年迭代次抖音基于的实时推荐系统演进历程
以下文章来源于InfoQ ,作者郭文飞
摘要: 本文基于字节跳动推荐系统基础服务方向负责人郭文飞在 5 月 22 日 Apache Flink Meetup 分享的《Flink 在字节跳动推荐特征体系中的落地实践》整理
2021 年,字节跳动旗下产品总 MAU 已超过 19 亿。在以抖音、今日头条、西瓜视频等为代表的产品业务背景下,强大的推荐系统显得尤为重要。Flink 提供了非常强大的 SQL 模块和有状态计算模块。目前在字节推荐场景,实时简单计数特征、窗口计数特征、序列特征已经完全迁移到 Flink SQL 方案上。结合 Flink SQL 和 Flink 有状态计算能力,我们正在构建下一代通用的基础特征计算统一架构,期望可以高效支持常用有状态、无状态基础特征的生产。
一、业务场景
对于今日头条、抖音、西瓜视频等字节跳动旗下产品,基于 Feed 流和短时效的推荐是核心业务场景。而推荐系统最基础的燃料是特征,高效生产基础特征对业务推荐系统的迭代至关重要。
1. 主要业务场景

- 抖音、火山短视频等为代表的短视频应用推荐场景,例如 Feed 流推荐、关注、社交、同城等各个场景,整体在国内大概有 6 亿 + 规模 DAU;
- 头条、西瓜等为代表的 Feed 信息流推荐场景,例如 Feed 流、关注、子频道等各个场景,整体在国内有数亿规模 DAU;
2. 业务痛点和挑战

目前字节跳动推荐场景基础特征的生产现状是“百花齐放”。离线特征计算的基本模式都是通过消费 Kafka、BMQ、Hive、HDFS、Abase、RPC 等数据源,基于 Spark、Flink 计算引擎实现特征的计算,而后把特征的结果写入在线、离线存储。各种不同类型的基础特征计算散落在不同的服务中,缺乏业务抽象,带来了较大的运维成本和稳定性问题。
而更重要的是,缺乏统一的基础特征生产平台,使业务特征开发迭代速度和维护存在诸多不便。如业务方需自行维护大量离线任务、特征生产链路缺乏监控、无法满足不断发展的业务需求等。
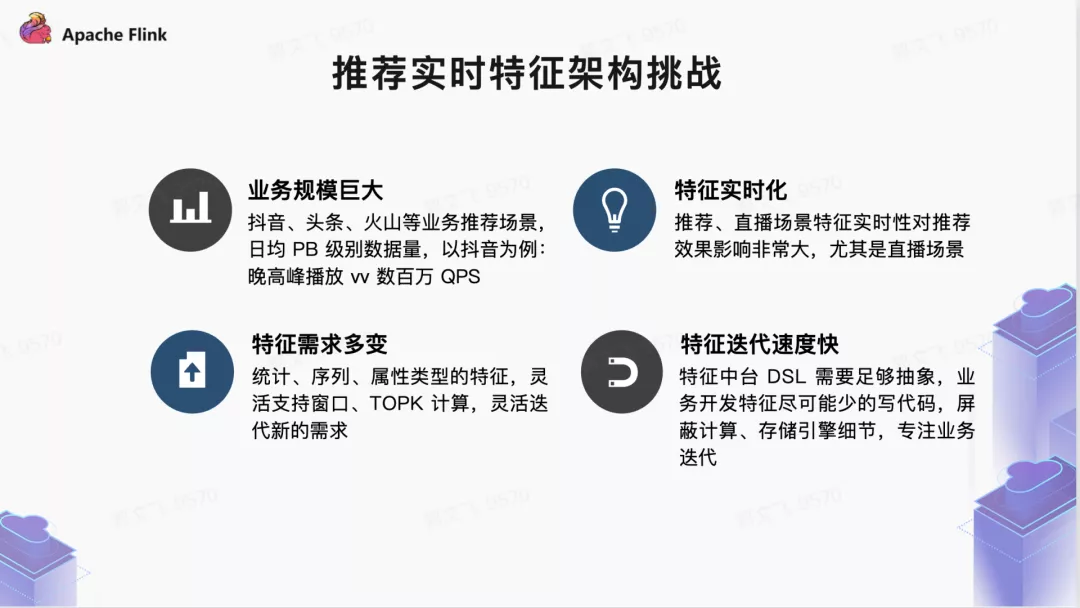
在字节的业务规模下,构建统一的实时特征生产系统面临着较大挑战,主要来自四个方面:
- 巨大的业务规模: 抖音、头条、西瓜、火山等产品的数据规模可达到日均 PB 级别。例如在抖音场景下,晚高峰 Feed 播放量达数百万 QPS,客户端上报用户行为数据高达数千万 IOPS。业务方期望在任何时候,特征任务都可以做到不断流、消费没有 lag 等,这就要求特征生产具备非常高的稳定性。
