淘系技术淘宝视频的跨模态检索
本系列将介绍在淘宝内容电商生态业务中,对短视频直播这类多媒体内容的识别理解工作。其中包括多媒体内容标签结构化、内容多模态融合识别、超大规模视频标签理解、跨模态语义检索、实时流媒体内容数字化、视频highlight提取及创意生产、多模态内容标签图谱建设等方面的工作成果。
本篇是淘宝视频的第三篇,前两篇可见:
背景
近年来短视频应用大火,视频媒体逐渐成为用户消费的主要内容载体之一,对视频内容的精准检索成为重要的技术需求。自然文本描述和视频进行跨模态检索(Cross-Modal Text-Video Retrieval)是最符合自然人机交互的方式之一,通过描述文本语义特征和视频理解多模态特征的相关性计算,满足用户对视频内容的检索需求。本文工作针对淘宝首猜全屏页、逛逛等内容场景,采用文本-视频跨模态检索的方法,实现淘宝大规模内容标签和视频的挂靠[1,3]。

淘宝内容社区中,商家及用户上传视频有较大内容随意性,内容发散性和内容多模态的特点,对内容搜索及推荐结果准确性的衡量,用户更多通过视觉内容判断是否符合自身需求兴趣,视觉信息对于视频内容语义表征十分重要。视频检索文本标签主要有3种方式:
- 内容文本检索标签;
- 图像序列检索标签;
- 视频多模态内容检索标签。
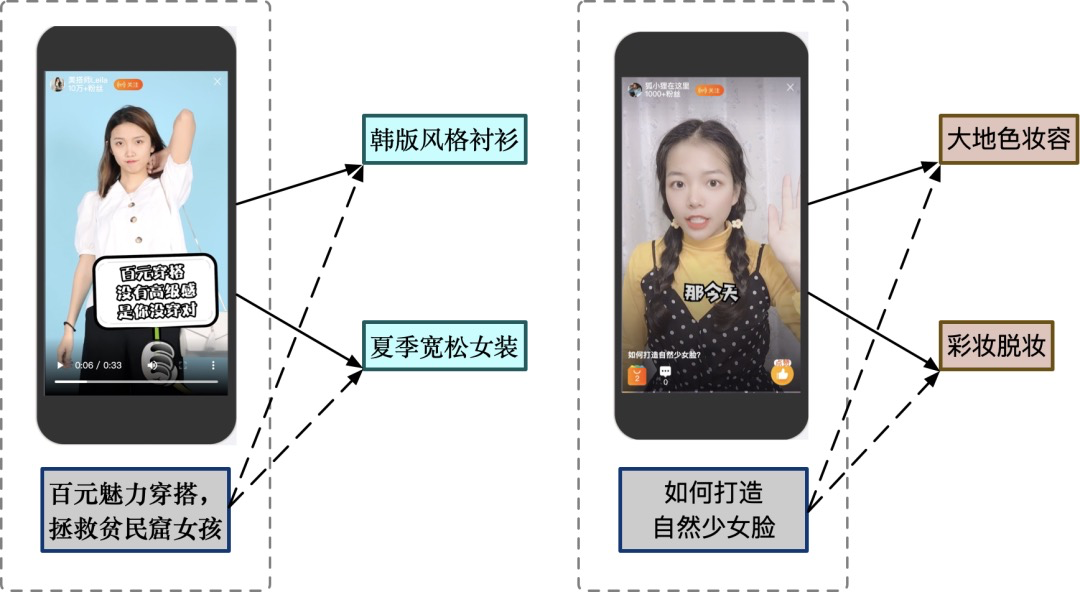
如下图视频内容文本与主题标签内容存在显著差异,视频内容文本检索标签的方式由于视频文本信息不足,难以匹配精准的主题标签满足用户的内容消费需求。视频图像分析主要理解视觉画面信息,缺少对文本语义的挖掘,语义信息不足以准确检索出符合的主题标签。考虑到标题文本信息不足语义缺失的问题以及视频多模态内容信息互补性的优势,视频多模态内容检索标签的方法更加贴合内容标签和淘宝视频挂靠的任务。
