推荐系统全链路召回粗排精排级联漏斗下篇
转自:知乎-水哥
链接: https://zhuanlan.zhihu.com/p/396951216
说明:本文仅用于知识交流,如有侵权,联系删除
写在前面
召回区分主路和旁路,主路的作用是个性化+向上管理,而旁路的作用是查缺补漏,推荐系统的前几个操作可能就决定了整个系统的走向,在初期一定要三思而后行。
做自媒体,打广告,漏斗的入口有多大很重要。美妆,游戏,篮球入口都非常大,做刷题的自媒体会把自己饿(说的就是我自己)
主旁路召回
召回这里稍微有些复杂,因为召回是多路的。首先我们要解释主路和旁路的差别,主路的意义和粗排类似,可以看作是一个入口更大,但模型更加简单的粗排。主路的意义是为粗排分担压力。但是旁路却不是这样的,旁路出现的时机往往是当主路存在某种机制上的问题,而单靠现在的这个模型很难解决的时候。举个例子,主路召回学的不错,但是它可能由于某种原因,特别讨厌影视剧片段这一类内容,导致了这类视频无法上升到粗排上。那这样的话整个系统推不出影视剧片段就是一个问题。从多路召回的角度来讲,我们可能需要单加一路专门召回影视剧的,并且规定:主路召回只能出3000个,这一路新加的固定出500个,两边合并起来进入到粗排中去。这个栗子,是出现旁路的一个动机。这个过程我们可以用下图来表示:
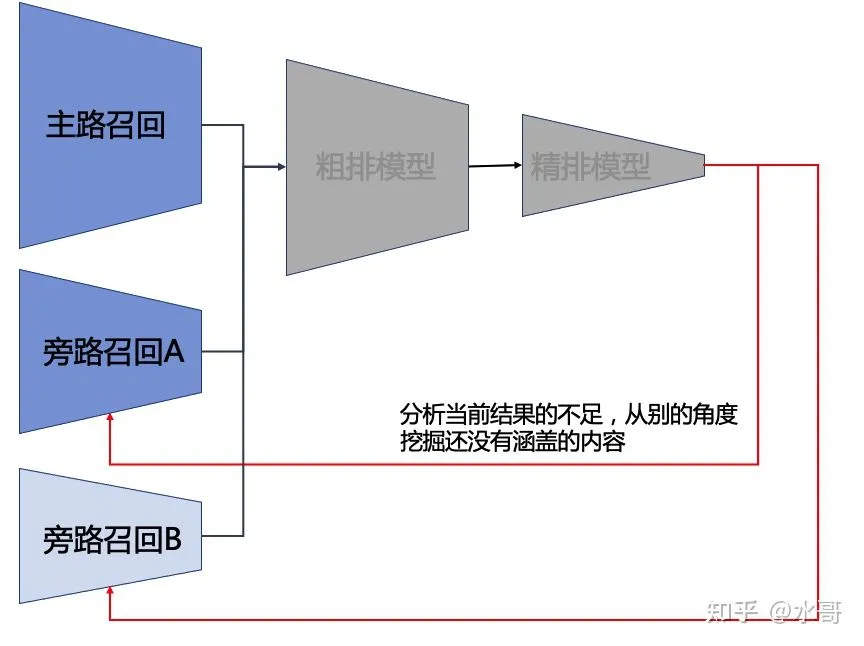 img在上面的图中,梯形的大小表示透出率的大小。
img在上面的图中,梯形的大小表示透出率的大小。
典型的召回都有哪些?
