微信看一看内容理解与推荐
在微信AI背后,技术究竟如何让一切发生?我们将为你一一道来。今天我们将放送 微信AI技术专题系列“微信看一看背后的技术架构详解” 的第三篇——《微信看一看内容理解》。
内容理解与推荐
相信对于不少人而言微信已经成为获取资讯的主要场景。与此同时,由于微信用户群体的庞大,也吸引了大量的内容生产者在微信公众平台创造内容,以获取用户关注、点赞、收藏等。微信内的内容推荐产品:看一看应运而生。
结合微信用户的内容消费需求,以业务目标为导向,我们的推荐系统从基于属性召回、到协同&社交召回、再到深度模型召回进行了演进,深度模型涵盖了序列模型、双塔模型、混合模型、图模型,最终形成了多种召回并列、多路模型共同作用的看一看内容召回系统。如果把推荐系统中工程服务比作骨骼,那么推荐模型可以比作肌肉,还需要内容理解作为血液,纵向贯穿整个推荐系统,从内容库、到召回、再到排序和画像,源源不断的提升系统的推荐精度,本文将着重介绍看一看内容理解平台及应用。
看一看接入了非常多合作方的数据作为内容源。由于接入数据源较多,各家数据从内容、质量、品类等差异性比较大。看一看平台方会对数据做“归一化”操作,然后应用于推荐系统线上部分。内容理解定义:对接各种外部图文等内容,对接入内容做业务级内容多维基础理解,同时进行外部标签与自有标签体系对齐,完成应用级内容打标;反馈至下游应用方:用户需求系统,召回策略,召回模型,排序/混排等使用;同时,在业务数据滚动与迭代中修正数据刻画精度与效果,逐步贴合与提升业务线效果;我们将内容画像定义为两个大维度:通过内容本身来理解内容,通过行为反馈来理解内容。前者主要针对内容抽取静态属性标签;后者,通过行为积累的后验数据,统计,或模型预估内容的知识,倾向性,投放目标,以及抽象表达。
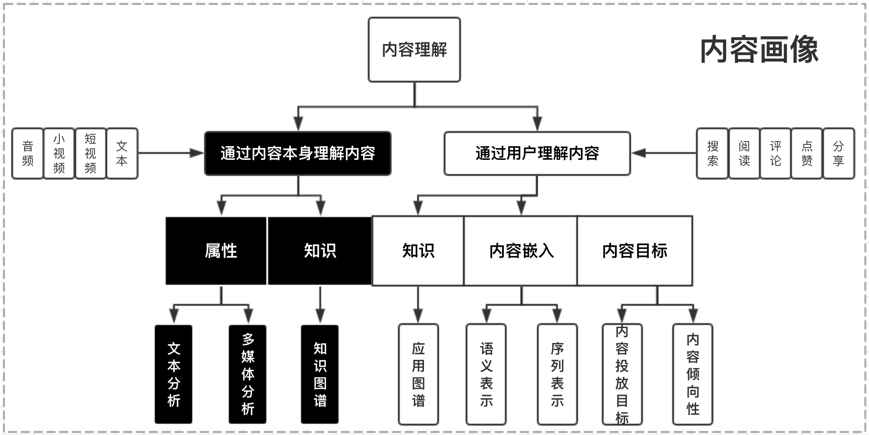
内容画像定义
内容理解主要包括文本理解、多媒体理解、内容倾向性、投放目标预估,主要应用在内容试探效率提升,推荐分发模型的特征泛化,多场景的内容库构建,推荐相关性召回和语义排序以及封面图优选创意,旨在提升精选、在看、看一看+核心业务指标。同时,我们在工程同学的大力支持下也将内容理解技术服务化/工具化,一方面支持业务快速扩展,另一方面对外部门提供内容理解支持。
文本内容理解
业务中有大量的文本信息,包括图文标题和正文,视频标题,ocr,评论等数据,需要对这些文本信息进行归一化,除了抽取分类、tag、entity,针对外部标签,我们还会做标签映射,面对画像中大量近似标签问题,我们也做了tag聚合/topic,同时我们还通过知识谱图的推理能力,加强对内容的理解深度和广度。
2.1 文本分类
文本分类是自然语言处理领域最活跃的研究方向之一,目前文本分类在工业界的应用场景非常普遍,文章的分类、评论信息的情感分类等均可辅助推荐系统,文本分类在推荐中相比标签与Topic具有较高的准召率与解释性,对于用户兴趣具有极大的区分度,并且作为内容画像中极具代表性的特征,往往是产品策略与自然推荐模型的重要决策依赖。目前已支持50+维一级主类目以及300+维二级子类目。
● 2.1.1 LSTM
在自然语言处理领域中,文本分类任务相较于文本抽取和摘要等任务更容易获得大量标注数据。因此在文本分类领域中深度学习相较于传统方法更容易获得比较好的效果。前期我们采用了自然语言处理中常用的LSTM算法进行了准召率的摸底试验。但LSTM具有训练、预测环节无法并行等缺点,伴随着推荐内容的体量增大,限制了迭代的效率。

● 2.1.2 TextCNN
与LSTM相比,TextCNN使用了卷积 + 最大池化这两个在图像领域非常成功的组合,以训练速度快,效果好等优点一段时间内在工业界具有广泛的应用。其中每个卷积核在整个句子长度上滑动,得到n个激活值,然后最大池化层在每一个卷积核输出的特征值列向量取最大值来供后级分类器作为分类的依据。但同时池化层也丢失了结构信息,因此很难去发现文本中的转折关系等复杂模式。
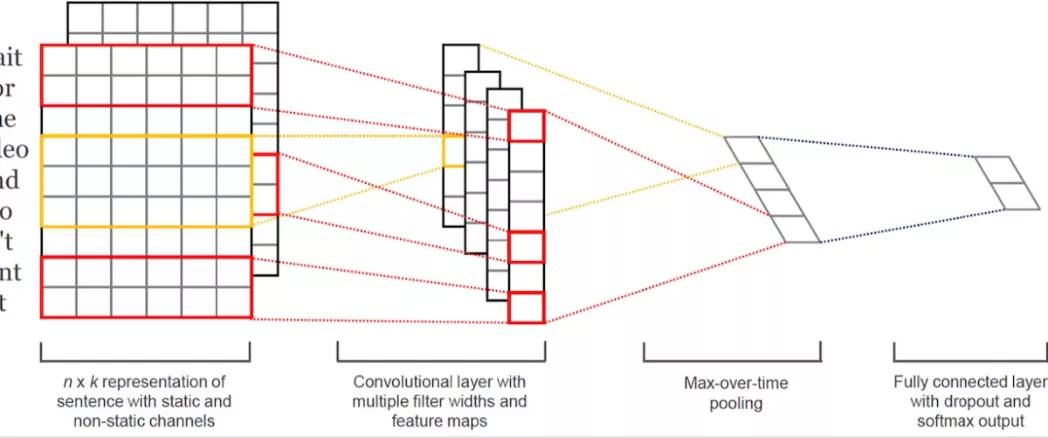
● 2.1.3fasttext
为解决LSTM模型优化慢的问题,我们采用了实现较快且效率较高的浅层模型fasttext。它的优点也非常明显,在文本分类任务中,fastText往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。
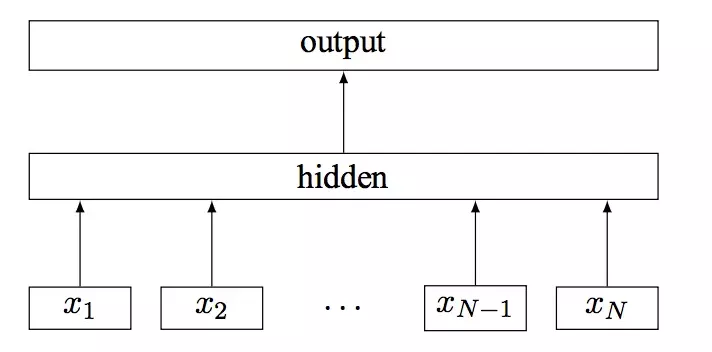
其中x1,x2,…,xN-1,xNx1,x2,…,xN-1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。与cbow模型相似,此处用全部的n-gram去预测指定类别。
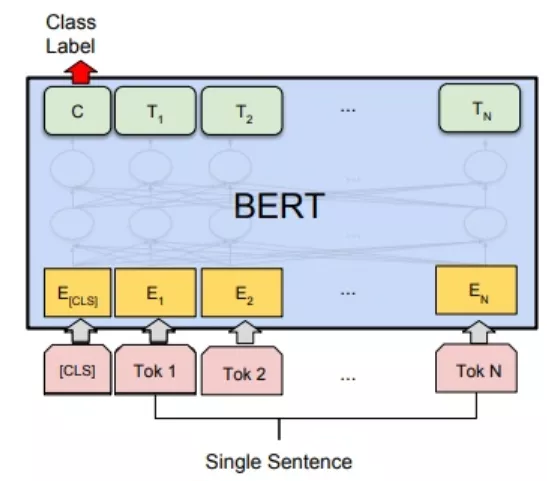
● 2.1.4 BERT
BERT在多项NLP任务中创下了优异的成绩,因此我们将文本分类算法优化至BERT finetune模型里,解决通用文本表示训练成本高等问题,在PreTrain Model(BERT-Base, Chinese)的基础上,通过推荐的特性数据进行finetune,得到基于BERT的finetune模型。
● 2.1.5 ensemble model
在已有的上述模型基础之上,我们对各已有模型以及合作团队的模型,进行了ensemble model优化,并对原始内容输入进行了词扩展补全等内容扩充特征工程,更近一步的增强了模型的鲁棒性,并针对不同场景的特性进行组合。
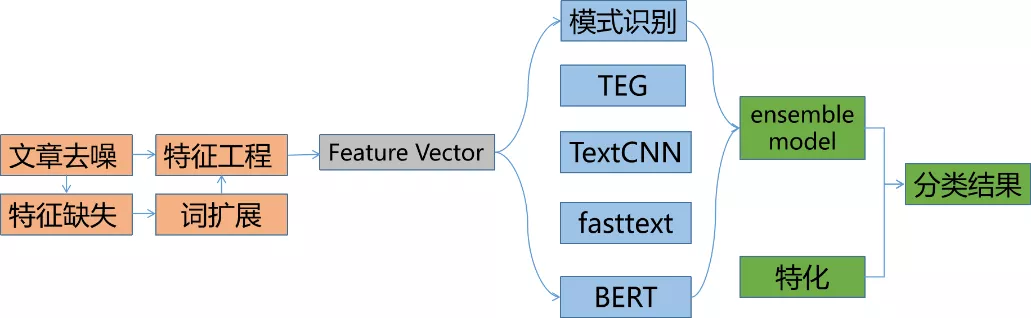
2.2 推荐文本标签
在推荐中,标签被定义为能够代表文章语义的最重要的关键词,并且适合用于用户需求和item profile的匹配项,相比于分类和topic,是更细粒度的语义。标签可以认为是推荐系统的“血液”,存在于推荐系统各个环节,内容画像维度、用户需求维度、召回模型特征、排序模型特征、多样性打散等等。跟随业务的快速发展,我们也从早期简单的无监督算法过渡到有监督,最后到深度模型。
● 2.2.1 TF IDF
前期为了快速支持业务,我们使用无监督投入产出比很高的方式,计算文档中每个token的TFIDF值,然后取top作为文档的tag。
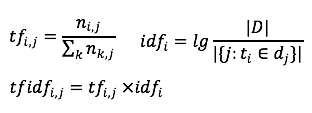
其中ni,j表示tokeni在文档j中出现的个数,|D|表示语料中文章个数,
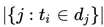 表示包含tokeni的文档个数。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。TFIDF优点是基于统计方式,易于实现,缺点是未考虑词与词、词和文档之间的关系。
表示包含tokeni的文档个数。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。TFIDF优点是基于统计方式,易于实现,缺点是未考虑词与词、词和文档之间的关系。
● 2.2.2 基于doc和tag语义排序
