机器学习模型如何优化干货总结
NLP杂货铺 微信号:gh_90d682be2296
历时几个月的NLP中文预训练模型泛化能力挑战赛【25】已经圆满结束,进入决赛的各个队伍都提供了很好的方案模型。
这次比赛是CLUE与阿里云平台、乐言科技联合发起的第一场针对中文预训练模型泛化能力的挑战赛。
赛题以自然语言处理为背景,要求选手通过算法实现泛化能力强的中文预训练模型。通过这道赛题可以引导大家更好地理解预训练模型的运作机制,探索深层次的模型构建和模型训练,而不仅仅是针对特定任务进行简单微调。
赛后,CLUE【26】就将各个选手的方案进行总结归拢,提取出各种对任务有效的 方案方法。大体上,各种优化方法根据机器学习的三要素来划分:模型、策略(loss)、算法(优化方法),再加上前期的数据,后期后处理跟其他正则化方法。
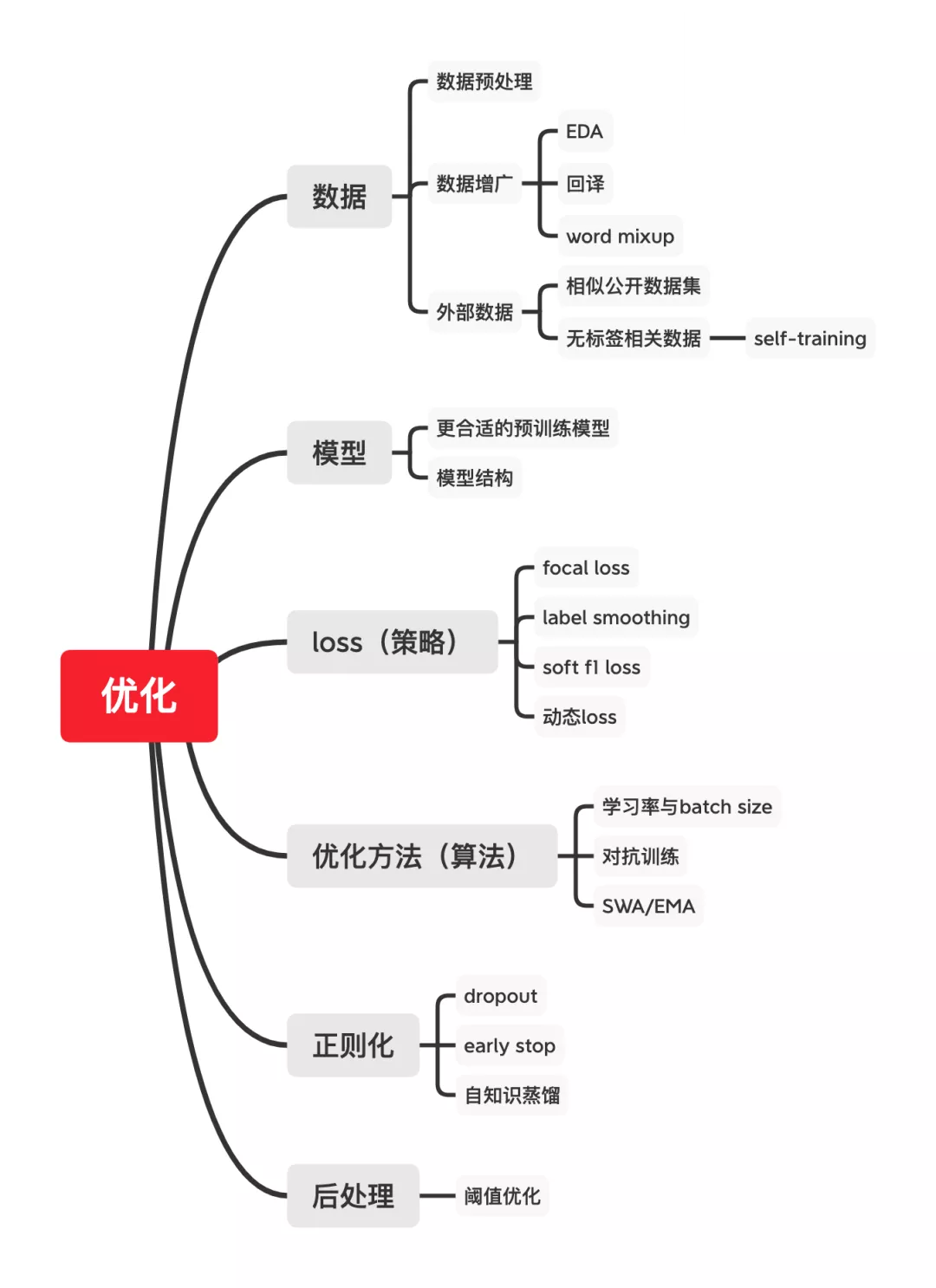
总的来说,对任务最有增益的还是大数据与大预训练模型,能够提高4%左右的指标,其他的各种trick也都可以锦上添花,可以提高0.5-1%左右的指标。下面我们就直接介绍各种方法。
数据
都说数据是模型的上限,可见数据对模型的重要性,其中数据的质量与数量都对模型至关重要。
数据预处理
数据预处理,主要会删除错误、冗余数据,修改特殊表示,整理数据格式等等,从而提高数据的整体质量,以此来提高模型的效果。在本次比赛中,数据相对比较干净,相关处理比较少,就是简单将emoj替换成相应字符,以及将中文标点替换成英文格式等操作,在选手的方案中,该方法与下面的数据增广一起,可以提高模型0.2%左右的指标。常用的数据预处理内容参考【1】【2】。
数据增广
数据增广,就是通过修改样本而不改变其标签的方式,提高了样本的多样性,在保持一定数据质量的条件下,提高了数据的数量,从而提高了模型的鲁棒性。最常用数据增广的方式主要有:
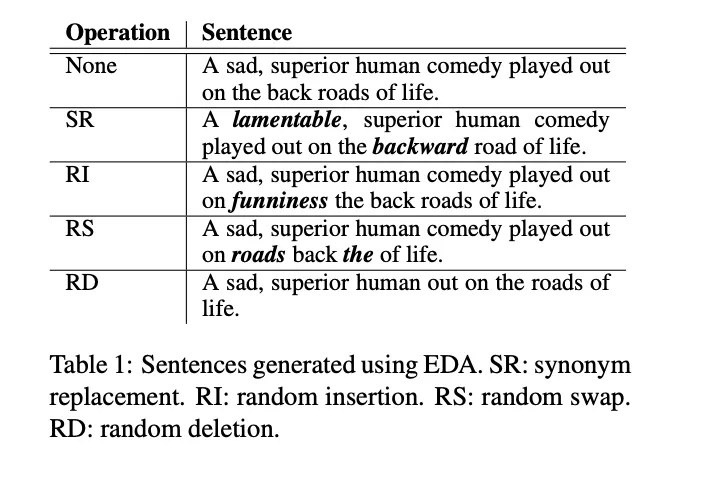
