淘系技术内容推荐场景下多模态语义召回的若干实践
本系列将系统介绍召回技术在内容推荐的实践与总结。
背景
内容分发平台已经成为互联网用户获取信息资讯的主要来源,已经完全渗透进互联网用户的日常生活。内容推荐系统作为精准匹配用户和内容的手段,在内容分发的链路中举足轻重,而其中召回则决定了整个推荐系统的上界。内容分发平台中,基于行为的召回模型通过个性化建模不同尺度的用户兴趣,构建个性化的内容消费体验。但是完全依赖平台上的可用日志信息,会使得推荐系统容易陷入自旋,进一步加重信息茧房效应,优质的长尾内容无法得到更加公平的有效分发,不利于整个平台的生态健康。实际上我们知道生态的健康,几乎可以决定整个产品的发展态势。而且电商app下的内容消费场景中用户消费更加稀疏,在behavior-base的模型下他们的兴趣表征容易出现较大的bias, 需要有相应的手段保证这部分用户的兴趣匹配。content-base的召回方式由于与行为解耦,在缓解此类问题上具有一定的优势,传统的content-base方法包括标签、属性等召回,一定程度上能够缓解这类问题,但是标签和属性的匹配一般都比较hard, 泛化能力和扩展能力存在一定的瓶颈,而随着多模态和深度召回模型的演进,采用多模态和语义召回模型解决content-base问题成为众多推荐平台的利器之一。
整体算法框架
多模态语义召回整体的算法框架如下所示,主要包含几个部分。底层是内容理解模块,主要从文本、视频、音频、类目体系等方面对内容进行结构化理解,得到结构化的体系表征。在用户侧通过profile等提取用户兴趣标签等,在内容侧根据标题、描述、视觉信息提取出内容体系下的结构化表征,然后通过标签、图谱、多模态、语义DM等手段进行全方位的内容召回。基础的内容召回方面有标签召回、属性召回、query2v等,这部分工作在此不再赘述了。这部分召回相似度刻画的方式由于与平台用户行为完全解耦,在生态指标方面都有20%+的提升。多模态召回主要是通过理解内容多模态表征,先后进行了v2v、聚类中心召回、个性化多模态表征相关的探索工作,在多样性方面取得了一定的效果,深度语义召回方面针对用户行为去噪和更好的表达语义信息角度出发,迭代了cate aware和query aware和序列mask 自监督任务的模型,此外针对多种序列之间的更好融合,也提出了一种异构信息图的模型,下面作分别介绍。