- 较高的特征实时化要求: 在以直播、电商、短视频为代表的推荐场景下,为保证推荐效果,实时特征离线生产的时效性需实现常态稳定于分钟级别。
- 更好的扩展性和灵活性: 随着业务场景不断复杂,特征需求更为灵活多变。从统计、序列、属性类型的特征生产,到需要灵活支持窗口特征、多维特征等,业务方需要特征中台能够支持逐渐衍生而来的新特征类型和需求。
- 业务迭代速度快: 特征中台提供的面向业务的 DSL 需要足够场景,特征生产链路尽量让业务少写代码,底层的计算引擎、存储引擎对业务完全透明,彻底释放业务计算、存储选型、调优的负担,彻底实现实时基础特征的规模化生产,不断提升特征生产力;
3. 迭代演进过程
在字节业务爆发式增长的过程中,为了满足各式各样的业务特征的需求,推荐场景衍生出了众多特征服务。这些服务在特定的业务场景和历史条件下较好支持了业务快速发展,大体的历程如下:
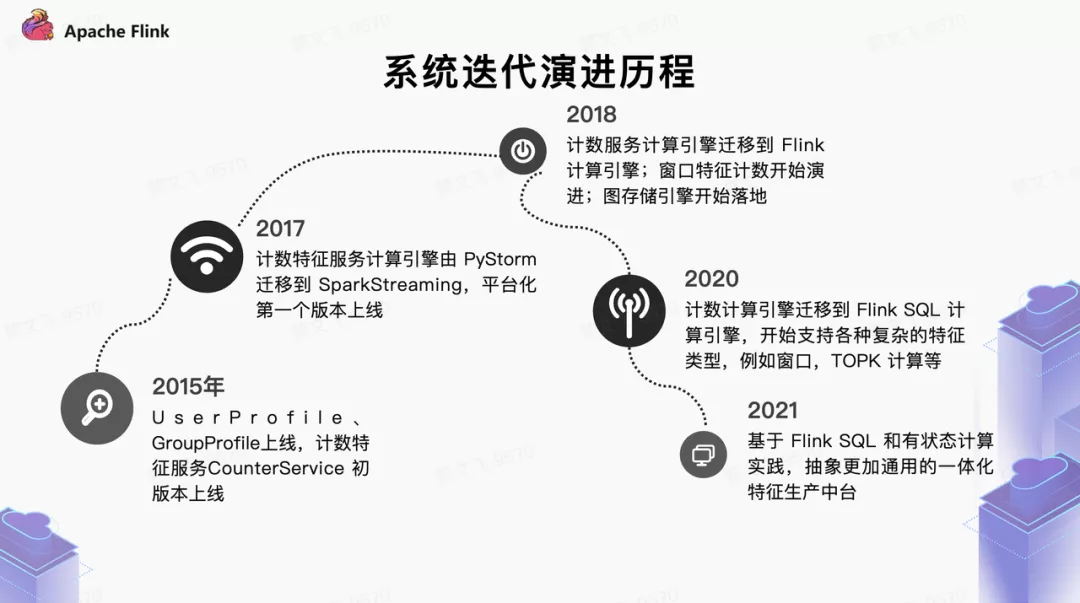
在这其中 2020 年初是一个重要节点,我们开始在特征生产中引入 Flink SQL、Flink State 技术体系,逐步在计数特征系统、模型训练的样本拼接、窗口特征等场景进行落地,探索出新一代特征生产方案的思路。
二、新一代系统架构
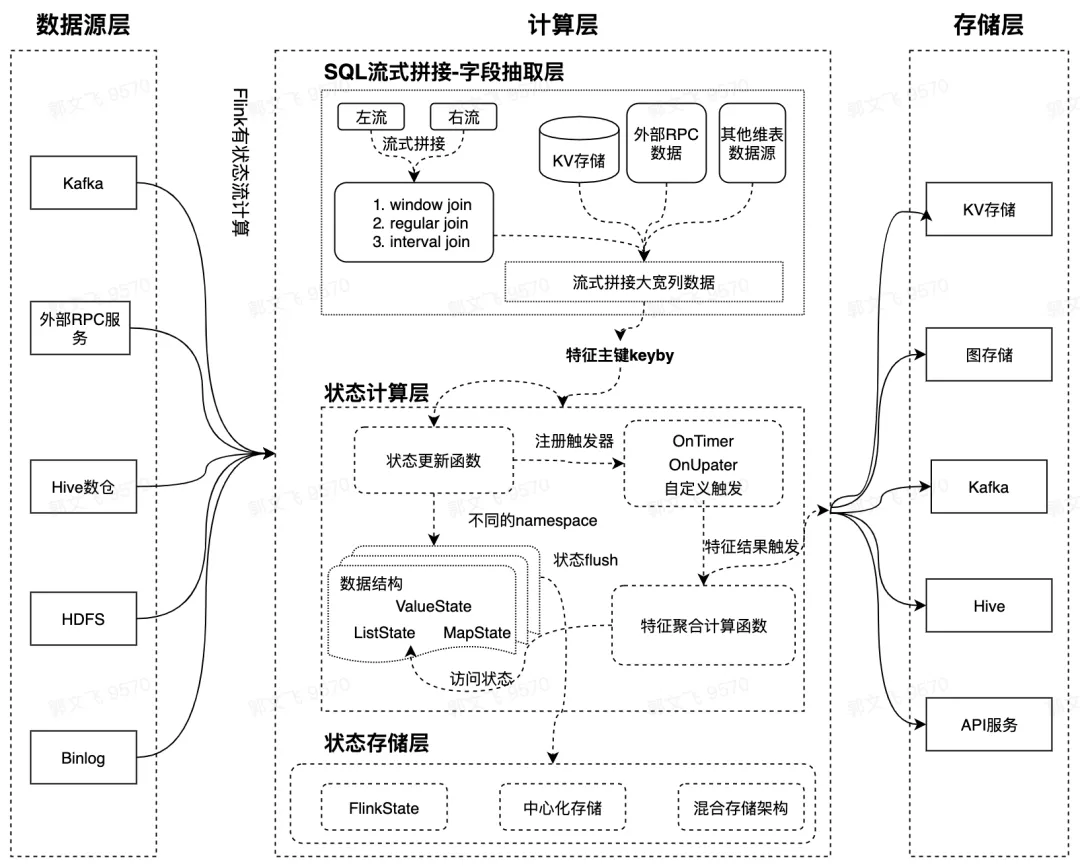
结合上述业务背景,我们基于 Flink SQL 和 Flink 有状态计算能力重新设计了新一代实时特征计算方案。新方案的定位是:解决基础特征的计算和在线 Serving,提供更加抽象的基础特征业务层 DSL。在计算层,我们基于 Flink SQL 灵活的数据处理表达能力,以及 Flink State 状态存储和计算能力等技术,支持各种复杂的窗口计算。极大地缩短业务基础特征的生产周期,提升特征产出链路的稳定性。新的架构里,我们将特征生产的链路分为数据源抽取 / 拼接、状态存储、计算三个阶段,Flink SQL 完成特征数据的抽取和流式拼接,Flink State 完成特征计算的中间状态存储。
有状态特征是非常重要的一类特征,其中最常用的就是带有各种窗口的特征,例如统计最近 5 分钟视频的播放 VV 等。对于窗口类型的特征在字节内部有一些基于存储引擎的方案,整体思路是 “轻离线重在线” ,即把窗口状态存储、特征聚合计算全部放在存储层和在线完成。离线数据流负责基本数据过滤和写入,离线明细数据按照时间切分聚合存储(类似于 micro batch),底层的存储大部分是 KV 存储、或者专门优化的存储引擎,在线层完成复杂的窗口聚合计算逻辑,每个请求来了之后在线层拉取存储层的明细数据做聚合计算。
