来也自监督学习在计算机视觉中的应用

文章作者:摄影师王同学
编辑整理:刘桐烔
导读: 在机器学习中,我们最常遇到的一个难题就是:缺少优质的标注数据。自监督学习让我们能够没有大规模标注数据也能获得优质的表征,它利用数据自身的关系来做为标注样本进行训练并且优化预定义的 pretext 任务。来也科技作为一家优秀的 RPA + AI 企业,对各种机器学习方式都进行了探索及实践。本文选自公司内部的 CV 分享。
01 什么是自监督学习
目前的机器学习算法可以基本分为以下几大类:
- 监督学习。 训练数据有标注(人工标注出准确的标签),比如典型的图像分类,给一张图片打上标签(类别),算法来通过学习来预测类别从而得到预测规则(模型参数)。目前机器学习取得较大突破的基本都是这类,而且取的进展比较大领域一般都是可以低成本的获取标注数据(比如推荐系统等)。
- 无监督学习。 没有明确目标下发现数据的规律,比如最常见的聚类、降维等。
- 自监督学习。 利用数据自身的关系来做为标注样本进行训练,大多数场景下自然存在的数据已有这样的自身关系, 比如我们熟悉的Bert等自然语言的模型,利用预测mask字(词)、预测上下文关系做为标注信息训练。
- 强化学习。 智能体通过观察和接受环境的信息,寻求并学习找到奖励最大化的行动,整个反馈在整个运行过程中收集,比如在围棋上成名的AlphaGo。
由于监督学习需要及其庞大的标注数据,但是获取大量高质的标注数据由于成本问题不太现实、目前缺少数据这个问题会严重制约着模型性能,而无监督学习和强化学习目前解决的场景问题有限,所以这几年越来越多的目光投入的自监督学习。
在2020ICLR大会上,Yann LeCun 和 Yoshua Bengio 甚至认为“自监督学习是AI的未来”
由于自监督学习在训练过程没有最终业务场景的任务,所以核心解决的问题是训练一个编码模型,这个编码模型对数据进行一个良好的特征表征,该特征未来可以直接用在更下游的任务,可以用下图来描述自监督学习的使用模式:
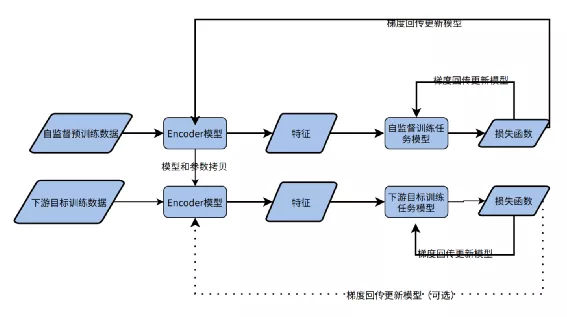
首先在无标签的预训练数据上进行自监督任务的训练,这一步核心要得到Encoder模型,这个Encoder模型要对数据产生一个良好的特征表征。
在预训练任务完成后,利用少量带有标签的下游任务数据来训练下游模型,这个时候编码器模型直接采用自监督训练的Encoder模型,将Encoder模型的输出特征直接输入到目标任务模型,可以只对下游目标任务模型进行学习,也可以同时对Encoder网络的参数进行finetune。
例如在0~9手写数字分类中,可以先在无标签数据上预训练Encoder网络,在Encoder训练完成后,后边接入10分类的全连接层,再在少量的标签数据上进行学习,即可得到一个完整的分类模型。
02 计算机视觉中的常用自监督任务
在机器学习中基本要遵循以下原理图:
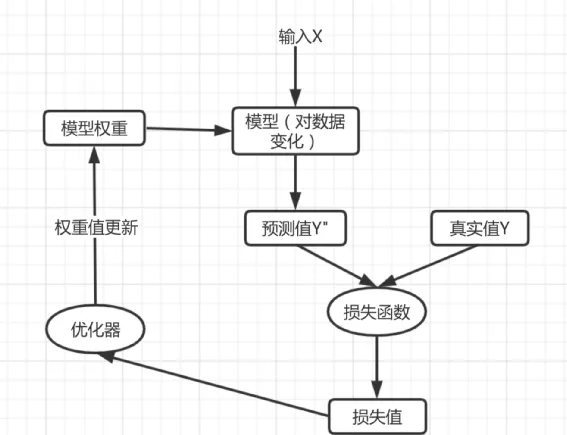
里边核心一点就是设计损失函数,通过损失函数对模型参数进行梯度求导,利用求导结果来更新模型参数,而损失函数又需要标签值(label),所以在设计自监督任务中非常关键的地方是:通过数据自身的关系来构建输入以及需要预测的标签值。在构造的的输入和标签数据上进行监督训练在自监督学习中称为“pretext tasks",在计算机视觉中常用 pretext tasks 有以下方式:
1. 预测图像旋转方向
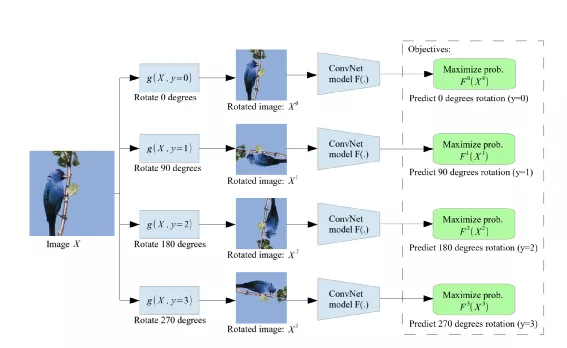
图片来源: https://arxiv.org/abs/1803.07728
过程如下:
- 原始图像会经过 0、90、180、270 四个角度方向旋转
- 然后Encoder输出的特征用来进行4分类判别
2. 预测图片补丁位置相对关系
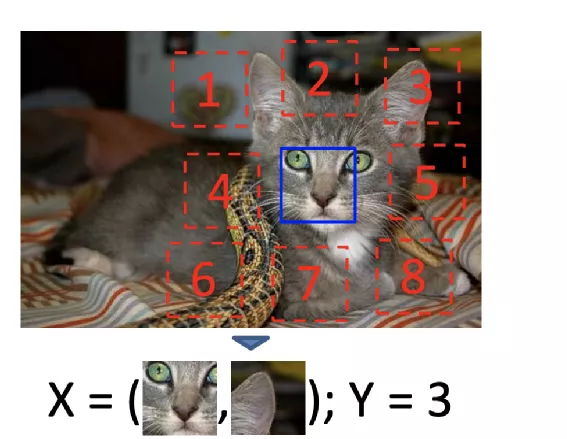