第一种召回,是非个性化的。比如对于新用户,我们要确保用最高质量的视频把他们留住,那么我们可以划一个“精品池”出来,根据他们的某种热度排序,作为一路召回。做法就是新用户的每次请求我们都把这些精品池的内容当做结果送给粗排。这样的召回做起来最容易,用sql就可以搞定。
第二种召回,是i2i,i指的是item,严格意义上应该叫u2i2i。指的是用用户的历史item,来找相似的item。比如说我们把用户过去点过赞的视频拿出来,去找画面上,BGM上,或者用户行为结构上相似的视频。等于说我们就认为用户还会喜欢看同样类型的视频。这种召回,既可以从内容上建立相似关系(利用深度学习),也可以用现在比较火的graph来构建关系。这种召回负担也比较小,图像上谁和谁相似完全可以离线计算,甚至都不会随着时间变化。
第三种召回是u2i,即纯粹从user和item的关系出发。我们所说的双塔就是一个典型的u2i。在用户请求过来的时候,计算出user的embedding,然后去一个实现存好的item embedding的空间,寻找最相似的一批拿出来。由于要实时计算user特征,它的负担要大于前面两者,但这种召回个性化程度最高,实践中效果也是非常好的。
召回的学习目标
一般来说,个性化程度最高的双塔,都会成为主路。它的学习目标,可以类比粗排和精排的关系去学习召回和粗排的关系。而基于graph或者图像相似度的召回,则有各自自己的学习目标。
召回的评估方式
主路召回,我们可以采用粗排的方式,以粗排的序计算NDCG,或者TopN重叠率。但是旁路召回在线下是比较难以评估的。如果采用一样的方式评估旁路,那旁路的作用岂不是和主路差不多?那旁路存在的意义是啥呢?不如把改进点加到主路里面去好了。在实际中,旁路召回虽然线下也会计算自己的AUC,NDCG等指标。但是往往都是只做一个参考,还是要靠线上实验来验证这路召回是不是有用。
在线上,除了AB需要看效果以外,有一个指标是召回需要注意的: 透出率 , 指的是最终展示的结果中,有多少比例是由这一路召回提供的 。如果我们新建了一路召回,他的透出率能达到30%,AB效果也比较好,那我们可以说这一路召回补充了原有系统的一些不足。反过来,如果你的透出率只有1点几,2点几,那不管AB是涨是跌,我都很难相信结果和这一路召回有关系,似乎也没有新加的必要。
多路的结果如何融合?
多个召回之间的结果综合的时候,要进行去重,可能有多个路返回了用样的item,这时候要去掉冗余的部分。但是,去重的步骤比较是需要经过设计的。有以下几种方法来进行融合:
- 先来先到:按照人为设计,或者业务经验来制定一个顺序,先取哪一路,再取哪一路。后面取得时候如果结果前面已经有了,就要去掉。
- 按照每一路打分平均:比如第一路输出A=0.6,B=0.4,第二路输出B=0.6,C=0.4,那么由于B出现了两次,B就需要平均一下,最后得到,A=0.6,B=0.5,C=0.4
- 投票:和上面的例子类似,但是B出现了两次。我们认为B获得了两个方面的认可,因此它的排序是最靠前的。
注意上面的item最后留下的是哪一路的,透出率就算在谁头上。
召回的问题
假设我们有三路召回ABC,在我们这个时空,业务部署的顺序是A-B-C;在另一个平行时空,业务的部署顺序是C-B-A。问:其他变量都不变的情况下,最终业务的收益是一样的吗?