我们新的解决思路是 “轻在线重离线” ,即把比较重的时间切片明细数据状态存储和窗口聚合计算全部放在离线层。窗口结果聚合通过离线窗口触发机制完成,把特征结果推到在线 KV 存储。在线模块非常轻量级,只负责简单的在线 serving,极大地简化了在线层的架构复杂度。在离线状态存储层。我们主要依赖 Flink 提供的原生状态存储引擎 RocksDB,充分利用离线计算集群本地的 SSD 磁盘资源,极大减轻在线 KV 存储的资源压力。
对于长窗口的特征(7 天以上窗口特征),由于涉及 Flink 状态层明细数据的回溯过程,Flink Embedded 状态存储引擎没有提供特别好的外部数据回灌机制(或者说不适合做)。因此对于这种 “状态冷启动” 场景,我们引入了中心化存储作为底层状态存储层的存储介质,整体是 Hybrid 架构。例如 7 天以内的状态存储在本地 SSD,7~30 天状态存储到中心化的存储引擎,离线数据回溯可以非常方便的写入中心化存储。
除窗口特征外,这套机制同样适用于其他类型的有状态特征(如序列类型的特征)。
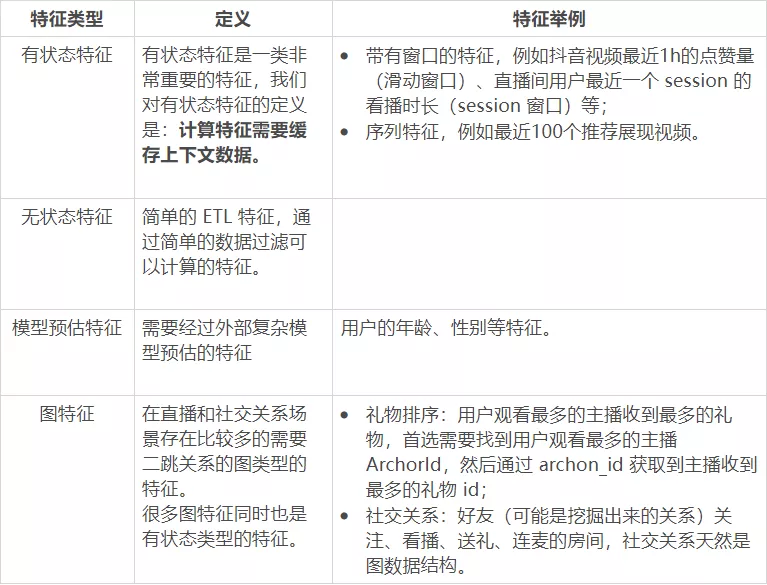
1. 实时特征分类体系
2. 整体架构
带有窗口的特征,例如抖音视频最近 1h 的点赞量(滑动窗口)、直播间用户最近一个 session 的看播时长(session 窗口)等;
■ 2.1 数据源层
在新的一体化特征架构中,我们统一把各种类型数据源抽象为 Schema Table,这是因为底层依赖的 Flink SQL 计算引擎层对数据源提供了非常友好的 Table Format 抽象。在推荐场景,依赖的数据源非常多样,每个特征上游依赖一个或者多个数据源。数据源可以是 Kafka、RMQ、KV 存储、RPC 服务。对于多个数据源,支持数据源流式、批式拼接,拼接类型包括 Window Join 和基于 key 粒度的 Window Union Join,维表 Join 支持 Abase、RPC、HIVE 等。具体每种类型的拼接逻辑如下:

三种类型的 Join 和 Union 可以组合使用,实现复杂的多数据流拼接。例如 (A union B) Window Join (C Lookup Join D)。

另外,Flink SQL 支持复杂字段的计算能力,也就是业务方可以基于数据源定义的 TableSchema 基础字段实现扩展字段的计算。业务计算逻辑本质是一个 UDF,我们会提供 UDF API 接口给业务方,然后上传 JAR 到特征后台加载。另外对于比较简单的计算逻辑,后台也支持通过提交简单的 Python 代码实现多语言计算。
