干货携程推理性能的自动化优化实践
度假AI 携程技术 投稿
一、背景
近年来,人工智能逐渐在安防,教育,医疗和旅游等工业和生活场景中落地开花。在携程旅游业务上,AI技术同样广泛覆盖了多个旅游产品和旅游服务领域,携程度假AI研发根据旅游的特定场景和业务需求,将自然语言处理,机器翻译,计算机视觉,搜索排序等主流AI技术成功应用于旅游度假的多个业务线,例如自由行,跟团游,签证,玩乐和租车等。
从技术角度,为了适应不同的业务场景需求,涉及到多种AI技术,包括传统机器学习,卷积神经网络,Transformer等深度学习模型结构,以及知识图谱和图神经网络等技术领域。同时,为了充分挖掘AI技术的优势,模型设计复杂度日渐提升,包括模型深度,宽度以及结构复杂度等各个维度,计算量的增大使得AI推理性能瓶颈日益凸显,尤其是实时性的业务需求对推理速度要求更高。为了追求最佳推理性能,往往需要手动进行逐个优化,涉及的开发,部署和沟通成本都很高。主要问题集中在:
- 模型结构种类多,性能瓶颈差异较大,适用的优化方法各有不同,手动优化成本高;
- 优化方法众多,自上而下,涉及多种模型压缩方式,系统级,运行时优化等,手动优化门槛高;
- 逐个手动优化,可推广性差,技术覆盖面有限;
- 硬件平台的差异,需要针对性调优,导致优化的人力成本和部署成本都很高;
- 新模型的发布和迭代,需要应用优化方法,涉及较高的沟通和接入成本,同时带来了性能的不稳定性;
- 模型压缩技术对不同模型的优化效果有所差异,可能需要进行模型的再训练,训练和数据准备流程较长,效率低下;
因此,为了降低优化,部署和迭代成本,提高工作效率,并保证性能稳定,我们尝试搭建模型自动化优化平台,旨在为算法模型提供更全面易用,稳定性更好,使用和维护成本更低的优化解决方案。
二、优化平台的主要框架
从性能优化方法论的角度,无论是自动优化还是手动优化,主要关注以下两大方向:
- 降低算法复杂度:可通过调整或简化模型结构,或者保持结构不变,改进算法实现效率;
- 充分发挥软硬件性能:模型结构和算法不变,优化软件执行效率,使用硬件优势特征,最大化硬件执行效率;