相关工作
跨模态检索的主要技术挑战在于底层特征异构,高层语义相关。当前跨模态检索主流的技术方法是编码不同模态数据到共同的隐空间,消除不同模态数据的语义gap实现语义特征的对齐,计算不同模态数据之间的特征相似度实现准确的检索。早期工作主要采用RNN类模型对文本侧进行特征编码,采用CNN类模型对视频图像侧进行特诊编码,接着结合ranking loss进行度量学习[10-13]。下一阶段工作着重于语义局部对齐,主要有几个思路:
- 文本侧分解文本的字词,图像侧切分图像区域,基于交互注意力实现局部特征细粒度对齐[9]。
- 分别对文本侧字词和图像侧图像区域构建图网络结构,结合GCN学习局部特征之间相关性[10][11]。
- 文本和图像的相互生成,通过对抗训练实现局部语义的对齐[12]。
以上前沿工作主要在图像-文本检索任务上实现,当前图像-文本检索任务在集团内部业务上的尝试也取得了不错的效果,如夸克图搜[6],封面图挑选[7,8]。以上论文工作目前在各大公开数据集达到了十分卓越的性能,但是应用于本文工作时存在以下问题:
- 文本-视频检索数据来源于淘宝点击日志,样本不均衡问题是个重大挑战。
- 语义局部对齐有不同模态特征的交互计算,在大规模召回场景中向量检索效率低下。
- 如何更加有效地表征视频多模态信息,融合互补多模态信息检索准确的主题标签。
对于视频-文本检索任务,视频内容的多模态特点和时空信息复杂性让该检索任务更具挑战性。本文工作针对视频-文本检索任务展开研究和讨论,实现基于图神经网络的视频跨模态检索算法。
算法