为了解决TFIDF存在的问题,考虑文档和token之间的关系,我们使用token与文章的LDA语义相关性排序,从而筛选出有意义的、满足文章主题信息的Tag,提高Tag的准确率。主要做法是用已有的topicModel inference 文章的topic分布和候选token的topic分布,然后计算文章topic分布和token topic分布的cos相似度,选取top token作为tag。后来将LDA升级到word2vec embeddding再到doc2vedc,效果上有提升。但该类方法可以考虑到文档和token之间的相关性,但是还是未考虑token之间的相关性,仍然是无监督方法,优化空间小且很多badcase不可控。
● 2.2.3 TextRank
TextRank由PageRank演变而来。PageRank用于Google的网页排名,通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种有向图和投票的思想来设计的,如下。直观来理解就是说网页Vi的rank值完全取决于指向它的网页,这些网页的数量越多,Vi的rank值越大,这些网页所指向的别的网页的数量越多,就代表Vi对于它们而言重要程度越低,则Vi的rank值就越小。
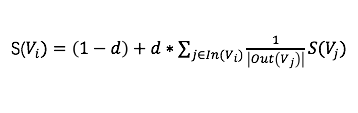
对于文章中的关键词提取也是类似的。我们将每个词语看成是网页,然后预先设置一个大小为m的窗口,从头遍历这篇文章,在同一个窗口中的任意两个词之间都连一条边,通常情况下,这里我们使用无向无权边(textrank的作者通过实验表明无向图的效果较好)。画出图过后,我们对每个词Vi赋予一个初值S0(Vi),然后按照公式进行迭代计算直至收敛即可。最终我们选择rank值的topN作为我们的Tag。相比于TFIDF,TextRank考虑了词与词、词与文章之间的相关性,但是TextRank没有利用整个语料的信息,不适合短文本抽取,且计算复杂度比较高。
● 2.2.4 CRF
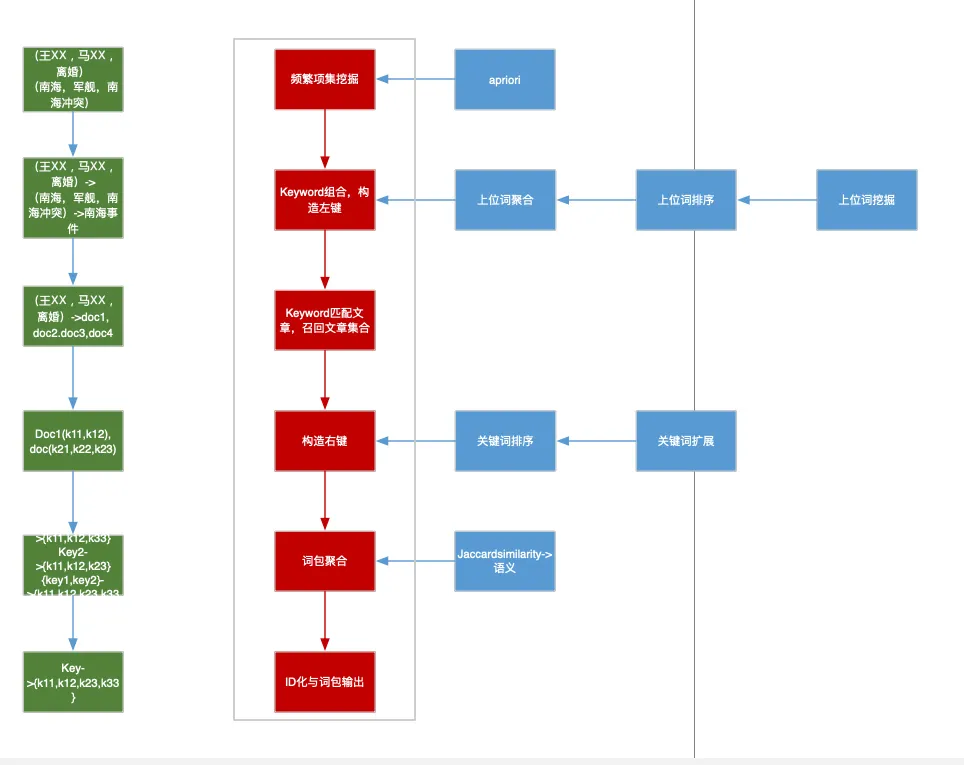
以上是无监督的方法的尝试,后来随着训练数据的积累,我们切换到了有监督模型上,tag抽取是一种典型的序列标注任务。我们尝试了经典的CRF(条件随机场)模型,特征包括字+词性+分词边界+特征词+词库,词库包括人名,地名,机构,影视,小说,音乐,医疗,网络舆情热词等词库。特征收集好之后需要配置特征模版,特征模版需要配置同一个特征不同位置组合,同一个位置不同特征组合,不同位置不同特征组合,特征模版70+。虽然CRF相比无监督方式效果比较好,但是特征工程复杂,面向新的数据源需要大量工作调节特征。
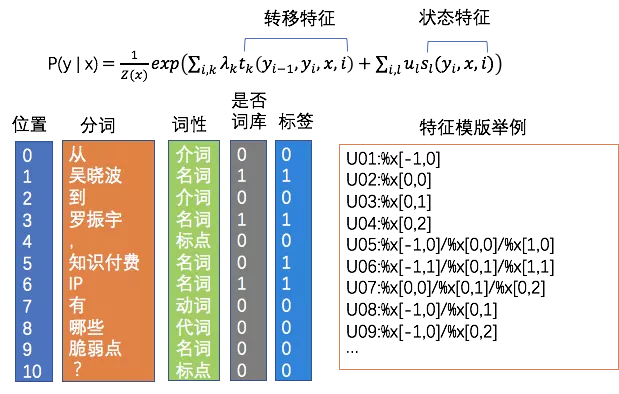
特征举例:
▶️ 如果当前词词性=名词 且 是否词库=1 且 标签=1,我们让t1=1否则t1=0,如果权重λ1越大,模型越倾向把词库中的词当成tag
▶️ 如果上一个词性是标点,下一个词性是动词且当前词是名词,我们让t2=1,如果权重λ2越大,模型越倾向把夹在标点和动词之间的名词当作tag
● 2.2.5 深度模型
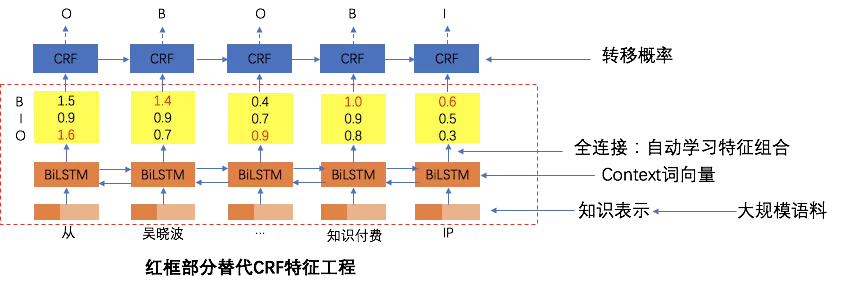
为了解决特征工程复杂问题,我们将浅层模型升级为深度模型,可以有效地替代人工特征设计,更全面地表示句子,同时增加序列约束。主要结构为预训练词向量+双向LSTM + CRF,目前业界比较经典的通用序列标注模型 。首先对句子分词得到token序列,输入序列先Lookup到embedding,embedding提前用word2vec从大规模语料中无监督得到,然后分别走前向和后向的LSTM,得到两个方向的基于Context的token表示,然后通过全连接层将前向和后向的语义表示Merge在一起,最后通过CRF层进行序列标注。神经网络部分替代特征工程,自动学习到高阶特征组合,embedding层通过无监督方式从大规模语料中学习到,可以降低分词token的稀疏性,LSTM可以学习到分词token动态的基于Context的embeddding表示,而双向LSTM使得表示更加全面,不但考虑前面的Context信息,也考虑了后面的Context信息,与人类一般读完整个句子才更好的确定词的重要度类似,之后的BERT验证了双向表示的重要性。而CRF层用来学习标签之间的约束关联信息,比如不太可能后半句全是1(1表示tag)。
LSTM-CRF带来的最大好处是
- 利用大规模语料来学习知识,容易迁移模型到新数据源
- 避免复杂的特征工程,但存在解释性差的问题。
● 2.2.6 深度模型升级
在经典的LSTM-CRF基础上,我们进行了模型的升级,模型整体结构变为Deep And Wide 结构,在原有的基础上增加 Wide部分,用于保持输入的低阶表示,增强模型的“记忆”能力,此处验证了TFIDF/postion/POS特征,只有TFIDF特征有效,在深度部分增加了self-attention层,学习token之间重要程度,与最终目标一致,self-attention的计算方法如下。其中Value是双向LSTM的输出, Query和Key相同,Key是不同于value的参数矩阵,大小是#corpus_uniq_tokens * attention_key_dim
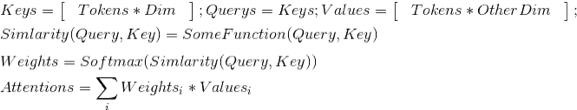
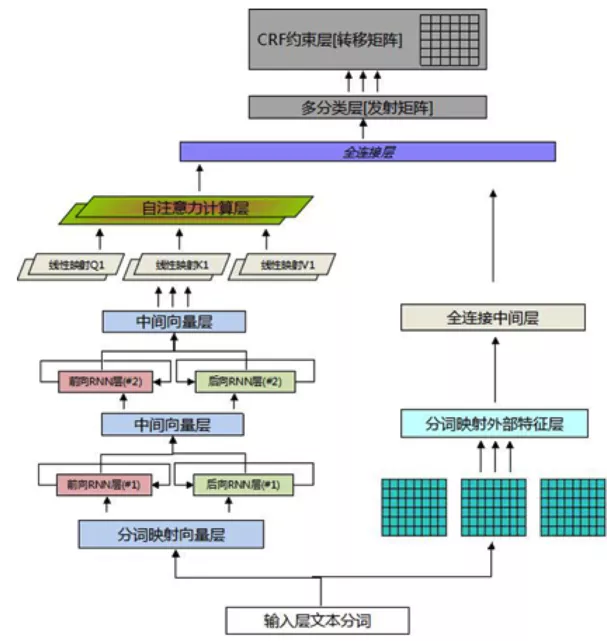
后续将尝试wide部分引入更多知识,比如词库特征。
2.3 推荐entity识别
● 2.3.1基于实体库
构建推荐系统初期,为了快速实现,我们基于实体库+AC匹配的方式进行实体识别,实体库使用CRF进行新实体发现,频率大于一定的实体再由人工审核进入实体库,这种方式往往忽略了上下文语境,容易引入badcase,对于新实体,识别并线上生效有所延迟。

● 2.3.2 序列标注模型
我们将推荐实体识别算法从匹配升级到BiLSTM-CRF with Attention架构的多类别实体联合识别模型。模型主要采用字、词、词性三种特征,在BiLSTM层与CRF层间引入multi-head self-attention层,在多个不同子空间捕获上下文相关信息,筛选不同类别实体的重要特征,增强特征对实体类别分辨能力,进而提升模型识别效果。最后使用CRF进行标签序列建模,利用全局信息,将标签转移矩阵作为标签序列的先验知识,避免结果中不合理的标签序列。
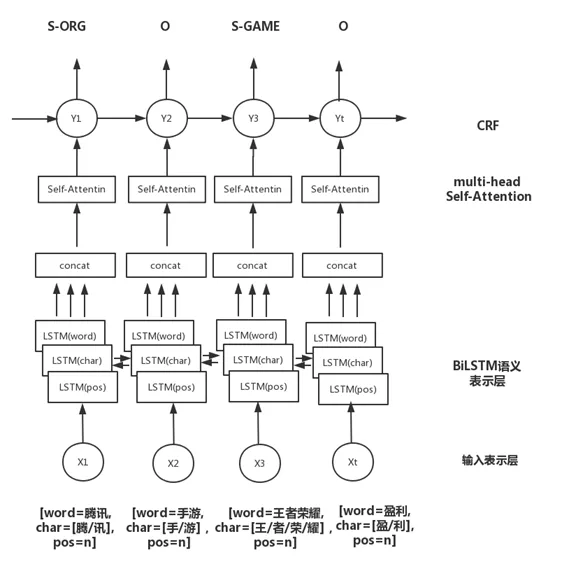
近期,我们又将实体识别算法升级到了BERT,解决训练数据难以获取导致的精度不高的问题,目前支持的实体类型包含人名、组织、地名、车、游戏、视频、书籍、音乐、食品、旅游景点、化妆品/服饰、疾病/养生、古董古玩、军事共14类实体。在PreTrain Model(BERT-Base, Chinese)的基础上,通过多类型实体标注数据进行finetune,得到支持多实体的实体识别模型。同时我们还尝试了BERT和LSTM-CRF的组合结构,目前来看,BERT效果最优。
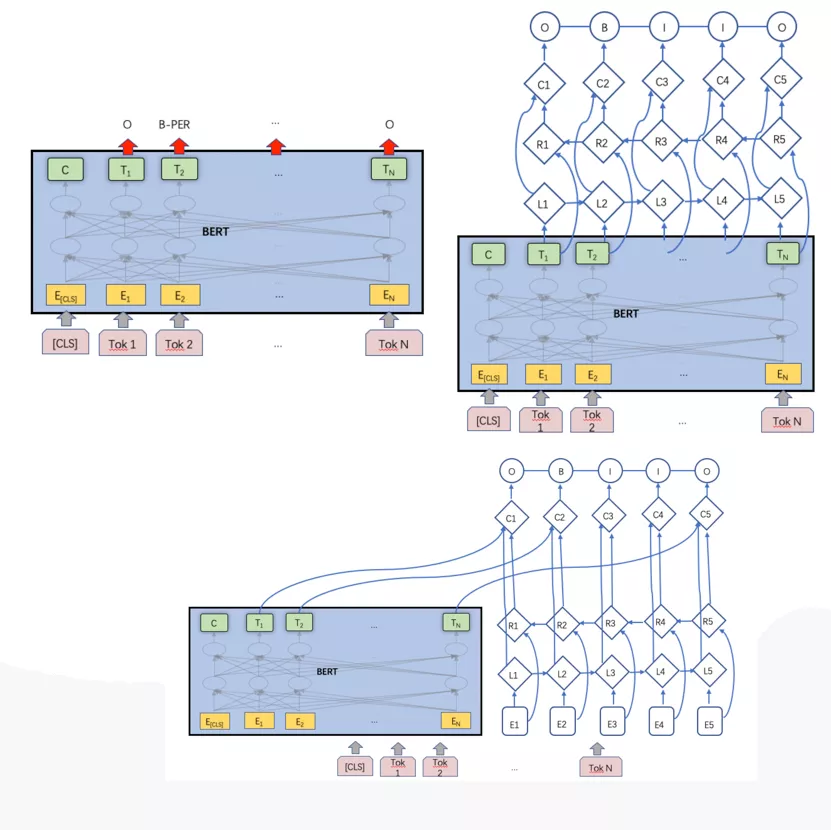
Rec-NER多模型对比
2.4 标签映射
外部视频有很多人工打的标签,标签体系和看一看的标签体系不一致,差异率为42%,由于外部标签难以和看一看画像相match,并且也不存在于召回和排序模型特征中,导致外部视频分发效率较低,因此需要将外部标签映射到看一看的标签体系。标签映射有两种方式:
