微信看一看推荐系统用户画像构建指南
导语 | 推荐系统无论在工业界还是学术界都被广泛研究,有不少关于召回和排序的工作,但是对于用户画像的研究少之又少。下文将就微信看一看推荐系统中如何构建用户兴趣标签展开讨论,希望与大家一同交流。文章作者:闫肃,微信搜索应用部研发工程师。
一、背景
用户画像是推荐系统中非常重要的一环,用户画像刻画的是否精准直接影响后续召回和排序环节的效果。
用户画像包括用户的基础信息,如性别年龄地域等。此外还有用户的行为信息,比如通过用户历史浏览的文章视频,计算出的用户的兴趣标签。
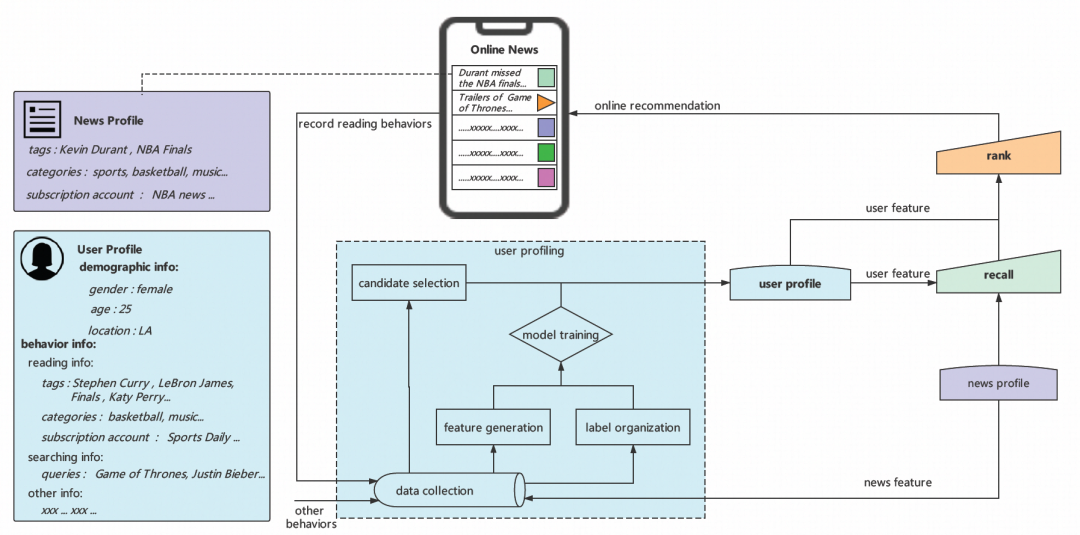
如上图所示,推荐系统会根据用户的画像把可能感兴趣的文章推送给用户。比如一个对 NBA 感兴趣的用户,他画像中有“库里”的标签,那系统很大可能会给他曝光相应的文章。
用户画像建模其实就是给用户打上他感兴趣的标签。然后这些标签会作为特征,传给召回和排序,最终排序将用户最可能感兴趣的文章展现给用户。
那么为什么要做用户画像建模呢,直接把用户的历史统计数据给到召回和排序做特征不就可以了吗?
