年月算法工程师道面试题分享
问题1:逻辑回归和SVM的异同
LR与SVM的相同点:
- 都是有监督的分类算法;
- 如果不考虑核函数,LR和SVM都是线性分类算法。
- 它们的分类决策面都是线性的。
- LR和SVM都是判别式模型。
LR与SVM的不同点:
- 本质上是loss函数不同,或者说分类的原理不同。
- SVM是结构风险最小化,LR则是经验风险最小化。
- SVM只考虑分界面附近的少数点,而LR则考虑所有点。
- 在解决非线性问题时,SVM可采用核函数的机制,而LR通常不采用核函数的方法。
- SVM计算复杂,但效果比LR好,适合小数据集;LR计算简单,适合大数据集,可以在线训练。
文末免费送电子书:七月在线干货组最新 升级的《2021最新大厂AI面试题》免费送!
问题2:LR的参数可以初始化0 吗?
可以。
在逻辑回归中,
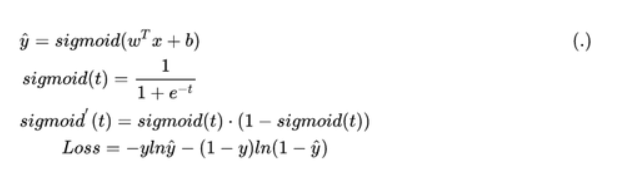
因此在LR的反向传播中,我们假设w=[w1,w2]Tw=[w_1,w_2]^Tw=[w1,w2]T,则

而
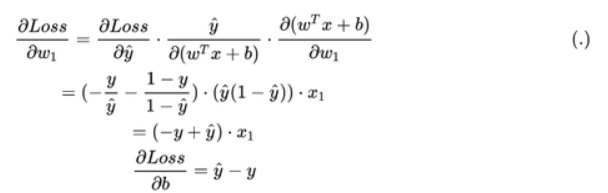
因而

可以看出,就算初始w1,w2,bw_1,w_2,bw1,w2,b设为0,后续梯度还是会更新的。
问题3:CNN中[1,1]卷积核的作用
- 实现跨通道的交互和信息整合
- 进行卷积核通道数的降维和升维
- 对于单通道feature map 用单核卷积即为乘以一个参数,而一般情况都是多核卷积多通道,实现多个feature map的线性组合
- 可以实现与全连接层等价的效果。如在faster-rcnn中用1x1xm的卷积核卷积n(如512)个特征图的每一个位置(像素点),其实对于每一个位置的1x1卷积本质上都是对该位置上n个通道组成的n维vector的全连接操作。
问题4:详细介绍下Batch Normolization
BN(Batch Normolization)是Google提出的用于解决深度网络梯度消失和梯度爆炸的问题,可以起到一定的正则化作用。我们来说一下它的原理:
批规范化,即在模型每次随机梯度下降训练时,通过mini-batch来对每一层卷积的输出做规范化操作,使得结果(各个维度)的均值为0,方差为1。
BN操作共分为四步。输入为xix_ixi,第一步计算均值:

第二步计算数据方差:

第三步进行规范化:

第四步尺度变换和偏移:

mmm表示mini-batch中的数据个数,可以看出,BN实际就是对网络的每一层都进行白化操作。白化操作是线性的,最后的“尺度变换和偏移”操作是为了让BN能够在线性和非线性之间做一个权衡,而这个偏移的参数γ\gammaγ和 β\betaβ 是神经网络在训练时学出来的
经过BN操作,网络每一层的输出小值被“拉大”,大值被“缩小”,所以就有效避免了梯度消失和梯度爆炸。总而言之,BN是一个可学习、有参数(γ、β)的网络层。
问题5:ROC与AUC
AUC是一种模型分类指标,且仅仅是二分类模型的评价指标。AUC是Area Under Curve的简称,那么Curve就是 ROC(Receiver Operating Characteristic),翻译为"接受者操作特性曲线"。也就是说ROC是一条曲线,AUC是 一个面积值。
七月【图像分类与图像搜�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E6%9C%88%E7%AE%97%E6%B3%95%E5%B7%A5%E7%A8%8B%E5%B8%88%E9%81%93%E9%9D%A2%E8%AF%95%E9%A2%98%E5%88%86%E4%BA%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