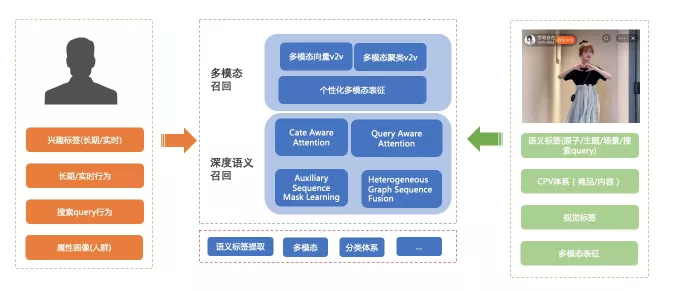
▐ 多模态召回
语义包含多层次的信息,除了文本标签之外还有视觉音频等,二者均对用户的决策具有一定的影响,两者相结合能够更好的表征出视频的语义信息和人格化特征。在推荐系统召回中更全面的理解视频内容也有益于更加全面的理解用户推荐意图,从而提升推荐的效果。目前业界比较常见的方案是多模态建模,将文本和视频等多种模态进行融合,互相促进表达,能够达到更全面理解视频内容的目的。一般而言文本视频融合有多种模式,通过参考业界和学术界的研究,多模态召回采用了video bert的架构,通过双流输入+later fusion 以及文本mask, 视频帧mask等辅助任务,更好的学习出多模态表达的内容,整体模型架构如下。
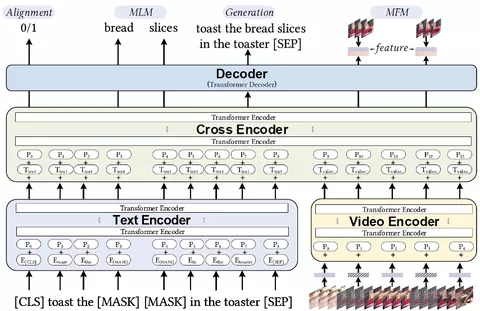
多模态召回根据不同的阶段,有三个有较为明显效果的迭代优化,向量v2v、聚类中心v2v和行为fineturn的个性化内容表征,下面分别介绍。
-
多模态召回v1.0: 向量v2v
基于大规模预训练模型,我们能够得到全部内容的多模态表征,融合了视觉和文本的表征一定程度上能够给推荐系统赋予找相似的能力。我们先后上线了视觉相似v2v和视觉聚类召回,前者基于多模态预训练表征,刻画用户trigger视频到分发视频的相似度,在线进行v2v召回,这一路上线之后,自然链路和冷启链路生态和效率指标均有一定程度提升(自然链路下7天内新发布容占比累计提升70%+,pctr/uctr基本持平). 实际的实验中更实时的trigger去进行v2v召回会有更明显的效果。

-
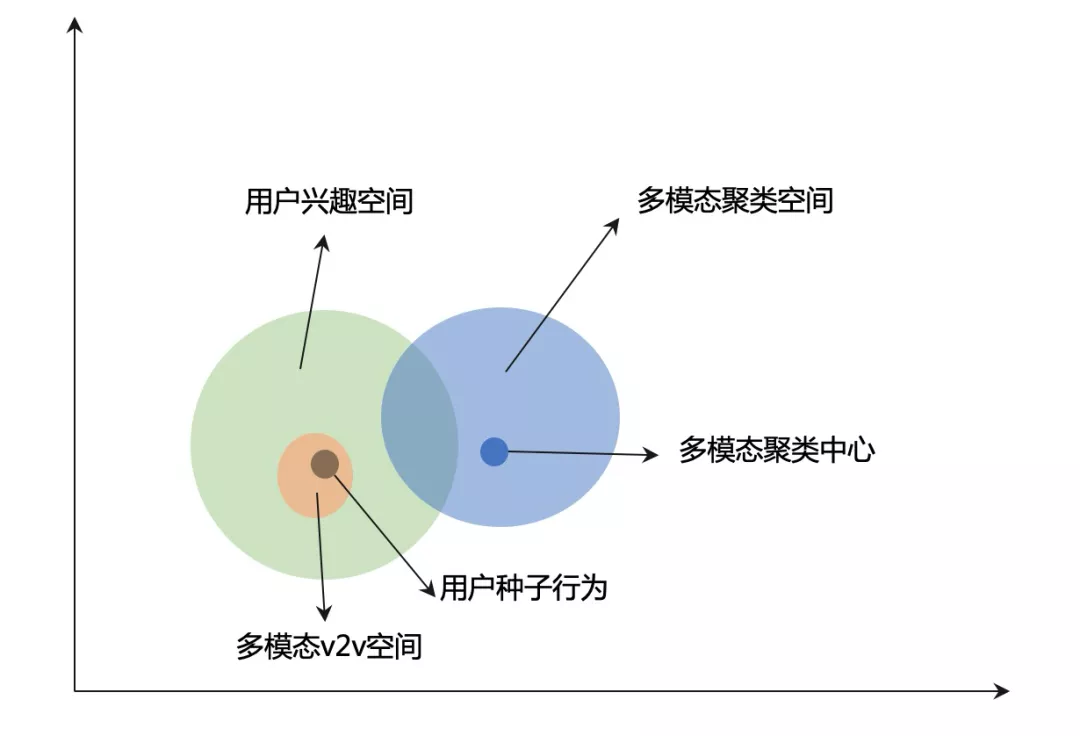
多模态召回v2.0: 聚类中心召回
v1.0 提供的是用户兴趣空间中的临近表达,解决的是找更相似的问题,类似于K近邻算法。但是在内容分发平台,频繁的推荐相似视频反而会更容易引起用户消费疲劳。所以我们希望通过一种更加泛化的“找相似”的方法去匹配用户兴趣。我们采用了聚类召回的方法,通过k-means聚类,将连续的、广泛的多模态空间降维为离散的、被约束的聚类空间。K-means聚类之后更有可能去触达到更广泛的用户兴趣,而且召回的内容更为发散。从图中可以得知,k-means聚类有更大概率命中用户兴趣(交叉部分面积较大),并且召回的类目更为发散。
