梳理常见的机器学习面试题你知道几个
添加微信: julyedukefu14,回复【7】领取最新升级版【名企Al面试100题】
26、说说常见的损失函数?
对于给定的输入X,由f(X)给出相应的输出Y,这个输出的预测值f(X)与真实值Y可能一致也可能不一致(要知道,有时损失或误差是不可避免的),用一个损失函数来度量预测错误的程度。损失函数记为L(Y, f(X)),用来估量你模型的预测值f(x)与真实值Y的不一致程度。
27、为什么xgboost要用泰勒展开,优势在哪里?
xgboost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了xgboost的适用性, 使得它按需选取损失函数, 可以用于分类, 也可以用于回归。
28、协方差和相关性有什么区别?
相关性是协方差的标准化格式。协方差本身很难做比较。例如:如果我们计算工资($)和年龄(岁)的协方差,因为这两个变量有不同的度量,所以我们会得到不能做比较的不同的协方差。
29、xgboost如何寻找最优特征?是有放回还是无放回的呢?
xgboost在训练的过程中给出各个特征的增益评分,最大增益的特征会被选出来作为分裂依据, 从而记忆了每个特征对在模型训练时的重要性 – 从根到叶子中间节点涉及某特征的次数作为该特征重要性排序.
30、谈谈判别式模型和生成式模型?
判别方法:由数据直接学习决策函数 Y = f(X),或者由条件分布概率 P(Y|X)作为预测模型,即判别模型。
生成方法:由数据学习联合概率密度分布函数 P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
31、线性分类器与非线性分类器的区别以及优劣
线性和非线性是针对,模型参数和输入特征来讲的;比如输入x,模型y=ax+ax^2那么就是非线性模型,如果输入是x和X^2则模型是线性的。
线性分类器可解释性好,计算复杂度较低,不足之处是模型的拟合效果相对弱些。
非线性分类器效果拟合能力较强,不足之处是数据量不足容易过拟合、计算复杂度高、可解释性不好。
常见的线性分类器有:LR,贝叶斯分类,单层感知机、线性回归
常见的非线性分类器:决策树、RF、GBDT、多层感知机
SVM两种都有(看线性核还是高斯核)
32、L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方
33、L1和L2正则先验分别服从什么分布
面试中遇到的,L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
34、简单介绍下logistics回归?
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛。
比如在实际工作中,我们可能会遇到如下问题:
预测一个用户是否点击特定的商品
判断用户的性别
预测用户是否会购买给定的品类
判断一条评论是正面的还是负面的
这些都可以看做是分类问题,更准确地,都可以看做是二分类问题。要解决这些问题,通常会用到一些已有的分类算法,比如逻辑回归,或者支持向量机。它们都属于有监督的学习,因此在使用这些算法之前,必须要先收集一批标注好的数据作为训练集。有些标注可以从log中拿到(用户的点击,购买),有些可以从用户填写的信息中获得(性别),也有一些可能需要人工标注(评论情感极性)。
