淘系技术召回技术在内容推荐的实践总结
“本文从跨域联合召会、语义&图谱&多模态、用户多兴趣表征和未来工作四个模块展开。”
引言
内容化这几年越来越成为电商的重点,用户来到网购的时候越来越不局限在只有明确需求的时候,而更多的是没有明确需求的时候,就像是逛街一样。逛逛就是在这样的背景下诞生的内容化产品,打造出有用、有趣、潮流、奇妙、新鲜的内容,为消费者提供全新的内容消费体验。在这个场景下的内容召回有很多问题需要探索,其中主要的特点和挑战有:
- 强时效性:内容推荐场景下的内容新旧汰换非常快,新内容的用户行为少,很难用用户历史行为去描述新内容,而用户行为正是老内容投放主要的依赖。所以当不能依靠用户行为数据来建模内容之间关系的时候,我们必须要找到其他可以表征内容的方法。
- 多兴趣表征:多兴趣表征,特别是多峰召回是这几年比较主流的一个趋势。但是目前多峰模型中峰的数量是固定的,当用户行为高度集中的时候,强制的将用户行为拆分成多向量,又会影响单个向量的表达能力。如何去平衡不同用户行为特点,特别是收敛和发散的兴趣分布,就成了此类任务的挑战。
在设计优化方向的时候,我们重点考虑上面描述问题的解法(召回本身也需要兼顾精准性和多样性,所以单一召回模型显然无法满足这些要求,我们的思路是开发多个互补的召回模型)。详细的介绍在后面的章节以及对应的后续文章中展开:
- 跨域联合召回 :除了单纯把多域的信息平等输入到模型中,如何更好利用跨域之间的信息交互就变的尤为重要。目前有很多优秀的工作在讨论这样的问题,比如通过用户语义,通过差异学习和辅助loss等。我们提出了 基于异构序列融合的多兴趣深度召回模型CMDM(a cross-domain multi-interest deep matching network),以及 双序列融合网络Contextual Gate DAN 2种模型结构来解决这个问题。