在实际线上的时候,我们获取用户trigger视频的聚类id, 然后去召回这些聚类中的视频(如图所示)。通过将视觉表征抽象为视觉风格,召回宽度得到进一步加强。线上的召回宽度进一步得到提升,而且单路独占召回的多样性远超其他各路,上线之后多样性(唯一内容数)有19%+的提升。
-
多模态召回v3.0: 个性化多模态内容表征召回
多模态表征在训练的时候由于采用的是自监督的方式,仅仅建模内容本身的特征。但是在实际的情况下,一个视频中所描述的东西可能仅仅只有一部分是用户感兴趣的,如果我们在召回的是将全部视频内容的表征去进行相似度计算的话,很容易引入噪声而影响真正对大多数人都较为感兴趣的部分。所以我们需要有某种指导信号对我们已有的表征进行进一步个性化区分,我们希望达到的目标是,我们学习出的内容表征函数f(x)能够既能一定程度上能够表征内容,同时也能突出群体最感兴趣的部分。
很自然的,结合用户行为进行多模态表征finetune是值得尝试的方向,所以我们提出了结合多模态表征和用户行为的内容表征模块该模块结合海量用户偏好信号和预训练ready的表征,得到更贴合实际业务场景的内容表达。需要注意的是,虽然这里的样本也是基于可用的平台日志,但是统计类的特征和id类(contentId等)并没有被使用,因为我们的目标不是个性化的召回模型,而是通过群体智慧,对内容表征提炼出适配大多数用户的表达。
我们认为用户真实的表达Eu应该包含两个部分,ECu和EPu, 前者可以理解为对内容的无偏偏好,后者可以理解为个性化的偏好。而内容Ei本身也应该包含两个部分ECi和EPi, 前者ECi可以表达为内容本身的特征,在我们的模型里可以认为是通过滤波器对我们的多模态等特征的输入进行过滤得到的共同特征表现,而EPi则表示为内容的bias. 所以我们的模型在用户侧和item侧分别设计了两个bias, 来提取出个性化的偏执信息。
整个模型架构如下:
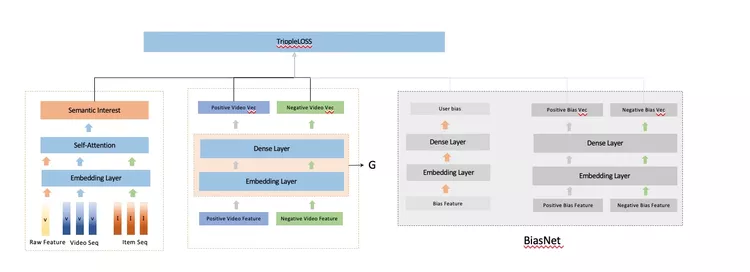