- EDA【3】:简单数据增广,通过随机增删字词,替换随机词或近义词,以及调整字词顺序来实现。
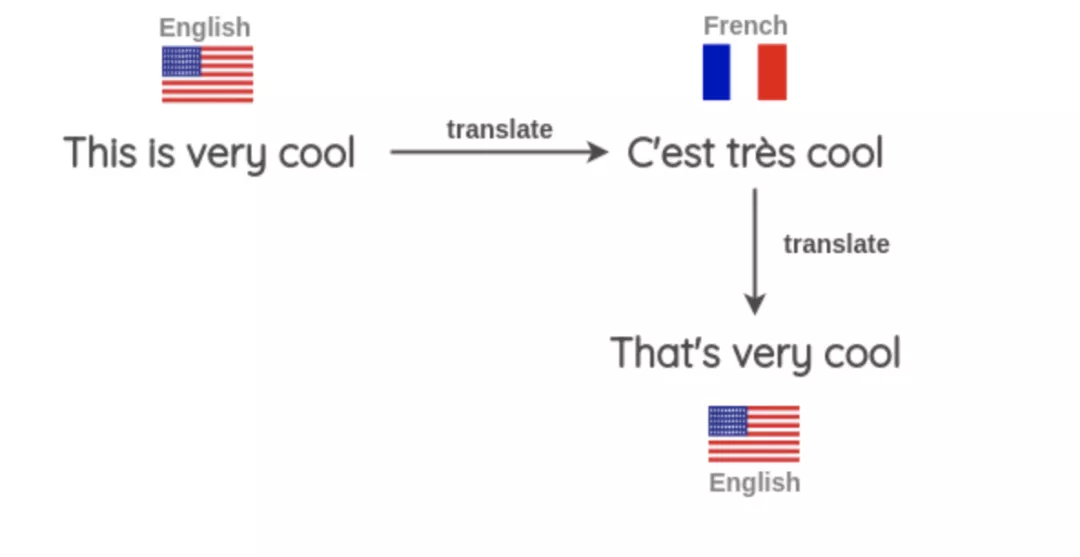
 2. 回译【4】:将样本翻译成第二种语言,然后再翻译回来,形成新样本。
2. 回译【4】:将样本翻译成第二种语言,然后再翻译回来,形成新样本。
比赛中,有选手使用EDA的方式进行数据增广,跟数据预处理一起,提高了0.2%左右的指标。【5】中提供了很多数据增广的方法,可用来快速生成大量训练数据。
外部数据
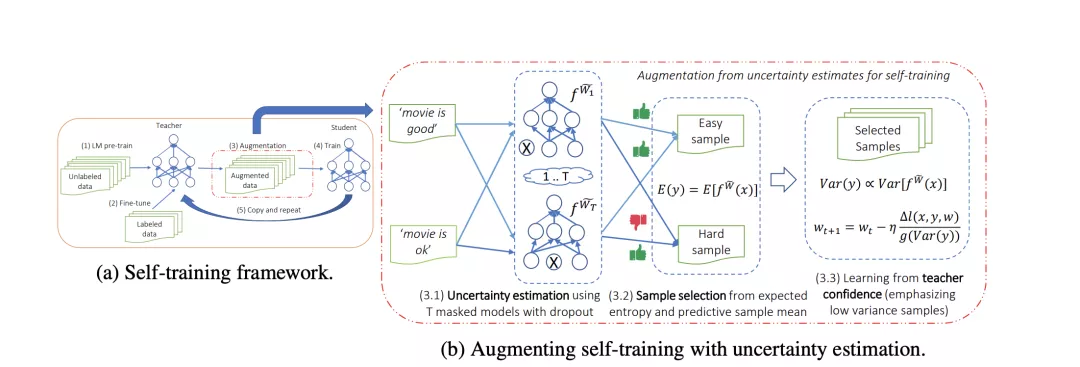
数据既然对模型的最终结果无比重要,那么就要通过各种方式来获取数据。最直接的,通过人工标注等方式获取更多的数据,但这种方法成本较高耗时也长,所以可以在网上寻找相似的公开带标签数据集,如果缺少此类数据,则可以获取相似的无标签数据,通过self-training的方式来训练模型;进一步如无标签数据也难以获得,则可以使用测试数据来做半监督学习。比赛中,选手通过大量相似的带标签数据以及大量无标签数据来做self-training【6】,整体提高1.5%左右的指标,也有选手使用测试数据做半监督学习,提高了0.8%左右。
模型
不同的任务,不同的数据,都可能需要不同的模型来处理。本次比赛是关于预训练的多任务学习(baseline模型结构可参考【7】),所以选择不同的预训练模型【8】,不同的多任务模型框架,改变细小的模型结构,都会对最终效果有影响。
大力出奇迹
本比赛中,对最终结果影响最大的,莫过于预训练模型的大小了,所谓大力出奇迹,越大的预训练模型,就包含了更多的信息,鲁棒性也更好。从各位选手的结果来看,bert-large同等规模(24层的bert类模型)的模型比bert-base(12层的bert类模型)平均高4.5%左右,而bert-xlarge【9】(36层的bert类模型)规模的模型比bert-large要高3%左右。