围绕这两大优化方向以及人工智能的主流技术方向,优化平台的整体架构层自下而上可以划分为:
- 硬件平台和操作系统层,包含x86架构的CPU,GPU,ARM,FPGA等多种平台,操作系统主要是Linux OS;
- 引擎框架层,主要是Tensorflow,Pytorch等人工智能主流框架;
- 推理优化层,主要是由我们结合业务场景和实际需求进行自主研发的优化技术,包含高性能算子库,图优化和修改工具以及量化蒸馏等模型压缩模块;
- 算法模型:包含业界常用模型,例如以卷积为主要结构的CV模型,Resnet,GoogleNet,YOLO等;以Transformer为主要结构的NLP模型Bert,Albert等;
- 应用场景:主要体现在旅游场景中的实际应用,例如智能客服平台,机器翻译,搜索排序等应用。
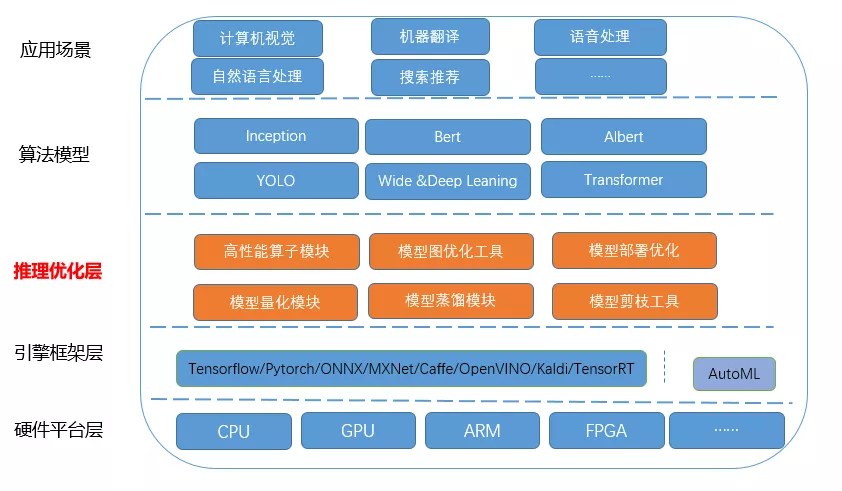
图1 模型平台的框架组成
三、自动化优化流程
优化平台的搭建能够系统有效地将优化技术整合起来,并快速应用于实际需求,但是如果不实现自动化优化,优化效率比较低,部署和迭代成本,沟通和接入成本高。因此我们建立了自动化优化流程,将所支持的优化技术涵盖在内,结合模型训练平台,数据标注平台,从模型设计,模型训练到模型推理优化,模型部署全链路,实现零介入无感知的优化效果,大大提升工作效率以及整体优化效果的稳定性。
图2所示为数据平台,模型训练平台,模型优化和部署的大概流程。具体有哪些优化手段,如何进行自动化实现的流程细节如图3所示。
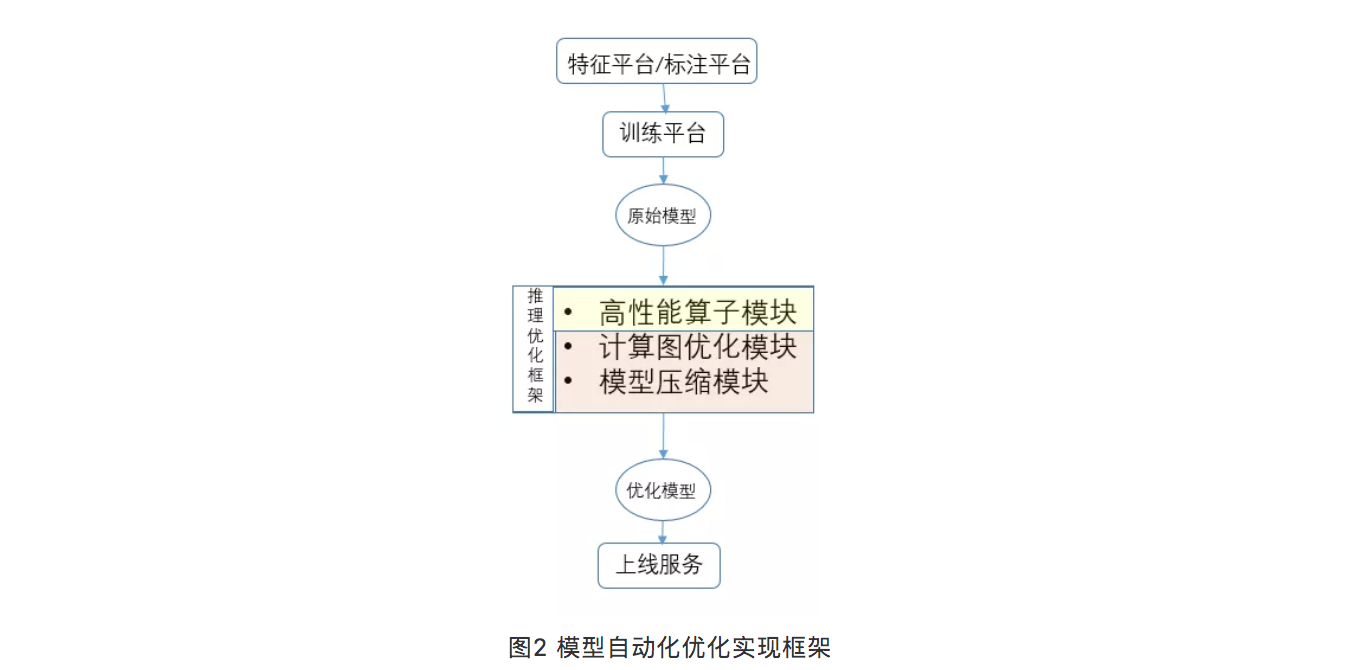
图2 模型自动化优化实现框架
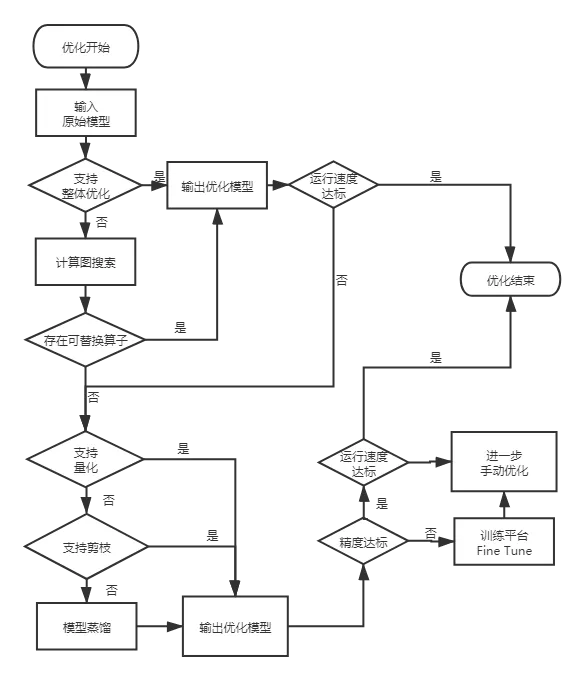
图3 自动优化实现的基本流程
四、功能模块
自动化优化平台的主要功能模块分四部分:
- 高性能算子库,包括算子重写,算子合并等多个优化,支持attention,softmax,Layer norm等多个常用算子;