整个模型采用的是contrastive learning的框架,正样本来自于点击,负样本来自于随机采样+部分hard sample. 预训练好的多模态表征作为整个模型的输入。通过训练,我们便可以学习出一个能融合多模态和行为的语义表征函数G。
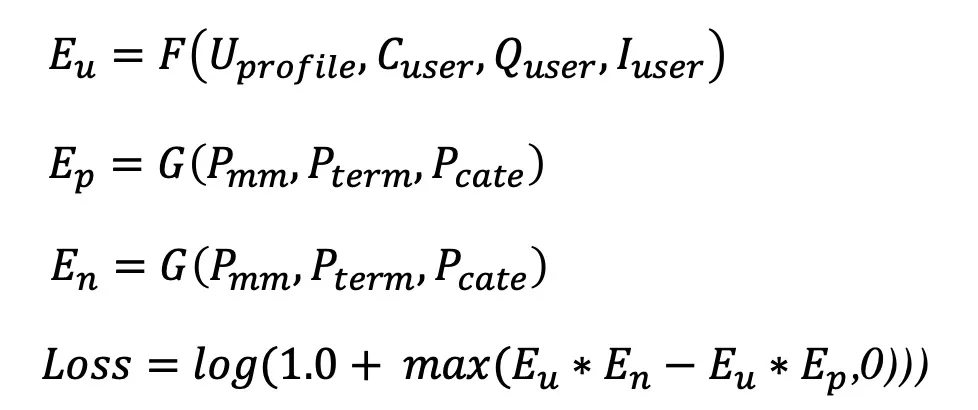
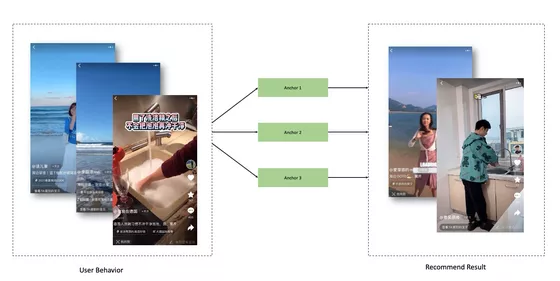
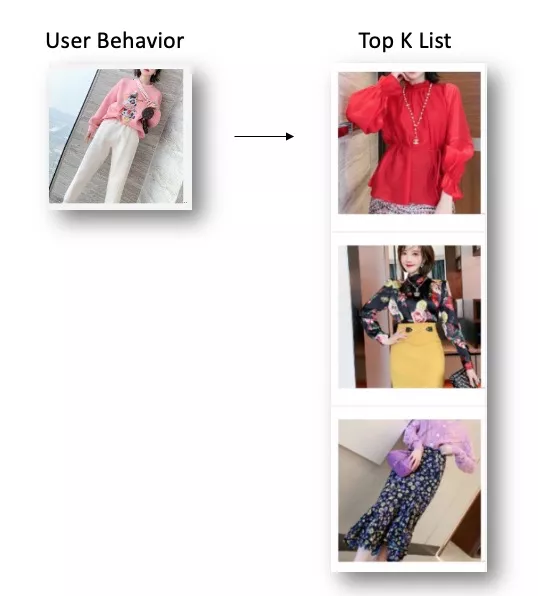
可以通过下面的case可以看到,模型捕捉到的不只是视觉层面的相似,更多是视频内所表示的内容。
这一路召回上线之后,在双列流和详情页在多样性和效率上均有一定的提升。其中双列流多样性能够提升10%+,详情页也有8%+的提升.
深度语义召回模型
在预训练模型和行为fineturn的加持下,内容表征得到进一步加强,生态效率等指标有一定提升。但是此时对于用户的表达还是依赖用户的实时行为,通过用户的实时行为经过triggerSelection等各种操作得到兴趣锚点,在利用T+1生成的v2v表进行召回,此时用户兴趣表达粒度较细,且泛化受到一定的局限,于是我们开始了端到端的深度语义召回模型的探索。
一提到语义匹配,搜索的同学肯定不陌生,搜索场景下语义相似一般意味着与query相似,匹配的核心是理解query和doc。但是在推荐场景下,语义匹配是一个更宽泛的问题-从单点到多点,解空间也更大更广,挑战也不太一样。
首先是用户行为的不确定性。与商品推荐不同的是,内容推荐场景下用户决策空间更大更广,从而导致用户对推荐系统的反馈信号本身就存在较大的不确定性,用户点击不一定代表语义相似,有行为不代表用户一定感兴趣。据统计在一跳场景中有超过40%的点击信号与用户行为在CPV空间或者词袋空间中没有任何关系,在这样的样本中想要学习用户真实的语义偏好,无异于把原本就不太容易优化的解空间增加更多的bias,如果贸然将这部分行为加入到用户表征中,会给模型带来一定的负担,需要一定的手段去进行噪音去除。当然完全过滤掉也让模型失去了泛化和破圈的能力,比如从鞋子泛化到衬衣,所以就需要在实际的模型中去权衡expoitation和exploration. expoitation旨在发掘用户真实偏好,而exploration则希望模型有一定的泛化.
