年月底字节跳动岗位抖音面试题分享
问题1:Bert模型中,根号dk的作用
QK进行点击之后,值之间的方差会较大,也就是大小差距会较大;如果直接通过Softmax操作,会导致大的更大,小的更小;进行缩放,会使参数更平滑,训练效果更好。
问题2:Bert模型中多头的作用
多次attention综合的结果至少能够起到增强模型的作用,也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
文末免费送电子书:七月在线干货组最新 升级的《2021最新大厂AI面试题》免费送
问题3:BPE的了解
BPE与Wordpiece都是首先初始化一个小词表,再根据一定准则将不同的子词合并。词表由小变大
BPE与Wordpiece的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
问题4:mask策略和改进
从bert最开始的mask token 到后面ernie的 mask entity以及还有mask n-gram,动态mask等等。
问题5:Bert模型中激活函数GELU
GELU函数是RELU函数的变种,形式如下:
问题6:部分激活函数的公式及求导
常见的激活函数有:Sigmoid、Tanh、ReLU
Sigmoid函数:
求导:
特点︰它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
缺点:
缺点1:在深度神经网络中梯度反向传递时导致梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
缺点2:Sigmoid 的output不是0均值(即zero-centered)。
缺点3:其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
Tanh函数:
求导:
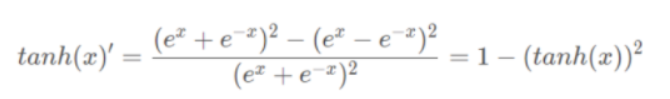
**特点︰**它解决了Sigmoid函数的不是zero-centered输出问题,收敛速度比sigmoid要快,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
ReLU函数︰
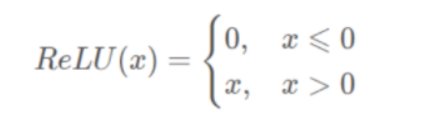
求导:
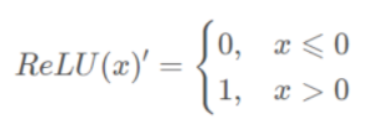
特点︰
1、ReLu函数是利用阈值来进行因变量的输出,因此其计算复杂度会比剩下两个函数低(后两个函数都是进行指数运算)
2、ReLu函数的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
3、ReLU的单侧抑制提供了网络的稀疏表达能力。
问题7:最短矩阵路径和
该题为leetcode第64题
思路︰动态规划
由于路径的方向只能是向下或向右,因此网格的第一行的每个元素只能从左上角元素开始向右移动到达,网格的第一列的每个元素只能从左上角元素开始向下移动到达,此时的路径是唯一的,因此每个元素对应的最小路径和即为对应的路径上的数字总和。
对于不在第一行和第一列的元素,可以从其上方相邻元素向下移动一步到达,或者从其左方相邻元素向右移动一步到达,元素对应的最小路径和等于其上方相邻元素与其左方相邻元素两者对应的最小路径和中�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E6%9C%88%E5%BA%95%E5%AD%97%E8%8A%82%E8%B7%B3%E5%8A%A8%E5%B2%97%E4%BD%8D%E6%8A%96%E9%9F%B3%E9%9D%A2%E8%AF%95%E9%A2%98%E5%88%86%E4%BA%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