● 2.4.1Tag2Tag
首先建立外部Tag到看一看Tag的映射关系,再将文章上的外部tag逐个映射到看一看tag。标签映射关系建立有4种方式:
- 编辑距离,计算外部标签中编辑距离最小的内部标签;
- 将外部标签和内部标签分词,利用词级别的word2vec embedding进行match;
- 通过外部行为得到uin(内部标签)到item(外部标签)之间的pair,然后通过频繁项挖掘或者矩阵分解得到标签映射关系;
- 通过知识图谱推理来得到内外部标签的关系;
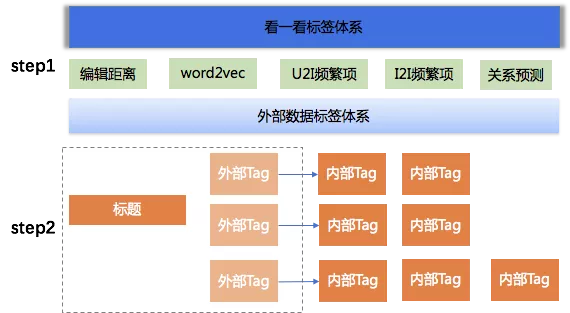
Tag2Tag示例:
外部视频:印度的自制椰子钓鱼装置,还真的有几把刷子!
外部标签:捕鱼|实拍|印度
内部标签:印度人,印度教,巴基斯坦,捕鱼游戏,捕鱼技巧,印度经济,印度文化
对于“印度教”“捕鱼游戏”等存在语义漂移问题,内部tag与上下文不相关,因此我们引入了Context2Tag进行标签映射的方式。
● 2.4.2 Context2Tag
基于Tag2Tag的方式,由于没有考虑到context信息,如标题、类目,容易产生歧义,导致badcase出现,所以更好的思路是利用双塔模型来建模,将外部标题和外部tag,统一编码到左端,看一看Tag编码到右端,利用深度语义匹配进行Tag映射。训练时使用看一看标题和Tag构造训练数据,看一看标题放在左端,将看一看Tag拆成两部分,N-1个放在左端,剩下一个放在右端。特征使用字、分词特征,能从看一看数据泛化到外部数据。预测时首先将内部tag embedding部署到knn服务中,然后对于外部文章和tag,用左端前馈生成文章表示,然后去knn服务中召回最相关的内部tag。其中,引入title attention net来计算外部标签重要度,代替对外部标签avg pool,上述case中,使得“捕鱼”权重更大,更容易找到与核心tag相关的内部tag。
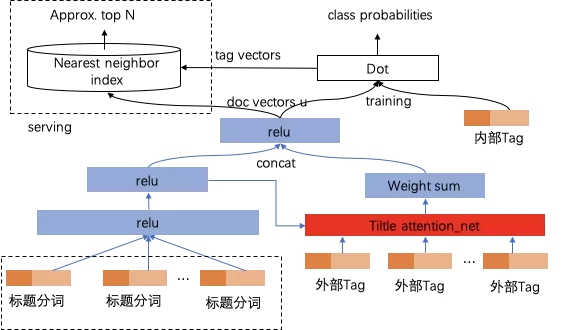
2.5 标签聚合
● 2.5.1 topic
我们使用lightlda构建了1千/1万/10万不同维度的topic模型,来解决分类和tag语义粒度跨度太大问题,同时我们还区分长期topic和时效topic,时效topic用于快速发现热点事件以及提升其分发效率。我们构建了面向新闻的实时topic理解模型,支持小时级全量topic和分钟级增量topic理解,能够快速捕捉热点及进行跟进,模型流程如下。
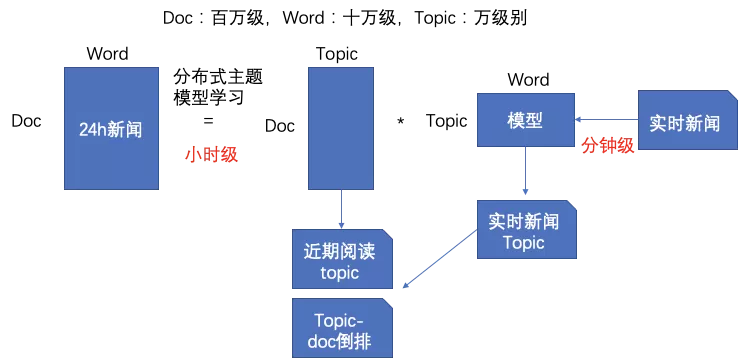
面向新闻的实时topic理解
● 2.5.2Tag Cluster
由于单一Tag拉取文章容易漂移,我们对Tag进行聚合形成更具象的语义内容。比如{王XX,马XX,离婚},用户感兴趣的不是王XX或马XX,而是王XX离婚事件。具体的Tag聚合方案,首先我们对文章Tag进行频繁项挖掘,并对频繁项进行层次聚类得到相近的语义内容。然后对类簇内Tag进行上位词挖掘与排序,构建类簇“title”。为了保证类簇的长期稳定标识,我们用类簇上位词的md5作为类簇ID。推荐方案类似Topic,分别为用户需求和文章打标Tag cluster ID,然后根据用户兴趣类簇ID拉取对应类簇内文章。
2.6 标签排序
有了文本标签、文本entity、多媒体标签、映射标签及人工标签后,我们构建了标签排序模型。目前推荐标签排序中文本建模采用自研的双向lstm变种模型,由于方法依赖大量样本,同时自动构建的样本质量较低,所以改为基于BERT的方式。将标题和标签作为sentence pair输入给BERT模型,使用CLS作为最终的排序分。主要优化点:
预训练+微调:引入已有字符预训练模型,根据少量高质量标注数据进行微调;
扩充高质量样本:针对训练出现的过拟合,通过自动构造扩充高质量样本并相应调参,仅补充训练集;
字符紧密度向量:针对识别结果的边界不准确和字符预训练模型的不足,引入基于图模型和词库预训练得到字符紧密度表示;
全局结构信息:模型引入全局结构信息,比如字符紧密度,设计不同的输入方式和结构。
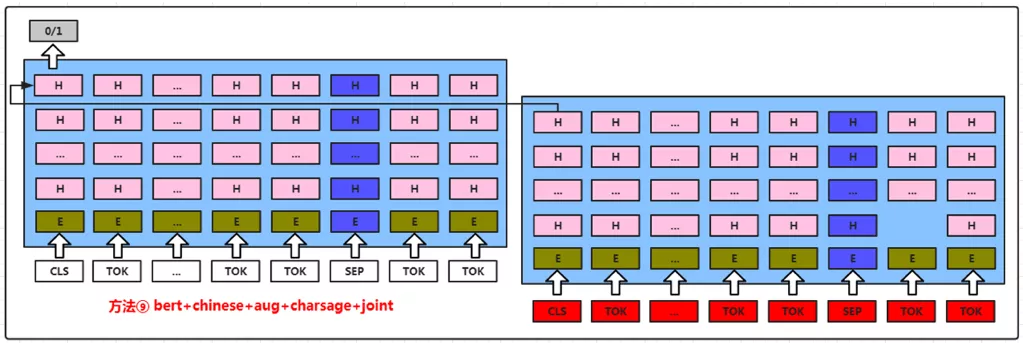
基于BERT的标签排序模型
2.7 关系图谱
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过将数据粒度从document级别降到data级别,聚合大量知识,从而实现知识的快速响应和推理。
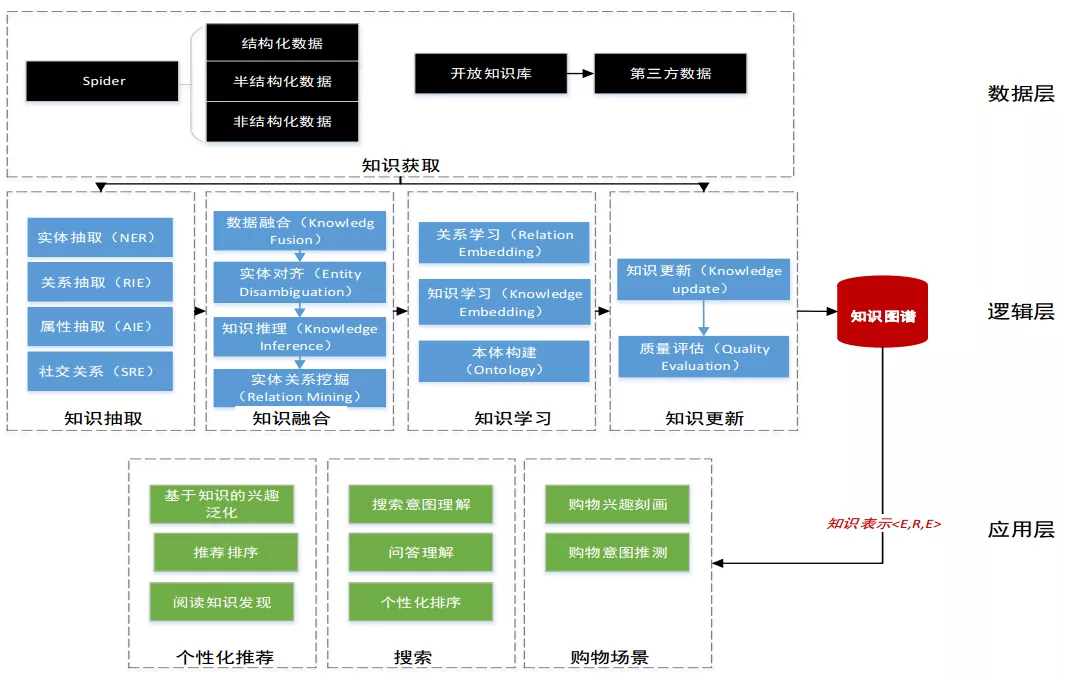
在看一看系统内,内容画像会将原关系信息整合,并构建业务可应用的关系知识体系;知识图谱已提供服务:看一看推理型推荐逻辑,看一看画像系统,看一看排序特征等;除此之外,业务中积累的关系数据,可用于构建知识的关系网,在此基础上输出知识表示,抽象后的知识图谱可以作为语义理解的载体,应用于任何具有文本搜索,识别,推荐的场景;
知识图谱的基本单位,便是“实体(E) - 关系(R) - 实体(E)”构成的三元组,这也是知识图谱的核心。
整个知识图谱的构建及应用划分为3层:数据层、逻辑层、应用层;每一层的具体任务如下:
● 2.7.1 数据层
获取:通过网络爬虫爬取数据
类型:结构化、半结构化和非结构化数据
数据存储:资源描述框架或者图数据库(Neo4j)
● 2.7.2 逻辑层
构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含四个阶段:
知识抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;关键技术:实体抽取、关系抽取、属性抽取和社交关系。
▶️ 实体抽取:也称命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体。
▶️ 关系抽取:文本经过实体抽取后,得到一系列离散的命名实体,为了得到语义信息,还需从相关语料中提取实体之间的关联关系,通过关系将实体联系起来,构成网状的知识结构。
▶️ 属性抽取:从不同信息源中采集特定实体的属性信息,如针对某个公众人物,抽取出其昵称、生日、国籍、教育背景等信息。
▶️ 社交关系:目标是预测不同实体之间是否存在社交关系,以便基于社交关系进行推荐。
知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体有多种表达,某个特定称谓对应于多个不同的实体等;
▶️ 数据融合:将知识抽取得到的碎片信息进行融合
▶️ 实体对齐:消除异构数据中实体冲突、指向不明
▶️ 知识推理:通过各种方法获取新的知识或者结论,这些知识和结论满足语义。具体方法:基于逻辑的推理、基于图的推理和基于深度学习的推理;
▶️ 实体关系挖掘:预测两个实体之间的可能存在的关联关系。
知识学习:对融合后的知识进行表示学习,得到三元组中实体与关系在特征空间的向量表示,方便后续的各项应用
▶️ 知识/关系表示学习:通过TransE,GraphSage等方法,得到实体/关系的表示
▶️ 本体构建:自动化本体构建过程包含三个阶段:实体并列关系相似度计算;实体上下位关系抽取;本体的生成
知识更新:对于获取到的新知识,需经过质量评估后才能将合格的部分加入到知识库中,以确保知识库的质量。