我个人的理解是,几乎不会一样。 先部署的召回会影响整个系统,后来的不管是什么方案,都要在不利于自己的情况下“客场作战” 。举一个极端的例子,A是一个特别喜欢土味视频的召回,我们第一版实现的是它。结果A上线以后,不喜欢土味视频的用户全都跑路了。在迭代的过程中我们就会想,唉是不是我们也可以加一路B来专门召回高雅类型视频啊。这时候上线一做,并没有正向,因为喜欢高雅的用户已经没了。这就是部署顺序给整个系统带来后效性的一个极端例子。如果我们一开始换一种做法,先上一路中规中矩的召回C,然后把AB当做补充的旁路加进来,效果是有可能更好的。
因此在最初的时候的操作一定要小心。否则会对算法同学带来很大的后续负担,比如上面这个例子,有一天领导说哎我们现在不够高雅你来搞一个,那你就只能为初期的不正确决定买单了。这个问题并不是说粗排,精排就不会出现。而是在实践中召回这里更容易出现。因为召回的某些方法实现很快,同学很可能一看有收益就推上去了。
入口的规模至关重要
前面讲的漏斗都是针对于item筛选这个角度。从生产者的角度也存在这么一个漏斗:
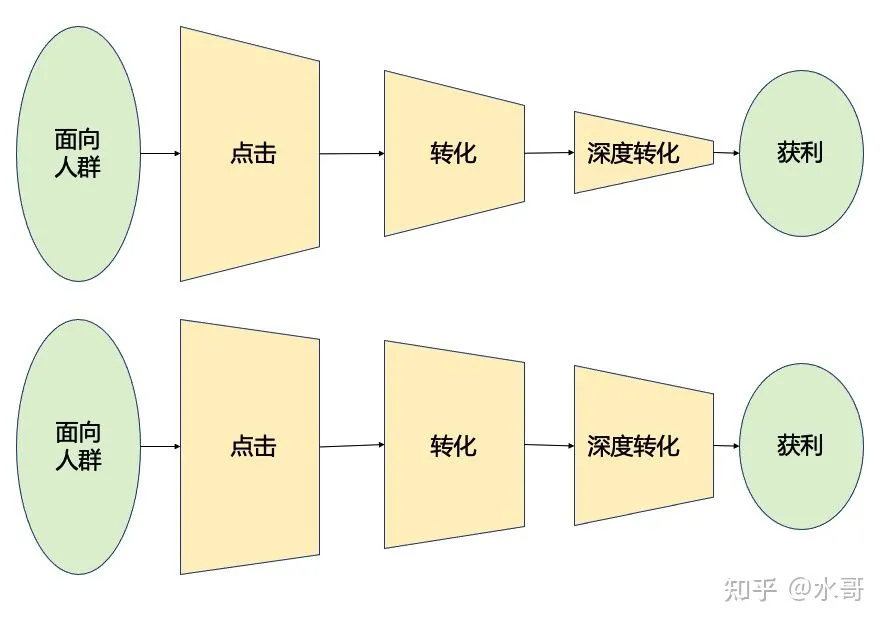 img一开始是吸引所面向的人群,然后一部分人会点击,点击的人中,一部分人会转化,可能后面会有深度转化等等。最终目的是广告主的获益。这里要说明一下,深度转化是相对于某些行业才有的,比如说电商里面转化了就是购买行为发生了,那已经获利了就不需要后面环节了。而对于游戏,转化一般指的是下载,用户后续氪金了叫深度转化,对于游戏行业这个时候才算获利。
img一开始是吸引所面向的人群,然后一部分人会点击,点击的人中,一部分人会转化,可能后面会有深度转化等等。最终目的是广告主的获益。这里要说明一下,深度转化是相对于某些行业才有的,比如说电商里面转化了就是购买行为发生了,那已经获利了就不需要后面环节了。而对于游戏,转化一般指的是下载,用户后续氪金了叫深度转化,对于游戏行业这个时候才算获利。
这个漏斗中有两个因素决定最终获利的大小, 一个是入口的规模,一个是梯形的斜率 。其实在图中,梯形的斜率就可以表示点击率和转化率的大小。如果你的产品很好,这两个指标很高,那留下来的就更多,越能获利。
但是点击率转化率这些东西很难优化(虽然大品牌都有专门的团队来负责)。更多的生产�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%85%A8%E9%93%BE%E8%B7%AF%E5%8F%AC%E5%9B%9E%E7%B2%97%E6%8E%92%E7%B2%BE%E6%8E%92%E7%BA%A7%E8%81%94%E6%BC%8F%E6%96%97%E4%B8%8B%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


