推荐广告模型的降本提效压缩策略
背景
从全局看,深度学习模型规模在过去数年持续的指数膨胀。在模型效果提升的同时,为训练和推理的性能和成本都带来了严峻的挑战。作为应对,出现了大量的模型压缩策略,比如Zero系列的训练时策略。推理时量化、剪枝策略。以及训练推理协同策略,比如蒸馏等等。
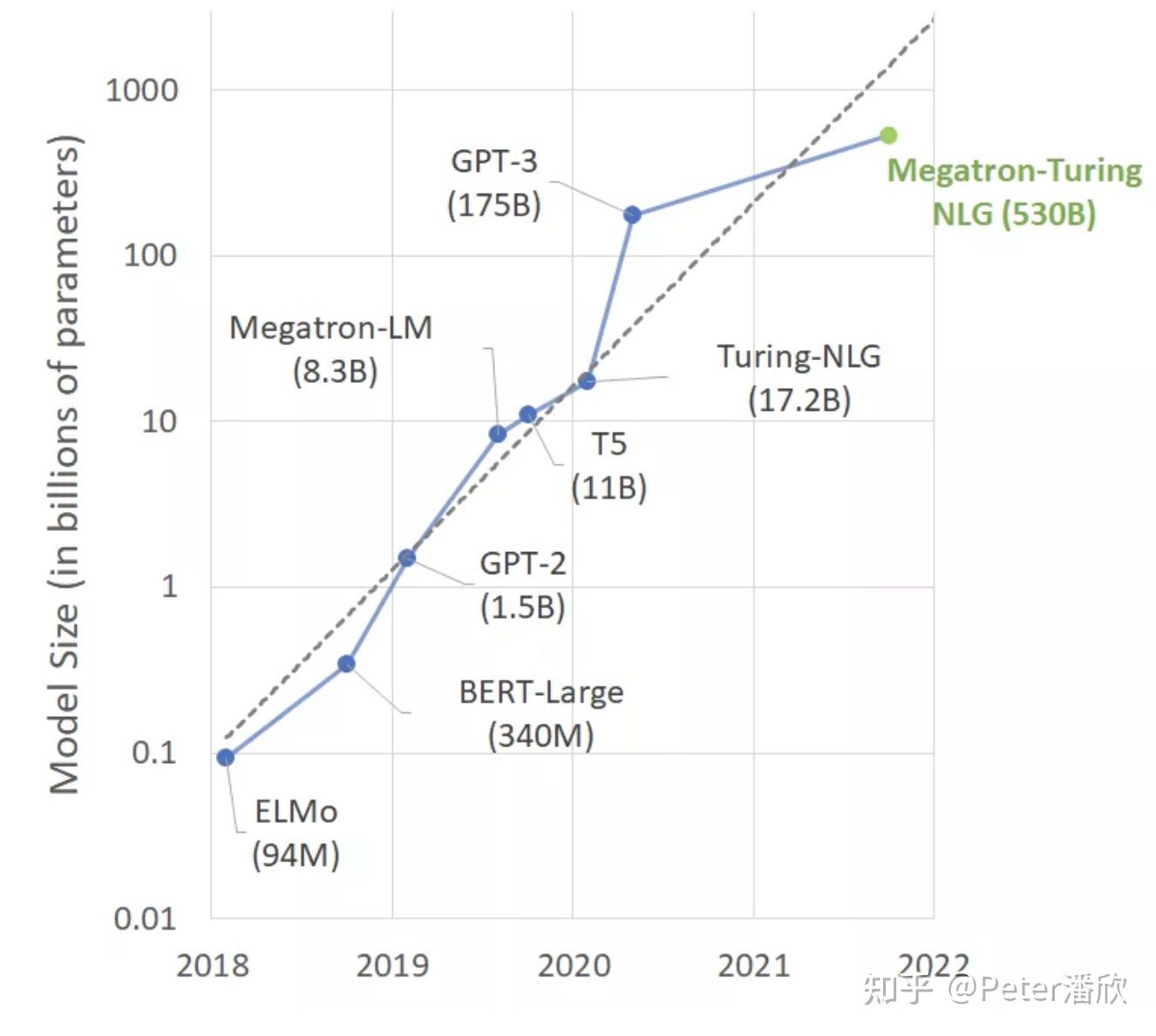
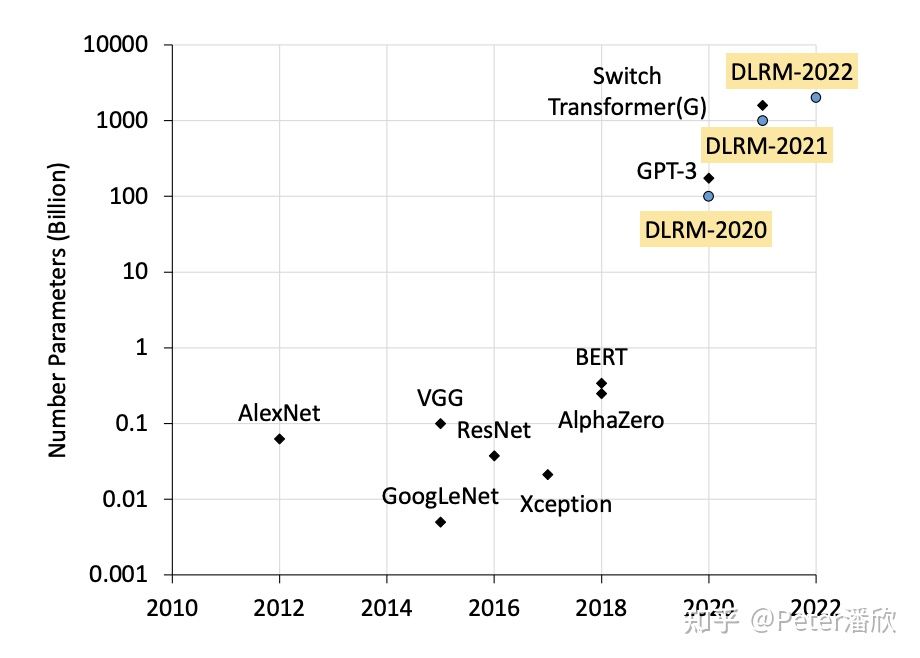
广告、推荐的深度学习模型的体积也非常庞大,从GB到TB不等。然而这类模型比较特殊在于通常99%以上的参数都在embedding层。广告、推荐模型在许多互联网公司占用了绝大部分的AI算力开销,超过了于CV、NLP等其他模型。主要有几方面原因:
- 广告、推荐模型本身embedding庞大,DNN层逐步向CV,NLP的复杂度看齐。
- 需要大量的A/B实验,模型需要持续、高频更新上线,导致单个场景需要多份训练和推理任务。
- 直接面向业务核心场景。每次用户操作(刷视频,新闻,电商,搜索等)都可能触发对应的推荐广告模型。
因为广告、推荐模型在embedding层如此显著的特性,导致这类模型的压缩技术也更有针对性。出了传统模型压缩技术外,这类模型需要特定的技术去解决embedding层在训练和推理阶段的压缩问题。然而广告、推荐模型的压缩技术却不是那么的广为人知。成熟和普及度也相对低一些。本文主要讨论这个领域的技术和应用成果。
特征分析
后面很多优化都需要利用一个关键点:每个特征的重要性是不一样的。