▶️ 知识更新主要是新增或更新实体、关系、属性值,对数据进行更新需要考虑数据源的可靠性、数据的一致性等可靠数据源,并选择将各数据源中出现频率高的事实和属性加入知识库。
▶️ 质量评估:是知识库构建技术的重要组成部分,可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
● 2.7.3 应用层
将知识图谱引入推荐系统,主要有如两种不同的处理方式:
**第一,基于特征的知识图谱辅助推荐,核心是知识图谱特征学习的引入。**一般而言,知识图谱是一个由三元组<头节点,关系,尾节点>组成的异构网络。由于知识图谱天然的高维性和异构性,首先使用知识图谱特征学习对其进行处理,从而得到实体和关系的低维稠密向量表示。这些低维的向量表示可以较为自然地与推荐系统进行结合和交互。
在这种处理框架下,推荐系统和知识图谱特征学习事实上就成为两个相关的任务。而依据其训练次序不同,又有两种结合形式:
知识图谱特征与推荐系统依次进行学习,即先学习特征,再将所学特征用于推荐。
交替学习法,将知识图谱特征学习和推荐系统视为两个相关的任务,设计一种多任务学习框架,交替优化二者的目标函数,利用知识图谱特征学习任务辅助推荐系统任务的学习。
**第二,基于结构的推荐模型,更加直接地使用知识图谱的结构特征。**具体来说,对于知识图谱中的每一个实体,我们都进行宽度优先搜索来获取其在知识图谱中的多跳关联实体从中得到推荐结果。根据利用关联实体的技术的不同,可分向外传播法和向内聚合法两种方法:
向外传播法模拟了用户的兴趣在知识图谱上的传播过程。如RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems, CIKM 2018 使用了向外传播法,将每个用户的历史兴趣作为知识图谱上的种子集合,沿着知识图谱中的链接迭代地向外扩展。
向内聚合法在学习知识图谱实体特征的时候聚合了该实体的邻居特征表示。通过邻居聚合的操作,每个实体的特征的计算都结合了其邻近结构信息,且权值是由链接关系和特定的用户决定的,这同时刻画了知识图谱的语义信息和用户的个性化兴趣。
视频内容理解
目前在推荐系统中,视频的消费量远大于图文,而视频内容中除了文本的内容以外,更多的信息其实来源于视频内容本身, 因此我们尝试从视频多种模态中抽取更丰富的信息。我们和优图实验室合作构建了支持看一看推荐场景下的视频图像等多模态数据的处理和分析的多媒体服务。目前服务接口主要包括:
视频分类:包含140类视频分类;
视频标签:从视频中提取的主要实体和内容等,模拟人工打标签过程,现支持20W量级标签;
水印识别:判断一个视频是否包含其他平台水印及水印尾帧位置判断;
OCR:抽取视频中的显著文字;
多封面图:提取视频中适合展示的候选封面图;
embedding:通过多模态信息学习视频的分布式表示;
这些接口已经在看一看+以及精选等视频推荐场景应用起来,并得到了显著的效果提升。
3.1 视频分类
● 3.1.1视频分类概念
图像分类是对于一张静态图片给定它属于什么样的类别。对于视频来说,增加了时间上的维度,其包含的语义信息更加丰富。根据时长,一般会把视频划分成长视频(长达几十分钟到数小时)和短小视频(几秒到几分钟)。由于长视频包含的内容信息太多,很难直接做分类。通常说的视频分类是指对短小视频进行内容层面上的分类。学术界相近的任务如动作识别,其目标就是把一个短视频划分到具体的某个行为动作。
在微信看一看+中,视频分类是指赋予某个视频唯一主题类别,一般包括二级或三级,二级分类从属于一级分类,所有短、小视频有且只有一个分类。例如:下面例子的分类为:搞笑,表演秀。一级分类为搞笑,二级分类为表演秀,二级分类从属于一级分类。比如,搞笑一级分类,其二级分类包括:搞笑段子、搞笑表演秀、搞笑糗事、搞笑其他。

视频分类示例
● 3.1.2视频分类算法
视频分类算法在学术界经过了长时间的发展。得益于近些年深度学习的快速发展和机器性能的大幅提升,视频分类主流算法已经从传统手工设计特征变成端到端学习的方法。最简单的方法是,用2D CNN抽取视频里面每一帧的特征,然后将所有帧的特征平均池化到一起变成视频特征进行分类[Karpathy et al., 2014]。这种方法带来的问题是,视频包含的帧数非常多,每一帧都抽特征会有非常大的计算开销,并且平均池化没有捕捉到视频的时序变化信息。
在此基础上,有一系列的算法来解决这两个问题,其中代表作有TSN[Wang et al.,2016],用基于片段采样的方法来解决稠密抽帧计算开销大的问题;有用NetVLAD[Miech et al., 2017]等用来聚合时序上多帧的信息。更直接方法是使用3D CNN进行视频分类,比如I3D[Carreira and Zisserman, 2017]将Inception里面的2d-conv直接展开成3d-conv来处理整个视频,Non-Local[Wang et al., 2018]将self-attention加入到3D ResNet里面学习时空的全局信息,SlowFast[Feichtenhofer et al., 2019]引入slow和fast两个不同时间分辨率的分支来学习视频的静态和动态变化。在微信看一看+的视频分类中,我们尝试了多种2D模型和SlowFast-ResNet50等模型,考虑到计算代价和模型性能的平衡,我们选择了2D的TSN-ResNet50为基础模型,并且引入了自研的video shuffle模块[Ma et al., 2019]和NetVLAD模块,来提升性能。
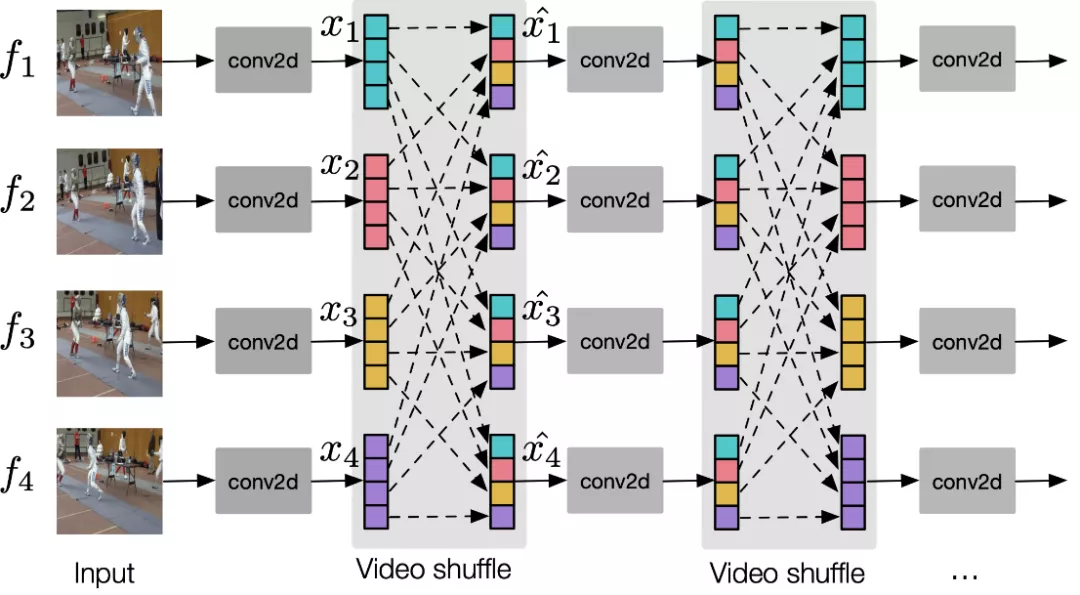
视频分类里的 Video Shuffle 操作
整个视频分类的pipeline可以分为以下几步:
(1)数据的采样和预处理;
(2)学习视频时空特征;
(3)时序特征动态融合。
下面详细介绍这几个步骤。输入一个M帧的视频,首先把M分成N段(M >= N,比如10s的25fps视频,M=250),那么每一段有M/N张图片,再在每一段中随机采样一帧,整个视频的输入就变成了N帧。这种方法不仅能够极大程度地减少输入的帧数,而且也能保证整个视频的信息都覆盖到了。对于N帧的图像,采用scalejitter随机进行裁剪,接着resize到224x224大小,进行随机水平反转,最后再做归一化。
经过上面的步骤,把处理好的多帧图像输入到2D CNN中,首先多个2d-conv会提取它们的空间特征。为了能够使得多帧图像之间有信息交流,我们引入了video shuffle操作,如图7所示,video shuffle会把每一帧的特征图分成若干个group,然后让某一帧的group feature和另一帧的group feature进行互换,互换之后的某帧特征都会包含其他帧的特征信息,接着用另外一个video shuffle来还原该帧空间特征。video shuffle使得在2d-conv内部,多帧信息得到了充分的交流,保证模型学习到的特征更好。
现在已经得到了N帧的特征,我们采用来YouTube-8M 2017年比赛冠军的思路,用NetVLAD+context gating来做时序特征融合。关于NetVLAD的介绍已经有非常多的资料了,这里不再展开描述。最后经过时序聚合的特征,也就是整个视频的特征,通过全链接fc到分类的类别,用交叉熵损失函数进行训练。
3.2 视频标签