图片来源: https://arxiv.org/abs/1505.05192
过程如下:
- 在图像上随机裁剪得到正方形图像;
- 对正方形图像裁剪成9个大小小相等正方形区域(注:裁剪过程有一些增强技巧如小图片增加缝隙、抖动增强详见附录论文2);
- 选取9个小图的中心小图和除外一个随机小图,这两个图片经过Encoder后特征拼接进入全连接分类图,分类类别为8。
3. 补丁拼图
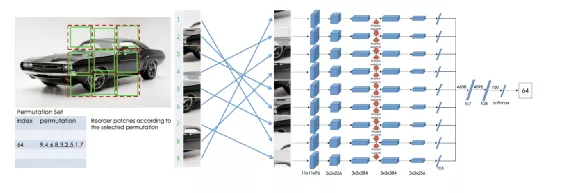
图片来源: https://arxiv.org/abs/1603.09246
过程如下:
- 在图像上随机裁剪得到正方形图像;
- 并对正方形图像裁剪成9个大小小相等正方形区域,同预测补丁相对位置关系,裁剪图片也有一些技巧,见论文3;
- 将9个小图随机打散顺序得到一种基于原图顺序排列组合,然后每个小图进入Encoder得到特征输出,特征进入各自的全连接网络(不共享)后输出变换特征
- 变换特征拼接后进入MLP得到分类类别,理论上一种排列组合可以认为是一种类别,所有类别总数为:9!=362880。作者认为这么多类别中有很多很相似没法训练模型提取有效的特征,所以通过序列字符串汉明距离来选择差异很大的序列作为类别。
4. 图片上色

图片来源: https://arxiv.org/abs/1603.08511
过程如下:
- 灰度图经过Encoder得到 特征;
- 特征经过Decoder重建得到上色图片;
- 上色图片和原图计算Loss,常见的上色任务是计算上色后图片与原图的L1或者L2 Loss,在附图论文中Loss做了一些特殊处理:颜色模式不是RGB而是LAB(参考4),此外将AB 颜色通道量化为313个区间,最终目标是求每个像素点在313区间的分类概率,根据将分类概率Top N 平滑后选择上色。
5. 自编码器系列
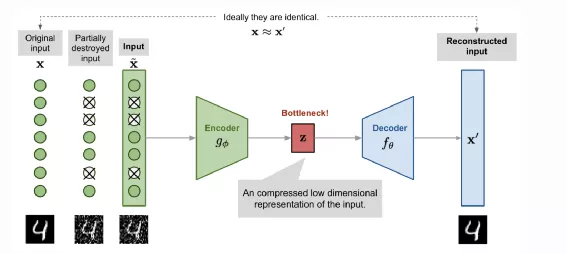
如图是一个去噪的自动编码机,过程如下:
- 原始图像经过扰动加入噪点
- 噪点图像经过Encoder编码后得到特征Z
- 特征Z经过Decoder得到重建图片,要求重建图像和原始图像尽可能一致
6. 对抗神经网络
对抗神经网络中图像修复,超分重建,Pix2Pix ,CycleGAN,其中这些模型中对应的特征提取网络Encoder都可以作为下游任务的网络。关于GAN的更多内容请看《 GAN详解和来也利用GAN在手写生成的探索》
7. 对比学习
基于正负Pair对比学习简单思路可以用下图理解:
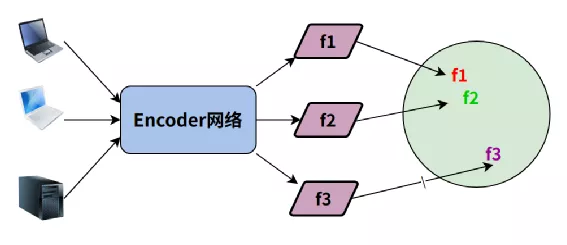
原始图像根据图像内容分为正正、正负样本对(Pair),所有图像经过相同Encoder得到编码特征,希望是这些特征投影到同一度量单位空间,正正样本Pair的投影距离近,正负样本投影距离远。
由于对比学习效果好,pretext task容易设计,这几年成为自监督最重要的研究方向之一,本文就核心面向对比自监督学习。
03 对比学习核心问题
从上面第7节可以看出一个优秀的对比学习系统如果要学习到非常好的特征表征,核心需要解决以下2个问题:
① 样本Pair对如何构造
这里边核心的问题是构造困难样本对,比如两个样本视觉差异很大但是特征相似,这两个样本属于正(Positive)样本对;以及两个样本视觉差异很小但是属于负样本(Negtive)样本对,比如如图像分类中有些"狗“和”猫“品种人眼看很像,但是希望学到的“特征”不相似。在自监督场景由于图像没有标签,Pair对构造方式会采用图像增强的方式,简单来说在图像集合中拿出一张图片P1,对这个图片进行增强得到P2,再从图像集合中随机抽取另外一张图片P3。这样P1和P2为正样本、P1和P3 为负样本对。
一般来说图像中常用的增强方式有如下,可以根据未来下游业务场景选择:
- 随机裁剪
- 随机噪音
- 高斯模糊
- 抖动