因此,表达每个特征的参数向量的重要性也是不一样的,这里重要性体现在几个方面:
- 特征的访问频率等统计值
- 特征对模型效果的影响
- 特征对应的参数当前的收敛程度
特征效果分析
这是个比较大的话题。推荐广告的特征通常在模型里通过embedding向量学习和表示,所以这里主要讨论如何分析embedding:
- 简单统计指标。许多简单的统计指标对于近似特征效果有一定作用。比如某个特征值出现的频率,出现在正样本中的频率等。
- 基于搜索机制。比如shapley等方法,通过排列组合不同的特征集合,并对比不同排列组合下的效果,来得出特征效果。这种方法相对比较暴力。
- 基于梯度值。这里面方法有不少变种,比如基于梯度和参数的乘积,或者是基于梯度的积分。直观上理解,重要的特征参数对于loss的影响比较大,对应的梯度值也会更突出。
训练时压缩
模型训练主要有两个特殊瓶颈点:
- 存储,embedding参数GB~TB级,加上优化器参数等,内存有较大的开销。
- 通信,除了DNN层的通信,embedding层也存在大量通信,按每个sample 1000个embedding向量算,128 batchsize需要10w个向量。而大规模分布式训练导致batch size进一步扩大100倍,达到1000w向量的单步通信量。单向量100~500Byte,总可以超过数GB每步。
存储压缩
动态Swapout