- 计算图优化,主要进行计算图搜索,修改替换模型图结构,合并生成新的模型文件进行推理部署;同时包含常用的图优化和修改工具;
- 模型压缩模块,包括模型静态和动态量化,模型剪枝和蒸馏等;
- 模型部署优化,主要提供部署的优化方案,包括部署设计,运行时环境配置等。
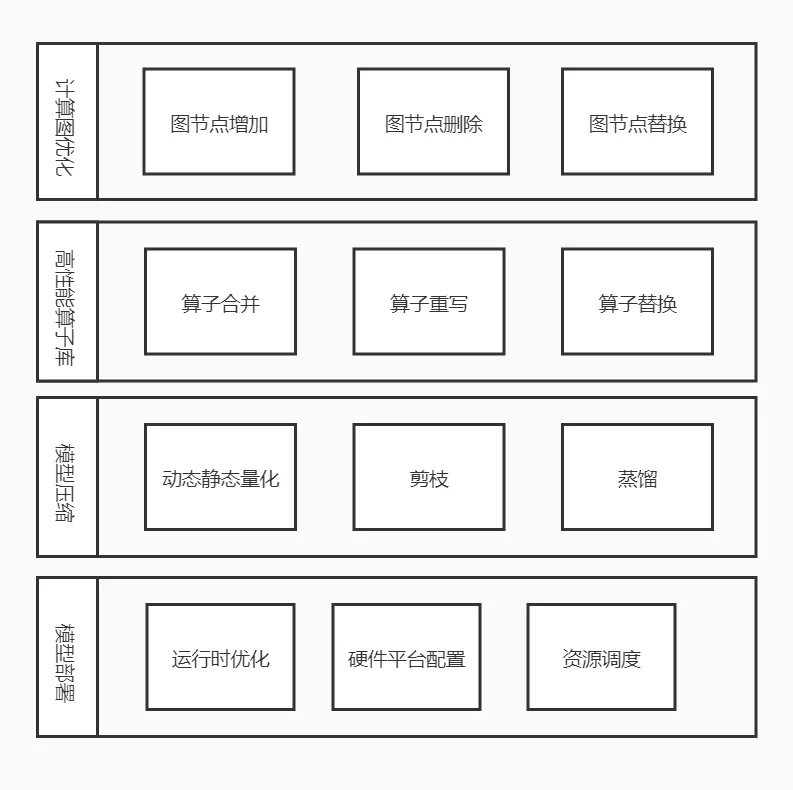
图4 模型优化平台基本模块
4.1 高性能算子库
该模块主要实现了常用的算子以及激活函数,包含基础算子,例如卷积,全连接层,batch norm,softmax等等以及合并后的经典的模型结构,例如transformer encoder,decoder等,基于tensorflow实现,采用c++实现,支持CPU和GPU平台的优化。
具体的优化方法涵盖了:
-
算法改进,例如卷积算法的实现,将im2col和winograd卷积相结合,针对不同卷积核大小自适应使用最佳算法,实现最快的速度;
-
内存重构,以BERT模型为例,最核心也是最耗时的计算模块之一就是多头自注意力机制multi-head self-attention,包含了大量的矩阵乘法计算,根据算法原理,包括query层,key层和value层的获取,query和key点乘等等,更重要的是当前的tensorflow算法实现包含了大量的行列变换操作(transpose),transpose带来大量的内存访问开销,这些问题可以通过内存重构来避免。
同时很多矩阵乘法实现可以通过批量矩阵乘法调用提升计算效率,从而带来运行速度的提升。如下图5所示,self-attention机制原始实现流程包含了三次冗余的transpose操作,T(a)表示张量a的transpose形式。通过对内存重构可以避免这三次transpose操作。如图6所示,优化后的计算流程不包含transpose。
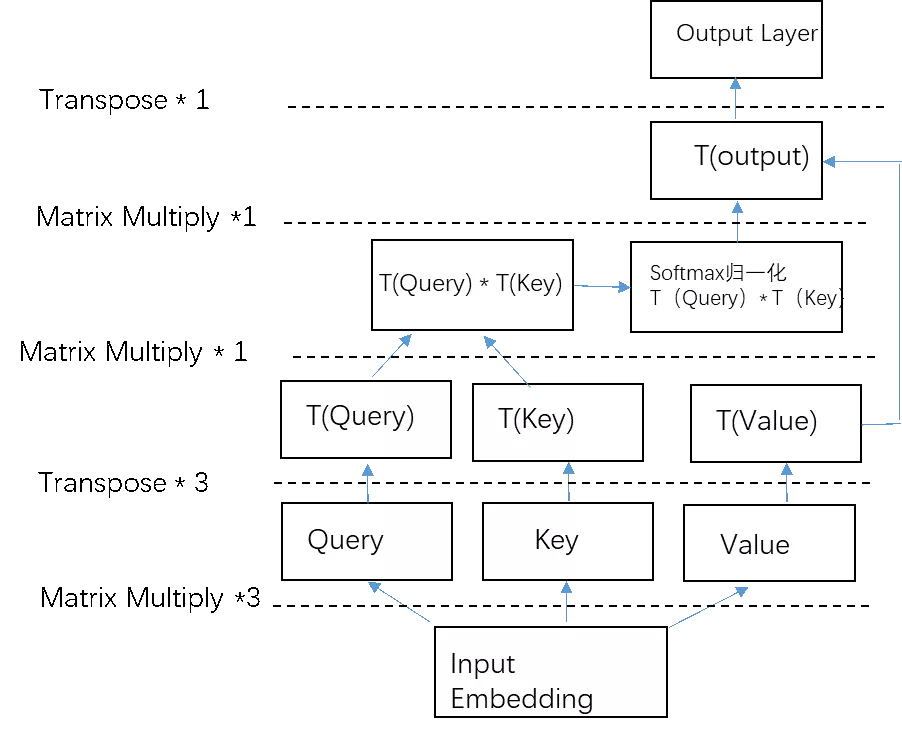
图5 Self-attention原始实现流程
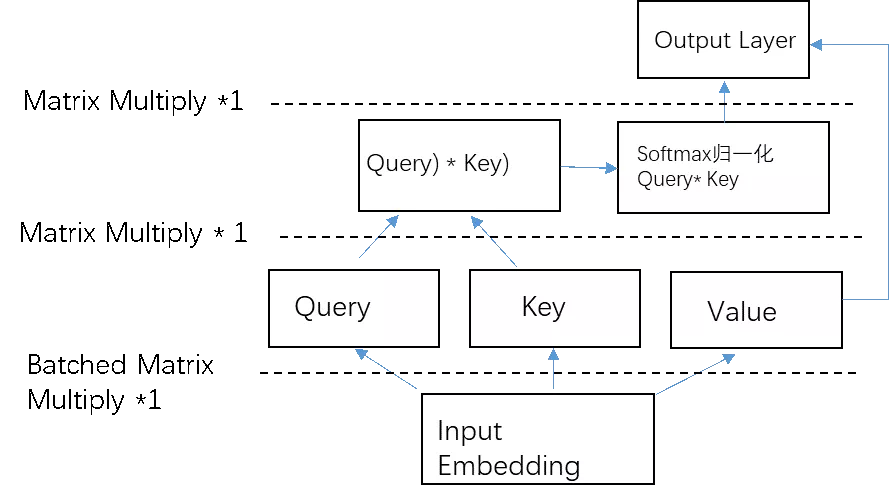