- 颜色通道转化
- 灰度化
- 对比度调节
- 亮度调节
② Loss 如何设计
在对比学习中,不好的Loss设计会出现”模型崩塌“的现象,即Encoder学习到特征投影到度量空间分布不均匀且过于集中,这个时候学习到Encoder无法用于下游任务。所以在对比度量学习中一个重要的严重方向是度量Loss设计,常用的Loss一般有以下:
① Contrast Loss
公式如下:
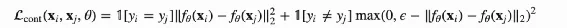
ϵ是超参数,希望的是负样本对之间L2的距离应该大于它。当正样本对的学习的特征一致(L2距离等于0)、负样本对之间特征L2 大于ϵ时,Loss为0,只要最小化Loss既可。
② Triplet Loss
Triplet Loss是深度度量学习中比较常用的Loss,效果一般优化Contrast Loss,公式如下:
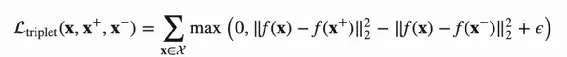
ϵ是超参数,Triplet Loss 以f(x)作为”锚点“。希望最小化正样本对距离同时最大化负样本对之间的距离,且负样本对距离相比正样本对的距离要超过ϵ,原理如下图:
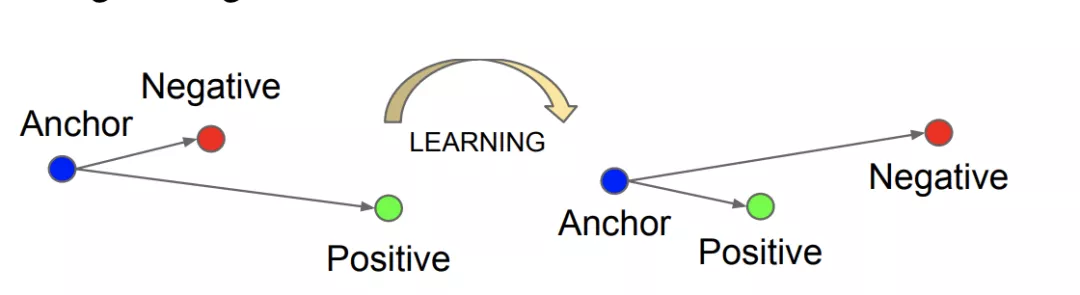
图片来源: https://arxiv.org/abs/1503.03832
③ N-Pair Loss
在Contrast Loss和Triplet Loss 中只考虑一个负样本,目前基本观点就是正负样本对比学习、负样本越多效果越好,所以N-Pair Loss 考虑了多个负样本对,公式如下:
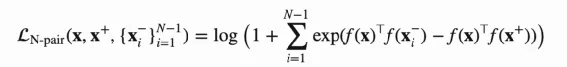
采样N+1个训练样本,包含1个锚点x,1个正样本,N-1个负样本。
④ InfoNCE Loss
InfoNCE Loss 思想取决于NCE,NCE希望是通过概率预估,利用逻辑回归可以区分数据中的正样本和噪音数据,而InfoNCE Loss来自CPC(Contrastive Predictive Coding)预估,可以是过分类交叉熵来区分正样本和噪音数据,公式如下:
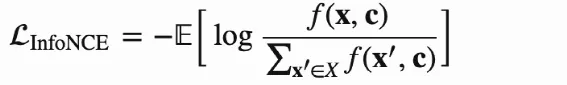
其中
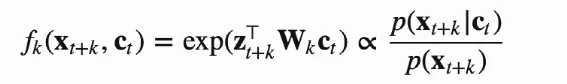
简单理解就是认为随机抽取的N个样本中1个正样本的概率分布符合p(x+t|ct),N-1个负样本的概率分布符合p(x+t),希望的是正样本出现概率越高越好,也就是x+t和ct的相似度越高越好。
公式推导较为复杂,结论就是x+t和ct 的互信息的上界取决于InfoNCE loss的下界,可以细看参考资料5。
在实际使用中Zt+k 可以是锚点样本Encoder输出特征的变换,WkCt是可以看做另外一个样本的Encoder的输出特征的变换。
04 典型的图像自监督对比学习方式
1. 正负Pair自监督对比学习
这类自监督学习核心思路就是一批N图像中,图像P经过增强得到P+,这批图像中随机抽取非P的1~x张作为负样本,通过Encoder和投影函数得到特征f,f+,f-,将f输入度量loss来优化模型。比较常用的模型有以下几种:
① SimCLR
SimCLR 原理如下图:
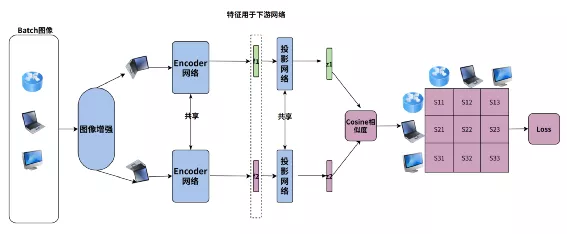
对Batch的每一张图片随机增强得到两张图片,两个图片经过共享的Encoder得到特征f1和f2(f1和f2 可硬用在下游的任务),f1和f2再经过投影网络变化得到Z1和Z2,Z1和Z2 计算得到余弦相似度Score,假设图片编号为1,Score为S11,除了每个图像本身增强的Pair计算Score,Batch内其他图片也会相互计算Score,对于N的Batch图片,得到NXN的Score矩阵,我们希望的是Score的对角线元素 Sij(i=j)取值最大,利用InfoNCE 作为loss。