● 3.2.1视频标签概念
上文介绍了视频分类,是给短视频一个确切的单一类别。而视频标签是对视频不同维度的描述,一般有多个。以图 8 为例,该短视频一共打了 11 个标签,描述了该视频不同维度的信息。比如加字幕是视频的质量维度,新型冠状病毒是描述整个视频内容在讲什么,新闻现场描述的是场景,民生新闻描述的是类型。
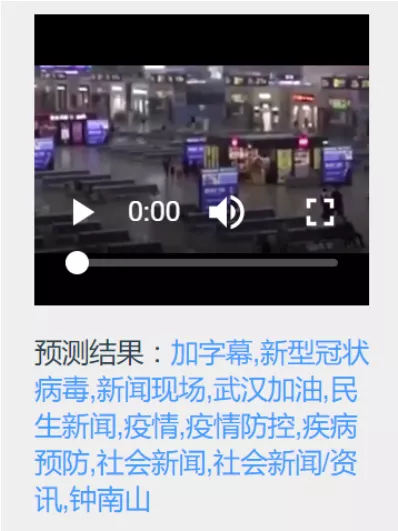
视频标签示例
● 3.2.2 视频标签算法
视频标签模块目前包括了视频内容识别的多标签预测模块和明星人脸识别模块。下面分别予以介绍。
▶️ 视频多标签模块
视频多标签预测模型由提取视频画面特征的骨干网络、可学习的时序池化层、考虑上下文的非线性网络单元门和以多标签分类为目标的分类器组成,具体结构如下图所示。
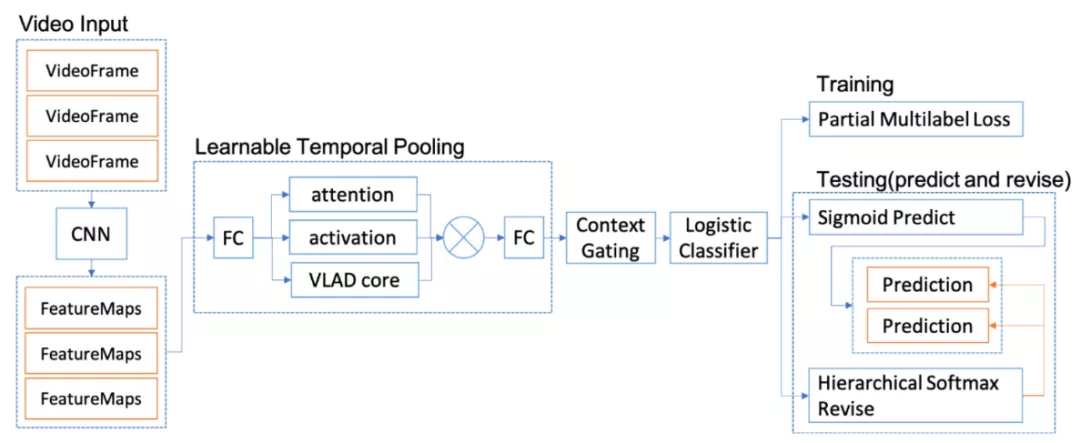
视频多标签算法结构
骨干网络采用的卷积神经网络结构是残差网络ResNet50,这是在学术界和工业界均有广泛应用的网络结构,其中引入的恒等近路连接结构有效解决了深层网络模型难以训练的问题,能在大大增加网络深度的同时获得高精准度。时序池化层通过学习得到的参数将视频输入得到的多帧画面特征图组成一个单独表达,将每幅特征图与码本聚类中心的差值通过attention和activation层做累加,再通过全连接层得到整个视频的降维描述特征向量。其后该特征向量被送入Context Gating层[Miech et al., 2017],捕捉其特征关联信息并重新调整权重,最后再接入多标签分类器。训练采用的视频标签数据基于人工标注的视频标签对生成,选取标注数据中的高频标签,并根据标签维度筛除部分视觉不可识别标签,组成标签词汇表。
训练过程中通过加入对低频次标签数据进行过采样等平衡数据的方法,提升低频标签的召回率。同时模型采用Partial Multilable Loss损失函数进行训练,有效解决了数据标注不完备带来的部分标签缺失的问题。模型预测标签时,则先通过Sigmoid层获得每个标签的预测分数,再结合标签层级依赖关系通过Hierarchical Softmax层[Mohammed et al., 2018]对标签预测分数进行修正,选取分数超过阈值的标签作为最后的预测结果。该多标签模型可以对于任意视频输出与视频内容相关的高精度、多样化、全面的标签。
▶️ 明星人脸识别模块
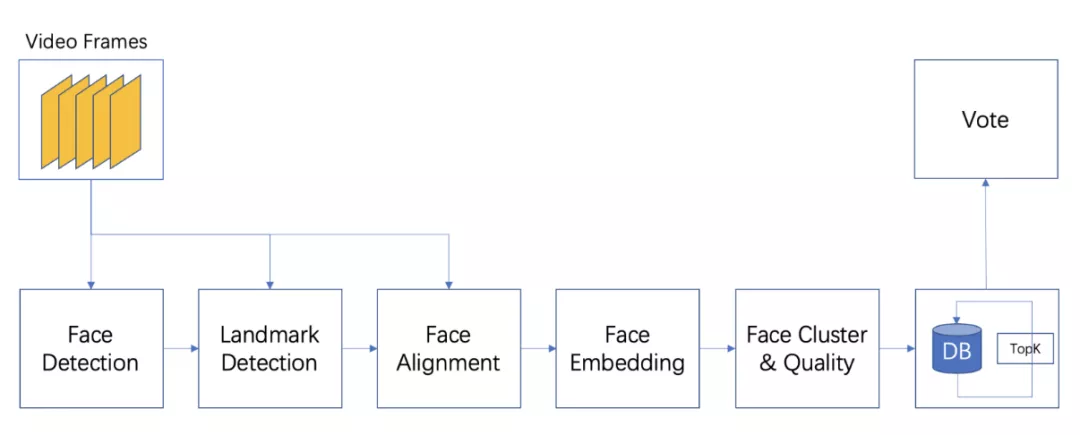
明星识别流程图
明星脸识别模块包含人脸检测,人脸关键点检测,人脸对齐,人脸特征,人脸聚类,人脸质量,人脸搜索和投票几个模块。
1.检测部分使用 RetinaFace [Deng et al., 2019],RetinaFace 是 Single-stage 的人脸检测方法,能保证检测的速度,并且采用 FPN+Context Module 的方式,提升对小人脸的召回和整体检测精度。另外,加入关键点回归分支一并训练。Multi-Task 的训练方式使得人脸定位和关键点回归相互促进。最后使得检测精度达到 State-of-the-art。
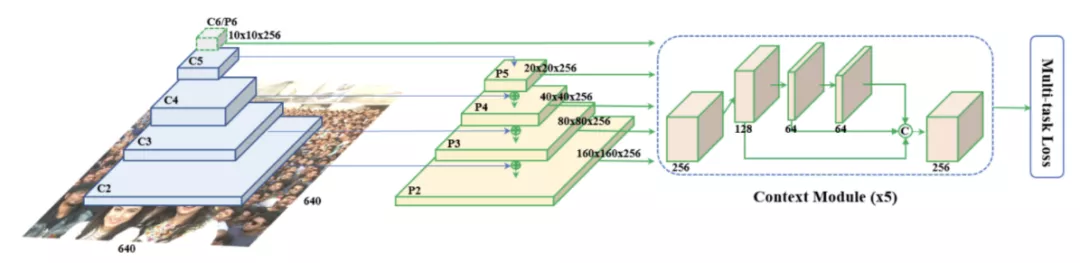
RetinaFace 人脸检测模块
2.在获得人脸框后,通过 Mobilenet V2 对人脸关键点进行精细化的检测,我们在 Mobilenet V2 中加入了 SE-layer,提升关键点的精度。通过关键点将人脸对齐到统一的模板,并送入 Face Embedding 模块提取每个人脸的特征。
3.Face Embedding 模块,我们采用的是 ResNet-50 的经典网络,加上 SE-layer。我们通过对 AdaCos [Zhang et al., 2019] 算法进行改进,针对不同场景的人脸数据和样本难易程度,自适应的调整 Scale 和 Margin 参数,加速训练,同时,使模型收敛到最优点。
4.在获得整个视频人脸特征后,对所有人脸进行聚类,并选优。通过 C-FAN [Gong et al., 2019] 算法对人脸进行选优。C-FAN 算法本意是为了对人脸集的特征进行融合的算法。我们在实验过程中发现,训练后的网络对不同质量的人脸,能给出不同指标。通过该指标,我们能对人脸进行选优。通过 C-FAN 我们能选出正脸,清晰的人脸,用于后续的识别。
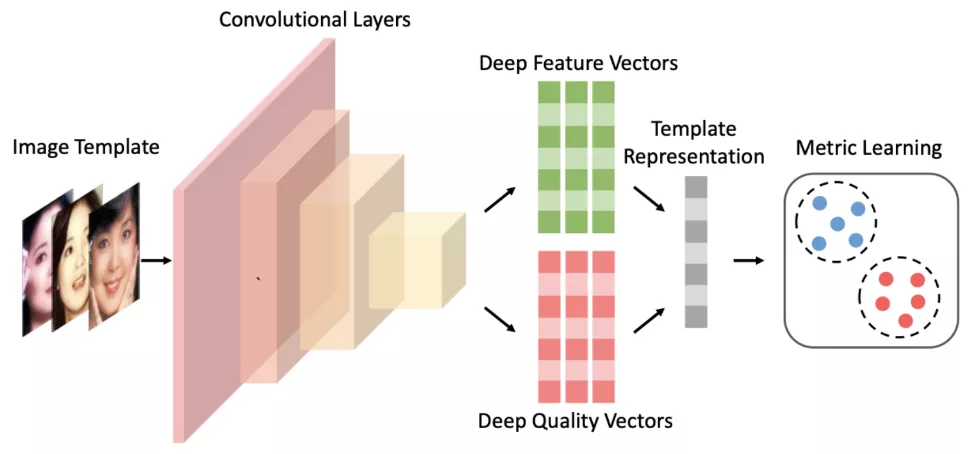
C-FAN 算法原理
人脸质量效果图
5.同前一步的聚类和选优,我们获得视频里每个人物的优质人脸,并进入人脸识别阶段。识别阶段,我们创造性的采用 2 次搜索的方式来提高准确率。其中第 1 次搜索,使用视频人脸检索库内的种子 ID。具体来说,对于库内每个 ID,其所有图片的特征求平均,作为这个 ID 的种子特征。第 1 次搜索,对于某个视频人脸,在种子人脸库内搜索得到 Top K 个种子 ID,Top K 取 50,从而初步确定 ID 的检索范围。第 2 次搜索,使用视频人脸,在第 1 次搜索得到的 TopK ID 的所有图片里面进行检索。并通过投票确定得分最高的 ID,作为该模块的输出。
6.返回上一模块的搜索结果即为人脸识别结果。
3.3 视频 Embedding
● 3.3.1 视频 Embedding 概念
视频中包含了丰富的语义信息,比如图像、语音、字幕等。视频 Embedding 的目标是将视频映射到一个固定长度的、低维、浮点表示的特征向量,使得 Embedding 特征向量包含了视频中的语义信息。相比视频分类和标签,视频 Embedding 中包含的信息更加丰富。更重要的是,Embedding 特征之间的距离可以度量视频之间的语义相似性。
● 3.3.2视频 Embedding 算法
视频中包括多个模态的信息,因此视频 Embedding 需要多个模态进行处理。
3.3.2.1 多模态 Embedding
视 频模态:视频中最重要的信息是视频画面,即视频模态,为了得到视频 Embedding,我们使用第 3.1.2 节介绍的视频分类算法进行训练,在此不赘述。
人 脸模态:短、小视频场景的一大特点是以人为中心,人物是视频内容中非常重要的部分。因此,我们将视频中人脸 Embeddding 部分融合进视频 Embedding。具体做法见 2.2.2.2 节明星人脸识别模块对应的介绍,在此不赘述。实践中发现,加入人脸 Embedding 后,可以找到同一个人的不同视频。
\\ OCR 模态**:视频中有丰富的文本信息,我们首先用 OCR 算法识别出视频中的 OCR 文字,之后训练文本模型,得到视频中 OCR 的 Embedding。识别 OCR 见第 2.4 节,在此不赘述。文本模型使用 BERT [Devlin et al, 2019] 进行训练。BERT 基于双向的 Transformer 结构,在预训练阶段捕获词语和句子级别的表示。BERT 在 2018 年发表时,通过预训练和微调在 11 项 NLP 任务中获得突出性能。
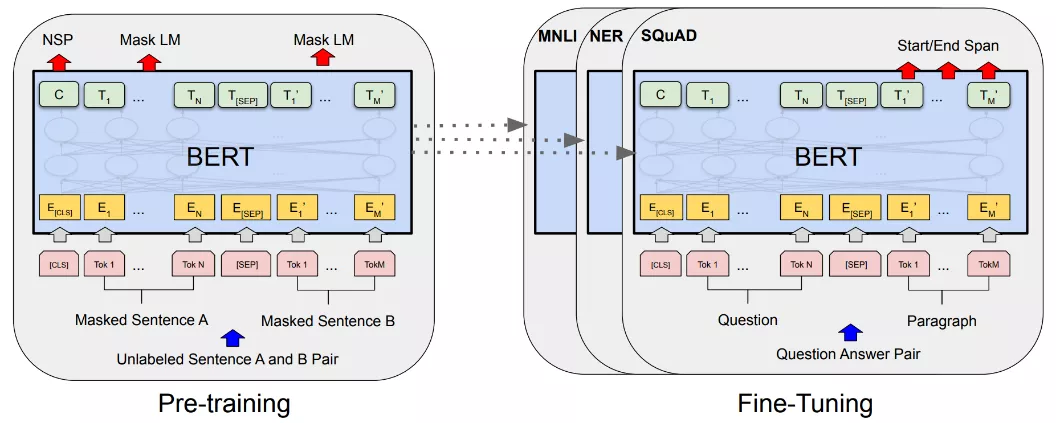
BERT 训练过程图