模型结构
本比赛是多任务学习,并且需要使用单个预训练模型,所以baseline大都是硬共享模式。三个任务中有两个是分类任务一个是匹配任务(也可以认为分类任务),基础的方法就是沿用最后一层cls或者pool层结果进行分类。针对这些具体任务,各个选手发挥主动能动性,使用了不同的网络结构来处理。
- 有选手使用bert最后4层的结果加上pooler层的结果来进行下游任务学习【10】,得到了1%左右的收益;
- 有选手则将多任务模型结构全部表示为共享形式,所有任务共享一种结构,只是对不同任务选择独立的query来获取当前任务的内容【11】;
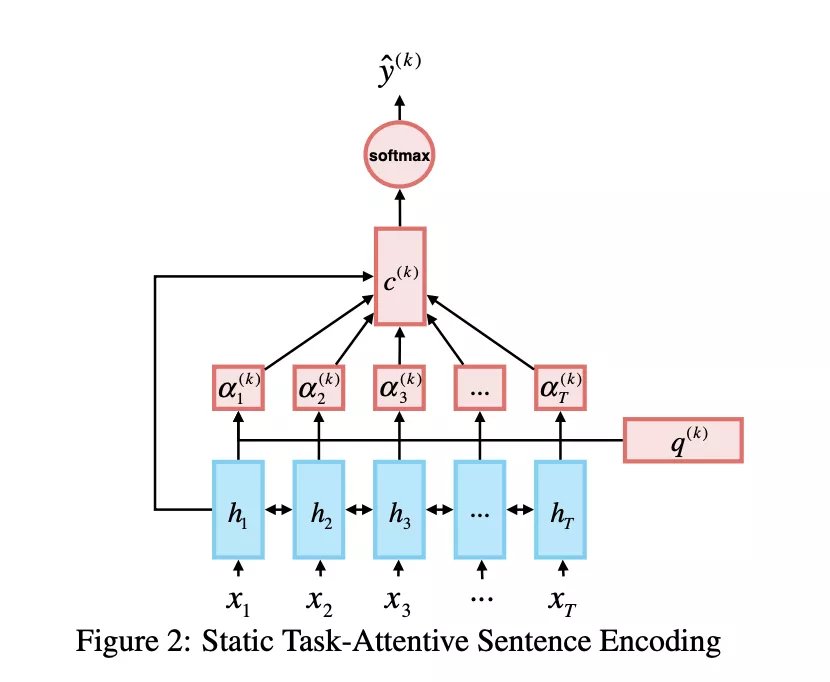 3. 有选手则根据不同的任务,选手lstm/transformer等结构来学习下游任务,提高了0.5%左右;
4. 有选手并不使用cls的向量来学习下游任务,而是用整个句子的平均池化结果来训练,这比cls的方法提高了0.5%左右;
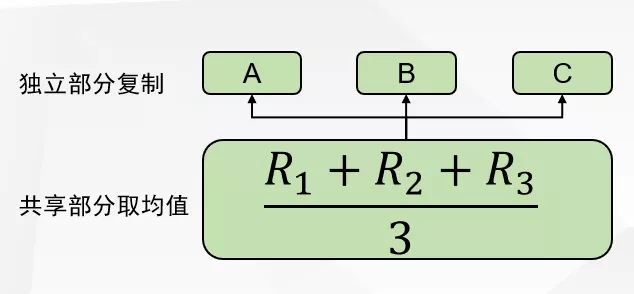
5. 有选手则是先对三个任务分别训练,然后将三个模型的参数进行融合,再一起训练,该方法带来了1%左右的提高;
3. 有选手则根据不同的任务,选手lstm/transformer等结构来学习下游任务,提高了0.5%左右;
4. 有选手并不使用cls的向量来学习下游任务,而是用整个句子的平均池化结果来训练,这比cls的方法提高了0.5%左右;
5. 有选手则是先对三个任务分别训练,然后将三个模型的参数进行融合,再一起训练,该方法带来了1%左右的提高;
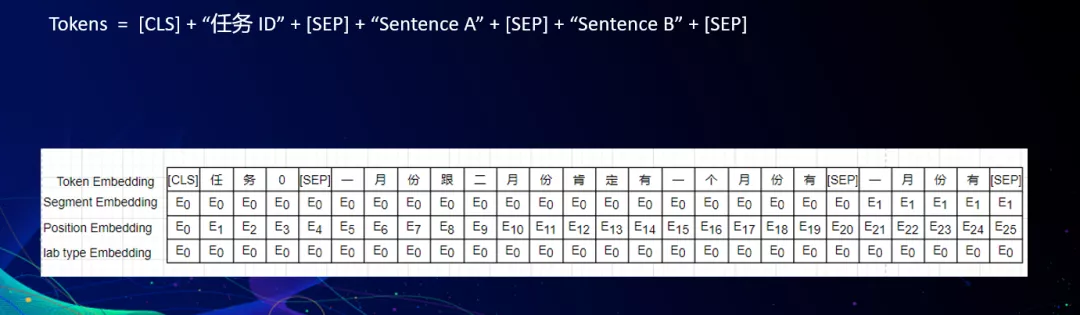
 6. 还有选手不把赛题看作是多任务学习问题,将各个任务混合在一起铺平,进行25分类训练,并在输入时新增了task type的embedding以区分任务。