② MOCO系列
前边提到正负样本Pari对比学习,一个影响最终效果的重要因素就是负样本Pair的数量,而在SimCLR 的负样本Pair是来自一个Batch,受限于训练显存,负样本数量有限。为了提高负样本的数量,何凯明提出了MOCO的自监督对比学习,MOCO V2原理如下图:
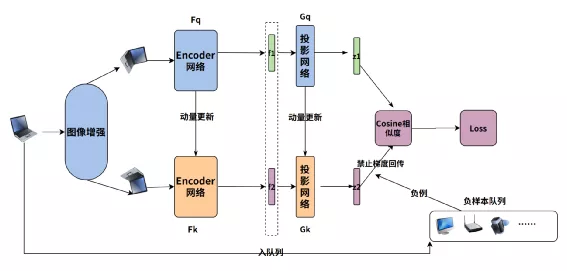
核心是以下两点:
- 负样本通过定长队列维护保存,每个Batch淘汰老数据,加入新数据
- 正例网络(Fq,Gq)用标准的梯度下降优化,负例网络(Fk,Gk)采用正例的模型参数的动量更新,即:Fk <- Fk*m+(1-m) Fq,Gk <- Gk m+(1-m)*Gq,代码如下:
@torch.no_grad()
def _momentum_update_key_encoder(self):
"""
Momentum update of the key encoder
"""
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
2. 聚类自监督对比学习
前边提的几种对比学习都需要成对计算所有样本的相似性,且模型最终的效果和负样本对数量有密切关系,基于这些限制,不直接利用图片表征来进行对比,而是将图片表征feature进行聚类,希望相同图片的聚类结果一致来进行自监督,比如DeepCluster,SmAv等模型,下边简单描述SmAv。
2020年《Swapping Assignments between multiple Views of the same images》被提出,利用聚类来进行样本区分,目前在一些公开数据集合上效果逼近监督学习,SmAV原理图如下x`:
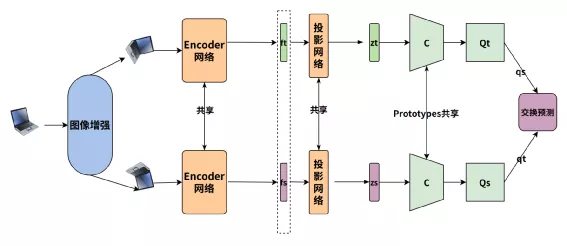
模型的前半部分和上边的对比学习一致,图片增强后编码特征再经过非线性投影变换的向量Zt和Zs,不一样地方在后半部分,核心可以用以下几点来描述:
- 两个投影向量分别会和一个KxD 的向量(图中的C,论文作者称之Prototypes)相乘得到变换后的向量,这个K可以假设就是K个类,每一行向量可以代表这个类表示(聚类中心),可以认为相乘后的结果就是图片表征向量和K类的相似度,记作为ZtC,ZsC,其中C是参与学习。
- 引入了 Q=[q1,…,qB]∈ℝK×B,可以认为Q就是这B个(Batch Size)图片对应的最理想的聚类中心,论文作者尝试Q分别为离散值和连续值的效果,目前连续值的效果更好。
- 希望ZC和Q 相似度尽可能高,论文作者采用最优传输的理念也就是将一个分布传输到另一个分布的代价做大,来优化C,论文采用的是Sinkhorn 进行最优传输解,见附录17
- ZtC,ZsC分别经过Qt和Qs变化后的得到qs和qt,qs和qt可以认为就是聚类结果的label
- 然后采用交换预测的方法,也就是t的聚类结果去预测s,同样s也去预测t,loss采用交叉熵,如下:

3. 非对称结构的自监督学习
前边提到模型大家可以认为两份增强图片进行处理流程都是一样的,且Loss设计理念是要增大正正Pair表征的相似度,同时减少正负Pair的相似度,这种模型的效果一般和负样本的难易程度以及参与损失的负样本的数量密切相关,基于这些缺点,只需要正样本自监督学习模型被提出,典型的有BYOL和SimSiam,本文就简单的描述下SimSiam 模型。
SimSiam 整体结构非常简单,无负样本,原理图如下:
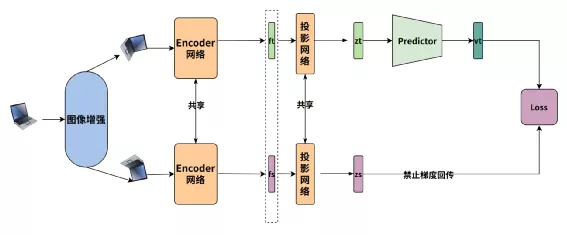
流程如下:
- 一张图像经过两次不同增强后,再经过Encoder编码的图像特征经过投影变化后得到特征Zt,Zs
- 对于Zt,Zs 再分别一个Predictor网络(MLP)变化得到Vt和Vs(为了避免流程图引起歧义只画了Vt)
