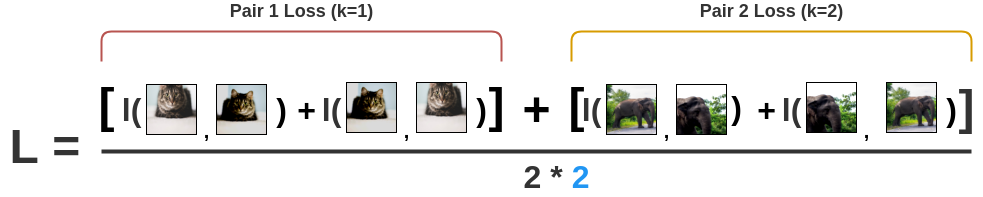
基于这种损失,编码器和投影头表示法会随着时间的推移而改进,所获得的表示法会将相似的图像放在空间中更相近的位置。
下游任务
一旦SimCLR模型被训练在对比学习任务上,它就可以用于迁移学习。为此,使用来自编码器的表示,而不是从投影头获得的表示。�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%BE%E8%A7%A3%E6%A1%86%E6%9E%B6%E7%94%A8%E5%AF%B9%E6%AF%94%E5%AD%A6%E4%B9%A0%E5%BE%97%E5%88%B0%E4%B8%80%E4%B8%AA%E5%A5%BD%E7%9A%84%E8%A7%86%E8%A7%89%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


