基于异构序列融合的多兴趣深度召回模型在内容平台的探索和实践
作者 凌祎
编辑| 橙子君
出品| 阿里巴巴新零售淘系技术
基于内容推荐场景的发展,针对工业界主要召回算法的问题,提出CMDM 。
背景
随着电商场景和内容场景的快速发展,越来越多的融合场景开始出现。我们服务的场景是一个根植于电商场景下的内容消费场景,这样一个全新的内容推荐场景也给我们的推荐技术带来了全新的挑战。在我们的推荐场景中,我们将推荐系统拆分为经典的召回(Match)和排序(Rank)两个阶段(排序可进一步分为粗排、精排和重排)。其中召回阶段从海量的候选内容池中挑选出与用户兴趣相关的内容集合,排序阶段对该内容集合中的每一个内容依据业务目标进行打分,并根据打分结果进行排序截断,决定最终向用户展示的结果顺序。推荐算法的效果同时受到两个阶段的影响,其中召回作为推荐算法的第一个阶段,生产了排序的候选池,因此也决定了整个推荐算法的效果上限。
当前工业界的召回算法主要分为两类:基于协同过滤的召回(比如swing i2i)和基于深度学习的向量召回(比如deepmatch和MIND)。基于协同过滤的i2i召回从全局来看简单高效,依靠内容的共现性可以保证用户兴趣的相关性,同时借助实时trigger便于捕捉用户的实时兴趣,在召回算法中发挥着非常重要的作用。但是i2i召回本身也存在一些问题,比如对新用户和新商品不友好,难以解决冷启动问题;无法有效利用用户行为序列信息及内容side info信息,尤其像我们场景这样的存在异构行为序列的复杂场景。因此,在使用i2i召回保证基本效果的基础上,我们也大力探索了深度召回模型在逛逛场景的应用。目前业界主流的深度召回模型(如双塔,TDM [1],MIND [2],ComiRec [3])都是针对单一场景的召回,在我们这种全新的电商场景下的内容消费场景难以发挥最大的优势。为了解决上述问题,我们提出了基于异构序列融合的多兴趣深度召回模型CMDM (a cross-domain multi-interest deep matching network)。
问题分析
在探索深度召回模型在我们场景的应用过程中,我们发现目前业界主流的深度召回模型大都是针对单一场景的建模,比如淘宝猜你喜欢这种纯电商场景或者抖音、小红书这种纯内容消费场景。而随着内容电商概念的流行,无论是“电商内容化”还是“内容电商化”,都预示着在同一个app内的混合场景在未来将会成为新的主流推荐场景。在单一推荐场景下,深度召回模型只需要考虑用户在当前场景下的消费行为,通过序列建模技术提取用户兴趣进而与目标商品或内容进行匹配建模。而在电商和内容的混合场景下,深度召回模型需要同时考虑用户在内容场景内的内容消费行为和在电商场景内的商品消费行为,进行跨场景建模。为此,我们提出了CMDM多兴趣召回模型架构,能够对用户的跨场景异构行为序列进行融合建模,取得了显著的业务效果。
模型结构
本节重点介绍CMDM的模型结构,如图1所示。CMDM融合了两个场景的用户消费行为,分别是商品域场景和内容域场景,因此CMDM接收两个场景的用户点击行为序列作为输入,同时接收用户画像作为输入用于描述用户的基础特征。在CMDM中,我们设计了用于异构序列建模的层级注意力模块,通过层级注意力模块提取的多个用户兴趣向量与目标内容向量进行匹配建模。
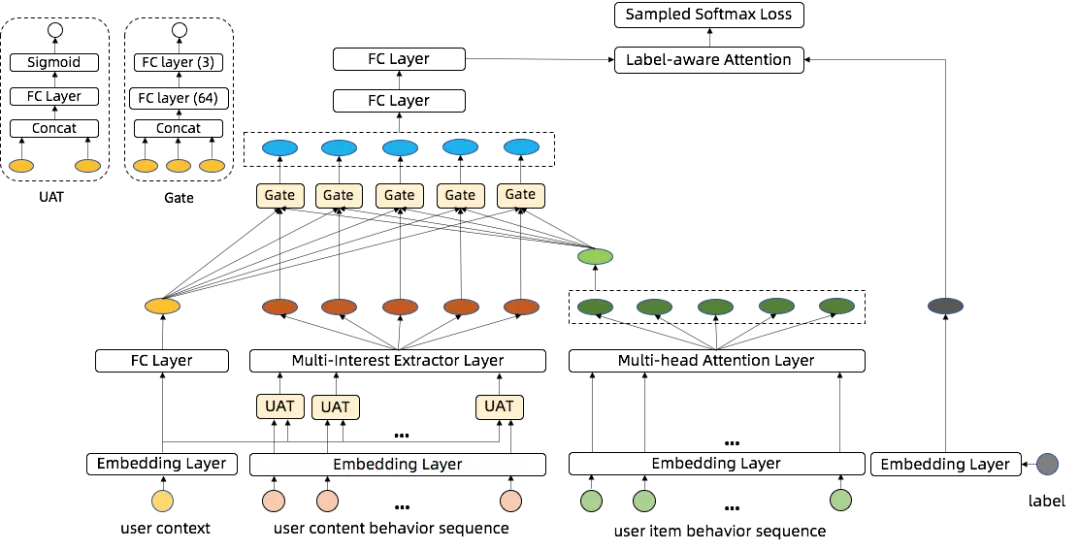
图1:CMDM: a Cross-domain Multi-Interest Deep Matching Network in Guangguang
▐ 层级注意力模块
为了更好地融合用户的内容行为序列和商品行为序列,我们设计了层级注意力机制。其中底层注意力机制可以聚焦到每个行为序列的内部,用于识别用户的兴趣,上层注意力机制负责行为序列特征间的融合。
- 底层注意力机制