- 通过交换预测来计算Loss,也就是希望Zt和Vs 相似,Zs 和 Vt相似
在SimSiam中有非常重要的三点:
- 一路的特征Z需要经过Predictor变化,若没有Predictor变化得到V,直接计算两个Z的loss,模型会崩塌

- Predictor 的MLP的隐层输出需要进行Batchnorm(但输出层不能加),否则模型性能退化严重

- 计算Loss时对于Z要禁止梯度回传,否则模型会崩塌,也就是Loss的计算伪代码如下:
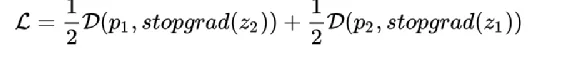
4. 对比学习模型总结
目前对比学习的模型效果在一些公开分类数据集合上的效果:
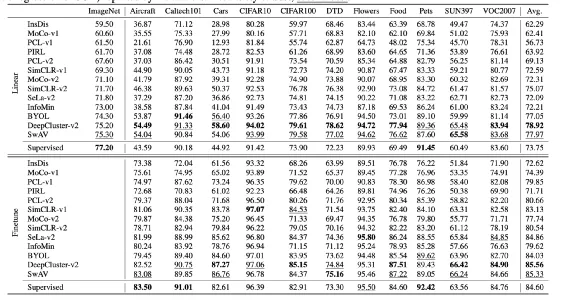
利用ResNet50 作为backbone 在ImageNet 网络上做自监督学习,图的上半部分是冻结ResNet50 ,只训练最后的分类网络得到的结果;下半部分是微调整个ResNet50和分类网络得到结果,能看到在ImageNet利用自监督做预训练训练,在目标数据集合上微调,相比直接在这个数据集合上监督训练,能在大多数数据集合上都有相当的提升。
05 自监督学习在Laiye OCR上的尝试
来也的核心产品战略方式是RPA+AI,而AI中最重要的能力之一就是OCR,目前来也自研的通用文本识别在40个多个复杂文档场景上,总体字符准确率超过95%,已经超过国内绝大多数头部的OCR公司。
随着图像领域的自监督的成熟,我们希望在OCR也尝试自监督学习落地的可能性,我们先在一个细分的领域,验证码识别验证落地的可能性。
在RPA操作各种权限保护的系统时,需要进行授权登录,而大多数授权的登录系统都有图形验证码来防止机器人抓包登录,而且不同网站的验证码形状各异,如下图:



为此我们基于深度学习研发图形验证码识别来辅助RPA进行无人工干预登录系统,在20+的测试集合识别准确率接近90%,若重试一次可以达到99%。验证码识别的模型架构如下图:
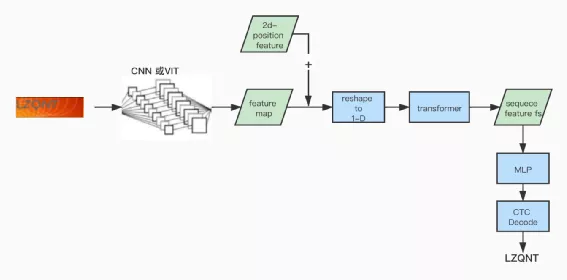
我们希望的是通过自监督学习能得到transformer之后的序列特征表征fs,在利用少量真实标签数据训练MLP和微调MLP之前的所有网络,最终通过少量的标注就能得到一个效果不错的模型。
在用自监督做这个任务之前需要解决两个问题:
① 因为文字识别不同图像分类,文字识别一张图像里边有多个文字目标,而原始图像识别只有一个目标,如果参考图像分类用fs作为对比特征,很容易出现表征特征混乱,比如两个正样本的特征相似,不能代表每个字符对应的特征相似。
解决这个问题我们参考CVPR 2021 以色列和Amazon的一篇最新论文(附录19)《 Sequence-to-Sequence Contrastive Learning for Text Recognition 》,在这篇论文提出了 “Frame” 这个概念,因为在文本识别解码前的特征为1-D序列,这个1-D特征最终被解码成文字,也就是说1-D序列上有多个序列会对应最终的文字,这个被称之为"Frame" ,论文中提出好几种 “Frame” 实现方式如图,P可以认为就是前边提到Fs:
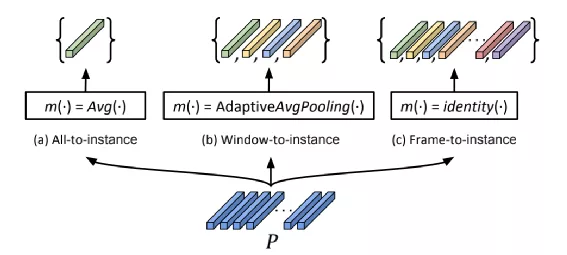
图片来源: https://arxiv.org/pdf/2012.10873.pdf
经过思考我们选择AvgPooling这种方式,PoolSize=5,代码如下:
'''
将原始的序列特征 shape 为 B x SeqLen x FeatureDim 的输入特征
转成 shape为 B*ceil(SeqLen/5) x FeatureDim 的输出特征
相当增加Batch Size, 去自监督对比维度为FeatureDim 的特征
'''
def feature_flat(self, feature):