本文的任务场景是给定淘宝视频标题内容文本、视频图像以及主题文本标签,完成文本到视频的跨模态检索,进一步提升检索准确率。为此设计的算法思路着力于消除不同模态的语义鸿沟,同时保证同模态内容的语义判别性。
考虑到淘宝主题标签与视频数据挂载分布特点和大规模高效检索的需求,文本与视频的大规模检索拟解决的挑战如下:
- 训练样本稀疏和均衡:主题标签关联商品或视频内容有不同热度和关注人群密度,点击日志中主题与视频挂靠呈现不均衡性和稀疏性,如何实现构建更多的隐Pair训练过程中进行数据增强。
- 同模态语义判别性:主题标签与视频的匹配二值标签无法提供单模态同语义样本的度量约束。
- 多目标学习:同模态度量学习和跨模态度量学习的联合训练。
- 大规模检索效率:语义相关性模型检索效率比语义检索模型低,采用双塔模型结构实现。
针对上述技术挑战,本文的算法模型设计结合图神经网络GraphSAGE[15]的双塔检索框架,该框架的优点:
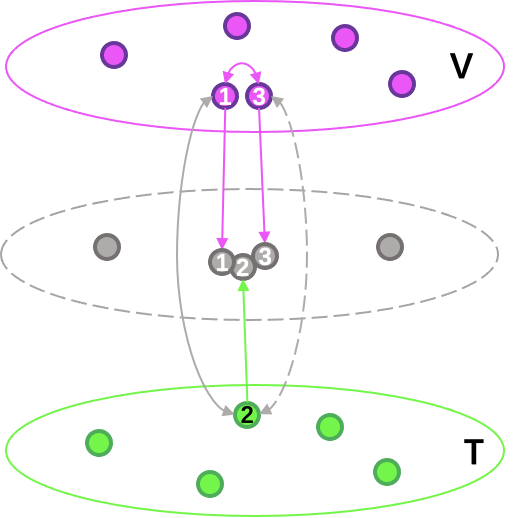
- 通过图网络构建缓解训练样本稀疏和均衡问题。样本1和样本2有点击Pairs标签,样本3和样本2内容表达一致但没有点击Pairs标签,在图网络中拉近样本1和样本3的特征距离来间接拉近样本2和样本3的特征距离。
- 图网络中同模态和跨模态端到端的度量学习进一步保证不同模态的语义一致性和同模态语义的判别性。
- 可以实现高效的大规模检索。
该模型主要包括文本编码模型、视频多模态编码模型、图网络算法模型、度量学习模型。
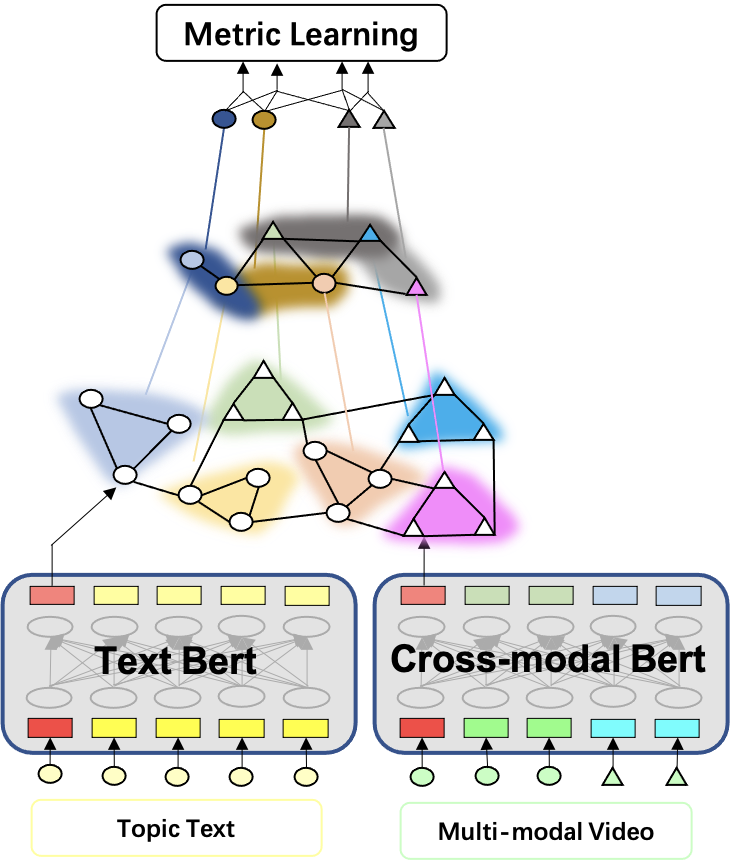
▐文本编码