- 语义&图谱&多模态 :解决时效性,最主要的问题就是怎么去建模新内容,最自然的就是content-based的思想。content-based的关键是真正理解内容本身,而content-based里主要的输入信息就是语义,图像,视频等多模态信息。目前有许多工作在讨论这样的问题,比如通过认知的方式来解决,多模态表征学习,结合bert和高阶张量等方式等等。在语义召回上,我们不仅仅满足于语义信息的融入,还通过 Auxiliary Sequence Mask Learning 去对行为序列进行高阶语义层面的提纯。更进一步,我们利用内容图谱信息来推荐,并且引入了 个性化动态图谱 的概念。对于新老内容上表达能力的差异问题,我们通过 multi-view learning 的思想去将id特征和多模态特征做融合。
- 泛多峰 :为了解决多峰强制将兴趣拆分的问题,我们考虑到单峰和多峰的各自特点,特别是在泛化和多样性上各自有不同的建模能力。基于此,我们提出了 泛多峰 的概念。
跨域联合召回
▐ 基于异构序列融合的多兴趣深度召回
在单一推荐场景下,深度召回模型只需要考虑用户在当前场景下的消费行为,通过序列建模技术提取用户兴趣进而与目标商品或内容进行匹配建模。而在本推荐场景下,深度召回模型需要同时考虑用户内容消费行为和商品消费行为,进行跨场景建模。为此,我们提出了CMDM多兴趣召回模型架构,能够对用户的跨场景异构行为序列进行融合建模。在CMDM中,我们设计了用于异构序列建模的层级注意力模块,通过层级注意力模块提取的多个用户兴趣向量与目标内容向量进行匹配建模。
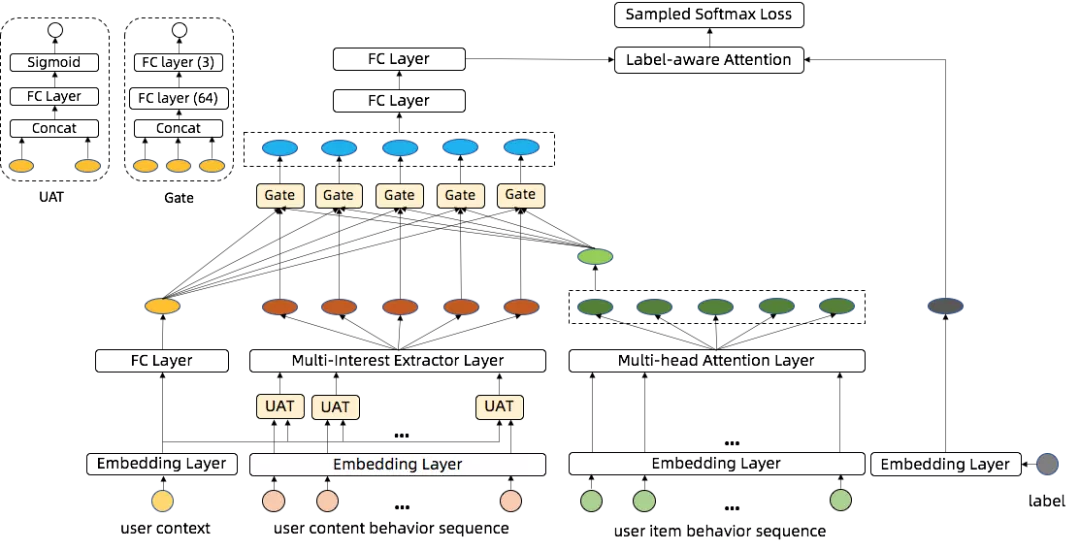
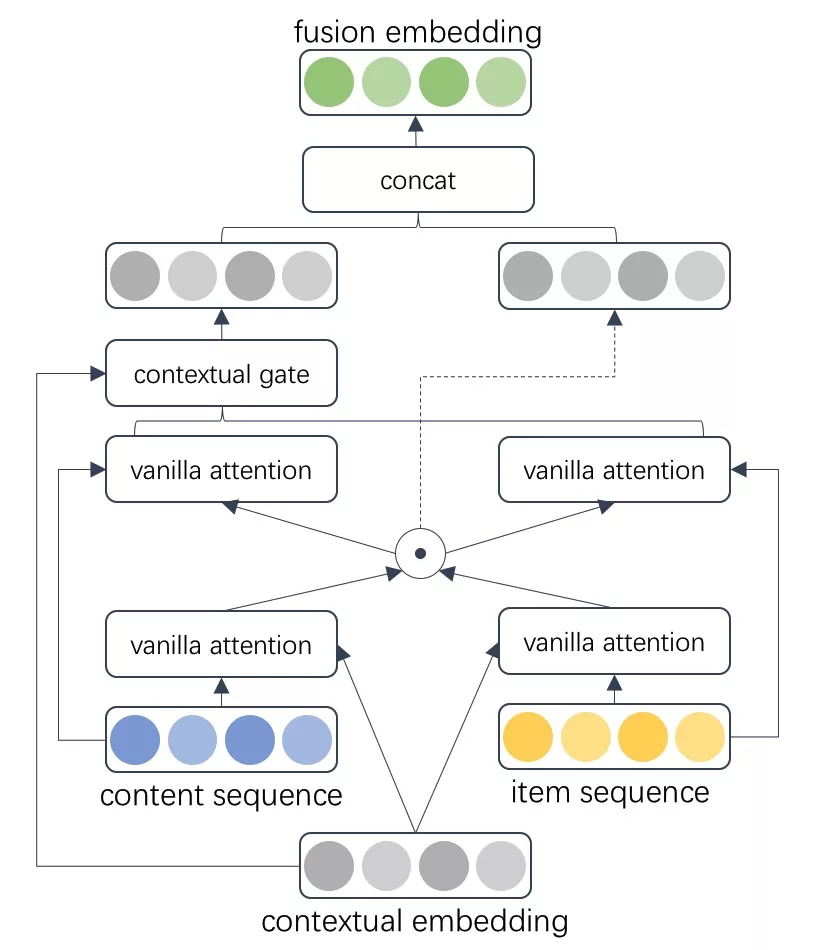
▐ 双序列融合网络Contextual Gate DAN