dim = tf.shape(feature)[2]
feature = tf.keras.layers.AvgPool1D(pool_size=5, padding="same")(feature)
feature = tf.reshape(feature, [-1, dim])
return feature
② 增强方式的选择,因为人类阅读文本和做图像识别差异,在增强方式不能和原始的图像识别一样,比如左右镜像翻转,文本区域裁剪明显会带来噪音图片,这个自监督任务上,我们选用的增强方式有:
- 随机噪点
- 高斯模糊
- 抖动
- 颜色通道转化
- 灰度化
- 对比度调节
- 亮度调节
- 随机等比缩放图片
其中对抖动,随机噪点,高斯模糊调大出现比例
解决这两个问题,我们分别尝试了SimSiam和SimCLR这两种自监督方式
1. SimSiam实现
#预测模型
self.predictor_model = tf.keras.Sequential([
tf.keras.layers.Dense(
self.LATENT_DIM,
use_bias=False,
kernel_regularizer=tf.keras.regularizers.l2(0.001),
),
tf.keras.layers.LeakyReLU(alpha=0.18),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(self.PROJECT_DIM),
]
)
# 投影模型
self.projector_model = tf.keras.Sequential([
tf.keras.layers.Dense(
self.PROJECT_DIM,
use_bias=False,
kernel_regularizer=tf.keras.regularizers.l2(0.001),
),
# 模型崩溃,加入batchnorm
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(alpha=0.18),
tf.keras.layers.Dense(self.PROJECT_DIM),
tf.keras.layers.BatchNormalization(),
]
)
#simsiam 的前向传播
def forward_sim_siam(self, inputs, training, compute_err, valid):
parallel = 1
if self.multi_gpu:
parallel = self.strategy.num_replicas_in_sync
img = inputs["image"]
img1, img2 = self.get_aug_img(img, training)
_, _, feature1 = self.model(img1, training=training)
_, _, feature2 = self.model(img2, training=training)
z1, z2 = self.projector_model(feature1), self.projector_model(feature2)
p1, p2 = self.predictor_model(z1), self.predictor_model(z2)
p1, z1, p2, z2 = list(map(self.feature_flat, [p1, z1, p2, z2]))
loss = self.loss_simsiam(p1, z2) / 2 + self.loss_simsiam(p2, z1) / 2
result = {"total_loss": loss}
return {k: v / parallel for k, v in result.items()}