6. 还有选手不把赛题看作是多任务学习问题,将各个任务混合在一起铺平,进行25分类训练,并在输入时新增了task type的embedding以区分任务。
LOSS
学习不同的任务,需要不同的loss,比如分类任务通常使用交叉熵,预测问题通常使用均方误差等等。loss函数,可以体现任务标签的分布情况,样本的比例,学到的信息大小与学习难度等等。所以一个更贴近数据情况的loss,能够让模型学习得更加鲁棒。在本次比赛中,选手也更具具体情况选择了不同的loss,但也并不是所有的策略都有效。比如像经典的focal loss【12】,或者根据F1指标修改的soft F1 loss【13】,或者是针对多任务学习的一些(动态)权重loss等等,在本次比赛中并没有起到明显效果。而有选手则使用了label smoothing【14】的方式对标签进行了平滑,提高了模型的鲁棒行,最终与emb mixup【21】(在后续正则化讲到)策略一起,将指标提高了0.5%左右。
优化方法
数据与模型都已经准备好,现在就需要学习模型,因为大部分神经网络学习都不能找到最优解,只能找到次优解。从应用的角度看,次优解已经可以使用,所以也没有必要追求最优解,但是通常情况下,次优解越接近最优解,应用效果就越好,所有实际过程中,研究人员也通过各种方式,试图获取一个更好的次优解。
学习率
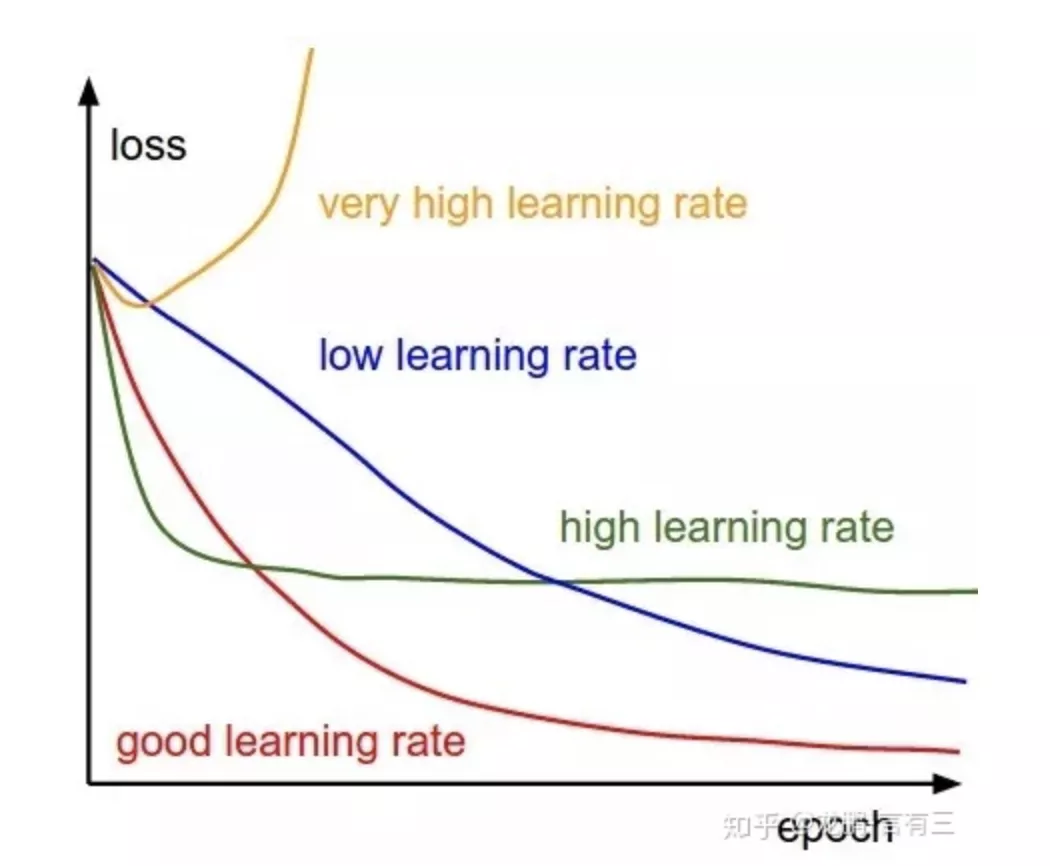
当前最主流的神经网络学习方法是基于梯度下降的算法,如sgd,adma等。梯度下降方法中,学习率是个比较重要的超参数【15】,其控制着每次更新参数变化量的大小,不同的模型结构,不同的训练阶段,甚至不同的参数层,都可以通过调整学习率来获得更好的表现。大的学习率能够让模型学得更快,在一定程度上能让参数跳过某些局部值,但也容易引起模型的不稳定,容易过拟合等等;小的学习率可以让模型学习得更稳定,学习到一个较好的可行解,但也容易陷入局部值而不能跳出,且训练相对较慢。本次比赛中,有选手对bert之后的几层选用不同的学习率【10】,但并没有带来明显收益;而在使用较复杂的下游任务网络模型的时候,通常的学习率并不能让模型学习到有效信息,而更小的学习率则让模型学到了有效信息。
