机器学习一文理解的原理
现在网上介绍gbdt算法的文章并不算少,但总体看下来,千篇一律的多,能直达精髓的少,有条理性的就更稀少了。我希望通过此篇文章,能抽丝剥茧般的向初学者介绍清楚这个算法的原理所在。如果仍不清楚可以在文后留言。
1、如何在不改变原有模型的结构上提升模型的拟合能力
假设现在你有样本集
 ,然后你用一个模型,如
,然后你用一个模型,如
 去拟合这些数据,使得这批样本的平方损失函数(即
去拟合这些数据,使得这批样本的平方损失函数(即
 )最小。但是你发现虽然模型的拟合效果很好,但仍然有一些差距,比如预测值
)最小。但是你发现虽然模型的拟合效果很好,但仍然有一些差距,比如预测值
 =0.8,而真实值
=0.8,而真实值

 =1.4,
=1.4,
 =1.3等等。另外你不允许更改原来模型
=1.3等等。另外你不允许更改原来模型
 的参数,那么你有什么办法进一步来提高模型的拟合能力呢。
的参数,那么你有什么办法进一步来提高模型的拟合能力呢。
既然不能更改原来模型的参数,那么意味着必须在原来模型的基础之上做改善,那么直观的做法就是建立一个新的模型
 来拟合
来拟合
 未完全拟合真实样本的残差,即
未完全拟合真实样本的残差,即
 。所以对于每个样本来说,拟合的样本集就变成了:
。所以对于每个样本来说,拟合的样本集就变成了:
 .
.
2、基于残差的gbdt
在第一部分,
 被称为残差,这一部分也就是前一模型(
被称为残差,这一部分也就是前一模型(
 )未能完全拟合的部分,所以交给新的模型来完成。
)未能完全拟合的部分,所以交给新的模型来完成。
我们知道gbdt的全称是Gradient Boosting Decision Tree,其中gradient被称为梯度,更一般的理解,可以认为是一阶导,那么这里的残差与梯度是什么关系呢。在第一部分,我们提到了一个叫做平方损失函数的东西,具体形式可以写成
 ,熟悉其他算法的原理应该知道,这个损失函数主要针对回归类型的问题,分类则是用熵值类的损失函数。具体到平方损失函数的式子,你可能已经发现它的一阶导其实就是残差的形式,所以基于残差的gbdt是一种特殊的gbdt模型,它的损失函数是平方损失函数,常用来处理回归类的问题。具体形式可以如下表示:
,熟悉其他算法的原理应该知道,这个损失函数主要针对回归类型的问题,分类则是用熵值类的损失函数。具体到平方损失函数的式子,你可能已经发现它的一阶导其实就是残差的形式,所以基于残差的gbdt是一种特殊的gbdt模型,它的损失函数是平方损失函数,常用来处理回归类的问题。具体形式可以如下表示:


损失函数的一阶导:
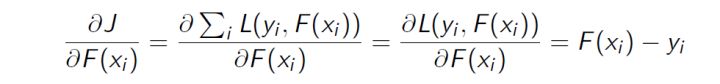
正好残差就是负梯度:
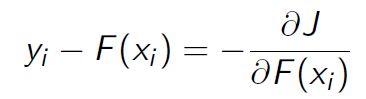
3、为什么基于残差的gbdt不是一个好的选择
基于残差的gbdt在解决回归问题上不算是一个好的选择,一个比较明显的缺点就是对异常值过于敏感。我们来看一个例子:

很明显后续的模型会对第4个值关注过多,这不是一种好的现象,所以一般回归类的损失函数会用绝对损失或者huber损失函数来代替平方损失函数:

4、Boosting的加法模型
如前面所述,gbdt模型可以认为是是由k个基模型组成的一个加法运算式:

其中F是指所有基模型组成的函数空间。
那么一般化的损失函数是预测值
 与 真实值
与 真实值
 之间的关系,如我们前面的平方损失函数,那么对于n个样本来说,则可以写成:
之间的关系,如我们前面的平方损失函数,那么对于n个样本来说,则可以写成:

更一般的,我们知道一个好的模型,在偏差和方差上有一个较好的平衡,而算法的损失函数正是代表了模型的偏差面,最小化损失函数,就相当于最小化模型的偏差,但同时我们也需要兼顾模型的方差,所以目标函数还包括抑制模型复杂度的正则项,因此目标函数可以写成:

其中
 代表了基模型的复杂度,若基模型是树模型,则树的深度、叶子节点数等指标可以反应树的复杂程度。
代表了基模型的复杂度,若基模型是树模型,则树的深度、叶子节点数等指标可以反应树的复杂程度。
对于Boosting来说,它采用的是前向优化算法,即从前往后,逐渐建立基模型来优化逼近目标函数,具体过程如下:

那么,在每一步,如何学习一个新的模型呢,答案的关键还是在于gbdt的目标函数上,即新模型的加入总是以优化目标函数为目的的。
我们以第t步的模型拟合为例,在这一步,模型对第
 个样本
个样本
 的预测为:
的预测为:

其中
 就是我们这次需要加入的新模型,即需要拟合的模型,此时,目标函数就可以写成:
就是我们这次需要加入的新模型,即需要拟合的模型,此时,目标函数就可以写成:

即此时最优化目标函数,就相当于求得了
 。
。
5、什么是gbdt的目标函数
我们知道泰勒公式中,若
 很小时,我们只保留二阶导是合理的(gbdt是一阶导,xgboost是二阶导,我们以二阶导为例,一阶导可以自己去推,因为更简单),即:
很小时,我们只保留二阶导是合理的(gbdt是一阶导,xgboost是二阶导,我们以二阶导为例,一阶导可以自己去推,因为更简单),即:

那么在等式(1)中,我们把
 看成是等式(2)中的x,
看成是等式(2)中的x,
 看成是
看成是
 ,因此等式(1)可以写成:
,因此等式(1)可以写成:

其中
 为损失函数的一阶导,
为损失函数的一阶导,
 为损失函数的二阶导,注意这里的导是对
为损失函数的二阶导,注意这里的导是对
 求导。我们以 平方损失函数为例
求导。我们以 平方损失函数为例
 ,则
,则
 ,
,
 。
。
由于在第t步
 其实是一个已知的值,所以
其实是一个已知的值,所以
 是一个常数,其对函数优化不会产生影响,因此,等式(3)可以写成:
是一个常数,其对函数优化不会产生影响,因此,等式(3)可以写成:

所以我么只要求出每一步损失函数的一阶和二阶导的值(由于前一步的
 是已知的,所以这两个值就是常数)代入等式4,然后最优化目标函数,就可以得到每一步的
是已知的,所以这两个值就是常数)代入等式4,然后最优化目标函数,就可以得到每一步的
 ,最后根据加法模型得到一个整体模型。
,最后根据加法模型得到一个整体模型。
6、如何用决策树来表示上一步的目标函数
假设我们boosting的基模型用决策树来实现,则一颗生成好的决策树,即结构确定,也就是说树的叶子结点其实是确定了的。假设这棵树的叶子结点有
 片叶子,而每片叶子对应的值
片叶子,而每片叶子对应的值
 。熟悉决策树的同学应该清楚,每一片叶子结点中样本的预测值都会是一样的,在分类问题中,是某一类,在回归问题中,是某一个值( 在gbdt中都是回归树,即分类问题转化成对概率的回归了),那么肯定存在这样一个函数
。熟悉决策树的同学应该清楚,每一片叶子结点中样本的预测值都会是一样的,在分类问题中,是某一类,在回归问题中,是某一个值( 在gbdt中都是回归树,即分类问题转化成对概率的回归了),那么肯定存在这样一个函数
 ,即将
,即将
 中的每个样本映射到每一个叶子结点上,当然
中的每个样本映射到每一个叶子结点上,当然
 和
和
 我们都是不知道的,但我们也不关心,这里只是说明一下决策树表达数据结构的方法是怎么样的,不理解也没有问题。
我们都是不知道的,但我们也不关心,这里只是说明一下决策树表达数据结构的方法是怎么样的,不理解也没有问题。
那么
 就可以转成
就可以转成

 代表了每个样本在哪个叶子结点上,而
代表了每个样本在哪个叶子结点上,而

 值,所以
值,所以
 就代表了每个样本的取值
就代表了每个样本的取值
 (即预测值)。
(即预测值)。
如果决策树的复杂度可以由正则项来定义
 ,即决策树模型的复杂度由生成的树的叶子节点数量和叶子节点对应的值向量的L2范数决定。
,即决策树模型的复杂度由生成的树的叶子节点数量和叶子节点对应的值向量的L2范数决定。
我们假设
 为第
为第
 个叶子节点的样本集合,则等式4根据上面的一些变换可以写成:
个叶子节点的样本集合,则等式4根据上面的一些变换可以写成:

即我们之前样本的集合,现在都改写成叶子结点的集合,由于一个叶子结点有多个样本存在,因此才有了
 和
和
 这两项。
这两项。
定义
 ,
,
 ,则等式5可以写成:
,则等式5可以写成:

如果树的结构是固定的,即
 是确定的,或者说我们已经知道了每个叶子结点有哪些样本,所以
是确定的,或者说我们已经知道了每个叶子结点有哪些样本,所以
 和
和
 是确定的,但
是确定的,但
 不确定(
不确定(
 其实就是我们需要预测的值),那么令目标函数一阶导为0,则可以求得叶子结点
其实就是我们需要预测的值),那么令目标函数一阶导为0,则可以求得叶子结点
 对应的值:
对应的值:
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