#simsiam 的loss计算
def loss_simsiam(self, p, z):
'''
对z要停止梯度回传
'''
z = tf.stop_gradient(z)
p = tf.math.l2_normalize(p, axis=1)
z = tf.math.l2_normalize(z, axis=1)
'''
希望的是p和z相似度尽可能大
'''
return -tf.reduce_mean(tf.reduce_sum((p * z), axis=1))
2. SimCLR 实现
# clr 投影模型
self.predictor_model_clr = tf.keras.Sequential([
tf.keras.layers.Dense(
self.PROJECT_DIM,
use_bias=False,
),
tf.keras.layers.LeakyReLU(alpha=0.18),
tf.keras.layers.Dense(self.PROJECT_DIM),
]
)
def forward_simclr(self, inputs, training, compute_err, valid):
parallel = 1
if self.multi_gpu:
parallel = self.strategy.num_replicas_in_sync
img1, img2 = self.get_aug_img(inputs["image"], training)
_, _, feature1 = self.model(img1, training=training)
_, _, feature2 = self.model(img2, training=training)
z1, z2 = self.predictor_model_clr(feature1), self.predictor_model_clr(feature2)
'''
将sequence feature 转为 frame的feature
'''
z1, z2 = self.feature_flat(z1), self.feature_flat(z2)
loss = self.info_nce_loss(z1, z2)
result = {"total_loss": loss}
return {k: v / parallel for k, v in result.items()}
def info_nce_loss(self, projections_1, projections_2):
projections_1 = tf.math.l2_normalize(projections_1, axis=1)
projections_2 = tf.math.l2_normalize(projections_2, axis=1)
similarities = (
tf.matmul(projections_1, projections_2, transpose_b=True) / 0.1
)
batch_size = tf.shape(projections_1)[0]
contrastive_labels = tf.range(batch_size)
'''
希望正样本的图片特征相似度足够大,负样本对相似度足够小,采用交叉熵的方式
正样本的label=1,负样本=0
'''
loss_1_2 = tf.keras.losses.sparse_categorical_crossentropy(
contrastive_labels, similarities, from_logits=True
)
loss_2_1 = tf.keras.losses.sparse_categorical_crossentropy(
contrastive_labels, tf.transpose(similarities), from_logits=True