\\ 音频模态**:我们使用 VGGish 提取音频的 Embedding特征 [Abu-El-Haija et al, 2016]。VGGish 是从 AudioSet 数据集训练得到的音频模型,其产生 128 维的 Embedding 特征。VGGish 的网络结构类似于 VGGNet 的配置 A,有 11 层带权重的层。区别在于:(1). 输入是 96 × 64 大小的音频中得到的对数梅尔谱。(2). 去除最后一组卷积和汇合组,因此,相比于原来 VGG 模型的五组卷积,VGGish 只有四组。(3). 最后的全连接层由 1000 改为 128,这个的 128 维特征输出作为音频 Embedding。
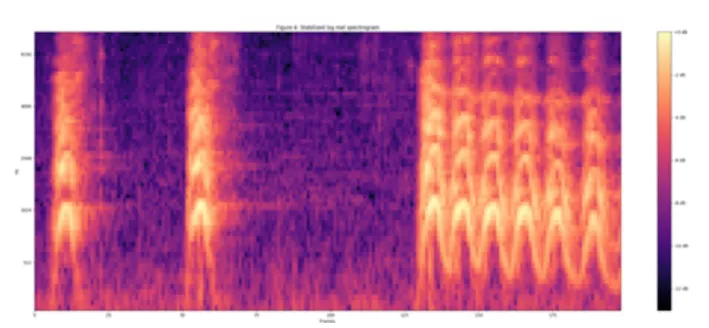
图 16:音频模态中使用的对数梅尔谱(Log Mel Spectrum)
关于特征融合部分,特征融合常用的有以下几种方式:直接拼接(Concatenation)、乘积(包括内积和外积)、加权平均、Bi-Interaction 等。这里我们采用最直接的拼接方法。
3.3.2.2 度量学习
度量学习有两大类基本思路。
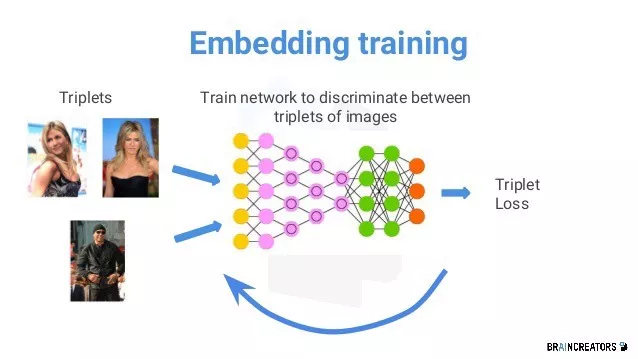
图 17:度量学习训练流程
一种思路是基于 Contrastive Loss 或 Triplet Loss。其基本思想是:两个具有同样类别的视频,它们在 Embedding 空间里距离很近。两个具有不同类别的视频,他们在 Embedding 空间里距离很远。Triplet Loss [Schroff et al., 2015] 是三元组输入,我们希望 Anchor 与负样本直接的距离,以一定间隔(Margin)大于与正样本之间的距离。使用 Triplet Loss 通常会配合 OHEM(Online Hard Example Mining)[Shrivastava et al., 2016] 等训练技巧。但是面对千万级别的视频数据量,使用 Triplet Loss 会产生很庞大的训练开销,收敛会比较慢。
另外一种思路是基于大间隔 Softmax 进行训练,这类方法在人脸识别领域取得了巨大成功。因此,我们使用 AdaCos [Zhang et al., 2019] 算法以达到更快和更稳定的训练收敛。
● 3.3.3 视频 Embedding 作用
▶️ 3.3.3.1 视频 Embedding 直接用于推荐
视频 Embedding 作为视频语义内容的描述,可以作为一个重要特征,直接用于推荐的召回和排序阶段。另一方面,可以通过视频 Embedding,寻找和平台中优质视频相似的视频,补充到平台中,提升内容丰富度。
▶️ 3.3.3.2视频去重
短、小视频内容十分热门,每天都会产生大量的新增视频。而这些新增视频中,一部分是用户上传的原创视频内容,另一部分是搬运平台已有的内容。搬运会导致平台中同时存在内容一样的视频,这对视频原作者是很大的打击。即使内容完全一样,但视频帧率、分辨率仍有差异,依靠视频文件 MD5SUM 无法进行判断。
通过视频 Embeding,可以帮助平台发现内容相同的视频,从而可以帮助平台进行去重,保留帧率、分辨率较高的视频。打击搬运,避免了对用户重复推荐同一视频。

视频 Embedding 用于视频去重
▶️ 3.3.3.3 视频标签
在第 3.2 节介绍了视频标签预测算法。在短、小视频场景下,该算法会面临一些挑战。比如,短、小视频内容更新快、流行期短,算法需要具备快速扩展识别新标签的能力。另一方面,短、小视频内容以人为中心,内容相对比较主观,传统计算机视觉算法(如分类、检测等)难以突破。
利用视频 Embedding 也可以进行视频标签预测。具体过程如下图:
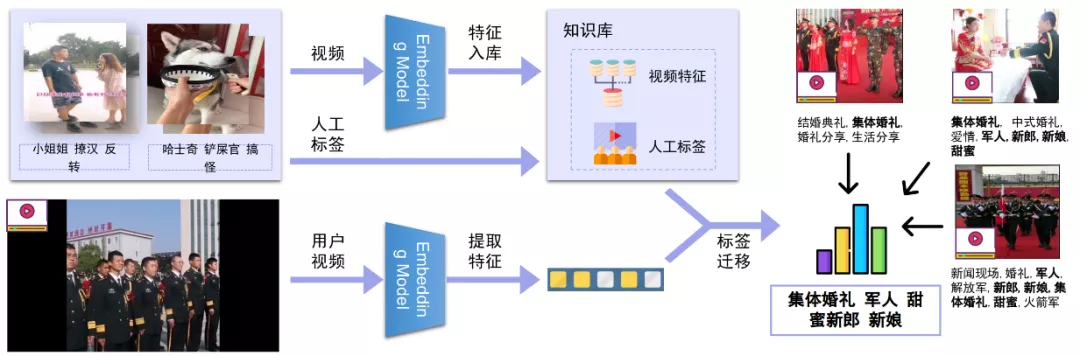
视频 Embedding 用于视频标签预测流程
1.提取待预测的视频(Query)的 Embedding 特征。除了待预测视频外,我们已经有了很多的历史有标注视频(DB),我们提取这些标注视频的特征,构建千万视频量级的特征库;
2.最近邻检索。对 Query 视频的 Embedding 在 DB 的 Embedding 特征库中进行最近邻检索,找到 Query 视频的相似视频;
3.利用找到的相似视频的标注的标签,投票对 Query 视频进行预测。

视频有搜索版标签、无搜索版标签结果对比
从上图可以看出,利用了视频 Embedding 进行标签预测(有搜索版标签)后,标签数量和精细程度有明显提升。
3.4 视频主题文本提取技术(T-OCR)
T-OCR 主要分为以下几个步骤:1、镜头分割;2、关键帧采样;3、文本检测;4、文本识别;5、后处理及主题提取。
● 3.4.1镜头分割
采用帧间二次差分法做镜头分割。具体做法如下:
设表示第 n 帧在点 (i, j) 上 c 通道()的值,那么两帧图像和在点 (i, j) 上的差异度定义为
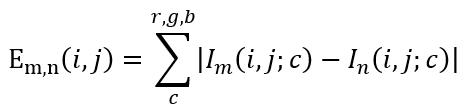
定义
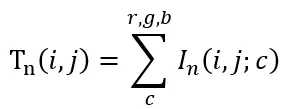
归一化后的差异度为
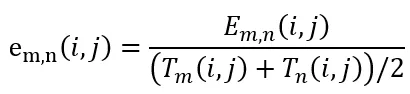
在区间 (0, 1) 内选择一个阈值来判定两帧图像在点 (i, j) 上差别是否大,记为 C,则
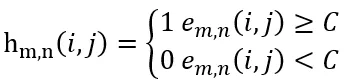
那么两帧图像整体上的差异度就是
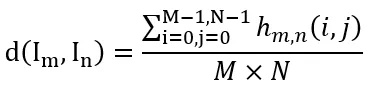
设定一个阈值 T,当
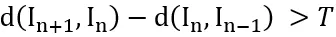 时,从第 n + 1 帧切分镜头。
时,从第 n + 1 帧切分镜头。
● 3.4.2关键帧采样
关键帧采样的目的是为了估算特定文本在镜头中出现的时长,从而节省处理时间。假设一个镜头中有 N 帧图像,从中均匀采样 F 帧,并识别这 F 帧中的文本,假设某文本在 C 帧中都出现了,那么该文本在镜头中出现的时长就估算为。文本的时间信息将在后处理阶段用到。
● 3.4.3 文本检测
采用 PSENet 做文本检测,网络的整体结构图如下:
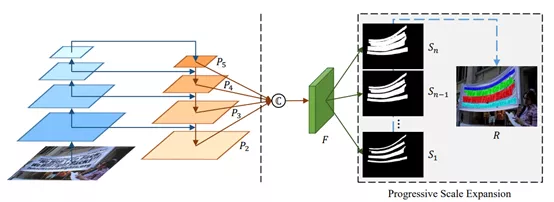
PSENet 网络结构
PSENet 主要有两大优势:第一,对文本块做像素级别的分割,定位更准;第二,可检测任意形状的文本块,并不局限于矩形文本块。
PSENet 中的一个关键概念是 Kernel,Kernel 即文字块的核心部分,并不是完整的文字块,该算法的核心思想就是从每个 Kernel 出发,基于广度优先搜索算法不断合并周围的像素,使得 Kernel 不断扩大,最终得到完整的文本块。
如上图所示,PSENet 采用 FPN 作为主干网络,图片 I 经过 FPN 得到四个 Feature Map,即P2、P3、P4 和 P5;然后经过函数 C 得到用于预测分割图的 Feature Map F。基于 F 预测的分割图有多个,对应着不同的覆盖程度,其中 S1 的覆盖度最低,Sn 的覆盖度最高。
基于不同覆盖程度的分割图,通过 Scale Expansion 算法逐渐生成完整、精细的分割图,其过程如下图:
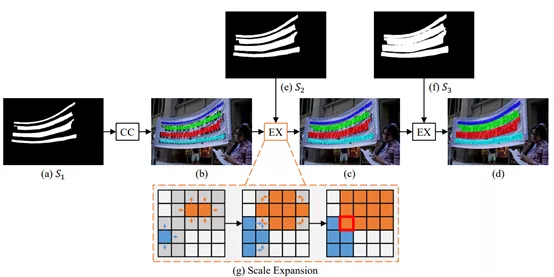
PSENet 生成完整、精细的分割图过程