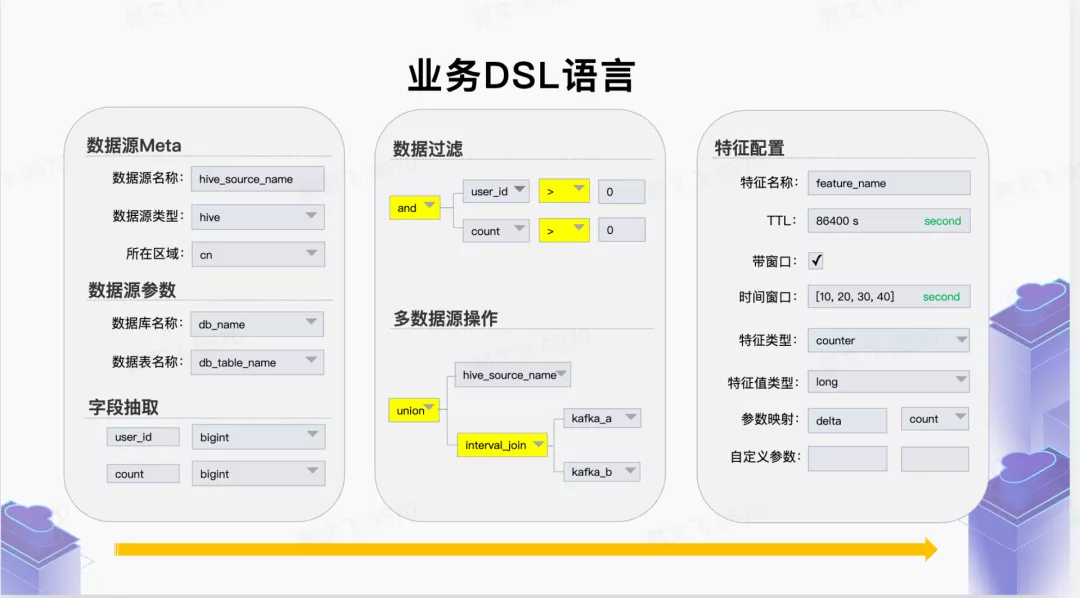
■ 2.2 业务 DSL
从业务视角提供高度抽象的特征生产 DSL 语言,屏蔽底层计算、存储引擎细节,让业务方聚焦于业务特征定义。业务 DSL 层提供:数据来源、数据格式、数据抽取逻辑、数据生成特征类型、数据输出方式等。
■ 2.3 状态存储层
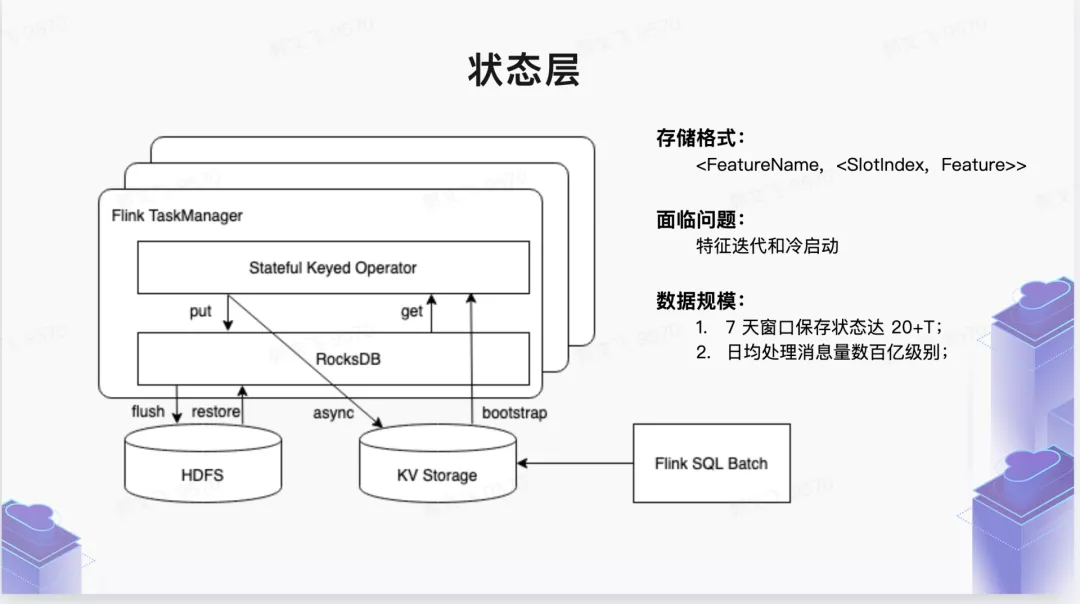
如上文所述,新的特征一体化方案解决的主要痛点是:如何应对各种类型(一般是滑动窗口)有状态特征的计算问题。对于这类特征,在离线计算层架构里会有一个状态存储层,把抽取层提取的 RawFeature 按照切片 Slot 存储起来 (切片可以是时间切片、也可以是 Session 切片等)。切片类型在内部是一个接口类型,在架构上可以根据业务需求自行扩展。状态里面其实存储的不是原始 RawFeature(存储原始的行为数据太浪费存储空间),而是转化为 FeaturePayload 的一种 POJO 结构,这个结构里面支持了常见的各种数据结构类型:
-
Int:存储简单的计数值类型 (多维度 counter);
-
HashMap<int, int>:存储二维计数值,例如 Action Counter,key 为 target_id,value 为计数值;
-
SortedMap<int, int>: 存储 topk 二维计数 ;
-
LinkedList
:存储 id_list 类型数据;
-
HashMap<int, List
:存储二维 id_list;
-
自定义类型,业务可以根据需求 FeaturePayload 里面自定义数据类型
状态层更新的业务接口:输入是 SQL 抽取 / 拼接层抽取出来的 RawFeature,业务方可以根据业务需求实现 updateFeatureInfo 接口对状态层的更新。对于常用的特征类型内置实现了 update 接口,业务方自定义特征类型可以继承 update 接口实现。
/**
* 特征状态 update 接口
*/
public interface FeatureStateApi extends Serializable {
/**
* 特征更新接口, 上游每条日志会提取必要字段转换为 fields, 用来更新对应的特征状态
*
* @param fields
* context: 保存特征名称、主键 和 一些配置参数 ;