)
'''
交叉预测
'''
loss = (loss_1_2 + loss_2_1) / 2
return tf.reduce_mean(loss)
3. 实现细节
我们一共使用86万张各种版式验证码图片数据,文字数目4~6位,其中用80万张作为自监督训练数据,剩下的4万张作为带标签的模型训练,最后2万张用来测试。
① 自监督+finetune训练过程
- 首先SimCLR和SimSiam 采用 SGD+0.8 momentum 优化器 ,lr=3e-4,batch size=96 在80万数据上训练10个epoch
- 接在用ADW优化器,lr=3e-4 ,batch size=8 在4万张标签数据上训练识别模型中MLP(两层全连接网络) 10个epoch
- 最后采用 ADW优化器,lr=3e-5 ,batch size=8 在4万张标签数据上微调识别整个网络 40个epoch
② 监督训练过程
- 直接用ADW 优化器,lr=3e-4 ,batch size=8 在4万张标签数据训练整个识别网络50个epoch
③ 结果评测
我们利用编辑距离准确率来衡量模型的识别效果,假设真实字符串值为label,预测值predict,那么准确率公式如下:
准确率 = 1- 编辑距离(label,predict)/字符串数目(label)
最终对比结果如下:
监督训练SimSiam+fintuneSimCLR+finetune准确率0.90810.95410.957
可以看到通过自监督预训练+少量的标签数据finetune,最终的指标有5%的提升。
06 参考资料
- https://zh.m.wikipedia.org/wiki/CIELAB%E8%89%B2%E5%BD%A9%E7%A9%BA%E9%97%B4
- https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html#denoising-autoencoder
- https://github.com/facebookresearch/moco
- https://arxiv.org/pdf/2006.09882.pdf
- https://blog.csdn.net/Utterly_Bonkers/article/details/90746259
- https://wandb.ai/authors/swav-tf/reports/Unsupervised-Visual-Representation-Learning-with-SwAV--VmlldzoyMjg3Mzg
- https://www.jiqizhixin.com/articles/19031102
- https://zhuanlan.zhihu.com/p/308159909
- https://arxiv.org/abs/2012.10873
- 《黄铁军对话Lecun》 https://posts.careerengine.us/p/612b3d8cd8be0f2392f48da9
- 《深度度量学习中的损失函数》 https://zhuanlan.zhihu.com/p/82199561
- 《从NCE到InfoNCE》 [https://zhuanlan.zhihu.com/p/334772391](https://zshipu.com/t?url=https%3A%2F%2Fzhu
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9D%A5%E4%B9%9F%E8%87%AA%E7%9B%91%E7%9D%A3%E5%AD%A6%E4%B9%A0%E5%9C%A8%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


