推荐系统遇上深度学习二十贝叶斯个性化排序算法原理及实战
2018.06.29 23:27
排序推荐算法大体上可以分为三类,第一类排序算法类别是点对方法(Pointwise Approach),这类算法将排序问题被转化为分类、回归之类的问题,并使用现有分类、回归等方法进行实现。第二类排序算法是成对方法(Pairwise Approach),在序列方法中,排序被转化为对序列分类或对序列回归。所谓的pair就是成对的排序,比如(a,b)一组表明a比b排的靠前。第三类排序算法是列表方法(Listwise Approach),它采用更加直接的方法对排序问题进行了处理。它在学习和预测过程中都将排序列表作为一个样本。排序的组结构被保持。
之前我们介绍的算法大都是Pointwise的方法,今天我们来介绍一种Pairwise的方法:贝叶斯个性化排序(Bayesian Personalized Ranking, 以下简称BPR)
1、BPR算法简介
1.1 基本思路
在BPR算法中,我们将任意用户u对应的物品进行标记,如果用户u在同时有物品i和j的时候点击了i,那么我们就得到了一个三元组,它表示对用户u来说,i的排序要比j靠前。如果对于用户u来说我们有m组这样的反馈,那么我们就可以得到m组用户u对应的训练样本。
这里,我们做出两个假设:
-
每个用户之间的偏好行为相互独立,即用户u在商品i和j之间的偏好和其他用户无关。
-
同一用户对不同物品的偏序相互独立,也就是用户u在商品i和j之间的偏好和其他的商品无关。
为了便于表述,我们用>u符号表示用户u的偏好,上面的可以表示为:i >u j。
在BPR中,我们也用到了类似矩阵分解的思想,对于用户集U和物品集I对应的U*I的预测排序矩阵,我们期望得到两个分解后的用户矩阵W(|U|×k)和物品矩阵H(|I|×k),满足:
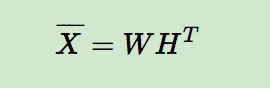
那么对于任意一个用户u,对应的任意一个物品i,我们预测得出的用户对该物品的偏好计算如下:
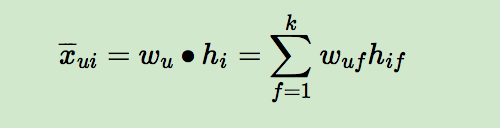
而模型的最终目标是寻找合适的矩阵W和H,让X-(公式打不出来,这里代表的是X上面有一个横线,即W和H矩阵相乘后的结果)和X(实际的评分矩阵)最相似。看到这里,也许你会说,BPR和矩阵分解没有什区别呀?是的,到目前为止的基本思想是一致的,但是具体的算法运算思路,确实千差万别的,我们慢慢道来。
1.2 算法运算思路
BPR 基于最大后验估计P(W,H|>u)来求解模型参数W,H,这里我们用θ来表示参数W和H, >u代表用户u对应的所有商品的全序关系,则优化目标是P(θ|>u)。根据贝叶斯公式,我们有:
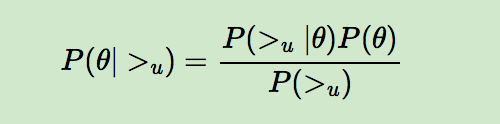
由于我们求解假设了用户的排序和其他用户无关,那么对于任意一个用户u来说,P(>u)对所有的物品一样,所以有:
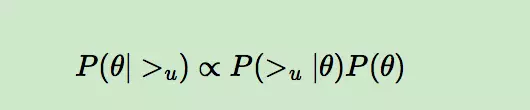
这个优化目标转化为两部分。第一部分和样本数据集D有关,第二部分和样本数据集D无关。
第一部分
对于第一部分,由于我们假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以有:
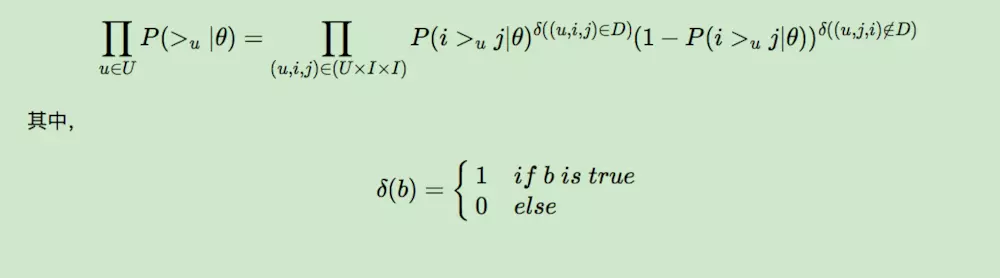
上面的式子类似于极大似然估计,若用户u相比于j来说更偏向i,那么我们就希望P(i >u j|θ)出现的概率越大越好。
上面的式子可以进一步改写成:
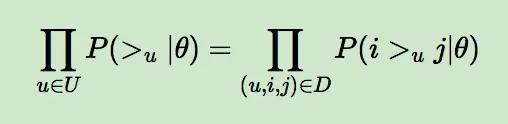
而对于P(i >u j|θ)这个概率,我们可以使用下面这个式子来代替:
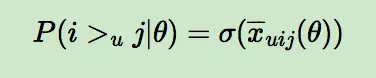
其中,σ(x)是sigmoid函数,σ里面的项我们可以理解为用户u对i和j偏好程度的差异,我们当然希望i和j的差异越大越好,这种差异如何体现,最简单的就是差值:
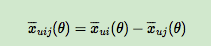
省略θ我们可以将式子简略的写为:
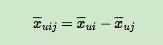
因此优化目标的第一项可以写作:

哇,是不是很简单的思想,对于训练数据中的,用户更偏好于i,那么我们当然希望在X-矩阵中ui对应的值比uj对应的值大,而且差距越大越好!
第二部分
回想之前我们通过贝叶斯角度解释正则化的文章: https://www.jianshu.com/p/4d562f2c06b8
当θ的先验分布是正态分布时,其实就是给损失函数加入了正则项,因此我们可以假定θ的先验分布是正态分布:
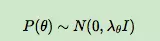
所以:
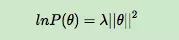
因此,最终的最大对数后验估计函数可以写作:
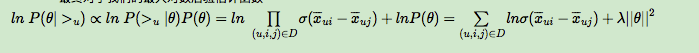
剩下的我们就可以通过梯度上升法(因为是要让上式最大化)来求解了。我们这里就略过了,BPR的思想已经很明白了吧,哈哈!让我们来看一看如何实现吧。
2、算法实现
本文的github地址为: https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-BPR-Demo
所用到的数据集是movieslen 100k的数据集,下载地址为: http://grouplens.org/datasets/movielens/
数据预处理
首先,我们需要处理一下数据,得到每个用户打分过的电影,同时,还需要得到用户的数量和电影的数量。
def load_data():
user_ratings = defaultdict(set)
max_u_id = -1
max_i_id = -1
with open('data/u.data','r') as f:
for line in f.readlines():
u,i,_,_ = line.split("\t")
u = int(u)
i = int(i)
user_ratings[u].add(i)
max_u_id = max(u,max_u_id)
max_i_id = max(i,max_i_id)
print("max_u_id:",max_u_id)
print("max_i_idL",max_i_id)
return max_u_id,max_i_id,user_ratings
下面我们会对每一个用户u,在user_ratings中随机找到他评分过的一部电影i,保存在user_ratings_test,后面构造训练集和测试集需要用到。
def generate_test(user_ratings):
"""
对每一个用户u,在user_ratings中随机找到他评分过的一部电影i,保存在user_ratings_test,我们为每个用户取出的这一个电影,是不会在训练集中训练到的,作为测试集用。
"""
user_test = dict()
for u,i_list in user_ratings.items():
user_test[u] = random.sample(user_ratings[u],1)[0]
return user_test
构建训练数据
我们构造的训练数据是的三元组,i可以根据刚才生成的用户评分字典得到,j可以利用负采样的思想,认为用户没有看过的电影都是负样本:
def generat
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E9%81%87%E4%B8%8A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%BA%8C%E5%8D%81%E8%B4%9D%E5%8F%B6%E6%96%AF%E4%B8%AA%E6%80%A7%E5%8C%96%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E6%88%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