我们发现,特征访问频率存在显著的power-law分布,甚至更极端。超过80%的访问少于20%的特征。因此,基于这个特性,我们可以将低频的特征swapout到磁盘等持久性存储中。实践表明,swapout最低频的50%特征参数不会带来显著的磁盘IO。同时配合无量框架分布式训练是的“prepare机制”,这部分IO可以提前被完成,掩盖掉swapin的延迟。通过这种方式可以在降低显著内存空间的情况下,不影响训练的性能。
其实在小流量推理时,本地的SSD也可能用类似机制。
特征变长和淘汰
基于上面的特征效果分析结论,可以有相应的策略来节省存储:
- 变长。通常不重要或者说对模型效果影响不大的,我们可以降低对应向量的长度,用更少的参数,或者更低的精度去学习表示,对重要的用更多的参数。
- 这里有个细节。cardinality比较大的feature field/slot,从信息论角度,似乎也需要更长的向量。
- 淘汰。当内存预算快用满时,基于特征效果分析,可以优先将最不重要的那部分参数直接扔掉。这种方式对于推荐等具有一定时效性的场景往往简单有效。因为整个推荐系统本身也会清理过时的item,优先推送新热的item。只要阈值控制合理,通常不会对模型效果带来可观测到的效果下降。
其他
其他还要许多在embedding层面思考压缩的方法。比如:
- 基于特征统计分布的准入,在进入模型前就干掉。这和特征淘汰有一定的功能重叠。
- 特殊的优化器。这通常是一种组合技术,基于特征效果分析,针对不同特征使用更小开销的优化器(而不是adam),尽量在不影响模型效果的情况下降低优化器参数的开销。
通信压缩
基于参数重要性
前面提到了特征重要性分析。这部分结果也可以简单应用在通信压缩上,比如不重要的特征参数:
- 可以考虑使用fp16。
- 可以mask掉大部分接近0的gradient&weight