图6 self-attention优化后实现流程
二者对比,可以明显看出,优化后减少了4次transpose操作,也就是减少了内存访问的开销,同时对于矩阵乘法,调用批量矩阵乘法替代单个矩阵乘法操作,效率更高。
- Intrinsic指令集优化,例如在CPU平台使用合适的向量化指令AVX512以及专门针对AI的VNNI指令等;
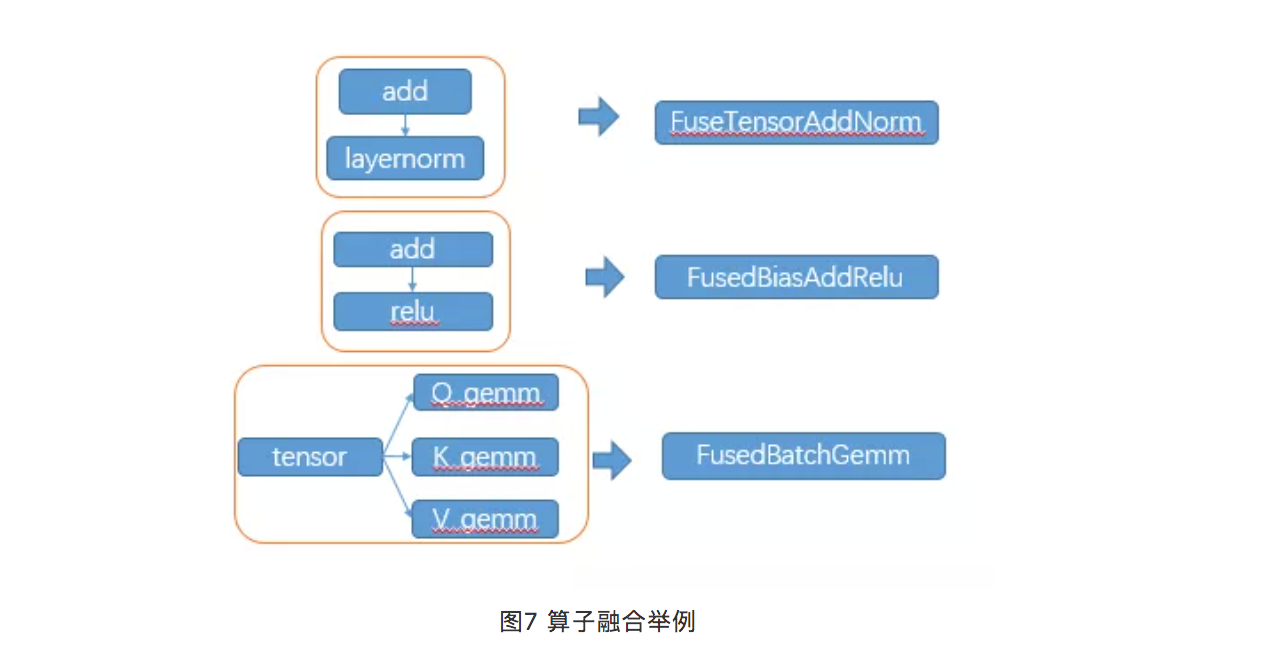
- 算子融合,以transformer为例,每一层包含大量的零散算子,包括self-Attention,GELU激活函数,归一化Layer Normalization算子等多个零散算子,为了减少数据访问开销,将多个算子进行融合,实现新的GPU kernel。通过算子合并,算子数量减少约90%,模型涉及内存搬移的操作去除率100%,90%的时间集中在核心计算的kernel launcher。如图7所示。
4.2 模型压缩
模型压缩是提升推理性能的另一个有效手段,主要是指在算法层面上的模型优化,保证精度的前提下,通过合理的降低模型结构或者参数量,从而实现减少整个模型计算量的目的。
模型压缩的主要作用有:
- 简化模型结构,降低计算复杂度,提升推理速度
- 减少模型参数和模型尺寸,降低对内存的占用;
宏观上来讲,当前的优化平台支持的模型压缩方法有模型蒸馏,模型剪枝,低精度量化等。
4.2.1 模型蒸馏
模型蒸馏采用的是迁移学习,通过预先训练好的复杂模型(Teacher model)的输出作为监督信号去训练另外一个简单的学生网络(Student Model),从而实现对模型的简化,减少模型参数。模型蒸馏普遍性很强,可有效提升小模型准确率,但是调参相对困难,主要的核心的问题包括,如何选择特征层如何设计损失函数,学生模型的设计和数据集的选择等等。图8是我们压缩框架中实现的对Transformer的decoder模型的蒸馏实现。
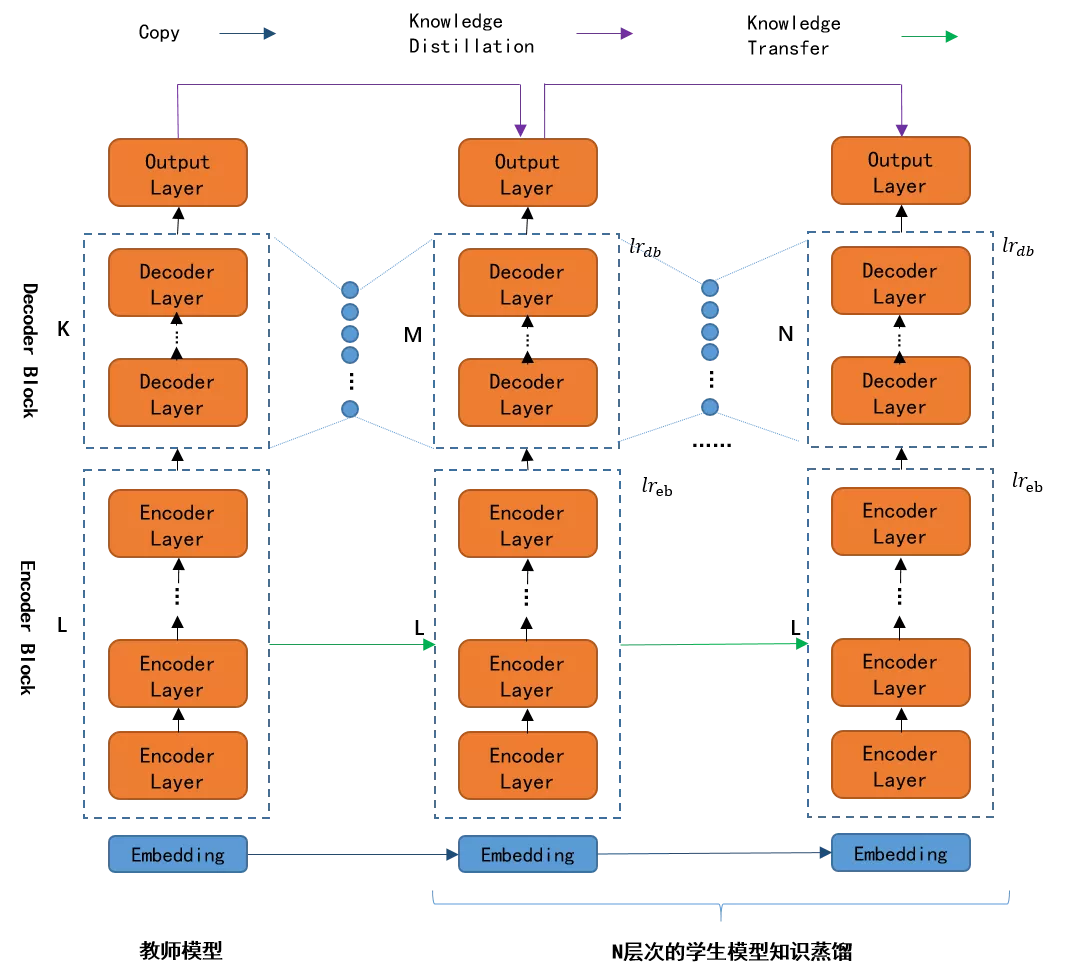
图8 Transformer模型蒸馏
总损失函数构成:
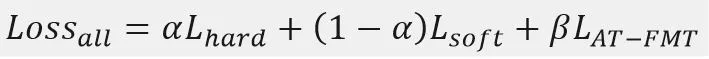
其中α和β分别表示相应的损失值权重系数,α∈(0,1],β∈R,Lsoft是 Teacher网络的输出与Student网络模型输出的损失值,Lhard - 训练数据语料真实标签与Student网络模型输出的损失值,LAT_FMT - Teacher和Student网络模型的Decoder 的中间输出内容损失值,采用逐级分层蒸馏的方法,最终推理速度加速比达到2倍,精度损失BLEU值在可接受范围内(4%)。
4.2.2 低精度量化
低精度量化更多是从计算机硬件的设计角度,修改数据类型,降低数据精度,从而进行加速,依赖于硬件实现。量化的方式也包含多种,训练后量化(PTQ post training quantization),训练时量化(QAT,quantization aware traning)等。
目前我们优化平台支持float16和int8,其中int8量化只支持PTQ方式,一般情况下,为了保证模型精度,采用int8量化需要对量化后的模型校准,校准方式实现依赖于复杂的数学算法,目前较常用的是KL散度,对于CV模型,精度损失可接受。对于基于Transformer的NLP模型,精度损失较大,我们目前只支持GPU平台的float16实现。相比于float32,存储空间和带宽减半,精度几乎无损失,吞吐提升可达3倍。
4.2.3 模型剪枝
剪枝的主要思想是将权重矩阵中相对“不重要”的权值剔除,然后再对网络进行微调;方法简单,压缩效果可控,但是在剪枝粒度和方法选择需要认为定义规则,而且非结构化的剪枝效果需要依赖于硬件平台实现。模型剪枝在计算机视觉领域广泛使用,并取得了不错的效果。
图9举例实现了一种典型的结构化剪枝的方法[4]。我们针对CV模型,在原始模型中加入batch_normal层,对batch_normal的参考论文2:ChannelPruning for Accelerating Very Deep Neural