对抗训练
对抗训练【16】是提高神经网络鲁棒性的利器,如下图所示,减少了随机干扰对模型结果的影响,其思想是,在训练过程中,通过对输入进行扰动,而使神经网络适应这种改变,从而提高对对抗样本的鲁棒性。本次比赛中,选手也尝试了不同的对抗训练方法,有选手通过FGM【17】对抗训练获得了0.5%左右的提高,更有选手通过PDG【18】对抗训练提高了1.8%左右的成绩。

训练手段
通常训练神经网络都是使用梯度下降之类的方法训练至收敛,不过因为一些随机因素(随机初始化、随机训练样本、不确定的学习率等等)甚至是梯度下降本身的因素,这样的模型参数经常会有较大的随机性,所以一些研究人员通过参数平滑的方式,来降低模型参数的随机性,以及提高模型的泛化能力。比赛中,有选手使用EMA【19】算法(滑动平均),降低了参数的随机性,从而提高了模型准确性;也有同学使用SWA【20】算法(随机权重衰减),类似与集成模型的思想,将多个模型参数合并一起,从而提高模型的泛化能力,比赛中该方法提高了1%左右的成绩。
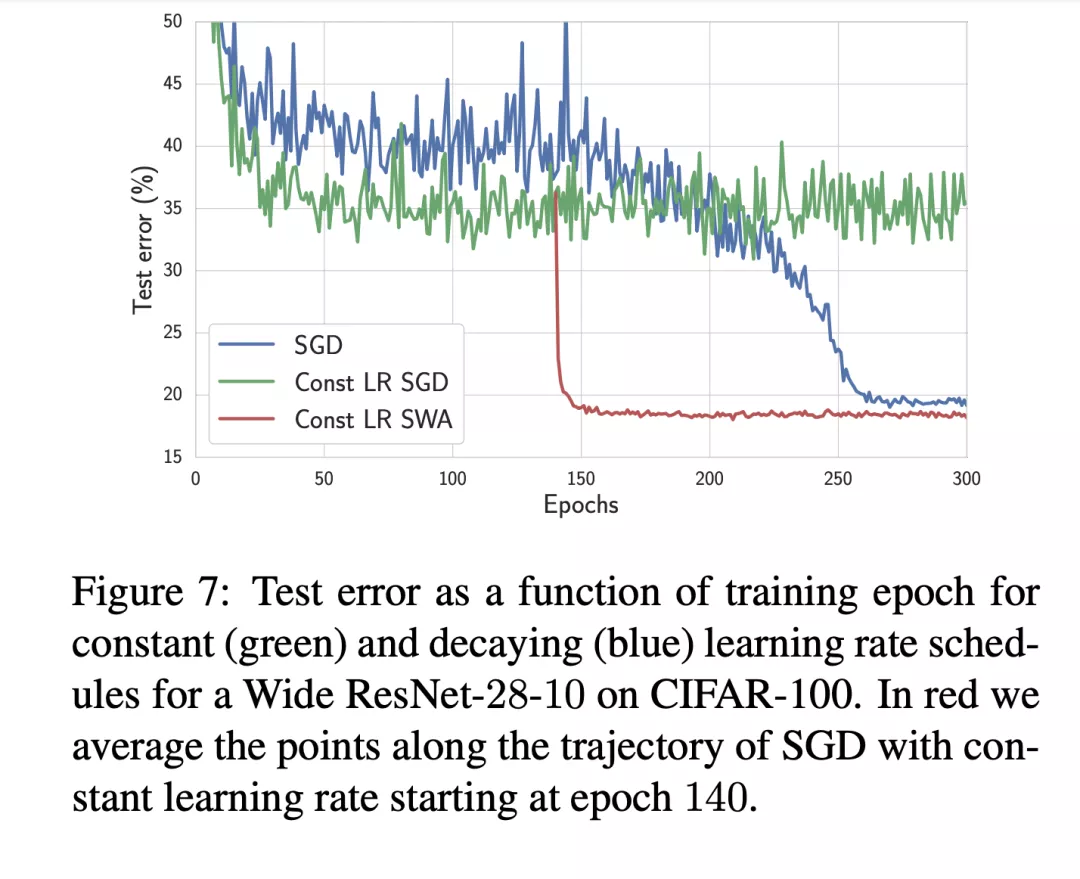
正则化
过拟合一直是模型训练中的一大难题,正则化就是针对处理过拟合的一些手段。狭义的正则化主要是对模型做约束,如L1/L2正则,dropout等等;广义的正则化则是一切能让模型降低测试误差的方法,如数据增广、调整loss、early_stop甚至是调整模型结构。从这个角度看,本文中的大部分内容,都可以认为是正则化手段。
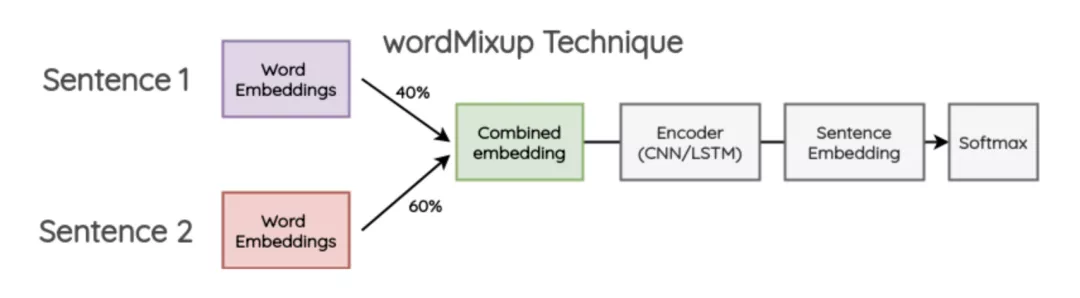
word mixup
word mixup【21】可以认为是一种数据增广的方式,这种方法可以大量构造虚拟样本,其思路是随机抽取两个样本,将两个样本的word embedding按比例混合作为新的样本,新样本的标签也是这两个样本的标签按比例的集合。比赛中,选手用该方法与label smoothing一起,将指标提高了0.5%左右。