再就是语义空间表达的对齐问题。这里的对齐包含两个方面,第一个方面是单个序列(例如内容点击序列)里的内容表达,内容本身能提现语义信息的有cpv、分词、语义标签、多模态表征等,需要将这些信息进行融合对齐,得到更合适的内容表达。另外一个方面是多序列之间的语义空间对齐问题。平台内行为序列多样,且用户除了在内容域消费之外,商品域、搜索域等行为也提供了丰富的语义信息,但是这些语义信息尺度不一,粒度不一,且空间也不尽相同。从简单的文本分布和CPV分布来看,商品域和内容域就存在诸多不一,文本分布方面商品域较多的关注商品买点属性,而内容则更多的关注种草体验,所以我们也需要去考虑多序列融合的问题,当然这方面业界和学术界有大量的工作在进行实践,我们的探索工作也是站在前人的肩膀之上。
基于以上几点考虑,在深度语义匹配模型我们作出了几种尝试。首先针对行为不确定的问题,我们尝试过手动去进行样本过滤,具体是根据标签分类体系对target content和序列中的seq content进行匹配校验,如果不符合则将样本剔除。但是实际中发现在语义召回方面离线评测提升不大,原因在于剔除出这部分样本之后,原因在于这种操作降低了模型的兴趣泛化能力,让兴趣更加收敛,从而影响效果。我们一般通过self-attention 自适应的去进行信号去噪,但是self-attention并不能够完全的建模用户真实的语义偏好,基于此我们分别提出了Cate Interest Aware Attention和Query Aware Attention,通过结合用户真实的类目偏好和搜索query seq去对内容和商品序列进行去噪,实际的效果也验证了这种方式的效果,在双列流和全屏页的实验也有不错的提升。针对语义空间对齐的问题,单序列内容表达我们提出了sequence mask learning的方法,通过辅助任务增强语义表达,提升效果。针对多序列的融合我们借鉴了集团内外的工作,提出了异构信息图 的序列融合方法,通过语义标签信息构建多序列之间的异构信息图模型,通过标签信息构建异构序列之间的异构图,然后在图中进行信息的对齐和表达, 下面进行分别介绍。
▐ Cate Aware Attention
顾名思义,cate aware attention是借助于用户真实的类目偏好,对序列进行attetntion, 更偏向于语义空间向用户类目偏好靠起,用到的是商品域内的类目偏好信息。整个模型架构如下:
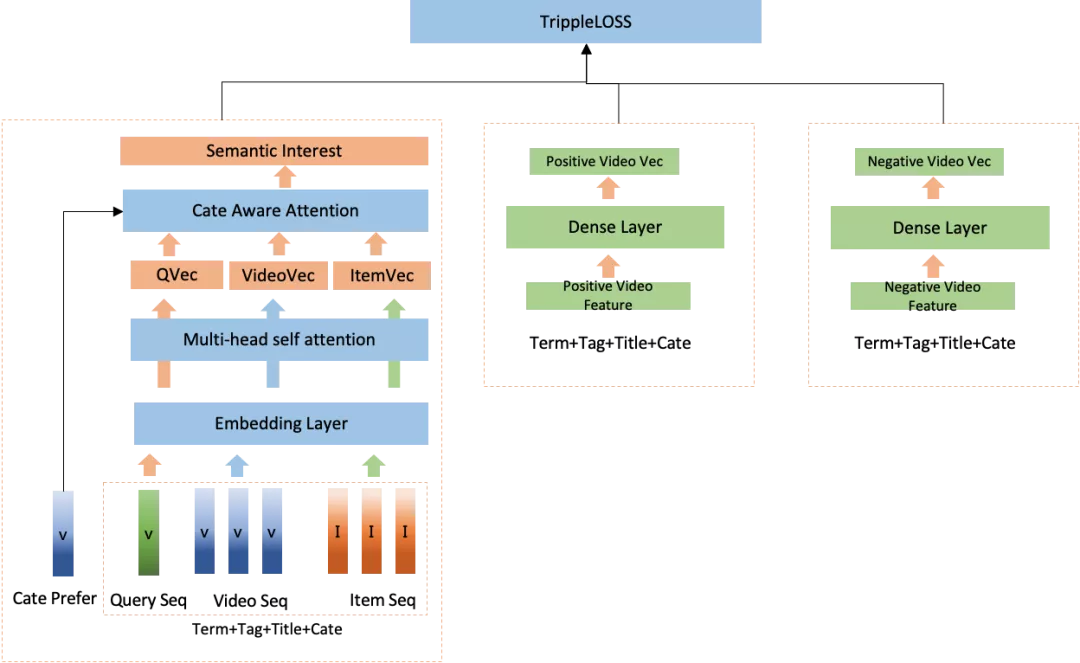
从架构来看,可以用户实时和长期的类目偏好分别和query sequence, video sequence, item sequence中的类目信息进行attention, 然后得到用户的表达。这样做的好处是能够通过用户先验的类目偏好约束用户表征,这个操作类似于在搜索语义召回中我们一般会对向量召回加入类目簇的约束,类目体系下更相关某种程度上可以认为表达的语义兴趣更为精准,模型上线后,vv +1.7%, 多样性+4%,七天内内容pvr 提升30%+ 。
ModelTypehitRate@100hitRate@50hitRate@30hitRate@10CatAttention11.79%8.16%6.15%3.36%Base9.63%6.31%4.56%2.16%