- 可以使用更异步的通信机制
特征稀疏化
通信是分布式训练里面一个比较突出的瓶颈,特别是对于基于CPU的分布式训练,2021年通常是基于以太网的25Gbps,而不是nvlink的数百G的带宽。
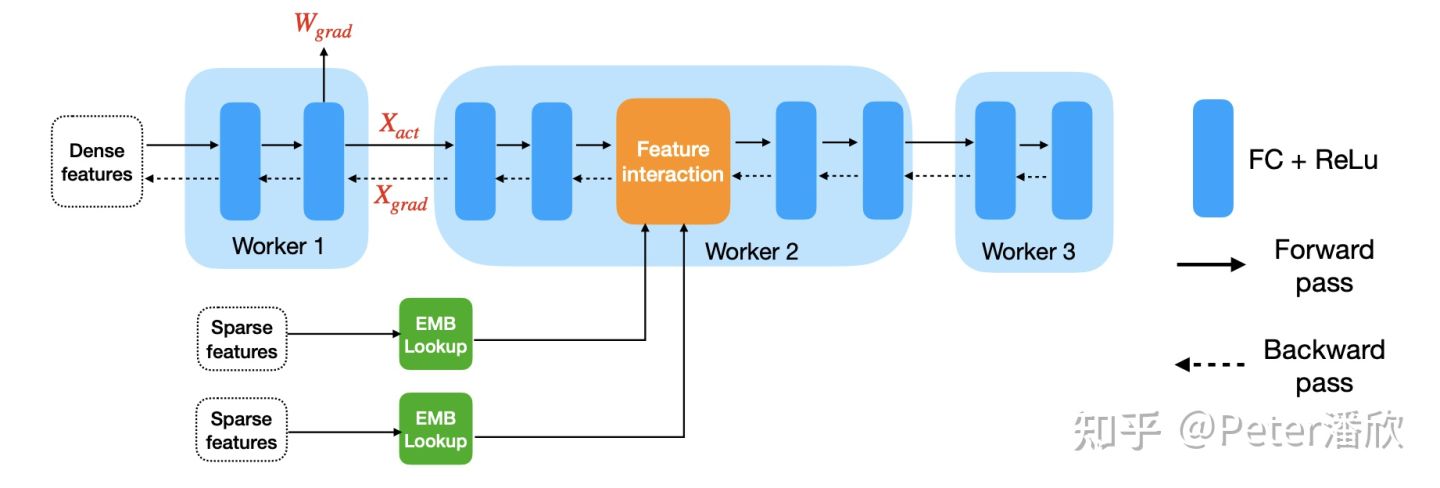
Facebook提出的稀疏化方案降低通信量达到90%以上,同时甚至能带来微弱的模型效果提升,比如Data Parallel Training时:
- 每L步根据希望达到的稀疏率,计算需要被通信的w值中最小的值。
- 小于该阈值的w全部被mask掉,不进行通信。而被mask掉的值会作为error记录下来。
- error会和下一步的w加和,进行错误补偿。然后w进入新一轮的稀疏化。
- 这里注意的是“阈值”每L步计算一次,避免所有参数排序开销(压缩、解压开销)

另外还提到Model Parallel Training时的稀疏化技术,甚至还能提升模型的收敛效果。总体来看如下图:
其他
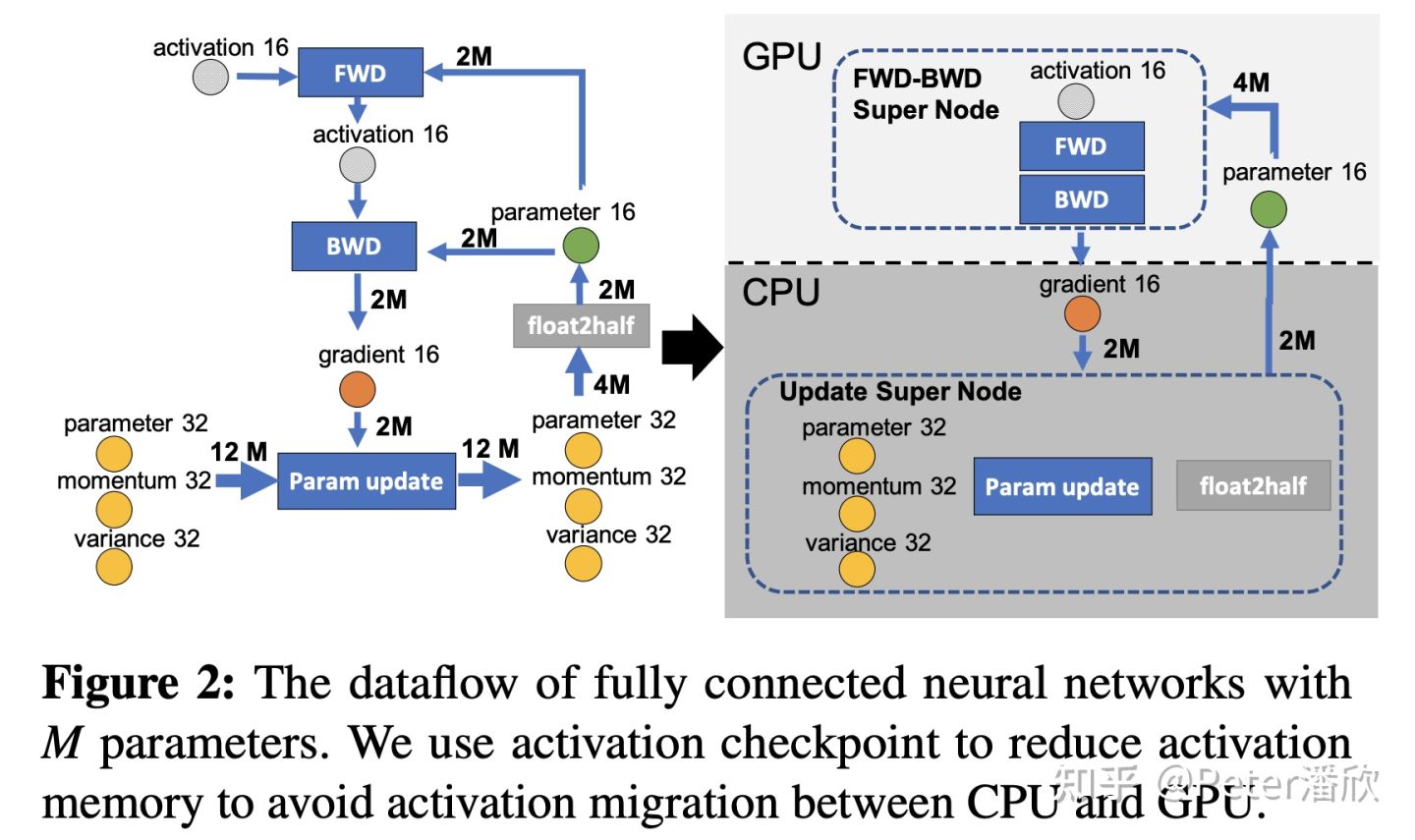
在分布式训练的各个环节都可能存在通信:
- 跨节点的通信
- 跨GPU设备的通信
- CPU和GPU间的通信
以及通信的不同重要性的内容:
- 参数通信
- activation通信
- gradient通信
- 优化器相关状态通信
对于各个流程数值分布分析,重要性分析和对模型的理解有助于挖掘更多的通信压缩点
 ---
---
推理时压缩
推理时压缩的方法非常的多,在推荐广告场景,更多是把传统方法针对领域进行定制化的引入。这里举几个比较有效的例子。
行量化
前面提到推荐广告模型有个巨大的embedding table。每一行的参数向量对应一个特征。传统训练完后是fp32的。我们希望把他量化压缩一下。
量化的方法就非常多了,有uniform, non-uniform。还有就是对outlier的处理策略也非常多样。这里一个关键点是一个向量quantize然后dequantize后和原向量的diff。直观上就是量化的信息损失。
很自然想到的就是为每行的向量分别量化。然后为每一行用一个简单搜索策略来最小化diff。具体的:
- 计算向量中的min, max。(这里其可以优化一下,减少搜索开销)
- 不断小步加大min,或者减小max。寻找量化MSE损失最少的min、max。进而得到量化scale。
- 通过scale值量化向量后保存,同时保存scale。
scale值每一行有一个,本身是个额外开销,所以也可以被压缩:
- 简单地换成fp16。
- 用一个长度256的codebook + int8 scale值。可能会带来效果损
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E5%B9%BF%E5%91%8A%E6%A8%A1%E5%9E%8B%E7%9A%84%E9%99%8D%E6%9C%AC%E6%8F%90%E6%95%88%E5%8E%8B%E7%BC%A9%E7%AD%96%E7%95%A5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