我们对于内容行为序列和商品行为序列采用了不同的建模方式。对于内容行为序列,我们采用了MIND提出的动态路由(Dynamic Routing)算法来建模用户的多峰兴趣分布,因为与商品消费场景相似,用户在内容消费场景的浏览兴趣通常也会横跨多个类目,同时多兴趣召回对于提升内容场景的多样性等生态指标至关重要。与MIND不同的是,我们设计了UAT(user attention network)注意力机制,在内容进入动态路由进行聚类之前使用用户基础画像特征对内容行为序列进行attention,使得聚类出的多兴趣与用户更加匹配。对于商品行为序列,我们直接使用Transformer中的multi-head attention机制提取序列特征。我们对内容行为序列和商品行为序列区别对待的原因是内容行为序列是内容场景中的核心行为,刻画了用户的真实兴趣。而商品行为序列更多的是充当辅助内容序列学习的角色,因此需要一个能够完整提取用户商品域兴趣的建模方式。这里我们也尝试过使用动态路由方法对商品行为序列建模,发现效果不如multi-head attention机制。
- 上层注意力机制
我们需要融合两种用户行为序列内部生成的兴趣表征,这里我们通过attention机制设计了一种门控网络,用于融合用户的基础画像表征、内容兴趣表征和商品兴趣表征。这里的设计思想是不同的用户对于不同特征的依赖程度是不一样的。对于内容场景内的高活用户,场景内的内容消费行为应该发挥更关键的作用,而对于电商场景的高活用户同时是内容场景的低活用户,电商场景内的商品消费行为更为重要,最后对于两个场景的低活用户,用户基础特征可以起到一个基础的打底作用。门控网络的具体实现方式如图1,接收用户的基础画像表征、内容兴趣表征和商品兴趣表征作为输入,并为每种表征产出一个权重,最后三种表征加权合并成最终的用户兴趣表征。
▐ 模型训练
在抽取了多个用户兴趣之后, 我们使用MIND中采用的label-aware attention方式构建sampled softmax loss损失函数对多个兴趣向量进行学习,如公式(1)所示。在训练过程中,针对每个用户,在抽取出的多个兴趣中,根据每个兴趣与目标内容的相关性计算每个兴趣的权重,然后将多个兴趣加权平均进入到后续的训练。这里我们也尝试过hard attention方式,即只从用户的多个兴趣中挑出一个与其目标内容最接近的兴趣参与训练,但是这种方式会导致模型的马太效应较为严重,虽然效率上取得了提升,但是对内容场景的生态指标影响较大。因此在最终的线上模型中我们依然采用了soft attention方式。
(1)deepmatch_loss=exp(vuTei)∑k∈Nexp(vuTek),其中N代表负样本集合。目前业界主流的负样本采样方式是在整个内容侯选池随机负采样,这区别于精排模型的曝光未点击负采样,原因是深度召回模型面对的是整个内容侯选池,随机负采样可以让负样本尽量符合线上真实分布。但是使用随机采样得到的负样本,很多情况下跟用户是极不匹配的,导致训练出来的模型,只能学到粗粒度上的差异,无法感知更细微的差别。因此,除了随机负采样样本这种easy negative样本,我们还使用了hard negative样本,如公式(2)所示。选择hard negative样本时,我们尝试了两种方式:曝光未点击和召回未曝光。实验结果表名召回未曝光效果提升较为明显,而曝光�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E5%BC%82%E6%9E%84%E5%BA%8F%E5%88%97%E8%9E%8D%E5%90%88%E7%9A%84%E5%A4%9A%E5%85%B4%E8%B6%A3%E6%B7%B1%E5%BA%A6%E5%8F%AC%E5%9B%9E%E6%A8%A1%E5%9E%8B%E5%9C%A8%E5%86%85%E5%AE%B9%E5%B9%B3%E5%8F%B0%E7%9A%84%E6%8E%A2%E7%B4%A2%E5%92%8C%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