▐ Query Aware Attention
基于cate aware attetnion的方式利用了用户的类目偏好,在序列之间做attention, 但是实际上序列之间也应该有一定的交互关系,query aware attention通过加入query sequence 对content sequence 和 item sequence的attention, 构建intra aware attention,能够一定程度上增强序列的语义表达。
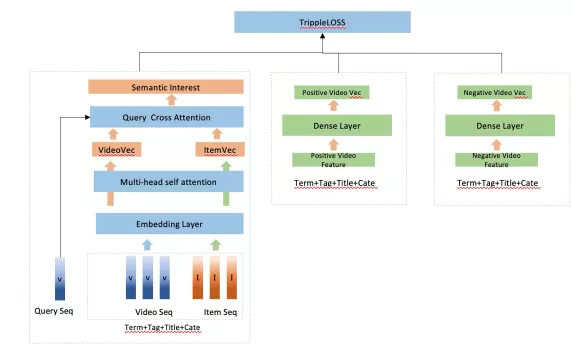
cate aware attention这种inter aware的方式能够约束语义表达到用户的类目偏好空间,而query aware attention则可以在早期的sequence fusion中提炼语义表达,提升精度。在实际的实验中,这种方式在线上有较好的效果,单路ctr相较于其他路deepMatch都有2%+的提升,对大盘也有正向的收益,双列流内短视频pctr提升+1.3%。
ModelTypehitRate@100hitRate@50hitRate@30hitRate@10QueryAttention13.67%9.72%7.37%3.94%CatAttention11.79%8.16%6.15%3.36%Base9.63%6.31%4.56%2.16%
▐ Auxiliary Sequence Mask Learning
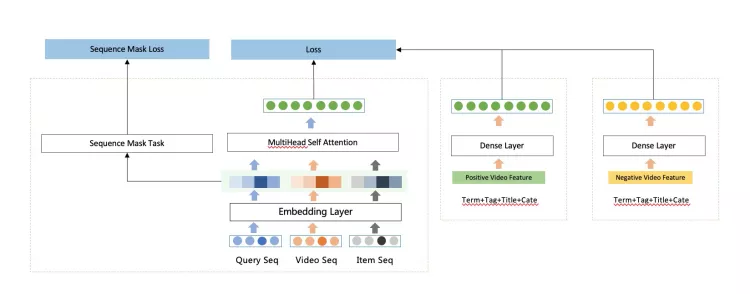
端到端的deepMatch模型依赖于较好的语义表达,所以我们期望通过一些辅助的任务,帮助模型更好的捕捉到单序列内的语义表达(当然我们也尝试过预训练好的cate,term embedding作为模型输入,也有一些效果), 我们设计了序列重建任务,通过在各自序列内,随机mask 掉一个位置,然后将序列重构任务作为总任务的辅助loss。
整个模型架构如下:
▐ Heterogeneous Graph Sequence Fusion
这部分工作与另外一部分关于图召回的工作类似(见:url), 主要的动机来自于多序列融合的考虑,原本的融合方式一般是经过self-attention + MLP做late fusion, 或者类似于前面query aware attention这种cross attention的方式,但是这些融合方式并不�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%98%E7%B3%BB%E6%8A%80%E6%9C%AF%E5%86%85%E5%AE%B9%E6%8E%A8%E8%8D%90%E5%9C%BA%E6%99%AF%E4%B8%8B%E5%A4%9A%E6%A8%A1%E6%80%81%E8%AF%AD%E4%B9%89%E5%8F%AC%E5%9B%9E%E7%9A%84%E8%8B%A5%E5%B9%B2%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