* oldFeature: 特征之前的状态
* fields: 平台 / 配置文件 中的抽取字段
* @return
*/
FeaturePayLoad assign(Context context,FeaturePayLoad feature, Map<String, Object> rawFeature);
}
当然对于无状态的 ETL 特征是不需要状态存储层的。
■ 2.4 计算层
特征计算层完成特征计算聚合逻辑,有状态特征计算输入的数据是状态存储层存储的带有切片的 FeaturePayload 对象。简单的 ETL 特征没有状态存储层,输入直接是 SQL 抽取层的数据 RawFeature 对象,具体的接口如下:
有状态特征聚合接口:
/**
* 有状态特征计算接口
*/
public interface FeatureStateApi extends Serializable {
/**
* 特征聚合接口,会根据配置的特征计算窗口, 读取窗口内所有特征状态,排序后传入该接口
*
* @param featureInfos, 包含 2 个 field
* timeslot: 特征状态对应的时间槽
* Feature: 该时间槽的特征状态
* @return
*/
FeaturePayLoad aggregate(Context context, List<Tuple2<Slot, FeaturePayLoad>> slotStates);
}
无状态特征计算接口:
/** * 无状态特征计算接口 */public interface FeatureConvertApi extends Serializable {
/** * 转换接口, 上游每条日志会提取必要字段转换为 fields, 无状态计算时,转换为内部的 feature 类型 ; * * @param fields * fields: 平台 / 配置文件 中的抽取字段 * @return */ FeaturePayLoad convert(Context context, FeaturePayLoad featureSnapshot, Map<String, Object> rawFeatures);
}
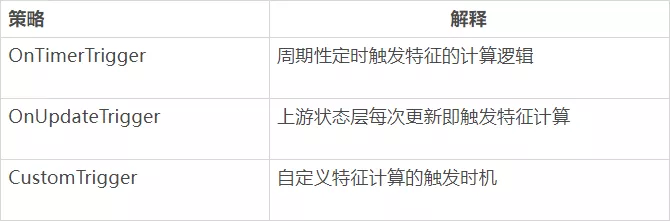
另外通过触发机制来触发特征计算层的执行,目前支持的触发机制主要有:
3. 业务落地
目前在字节推荐场景,新一代特征架构已经在抖音直播、电商、推送、抖音推荐等场景陆续上线了一些实时特征。主要是有状态类型的特征,带有窗口的一维统计类型、二维倒排拉链类型、二维 TOPK 类型、实时 CTR/CVR Rate 类型特征、序列类型特征等。