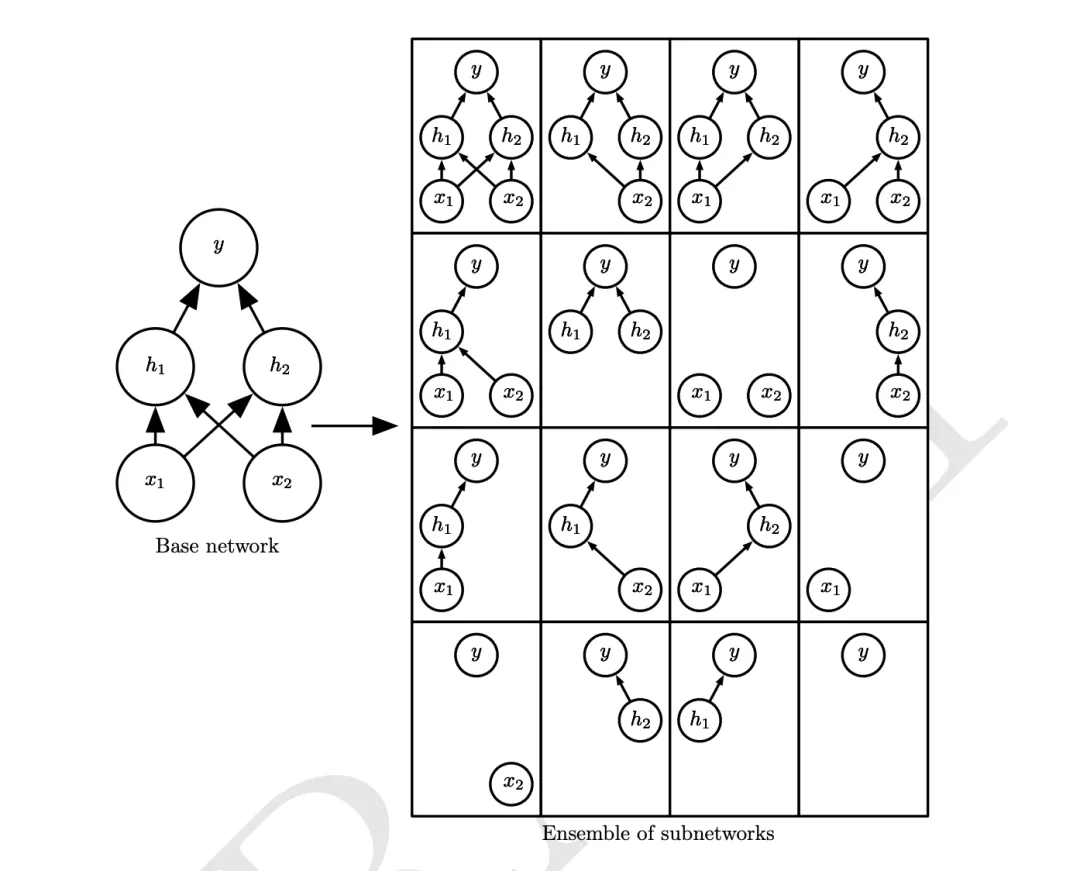
dropout
dropout【22】是常用的正则化手段之一,其主要思想是随机丢弃一些计算单元或通道,从而让各个计算单元或通道都能学到有效的信息,其思想也类似于bagging,减少了模型的方差。本次比赛中,选手使用dropout的方法,让指标提高了0.5%左右。
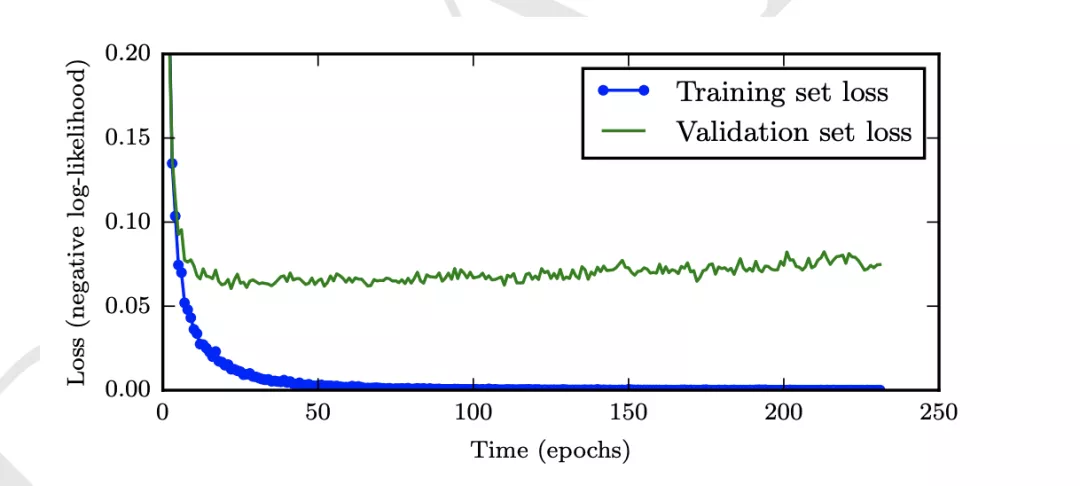
early stop
随着模型的不断训练,可能导致模型在训练数据集上过拟合,从而降低在测试集上的表现,如下图所示,随着训练次数的增加,测试误差先变小后变大。所以一个有效的early stop策略【23】,可以提高模型的泛化能力。本次比赛中,有效地利用early stop策略,可以提高1.8%左右的指标。
后处理
阈值优化
数据准备好了,模型也训练完成,模型的输出结果到最终的结果还要一个转换。对于通常的分类任务,可能直接使用0.5作为阈值分类就好,但对于具体任务而言,不同的阈值可能对最终结果有不少的影响。本次比赛中,也有选手对最终模型的阈值做了优化调整,且让最终指标提高了0.4%左右。
其他
未起效方法
比赛中,选手们也尝试过其他很多方法,其中有不少也并没有起到明显作用,比如利用训练数据与预训练模型再做预训练,以及一些对loss的调整,比如focal loss、soft f1 loss、动态loss调整等等。
训练技巧
比赛中,大部分选手使用使用的大模型,36层的bert模型在显存占用与训练速度上都堪忧。显存的角度,模型太大,就导致batch size比较小,为此有选手使用了累计多步更新一次参数的方法;速度的角度,模型本身训练已经比较慢,有很多tirck非常耗时,所以有选手就在训练初期使用原始模型训练,在一定轮次后,再加入trick继续训练,从而提高了训练效率。