除了通过层次注意力的方式,异构序列中还有个特点就是在时间上更接近交叉并存的状态。为了学习到两个序列之间的信息交叉,充分融合商品点击序列和内容点击序列,我们从自然语言处理的VQA任务中得到启发。VQA是用自然语言回答给定图像的问题的任务,常用做法是在图片上应用视觉注意力,在文本上应用文本注意力,再分别将图片、文字多模态向量输入到一个联合的学习空间,通过融合映射到共享语义空间。而DAN结构是VQA任务中一个十分有效的模型结构,DAN通过设计模块化网络,允许视觉和文本注意力在协作期间相互引导并共享语义信息。我们对DAN结构进行了改进,设计了Contextual Gate DAN 双序列融合网络:
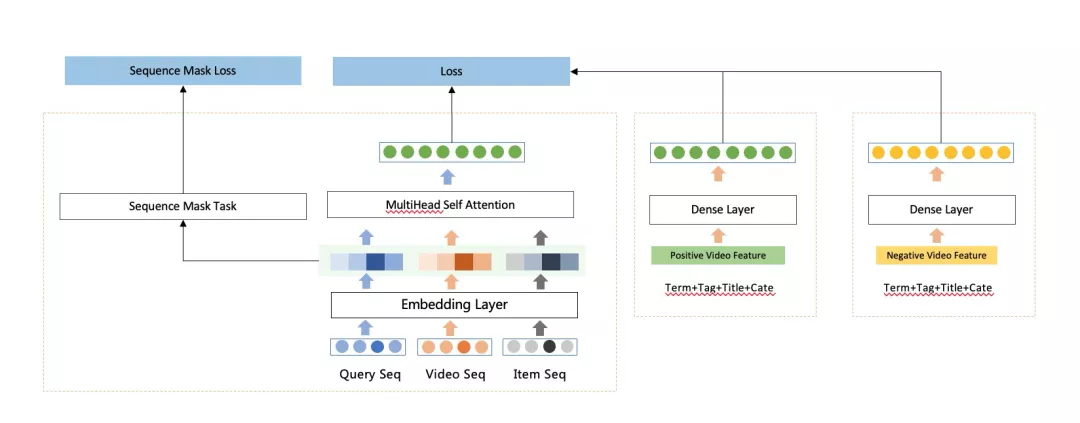
语义&图谱&多模态
▐ 多模态语义召回
在内容推荐场景内,存在大量新内容需要冷启动,我们主要通过语义和多模态2种方式。相对于搜索任务,语义匹配是一个从单点到多点,解空间更大更广的问题。首先是用户行为的不确定性,内容推荐场景下用户决策空间更大更广,从而导致用户对推荐系统的反馈信号本身就存在较大的不确定性;再就是语义空间表达的对齐问题,这里的对齐包含两个方面,第一个方面是单个序列里的内容表达的语义标签提取方式差别大(比如cpv、分词、语义标签、多模态表征等等),另外一个方面是多序列(内容和商品等)之间的语义空间对齐问题。多模态的召回方式融合了文本,图像,音频等大量模式跨域信息,由于与内容互动解耦,在缓解内容冷启动上具有一定的优势。多模态召回主要是通过理解内容多模态表征,先后进行了collaborative filtering、聚类中心召回、个性化多模态表征相关的探索工作,在多样性方面取得了一定的效果,深度语义召回方面针对用户行为去噪和更好的表达语义信息角度出发,迭代了cate-aware和query-aware和序列mask 自监督任务的模型。
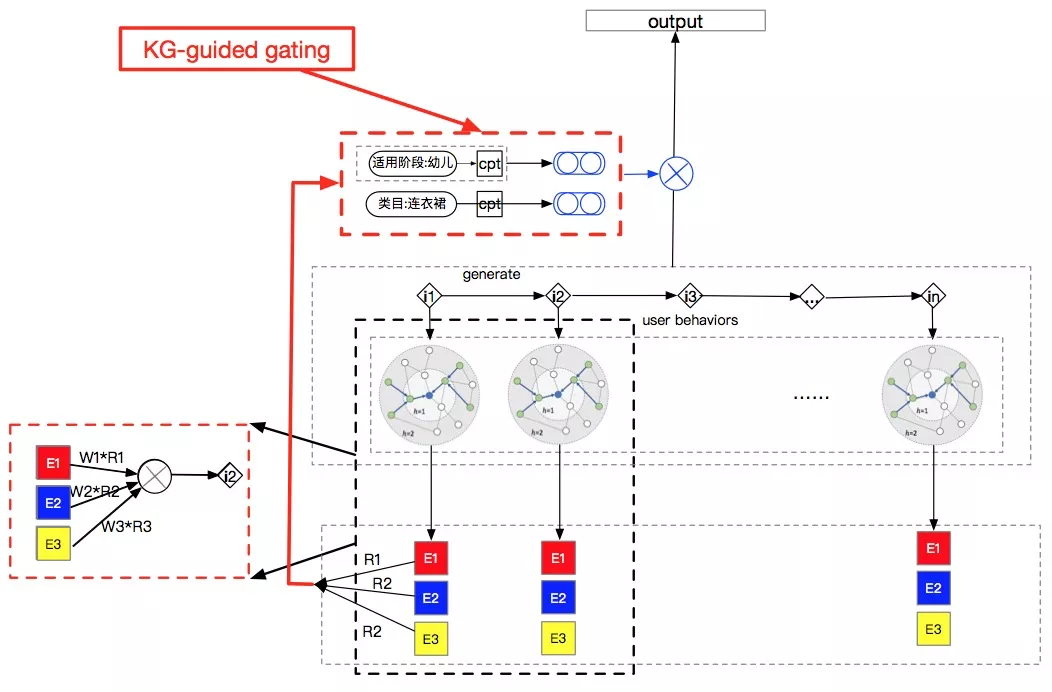
