年月初深圳图像算法工程师面试题分享
问题一:Batch-norm作用和参数
batch norm的作用
-
batch norm对于输入数据做了零均值化和方差归一化过程,方便了下一层网络的训练过程,从而加速了网络的学习。不同batch的数据,由于加入了batch
norm,中间层的表现会更加稳定,输出值不会偏移太多。各层之间受之前层的影响降低,各层之间比较独立,有助于加速网络的学习。梯度爆炸和梯度消失现象也得到了一些缓解(我自己加上去的)。
-
batch norm利用的是mini-batch上的均值和方差来做的缩放,但是不同的mini-batch上面的数据是有波动的,相当于给整个模型引入了一些噪音,从而相当于有了一些正则化的效果,从而提升表现。
测试时的batch norm在训练过程中,y,b参数和w相似,直接利用梯度值乘以学习率,更新值就好了。需要注意的是,batch norm中的z的均值和方差都是通过每一个mini-batch上的训练数据得到的。在测试过程中,不能通过单独样本的数据计算均值和方差,我们可以通过让训练过程中的每一个mini-batch的均值和方差数据,计算指数加权平均,从而得到完整样本的均值和方差的一个估计。在测试过程中,使用该值作为均值和方差,从而完成计算。
问题二:L1/L2的区别和作用
L1/L2的区别
- L1是模型各个参数的绝对值之和。
- L2是模型各个参数的平方和的开方值。
L1会趋向于产生少量的特征,而其他的特征都是0。
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0。
L1的作用是为了矩阵稀疏化。假设的是模型的参数取值满足拉普拉斯分布。
L2的作用是为了使模型更平滑,得到更好的泛化能力。假设的是参数是满足高斯分布。
问题三:模型的加速与压缩
深度学习模型压缩与加速是指利用神经网络参数和结构的冗余性精简模型,在不影响任务完成度的情况下,得到参数量更少、结构更精简的模型。被压缩后的模型对计算资源和内存的需求更小,相比原始模型能满足更广泛的应用需求。(事实上,压缩和加速是有区别的,压缩侧重于减少网络参数量,加速侧重于降低计算复杂度、提升并行能力等,压缩未必一定能加速)
主流的压缩与加速技术有4种:结构优化、剪枝(Pruning)、量化(Quantization)、知识蒸馏(Knowledge Distillation)。
问题四:两个链表存在交叉结点,怎么判断交叉点
该题为leetcode160——相交链表
- 方法一:暴力解法
对于A中的每一个结点,我们都遍历一次链表B查找是否存在重复结点,第一个查找到的即第一个公共结点。
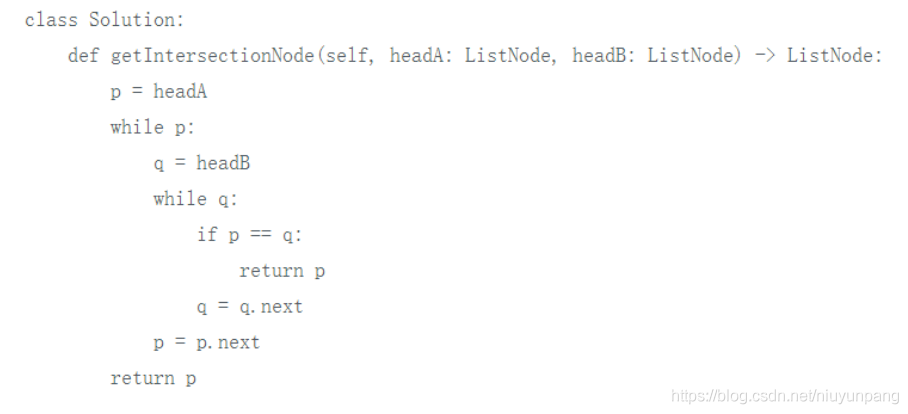
时间复杂度:O(n^2)
空间复杂度:O(1)
无法通过,会超时。
- 方法二:
对暴力解法的一个优化方案是:先将其中一个链表存到哈希表中,此时再遍历另外一个链表查找重复结点只需 O(n) 时间。
代码如下:

时间复杂度:O(n)
空间复杂度:O(n)
- 方法三:走过彼此的路
利用两链表长度和相等的性质来使得两个遍历指针同步。
具体做法是:让两指针同时开始遍历,遍历到结尾的时候,跳到对方的头指针,如果有公共结点,则,�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E6%9C%88%E5%88%9D%E6%B7%B1%E5%9C%B3%E5%9B%BE%E5%83%8F%E7%AE%97%E6%B3%95%E5%B7%A5%E7%A8%8B%E5%B8%88%E9%9D%A2%E8%AF%95%E9%A2%98%E5%88%86%E4%BA%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