其中 CC 表示计算连通域,EX 表示执行 Scale Expansion 算法,子图 (g) 展示了扩展的过程,如果出现冲突区域,按照先到先得的策略分配标签;算法详情参考下图。

Scale Expansion 算法过程
● 3.4.4 文本识别
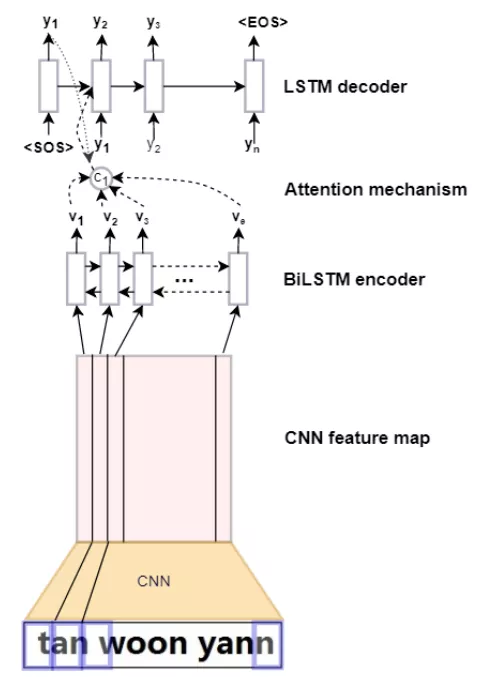
采用 Seq2Seq + Multi-head Attention 做文本识别,网络的整体结构图如下:
文本识别网络结构
整个网络从下到上共分为四部分:特征提取网络、Encoder、Multi-head Attention mechanism 和 Decoder。
特征提取网络是基于 EfficientNet 改进的,网络的详细结构参考下表:
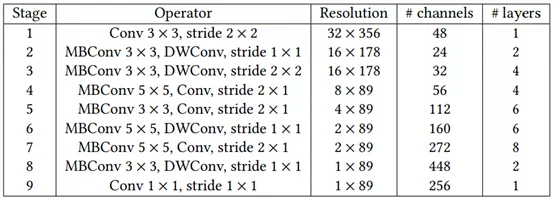
表 28:特征提取网络结构
Encoder 是一个 BiRNN,输入序列,然后计算每个时刻的隐状态。该网络其实由两层 LSTM 构成,每层 128 个隐状态;第一层从左向右处理输入序列,并产生正向隐状态,第二层从右向左处理输入序列,并产生反向隐状态,那么在时刻 j 的最终隐状态就是。
Decoder 也是一个 LSTM 模型,该模型基于 Encoder 的隐状态生成输出序列。
引入 Attention 机制是为了让 Decoder 在生成一个文字的时候能够在输入序列中定位到最相关的信息,也就是说 Attention 机制其实是一种对齐模型(Alignment Model),它通过打分来评估 i号输出与 j 号输入间的匹配程度。但传统的 Attention 机制存在一个问题,当输入序列的长度、尺度或分辨率发生变化时,这种 Attention 方法就会发生定位错误,进而引起误识别;而 Multi-head Attention 可以很好地解决这个问题。Multi-head Attention 的基本思想是使用多个 Attention 模块分别聚焦图像的不同部位,然后再将这些不同模块的结果整合起来,从而达到更加准确聚焦单个文字的目的。其结构如下图所示:
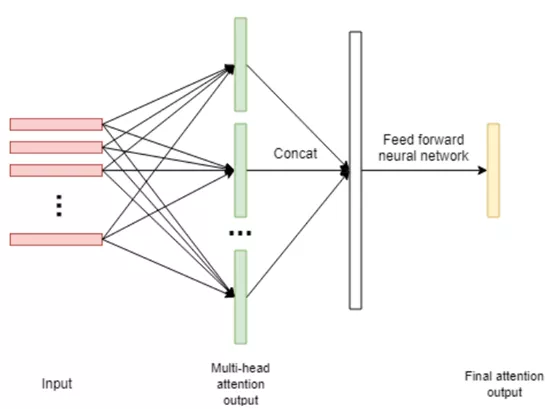
图 29:Multi-head attention 网络结构
● 3.4.5 后处理及主题提取
该阶段又分以下几个流程:A. 关键词过滤;B. 文本融合;C. 低频文本抑制;D. 主题生成。
1.关键词过滤。主要是过滤一些水印文本,比如“抖音”、“腾讯视频”等;
2.文本融合。同样的文本在不同帧中经 OCR 识别出来的结果可能有差异;比如在第 5 帧中 OCR 的结果是“这个美女说得太逗了”,而在第 10 帧可能识别为“这个美文说得太逗了”;因此需要将相似的文本进行融合。融合的基本思路是先通过编辑距离找到相似的文本,然后将时长最长的文本作为正确的文本,最后删掉其余的相似本文并将对应的时长融合到挑选出来的正确文本中;
3.低频文本抑制。主题文本与无关文本的一个重要区别就是主题文本的时长明显更长,所以应当将找到一个时长明显变短的位置,然后将低于这个时长的文本都过滤掉;
4.主题生成。按照从前到后、从上到下的顺序拼接剩余的文本以生成主题。
3.5 视频封面图和 GIF
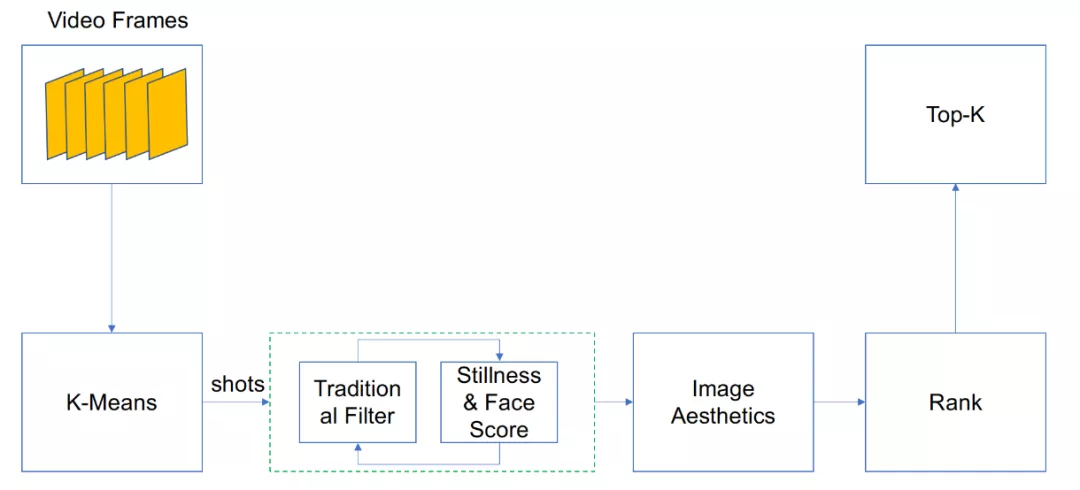
图 30:视频封面图算法流程
● 3.5.1K-Means 聚类
为了使得所提取的封面图能跟视频的主要内容匹配,我们首先采样后的帧提取特征,并进行 K-Means 聚类。特征模型以 MobileNet V2 作为 Backbone,在 ImageNet 上训练所得。K-Means 聚类过程中,我们使用 Elbow Method 来选择合适的 K 值。聚类后,每个类别包含若干帧。我们选择包含帧数最多的这个类作为候选集合。该类连续的帧为一个 Shot,所以每个类会存在多个 Shot。
● 3.5.2Traditional Filter
对上一步获得的 Shots,针对某个 Shot 的所有帧,我们从清晰度,亮度,色彩丰富度三个维度过滤掉模糊,过曝,纯色的低质量帧。
● 3.5.3Stillness & Face Score
上一步中,我们过滤掉一些低质量的帧,在本模块中,我们想要找出比较重要的能代表视频内容的帧。通过计算帧的重要程度(Stillness 和距离 Shot 特征中心的距离,可以衡量该帧的重要性)和人脸的得分(人脸位置,人脸偏角等),我们可以选出当前 Shot 的最佳帧,作为代表帧。
● 3.5.4Image Aesthetics
如果说前面过滤了低质量的帧,选出了内容丰富能代表视频内容的候选帧。那么这一步,我们的目的是选出,构图满足人类美学的帧。在这步中,我们使用了两个数据集,AVA 美学数据集和 AROD 社交数据集。因为两个数据集的标注体系不一致,所以我们采用了加权的 EMD Loss [Esfandarani & Milanfar, 2018] 和 L2 loss [Schwarz et al., 2018] 来进行网络的学习。学习后的模型能对图像进行美学打分。如图。
● 3.5.5 排序
经过上面的打分,我们返回美学得分最高的 Top-K 帧。

美学打分示例
● 3.5.6视频 GIF 生成
在生成封面图的基础上,我们选出得分最高的封面图,以该封面图为中心,前后各取 35 帧,共 70 帧,生成视频 GIF。
推荐内容倾向性与目标性识别
对于外部内容,例如UGC等,需要系统给予内容一定量的曝光,目的是挖掘其中的优质内容,召回和排序模型学习到优质内容之后会进行正常的分发,这就是内容试探过程。然而试探流量有限,新内容过多,如何预估内容试探的优先级是一个重要的问题。我们基于内容投放目标模型对新内容打分,优质分高的内容曝光优先级越高,并且针对不同的场景使用不同的投放目标,比如小程序使用分享率、精选视频流使用vv、精选主TL使用点击率,从而提升系统挖掘爆款的能力。
我们以曝光充分内容的后验分(点击率、分享率、带vv等)和内容倾向性(性别倾向、年龄倾向等)为训练目标,预估未充分曝光内容的投放倾向,发现大多数的内容缺乏置信的后验信息,尤其对于外部新内容,例如UGC,基本无曝光,而这些其中是蕴含很多优质item的,需要我们发掘可能的优质内容,并试探出来。
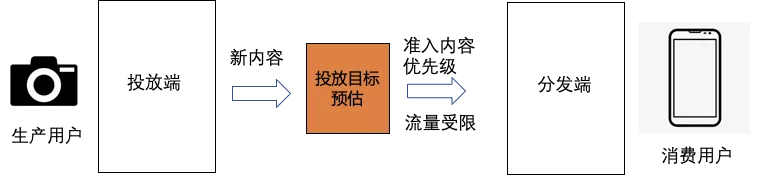
4.1 目标
我们要解决的问题就是给定item,预估试探等级。目标就是减少投放目标预估的点击率与实际投放点击率的差距。评价使用MAE,hitrate5%,hitrate。分类模型是从语义到语义的映射,点击率模型是从user叉乘item到行为的映射,而我们要构建的模型是从语义到行为的映射,这里如何减少映射空间的GAP是难点。
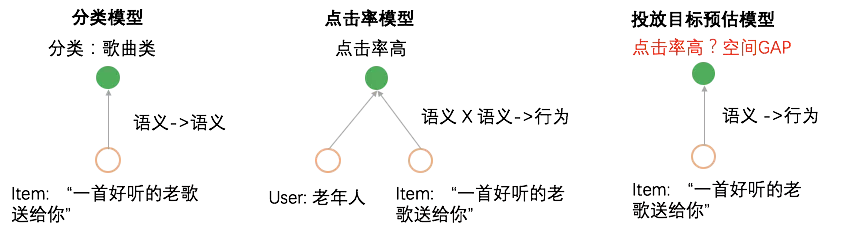
4.2 模型演进
● 4.2.1DNN
起初我们使用DNN快速构建模型,特征包括:1.文本属性 (标题、类目、主题、Tag等) 2.图像属性 (封面图、OCR) 3.固定属性 (发布时效、视频时长、是否优质) 4.发布者属性: 1.ID信息 (ID、媒体等级) 2.文本属性 (名称、类目)。除此之外,我们还引入cnn对标题和ocr text做理解,使用resnet对视频封面做理解。最终通过self attention将多路channel进行融合,最终输出投放目标。
