强化学习系列二应用思路优化搜索排序
文章作者:杨镒铭 滴滴出行 高级算法工程师
内容来源:记录广告、推荐等方面的模型积累@知乎专栏
在深度学习大潮之后,搜索推荐等领域模型该如何升级迭代呢?强化学习在游戏等领域大放异彩,那是否可将强化学习应用到搜索推荐领域呢?推荐搜索问题往往也可看作是序列决策的问题,引入强化学习的思想来实现长期回报最大的想法也是很自然的,事实上在工业界已有相关探索。因此后面将会写一个系列来介绍近期强化学习在搜索推荐业务上的应用。
本次将介绍第二篇,发表在SIGIR2018上,适合做搜索推荐等业务的同学精读,链接为 http://www.bigdatalab.ac.cn/~junxu/publications/SIGIR2018-M2Div.pdf。作者中徐君老师在SIGIR2018上做过搜索推荐中Matching相关的分享,很赞。
一、Introduction
这篇文章解决的问题是提高搜索多样性,搜索多样性是指搜索结果覆盖更多的主题,问题可定义成从候选集合中选出一个最小的子集来尽可能覆盖更多的主题。传统的解决方法是贪心选择,每次从候选集合里选出一个marginal relevance的文档。贪心选择的问题在于每次选择局部最优的文档会导致最终生成的文档列表很难是全局最优的,因为每个位置选择的文档会影响后续文档的选择。如果想得到全局最优的文档列表,如果候选文档的数目为N,暴力搜索的时间复杂度为N的阶乘,显然在实际的应用中不现实。
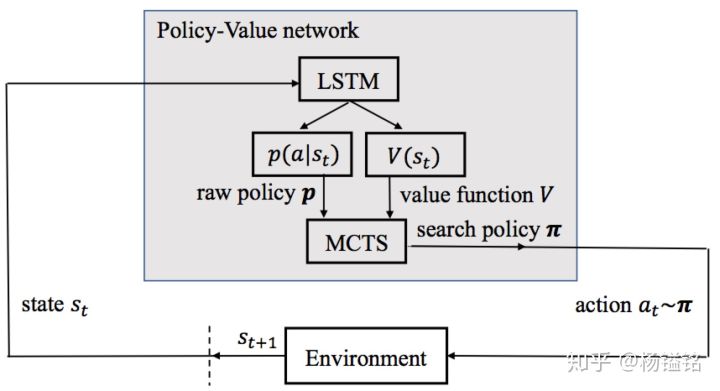
模型的整体框架
文章则借鉴了AlphaGo和AlphaGo Zero的思路,结合强化学习和蒙特卡洛搜索进行多样性排序,整体框架如上图。训练过程中,在每个时间步(对应每个排序的位置),基于用户query和已产生的文档列表,使用RNN得到当前状态,然后基于当前状态得到指导文档选择的策略函数(raw policy)以及评估当前列表的值函数。为了缓解次优解的问题,模型使用MCTS进行搜索,输出一个更优的策略(search policy)。模型的损失函数由两部分构成,一个是预测价值和文档排序指标的均方误差,另一个是raw policy和search policy的交叉熵。后面讲详细介绍整个训练过程和预测过程。
二、模型
- 基于MDP的多样性排序
文档列表生成过程中每个位置的文档选择可以看做一个时间步,整体是一个序列决策的过程,适合用MDP来建模。下面介绍下相关的状态、动作、转换、值函数和策略函数的定义。
状态:每个时间步的状态可看做三元组,
 ,q是用户查询,
,q是用户查询,
 是t时间之前已经产生的文档列表,而
是t时间之前已经产生的文档列表,而
 是候选文档。
是候选文档。
动作:
 中的动作对应可选择的候选文档。时间步t时选择的动作
中的动作对应可选择的候选文档。时间步t时选择的动作
 选择了标号为
选择了标号为
 的文档
的文档
 。
。
**状态转换:**状态转换很显然,设
 表示将
表示将
 加入到
加入到
 中,而
中,而
 表示将
表示将
 从
从
 中删除,定义为
中删除,定义为
 。
。
值函数:根据输入状态估计文档排序列表的质量,通过近似一个预先设定的指标来学习。不同时间步的状态可以一个输入给LSTM模型,值函数以LSTM输出作为输入并经过一个非线性层,即为