在业务核心指标达成方面成效显著。在直播场景,依托新特征架构强大的表达能力上线了一批特征之后,业务看播核心指标、互动指标收益非常显著。在电商场景,基于新特征架构上线了 400+ 实时特征。其中在直播电商方面,业务核心 GMV、下单率指标收益显著。在抖音推送场景,基于新特征架构离线状态的存储能力,聚合用户行为数据然后写入下游各路存储,极大地缓解了业务下游数据库的压力,在一些场景中 QPS 可以下降到之前的 10% 左右。此外,抖音推荐 Feed、评论等业务都在基于新特征架构重构原有的特征体系。
值得一提的是,在电商和抖音直播场景,Flink 流式任务状态最大已经达到 60T,而且这个量级还在不断增大。预计不久的将来,单任务的状态有可能会突破 100T,这对架构的稳定性是一个不小的挑战。
4. 性能优化
■ 4.1 Flink State Cache
目前 Flink 提供两类 StateBackend:基于 Heap 的 FileSystemStateBackend 和基于 RocksDB 的 RocksDBStateBackend。对于 FileSystemStateBackend,由于数据都在内存中,访问速率很快,没有额外开销。而 RocksDBStateBackend 存在查盘、序列化 / 反序列化等额外开销,CPU 使用量会有明显上升。在字节内部有大量使用 State 的作业,对于大状态作业,通常会使用 RocksDBStateBackend 来管理本地状态数据。RocksDB 是一个 KV 数据库,以 LSM 的形式组织数据,在实际使用的过程中,有以下特点:
- 应用层和 RocksDB 的数据交互是以 Bytes 数组的形式进行,应用层每次访问都需要序列化 / 反序列化;
- 数据以追加的形式不断写入 RocksDB 中,RocksDB 后台会不断进行 compaction 来删除无效数据。
业务方使用 State 的场景多是 get-update,在使用 RocksDB 作为本地状态存储的过程中,出现过以下问题:
- 爬虫数据导致热 key,状态会不断进行更新 (get-update),单 KV 数据达到 5MB,而 RocksDB 追加更新的特点导致后台在不断进行 flush 和 compaction,单 task 出现慢节点(抖音直播场景)。