一方面是用户的历史行为可能有成千上万条,由于性能原因,不可能把这么多的行为都喂到线上的召回和排序模型中,所以需要一个能够从用户众多历史行为中选出最感兴趣的top特征。
另一方面一些冷启动用户或者行为不丰富的用户,也需要额外补充一些可能感兴趣的用户标签,这部分就需要用户画像模型 具有用户兴趣预估的能力。
从上图的画像建模模块中可以看出,在建模过程中,我们会收集用户的各种统计行为数据和基础信息作为特征,然后训练用户画像预估模型,然后对用户的行为候选和预估的候选进行排序,最终吐出去的标签作为用户的画像。
二、问题建模
在构建用户画像标签中,我们能拿到的就是用户的一些基础信息,还有用户的一些行为特征,比如用户历史点击过的标签,类目等,此外就是用户在系统中的点击曝光日志。我们需要训练一个模型可以输入用户的特征,然后可以对任意标签进行打分。
1. 建模成多分类任务而非点击率预估
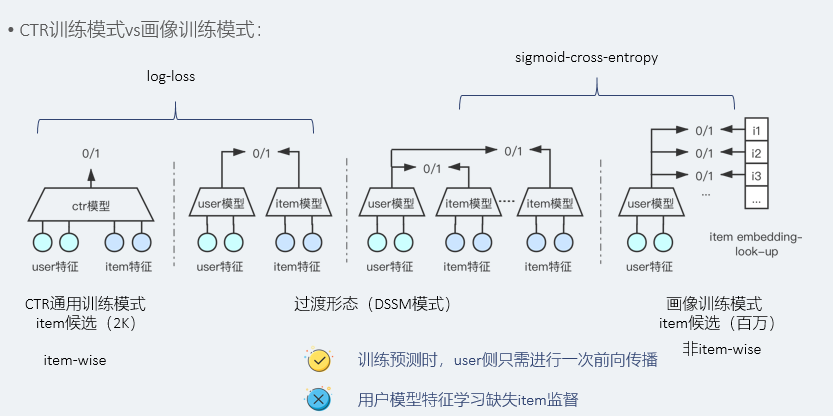
我们知道 CTR 训练的方式是从底层开始喂进去各种用户和 item 的特征,然后通过模型去自动学习用户和 item 的特征交叉。但是对于画像预估来说,这种模式是性能不友好的。
因为 CTR 处理的是召回后的结果,量级在千级别。而画像需要对整个标签空间(百万量级的标签)进行打分,所以我们直接把标签放到 label 侧,然后建模成一个多分类的任务,可以大大加快训练和预测效率。
2. 用户侧的特征学习
这里由于特征输入只有用户侧特征,那么如何更好的学习一个用户特征表达至关重要。这里我们使用下面的模型进行用户特征学习:
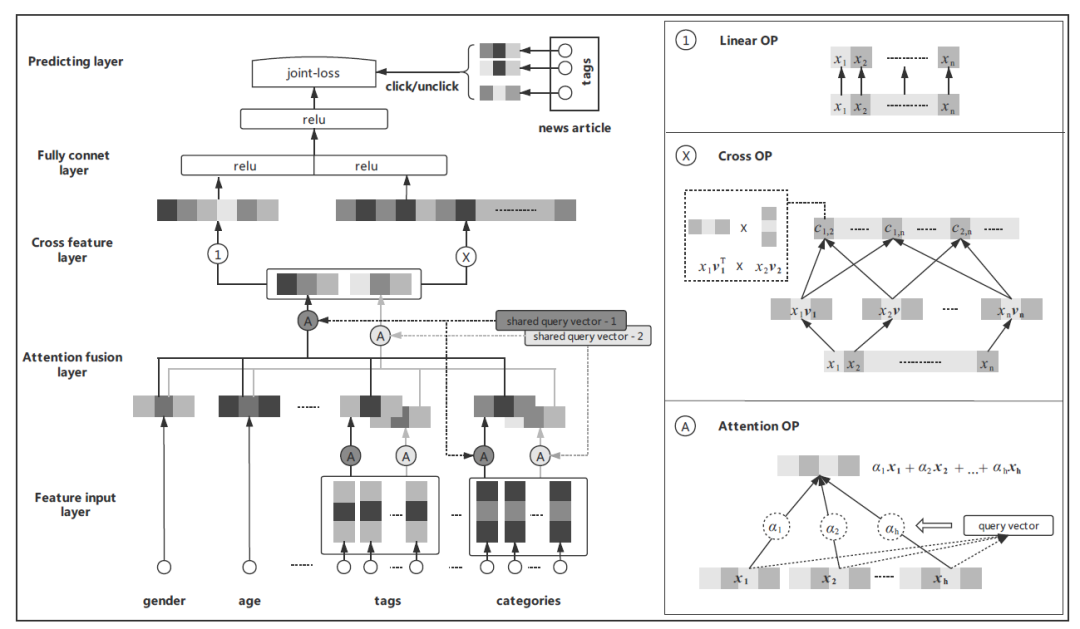
主要包括两部分,一个是用户域内域间的特征融合,另一个是用户的特征交叉:
(1)基于层次化attention的特征融合
首先对每个域内的多个离散特征进行 attention 融合,每个特征域输出一个 embedding,然后多个特征域的 embedding 再通过一个 attention 进行融合最终输出融合好的 embedding。
这里 attention 单元在融合多个特征时的结构如下图所示:
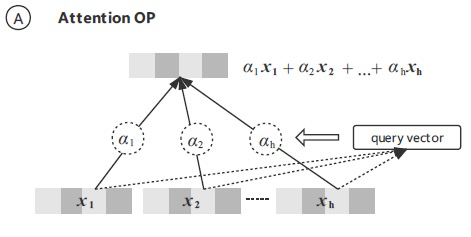
这里每个 attention 单元会有一个 query vector,这个向量是在模型学习中学出来的一个向量,用来衡量哪些特征对分类更有帮助。这里我们将不同域内和域间的 attention 单元的 query vector 共享,发现效果更好。我们猜想共享 query vector 可以让不同域的特征发生正向的相互影响。
此外,我们将设计多头 attention 机制,每个头都是一个完整的层次化 attention 机制,用来增加模型对多兴趣的学习能力。
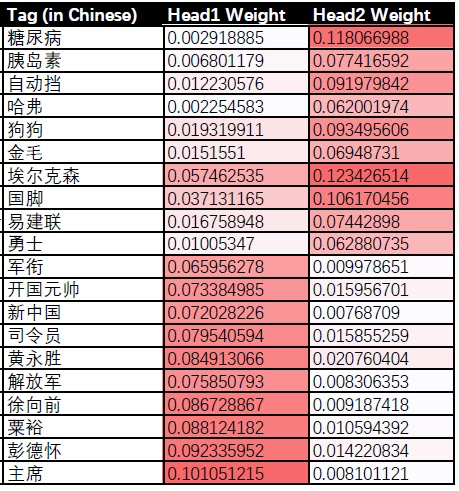
以上图为例,对于域内的标签特征,可以看出不同头侧重的兴趣不同。第一个头侧重历史兴趣,第二个则是体育和养生兴趣。
(2)用户特征交叉
当融合好用户的域内域间特征后,我们设计了一个特征交叉的模块。这个特征交叉的模块其实一个建模在稠密特征向量上面的特征交叉。
我们知道稠密特征向量的每一维其实也代表一个不可解释的空间。我们对特征向量的任意两维做特征交叉,使用类似FM的交叉方法,如下面公式,任意 i 和 j 维特征的交叉结果是,他们俩的特征隐向量内积乘上他俩数值的乘积。
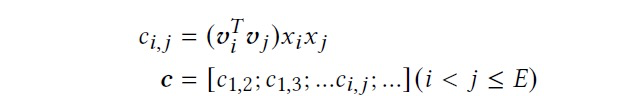
这里交叉后的特征和之前的线性特征各自归一化到同一量级,然后 concat 一起喂到下一层。
这里我们对比了一些别的方法,比如 AFM,NFM 这种基于 FM 的特征交叉,以及 DCN 和 AUTOINT 这种基于迭代的交叉网络的方法。
最终还是我们设计的这个特征交叉的模块效果更好。相对于我们设计的方法,上面的特征交叉的方法并没有显式的计算并保留两两维度的特征交叉值。
3. 用户点击标签偏好
在处理用户点击展现文章的时候,每一篇文章可能有不止一个标签。传统的训练方式就是把用户点击过的文章的标签全作为正例,曝光没点击的标签全作为负例。那这样训练的方式则默认用户对点击过文章的所有标签都感兴趣,这个假设显然是片面的。
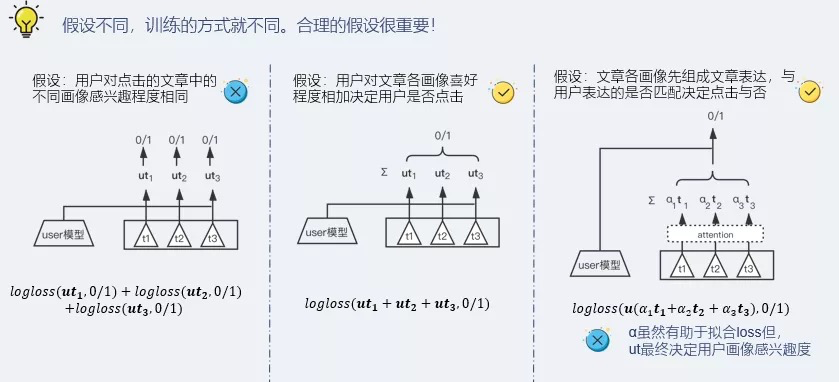
这里我们尝试过上面三种训练的方式:
第一种就是传统的拆分训练的方式,将一篇文章的多个标签拆分成多个正负例子;第二种就是我们最终使用的,用户对文章中的标签感兴趣程度相加决定用户最终的点击情况,这样模型自己去学习哪些标签应该更感兴趣。第三种是加上一个 attention 机制,相当在假设二的基础上去学习一个不同标签在文章中的权重,我们发现这种方式虽然让拟合的 loss 更好,但是准确率不如第二种,分析可能是因为学习到的权重信息并不能作用到最终用户标签的预估上导致的。
三、画像指标
在推荐系统中除了常用的点击率和时长之外,我们还需要考虑到画像的相关指标。这里我们主要使用画像有点数和画像有点率来衡量画像的线上准确率和覆盖情况。

四、实验
我们上面提到的特性进行实验,使用的是我们自己的数据和公开数据集 movielens 构造的数据。在域内域间融合上我们做了下面的实验:
1. attention特征融合实验
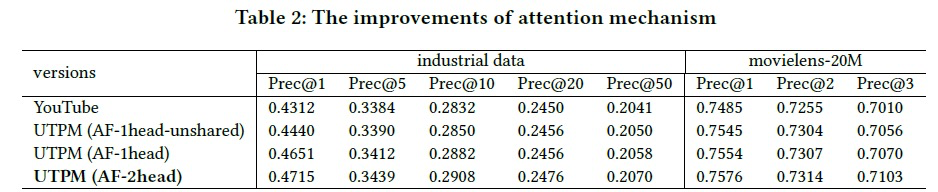
对比的是 youtube-dnn 模型,UTPM 是我们的画像模型(包含是否共享 query vector;使用单头还是多头 attention)。
2. 特征交叉实验
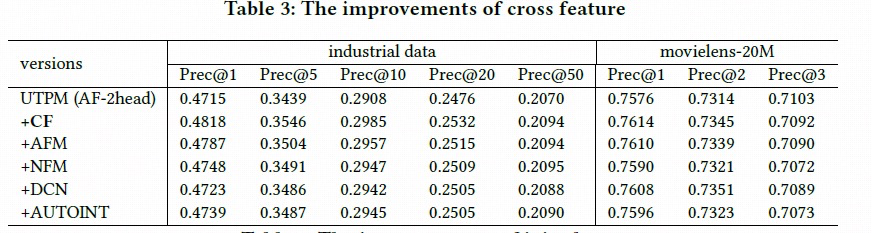
将我们模型的特征交叉模块替换成 AFM,NFM,DCN 和 AUTOINT,在两个数据集上进行离线指标测试。
3. 拆分训练和联合训练的效果对比

其中 base 是拆分训练,joint-loss 是联合文章中的多个标签一起训练的结果。
4. 线上ab实验
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BE%AE%E4%BF%A1%E7%9C%8B%E4%B8%80%E7%9C%8B%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E7%94%A8%E6%88%B7%E7%94%BB%E5%83%8F%E6%9E%84%E5%BB%BA%E6%8C%87%E5%8D%97/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