35、说一下Adaboost,权值更新公式。当弱分类器是Gm时,每个样本的的权重是w1,w2…,请写出最终的决策公式。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)}
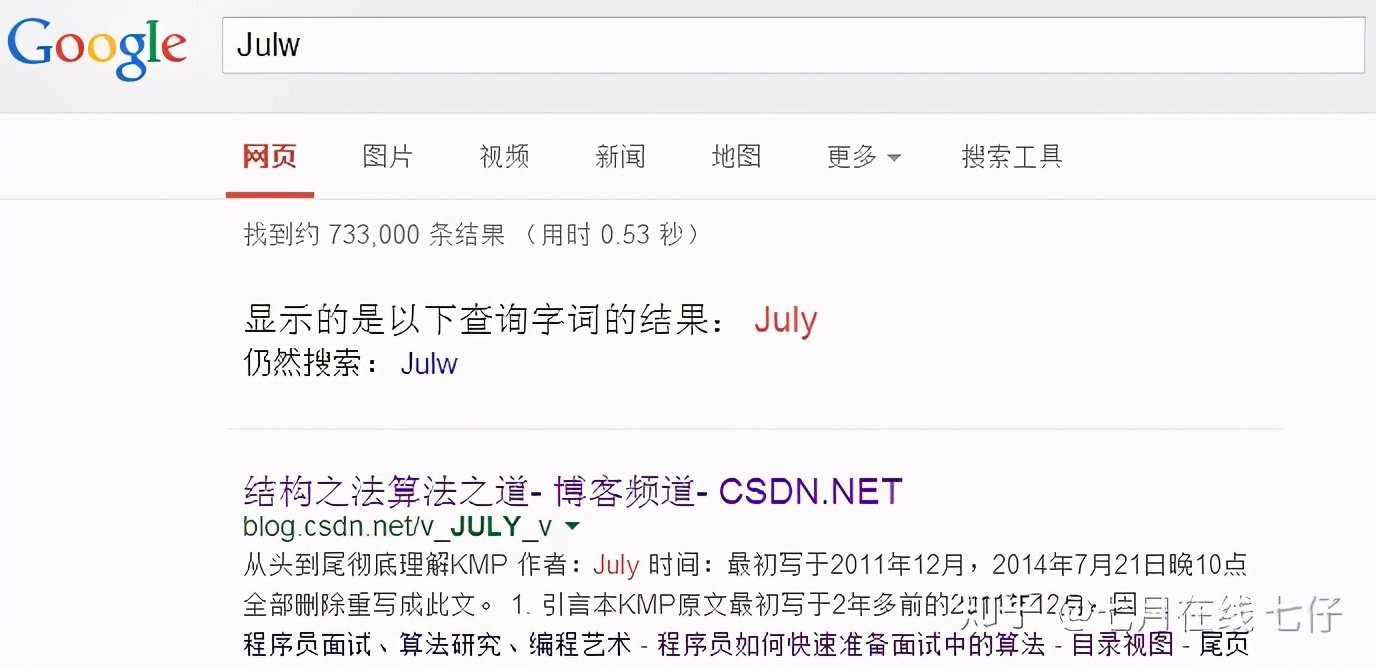
36、经常在网上搜索东西的朋友知道,当你不小心输入一个不存在的单词时,搜索引擎会提示你是不是要输入某一个正确的单词,比如当你在Google中输入“Julw”时,系统会猜测你的意图:是不是要搜索“July”
 梳理常见的机器学习面试题,你知道几个?
梳理常见的机器学习面试题,你知道几个?
用户输入一个单词时,可能拼写正确,也可能拼写错误。如果把拼写正确的情况记做c(代表correct),拼写错误的情况记做w(代表wrong),那么"拼写检查"要做的事情就是:在发生w的情况下,试图推断出c。换言之:已知w,然后在若干个备选方案中,找出可能性最大的那个c
37、为什么朴素贝叶斯如此“朴素”?
因为它假定所有的特征在数据集中的作用是同样重要和独立的。正如我们所知,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。
朴素贝叶斯模型(Naive Bayesian Model)的朴素(Naive)的含义是"很简单很天真"地假设样本特征彼此独立. 这个假设现实中基本上不存在, 但特征相关性很小的实际情况还是很多的, 所以这个模型仍然能够工作得很好。
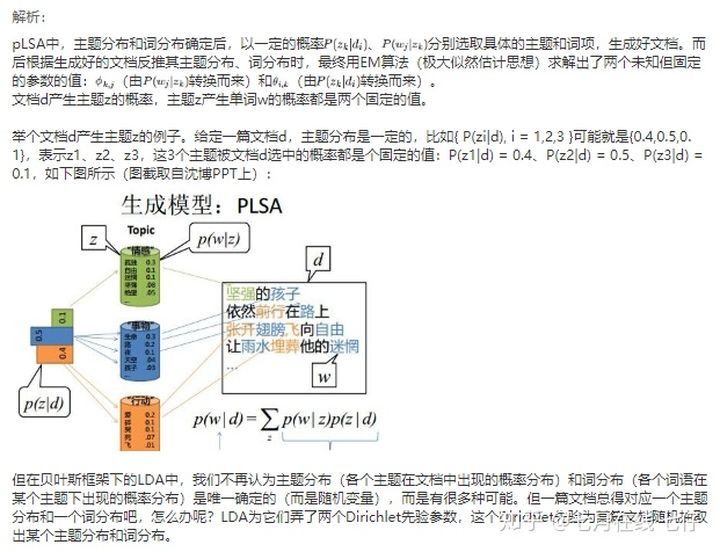
38、请大致对比下plsa和LDA的区别
 梳理常见的机器学习面试题,你知道几个?
梳理常见的机器学习面试题,你知道几个?
39、请详细说说EM算法
到底什么是EM算法呢?Wikipedia给的解释是:
最大期望算法(Expectation-maximization algorithm,又译为期望最大化算法),是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量。
40、KNN中的K如何选取的?
关于什么是KNN,可以查看此文:《从K近邻算法、距离度量谈到KD树、SIFT+BBF算法》(链接:
http://blog.csdn.net/v_july_v/article/details/8203674)。KNN中的K值选取对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%A2%B3%E7%90%86%E5%B8%B8%E8%A7%81%E7%9A%84%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E9%9D%A2%E8%AF%95%E9%A2%98%E4%BD%A0%E7%9F%A5%E9%81%93%E5%87%A0%E4%B8%AA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