 ,其中
,其中
 。
。
策略函数:策略函数也是以状态作为输入,输出则是动作上的概率分布。形式化如下,其中
 是待学习参数。
是待学习参数。
 ,
,

- 基于MCTS的更优策略
通过p(s)贪心地选择文档的方式仅基于历史信息去做决策,并未考虑动作
 对后续决策的影响,会导致次优解。因此如下图,文章提出了利用MCTS在排序空间进行lookahead搜索。在每个排序位置,利用当前的策略函数p和值函数V进行MCTS搜索,返回一个更优的搜索策略
对后续决策的影响,会导致次优解。因此如下图,文章提出了利用MCTS在排序空间进行lookahead搜索。在每个排序位置,利用当前的策略函数p和值函数V进行MCTS搜索,返回一个更优的搜索策略
 。蒙特卡洛树中节点表示状态,边表示状态转换,每条边保存三个属性,分别是动作值函数Q(s,a)、访问次数N(s,a)和先验概率p(s,a)。整体最多迭代K次,每次迭代中会在第四步Back-propagation时更新Q和N两个变量,迭代结束之后输出更优策略。
。蒙特卡洛树中节点表示状态,边表示状态转换,每条边保存三个属性,分别是动作值函数Q(s,a)、访问次数N(s,a)和先验概率p(s,a)。整体最多迭代K次,每次迭代中会在第四步Back-propagation时更新Q和N两个变量,迭代结束之后输出更优策略。
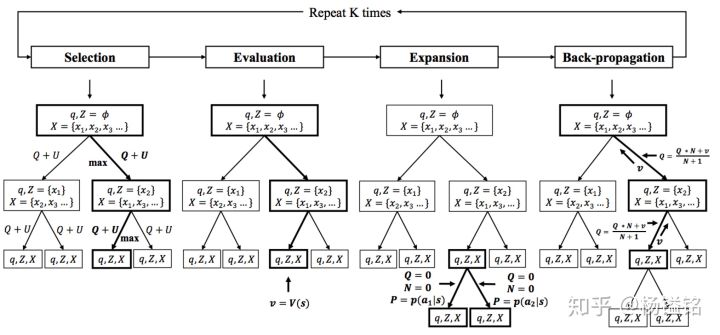
MCTS搜索过程-四个步骤
Selection
从根节点
 开始,在每个时间步t迭代选择使下式最大的动作
开始,在每个时间步t迭代选择使下式最大的动作
 。其中,
。其中,
 控制exploitation,倾向于选择价值更高的边;而
控制exploitation,倾向于选择价值更高的边;而
 控制exploration,
控制exploration,
 正比于先验概率,但随着访问次数衰减,倾向于选择探索次数少的边。
正比于先验概率,但随着访问次数衰减,倾向于选择探索次数少的边。

其中,
 。
。
Evaluation and Expansion
上一步一直迭代到一个叶子节点
 ,如果节点是一个episode的结尾则使用预设的评价指标评估,其他情况使用值函数
,如果节点是一个episode的结尾则使用预设的评价指标评估,其他情况使用值函数
 评估。这和AlphaGo Zero处理是一样的,而AlphaGo中价值评估是通过快速走子模拟实现的。接着叶子节点
评估。这和AlphaGo Zero处理是一样的,而AlphaGo中价值评估是通过快速走子模拟实现的。接着叶子节点
 有可能会拓展,拓展出的新边
有可能会拓展,拓展出的新边
 会初始化
会初始化
 、
、
 和
和
 这三个属性。
这三个属性。
Back-propagation and Update
利用
 沿着Selection经过的路径反向一路更新。针对路径上的每条边e(s,a),
沿着Selection经过的路径反向一路更新。针对路径上的每条边e(s,a),
 不变化,
不变化,
 加一,
加一,
 做累积平均的更新:
做累积平均的更新:
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