Networks论文中提出利用channel进行剪枝,实验如下:在超分辨率的实验中,考虑在原始模型中加入batch_normal层,然后对batch_nomal的α值做正则化,最后利用该值作为依据进行剪枝,对训练好的模型中的batch_normal层的参数α进行分析,针对不同的卷积模型应用同样的方式,发现有些模型有近一半的参数在1e-5数量级,此外同一层中的分布方差极小,据此对模型进行通道级别的剪枝并进行fine tune训练,剪枝效果明显,模型大小减少到原来的1/4,精度不变的前提下,加速比可达4倍。而对于yolov3模型,大部分参数差异不大(MAP降低2%),可剪掉的有限,所以为了保持精度,参数量减半,加速比1.5x左右。
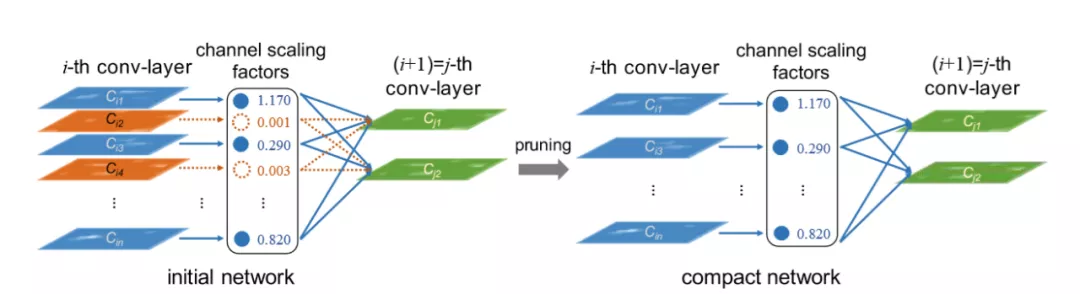
图9 模型剪枝实例
4.3 接口设计
模型优化平台采用即插即用的模块化设计,可无缝对接模型训练平台,模型发布平台等。
- 训练平台的调用和反馈:无缝对接训练平台,python接口调用或者web服务接口;如果需要重新训练,向训练平台申请接口;
- 优化结果的接口提供:支持*.pb格式的模型输出;
具体使用方式如图10和图11所示。
图10 高性能算子库的调用
图11给出了模型压缩模块的调用方式。
图11 模型压缩模块调用
五、优化成果
以实际应用机器翻译的Transformer模型为例,所测试平台为CPU: Intel(R) Xeon(R) Silver 4210CPU @ 2.20GHz; GPU:Nvidia T4,以固定算例的平均响应延迟为测试数据,优化后和优化前的加速比如下图12所示。
其中,原始性能基于tensorflow1.14为测试基准,在GPU平台框架层优化和编译运行时等多层优化实现,图13是Transformer翻译模型基于T4平台使用模型压缩和高性能算子库优化之后的对比结果,图中给出的是token长度为64,不同batch大小时的延迟和吞吐提升比例,实际中token越大,float16的优势越明显。
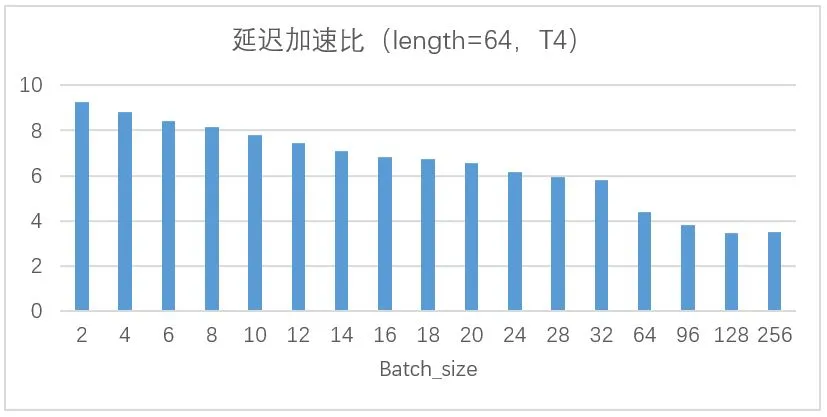
图12