▐行为稀疏场景下的图模型实践
更进一步,我们利用内容图谱信息来推荐。知识图谱构建的出发点就是对用户的深度认知,能够帮助系统以用户需求出发构建概念,从而可以帮助理解用户行为背后的语义和逻辑。这样可以将用户的每次点击行为,都用图谱的形式极大的丰富,图谱带来的可解释的能力还可以大大加快模型的收敛速度。知识图谱有个特点,就是其中的信息是相对固定的,或者说是静态的,因为知识图谱基本是由先验信息构成的。但是从各个用户的角度,知识图谱的数据中的链接重要度并不相同。比如一个电影,有的用户是因为主演看的,有的用户是因为导演看的,那么这个电影连接的主演边和导演边的权重就因人而异了。我们提出了一种新的方法来融合用户动态信息和静态图谱数据。每个行为都用图谱扩展,这样行为序列变成行为图谱序列, 并且加入KnowledgeGraph-guided gating的自适应的生成式门控图注意力,去影响知识图谱融入到模型中的点边的权重。
▐ 融合多模态信息的跨模态召回
针对新内容冷启动的问题,我们提出了跨模态召回模型来兼顾content-based和behaviour-based的召回各自的优点。在跨模态召回模型构建前,我们首先引入了多模态meta信息为主的“语义” deep collaborative filtering召回,两者的显著差别主要在target side的特�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%98%E7%B3%BB%E6%8A%80%E6%9C%AF%E5%8F%AC%E5%9B%9E%E6%8A%80%E6%9C%AF%E5%9C%A8%E5%86%85%E5%AE%B9%E6%8E%A8%E8%8D%90%E7%9A%84%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