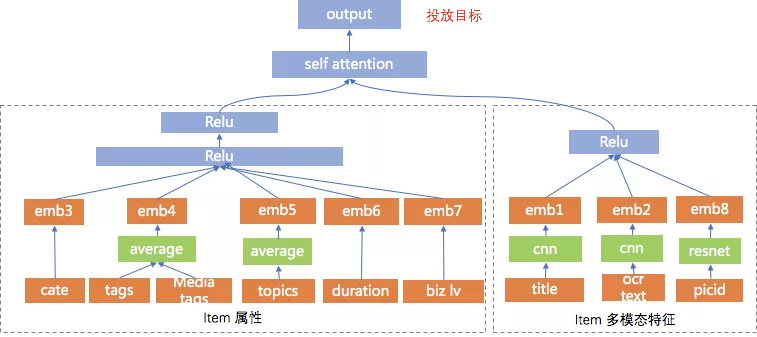
另外由于tag的稀疏性,我们初始化tag embedding使用word2vec无监督训练出来的向量。
样本构造上,初期我们的目标就是后验的分,比如分享率,但发现大部分内容的分享率都很低,导致我们模型过于拟合低分享内容,对于高分享内容的预估不准,我们根据目标调整了样本,即以高分享内容为正例,采样低分享内容,这样模型能够更好的区分出高分享内容。
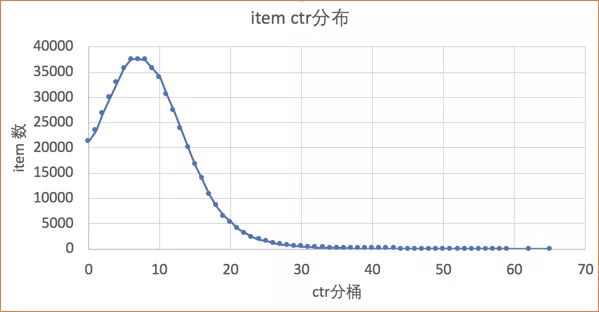
item ctr分布
● 4.2.2 PNN
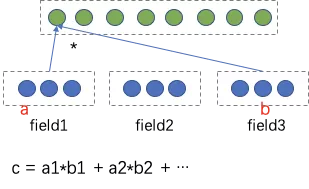
我们发现,DNN模型对于交叉特征学习的不够充分,比如小品长视频分享率高于小品短视频,我们的模型基本区分不出来。原因是DNN是隐性特征交叉,bit-wise特征相加,特征之间是or的关系,不能很好表达特征交叉,而且bit-wise丢失特征field边界。
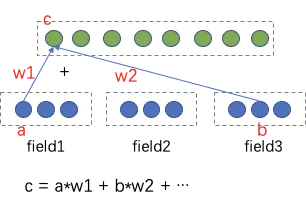
因此我们在网络中引入特征and关系,即特征相乘,加入vector-wise,保留特征field信息。
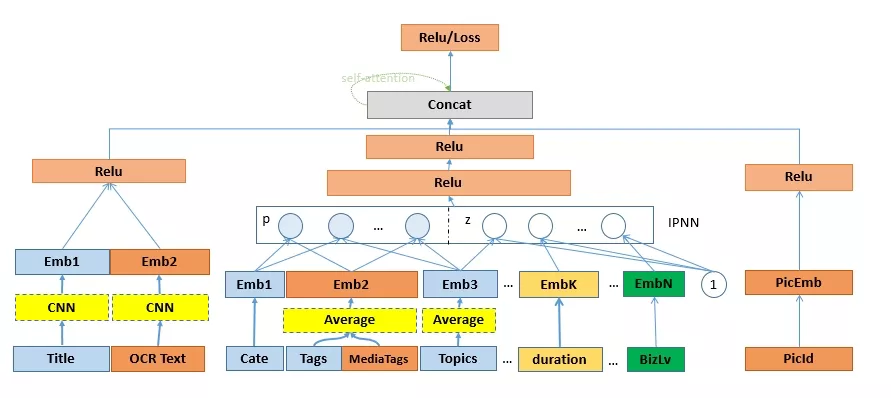
基于PNN的投放目标预估模型
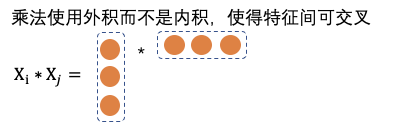
网络中特征filed使用PNN做特征交叉,PNN属于wide stack deep结构,即wide网络接deep网络,认为embedding输入到MLP之后学习的隐式交叉特征并不充分,提出了一种product layer的思想,即基于乘法的运算来体现特征交叉的DNN网络结构。分为IPNN和OPNN,特征向量运算时分别对应内积和外积,我们使用内积操作。Z部分直接平移embedding层,保留先前学习隐式高阶特征的网络结构,p层是PNN的亮点,特征交叉矩阵P是对称矩阵,所以采用了矩阵分解来进行加速。
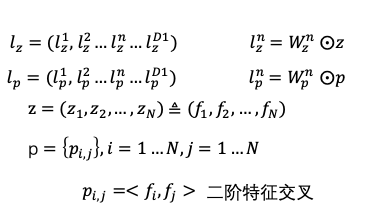
● 4.2.3DeepFM
PNN完成了从隐式高阶特征到隐式高阶特征+显式低阶特征的升级,但是显式低阶特征依然经过高阶变换,我们引入DeepFM来解决这个问题,即显式低阶特征与隐式高阶特征形成wide and deep结构。
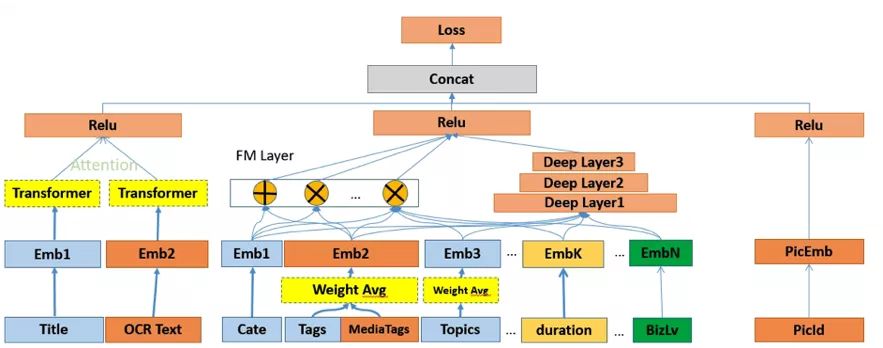
基于DeepFM的投放目标预估模型
● 4.2.4xDeepFM
DeepFM解决了二阶特征交叉,我们想增加多阶,进一步特征对文章的理解能力,但是遇到了组合爆炸问题。

这里我们引入xDeepFm来解决,xDeepFm采用高阶复用低阶结果的方式,减少计算量。
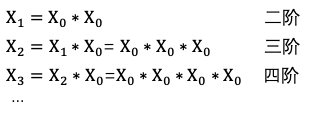
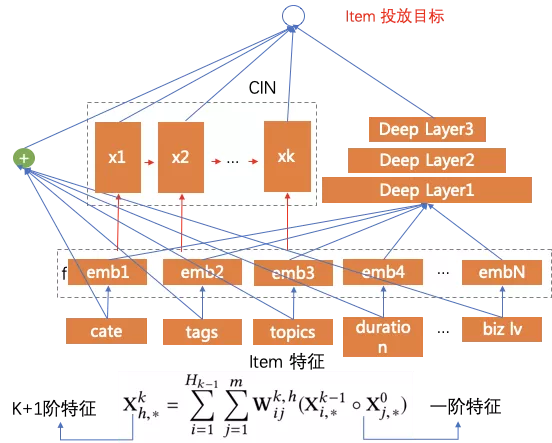
内容理解在推荐上的应用
5.1 全链路特征
标签和embedding主要应用在内容库构建,模型特征上(召回,粗排,精排,混排)。通过ItemKV和索引AB的方式推送给推荐系统中各个模型使用,这样使得内容理解直接作用于线上推荐系统,验证和发挥内容理解价值。未来ItemK会支持内容理解的AB实验,支持内容理解的离线优化策略。
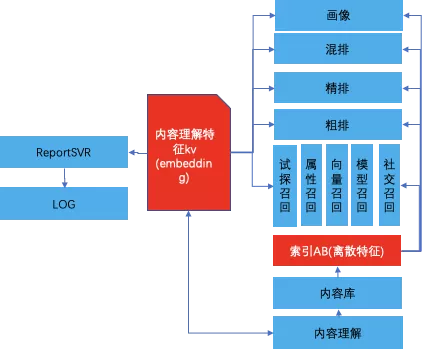
推荐系统中的特征实验通路
5.2 内容试探
很多外部接入的新内容,例如UGC,在系统中没有后验数据,通过正常的模型流程很难分发出去,需要先进行新内容的试探,筛选出优质内容。由于没有后验数据,试探的时候命中用户属性后只能采取随机的方式,内容理解中的投放目标预估能够提前计算待试探内容的目标值(点击率,分享率,带vv等),试探过程中用预估值提权,一方面可以提升出库内容的优质内容占比,提升流量的“变现”效果,另一方面,在不损伤系统的情况下,能够获取更多的试探流量,进一步加大优质内容的挖掘能力。我们先后在小视频、小程序试探上做了线上实验,都取得了正向的实验效果。
5.3 优质内容库构建
通过改变模型的目标,我们得到了内容倾向性模型。针对不同推荐场景,投放目标预估支持不同的目标。结合内容投放目标和内容倾向性,我们针对不同场景和人群,构建不同的内容库,比如针对老年人小程序,我们使用内容分享率和年龄倾向性来构建老年人库。
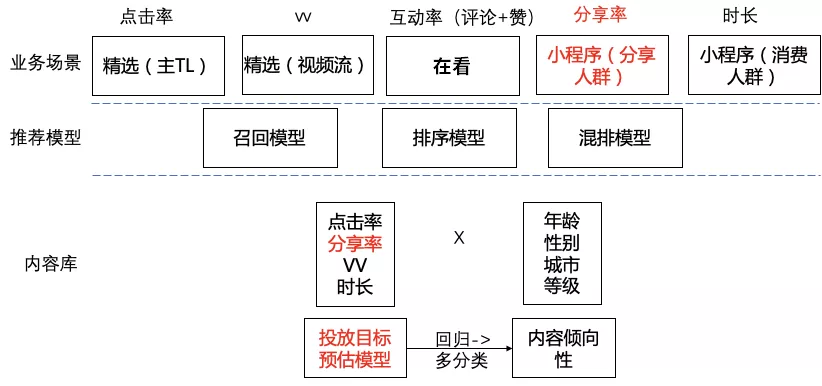
● 老年人库:比如我们目前正在优化的看一看小程序,主要面向老年人群体,内容就是通过年龄倾向性预估挖掘得到的,以年龄分布作为目标,以充分曝光的item为训练数据,训练内容年龄倾向性模型,然后预测没有后验行为的内容,挖掘老年人倾向的内容。
● 小程序高分享库:在小程序场景,DAU主要靠高分享内容的不断分享获得的,所以分享率是最核心的指标。我们以分享率为投放目标,训练分享率投放目标预估模型,对老年人倾向内容进行分享率预估,挖掘高分享老年人内容库,提升小程序分享率,进而提升小程序DAU。
● 高播放视频库:在相关视频场景上,我们尝试了带vv投放目标的应用,从主TL点击视频之后,BC位出的是A位的相关视频,我们大盘的目标是pv+vv,所以BC位出的视频的带vv能力很重要,比如用户观看了一个视频之后满意度很高,会往下观看更多视频,那可以认为这个视频的带vv能力很强。首先通过语义相关性,召回BC位视频,然后通过带vv投放目标预估模型对BC位候选视频进行rerank,进而加强用户阅读视频个数,增加大盘pv+vv。
除此之外,Item年龄性别倾向性用于召回过滤,避免出现明显的badcase;item的多目标的投放目标预估分后续也计划用于排序特征上。
5.4 智能创意
● 5.4.1智能封面
看一看+是我们复用看一看能力开发的一款视频推荐小程序,DAU增长主要靠群分享社交传播效应,群聊中的分享卡片对于用户进入小程序非常重要,我们使用以点击分享多目标的封面图优选模型优化群聊卡片封面图,提升用户点击率和分享率,进一步提升DAU。
另外,为了提升看一看+关注流点击率和公共主页关注率,我们引入了智能gif,视频列表中视频微动,提升消费者和生产者之间的互动,进一步提升上传端指标,进而激发用户进行更多创作。
● 5.4.2标题生成
为了提升Ugc有标题占比,进而能更好的理解内容,我们进行了自动标题生成,降低用户填写标题的门槛。为了构造社区氛围,我们还在尝试自动匹配热门话题等等。
总结与展望
随着业务发展和内容理解的深入优化,内容理解维度越来越多,我们与工程同学一起将其流程化和服务化,将内容理解各维度算法沉淀成nlp服务和图像服务,这样能够快速扩展到新数据源上,支持业务快速增长。另外,对于实验性性质的数据流程,我们优先在gemini上快速部署,等到实验验证有效�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BE%AE%E4%BF%A1%E7%9C%8B%E4%B8%80%E7%9C%8B%E5%86%85%E5%AE%B9%E7%90%86%E8%A7%A3%E4%B8%8E%E6%8E%A8%E8%8D%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