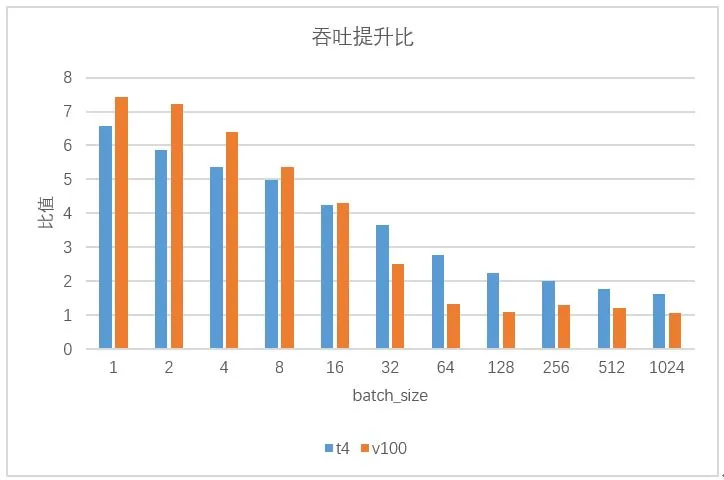
图13
基于CPU硬件平台,针对CV和NLP模型(例如yolov3,bert和albert等),也取得了不错的优化效果,延迟加速比最高达到5倍以上。
六、未来展望
AI优化的潜力和需求很大,因为AI理论和模型的日益完善,应用场景对模型精度等推理服务质量的更高要求,必然使得模型结构和计算复杂度越来越高,对推理服务的性能需求只会有增无减。从成本和效率多个角度考虑,自动优化是必然趋势,并且业界也都陆续开展了相关研究,取得了一些进展。
依旧从两方面来看,同样是基于自动化优化这个大方向,算子优化等系统级优化最终都会通过tvm等AI编译器实现,而模型压缩则侧重于使用AutoML的思想,基于当前平台和实际需求,通过结构搜索找到符合要求的最简化的网络。当然,当前的蒸馏,剪枝等传统压缩方法也可以跟AutoML的思想相结合,同样能够高效地实现压缩效果。
因此,我们的自动化优化平台也正是基于自动化优化的思路,综合考虑业务场景需求,参考业界更先进的优化技术,为旅游场景的AI模型带来更加高效的优化方案,推动AI技术在旅游业务更好落地。
参考文献:
[1].Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural languageunderstanding[J]. arXiv preprint arXiv:1909.10351, 2019.
[2].Sun S, Cheng Y, Gan Z, et al. Patient knowledge distillation for bert modelcompression[J]. arXiv preprint arXiv:1908.09355, 2019.
[3]. https://on-demand.gputechconf.com/gtc-cn/2019/pdf/CN9432/presentation.pdf
[4].Zhuang Liu, Jianguo Li, Zhiqiang Shen, GaoHuang, Shoumeng Yan, Changshui Zhang; Learning Efficient Convolutional Networksthrough Network Slimming ,Proceedings of the IEEE International Conference onComputer Vision (ICCV), 2017, pp. 2736-2744
[5] AshishVaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan NGomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXivpreprint arXiv:1706.03762, 2017.
[6]Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectionaltransformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018.
团队招聘信息
我们是携程度假AI研发团队,致力于为携程旅游事业部提供丰富的AI技术产品及优化工作,持续优化用户体验,提升效率。
在度假AI研发,你可以学习行业内前沿的AI算法知识,从算法到建模,到优化加速,到落地应用,经历完整的AI研发流程,同时为全球旅行者带来更好的旅游服务体验。
如果你热爱技术,并渴望不断进步,度假AI研发团队期待与你一同前行。目前我们有语音算法工程
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B2%E8%B4%A7%E6%90%BA%E7%A8%8B%E6%8E%A8%E7%90%86%E6%80%A7%E8%83%BD%E7%9A%84%E8%87%AA%E5%8A%A8%E5%8C%96%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