- 电商场景作业多数为大状态作业 (目前已上线作业状态约 60TB),业务逻辑中会频繁进行 State 操作。在融合 Flink State 过程中发现 CPU 的开销和原有~~ 的~~ 基于内存或 abase 的实现有 40%~80% 的升高。经优化后,CPU 开销主要集中在序列化 / 反序列化的过程中。
针对上述问题,可以通过在内存维护一个对象 Cache,达到优化热点数据访问和降低 CPU 开销的目的。通过上述背景介绍,我们希望能为 StateBackend 提供一个通用的 Cache 功能,通过 Flink StateBackend Cache 功能设计方案达成以下目标:
- 减少 CPU 开销 :通过对热点数据进行缓存,减少和底层 StateBackend 的交互次数,达到减少序列化 / 反序列化开销的目的。
- 提升 State 吞吐能力 :通过增加 Cache 后,State 吞吐能力应比原有的 StateBackend 提供的吞吐能力更高。理论上在 Cache 足够大的情况下,吞吐能力应和基于 Heap 的 StateBackend 近似。
- Cache 功能通用化 :不同的 StateBackend 可以直接适配该 Cache 功能。目前我们主要支持 RocksDB,未来希望可以直接提供给别的 StateBackend 使用,例如 RemoteStateBackend。
经过和字节基础架构 Flink 团队的合作,在实时特征生产升级 ,上线 Cache 大部分场景的 CPU 使用率大概会有高达 50% 左右的收益;
■ 4.2 PB IDL 裁剪
在字节内部的实时特征离线生成链路当中,我们主要依赖的数据流是 Kafka。这些 Kafka 都是通过 PB 定义的数据,字段繁多。公司级别的大 Topic 一般会有 100+ 的字段,但大部分的特征生产任务只使用了其中的部分字段。对于 Protobuf 格式的数据源,我们可以完全通过裁剪数据流,mask 一些非必要的字段来节省反序列化的开销。PB 类型的日志,可以直接裁剪 idl,保持必要字段的序号不变,在反序列化的时候会跳过 unknown field 的解析,这 对于 CPU 来说是更节省的,但是网络带宽不会有收益, 预计裁剪后能节省非常多的 CPU 资源。在上线了 PB IDL 裁剪之后,大部分任务的 CPU 收益在 30% 左右。
5. 遇到的问题
新架构特征生产任务本质就是一个有状态的 Flink 任务,底层的状态存储 StateBackend 主要是本地的 RocksDB。主要面临两个比较难解的问题,一是任务 DAG 变化 Checkpoint 失效,二是本地存储不能很好地支持特征状态历史数据回溯。