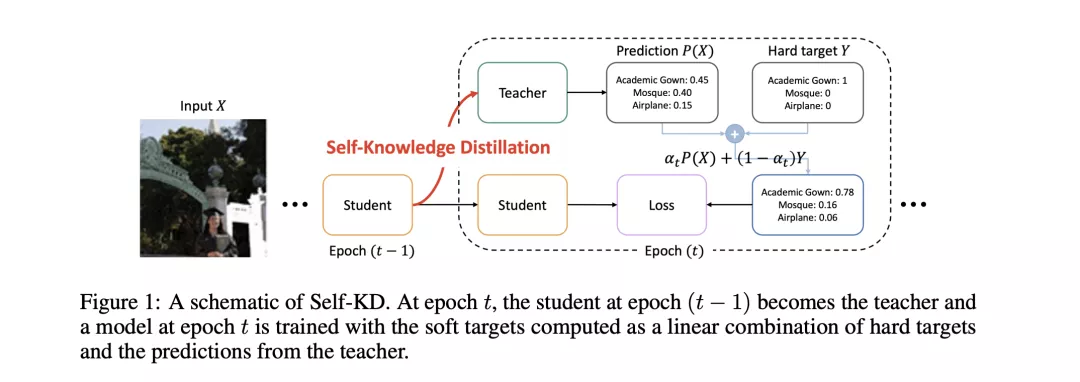
自知识蒸馏
自知识蒸馏【24】在很多任务上也能提高模型的的效果(本次比赛中,并没有选手使用),因为其相对于原始的硬标签提供的信息,可以额外提供各个类别之间关系的信息。比如分类任务中,原始标签只会对某个样本标记为第一类/第二类,但自知识蒸馏可以把某个样本标记为80%的第一类20%的第二类,这样就提供了更多的标签之间的信息。
参考
【1】如何对文本数据进行预处理?: https://blog.csdn.net/weixin_36711901/article/details/79523698
【2】自然语言处理之数据预处理: https://bainingchao.github.io/2019/02/13/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E4%B9%8B%E6%95%B0%E6%8D%AE%E9%A2%84%E5%A4%84%E7%90%86/
【3】EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks: https://arxiv.org/pdf/1901.11196.pdf
【4】Unsupervised Data Augmentation for Consistency Training: https://arxiv.org/pdf/1904.12848.pdf
【5】A Visual Survey of Data Augmentation in NLP: https://amitness.com/2020/05/data-augmentation-for-nlp/
【6】Uncertainty-aware Self-training for Text Classification with Few Labels: https://arxiv.org/pdf/2006.15315.pdf
【7】Multi-Task Deep Neural Networks for Natural Language Understanding: https://arxiv.org/pdf/1901.11504.pdf
【8】 NLP集大成之预训练模型综述
【9】 https://github.com/dbiir/UER-py
【10】 NLP重铸篇之BERT如何微调文本分类
【11】Same Representation, Different Attentions: Shareable Sentence Representation Learning from Multiple Tasks: https://arxiv.org/pdf/1804.08139v1.pdf
【12】Focal Loss for Dense Object Detection: https://arxiv.org/pdf/1708.02002.pdf
【13】The Unknown Benefits of using a Soft-F1 Loss in Classification Systems: [https://towardsdatascience.com/the-unknown-benefits-of-using-a-soft-f1-loss-in-classification-systems-753902c0105d](https://www.6
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E5%A6%82%E4%BD%95%E4%BC%98%E5%8C%96%E5%B9%B2%E8%B4%A7%E6%80%BB%E7%BB%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