- 实时特征任务不能动态添加新的特征:对于一个线上的 Flink 实时特征生产任务,我们不能随意添加新的特征。这是由于引入新的特征会导致 Flink 任务计算的 DAG 发生改变,从而导致 Flink 任务的 Checkpoint 无法恢复,这对实时有状态特征生产任务来说是不能接受的。目前我们的解法是禁止更改线上部署的特征任务配置,但这也就导致了线上生成的特征是不能随便下线的。对于这个问题暂时没有找到更好的解决办法,后期仍需不断探索。
- 特征状态冷启动问题:目前主要的状态存储引擎是 RocksDB,不能很好地支持状态数据的回溯。
三、后续规划
当前新一代架构还在字节推荐场景中快速演进,目前已较好解决了实时窗口特征的生产问题。
出于实现统一推荐场景下特征生产的目的,我们后续会继续基于 Flink SQL 流批一体能力,在批式特征生产发力。此外也会基于 Hudi 数据湖技术,完成特征的实时入湖,高效支持模型训练场景离线特征回溯痛点。规则引擎方向,计划继续探索 CEP,推动在电商场景有更多落地实践。在实时窗口计算方向,将继续深入调研 Flink 原生窗口机制,以期解决目前方案面临的窗口特征数据退场问题。
- 支持批式特征: 这套特征生产方案主要是解决实时有状态特征的问题,而目前字节离线场景下还有大量批式特征是通过 Spark SQL 任务生产的。后续我们也会基于 Flink SQL 流批一体的计算能力,提供对批式场景特征的统一支持,目前也初步有了几个场景的落地;
- 特征离线入湖: 基于 Hudi On Flink 支持实时特征的离线数仓建设,主要是为了支持模型训练样本拼接场景离线特征回溯;
- Flink CEP 规则引擎支持: Flink SQL 本质上就是一种规则引擎,目前在线上我们把 Flink SQL 作为业务 DSL 过滤语义底层的执行引擎。但 Flink SQL 擅长表达的 ETL 类型的过滤规则,不能表达带有时序类型的规则语义。�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E8%BF%AD%E4%BB%A3%E6%AC%A1%E6%8A%96%E9%9F%B3%E5%9F%BA%E4%BA%8E%E7%9A%84%E5%AE%9E%E6%97%B6%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E6%BC%94%E8%BF%9B%E5%8E%86%E7%A8%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