文本编码将主题标签文本转为定长实数向量,该向量能够反映主题内容信息,与视频编码向量进行相似度计算。本文在实验中尝试过通用预训练BERT、淘内预训练RoBert、Transformer等结构,最后综合考虑性能和效率采用了从头开始训练的6层Transformer结构。其首先对query进行分词,每个分词的word embedding初始参数随机;分词长度固定,不足补零,过长直接截断;整个文本所有参数random初始化,和检索模型一起端到端训练参数更新。
▐视频编码
视频编码模型主要是将视频多模态数据转化成反映视频内容的特征向量。为了提升训练效率,本文的视频多模态表征向量采用淘内数据预训练的视频多模态预训练模型离线提取的特征,尝试的模型包括双流网络结构LXMERT[3,13]和单流网络结构UniterVideo[4,5,14]。多模态模型输入每个视频帧提取的inception V4图像特征以及视频对应的描述信息,例如视频标题,summary等信息,设计了4个task,Mask Language Model(MLM), Mask Region Model(MRM), Video Text Match(VTM)以及商品类目分类模型(CLS),整体模型结构如下。
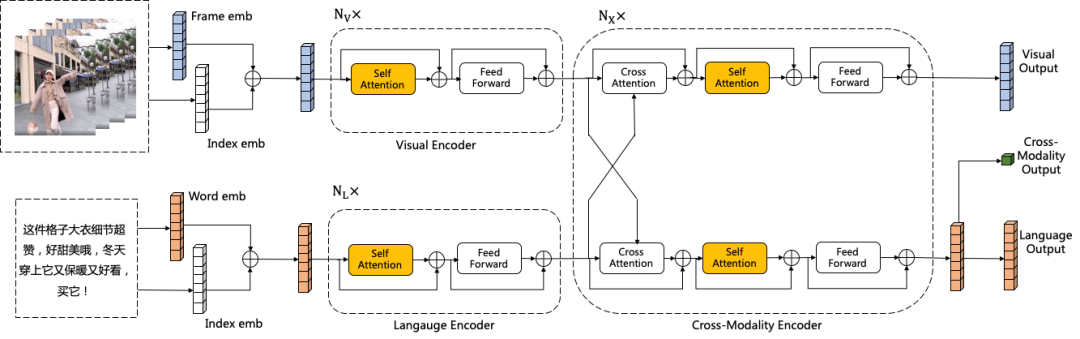
LXMERT双流架构
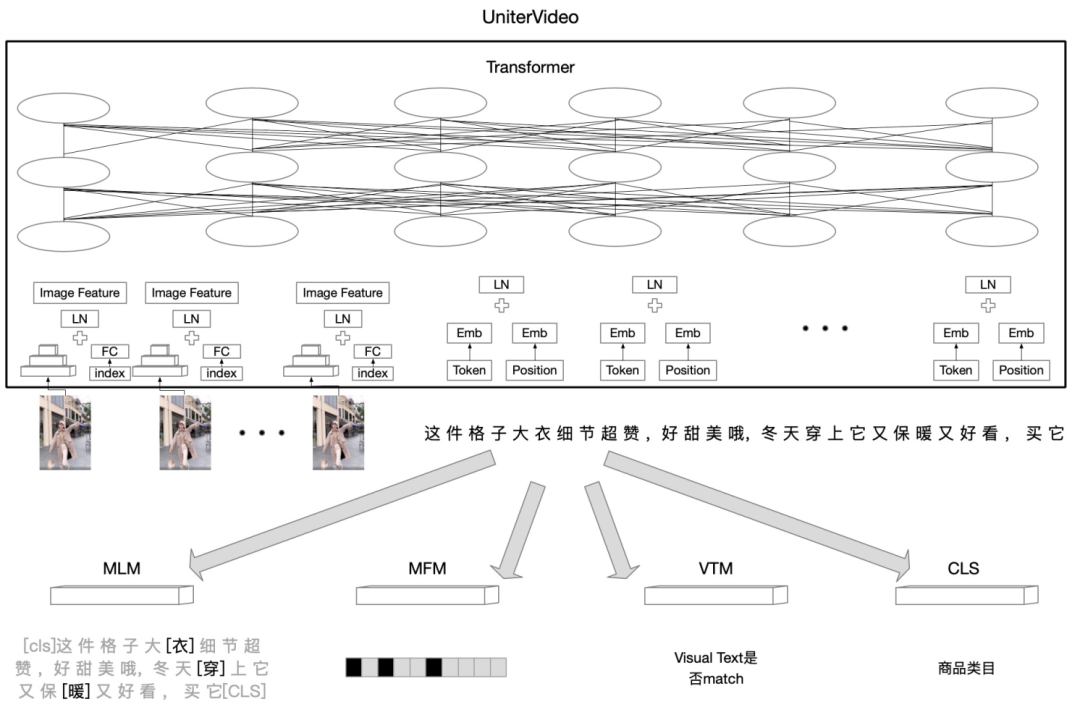
Uniter单流架构
▐图网络模型
本文工作在经典双塔模型的技术上嵌入GraphSAGE图神经网络模型,在大规模图上学习结点embedding,集团的GraphLearning图学习框架为本文的算法提供了框架基础。整体的图网络学习框架如下,其中输入特征分别来自文本编码和视频编码的输出特征。

-
大规模异构图构建
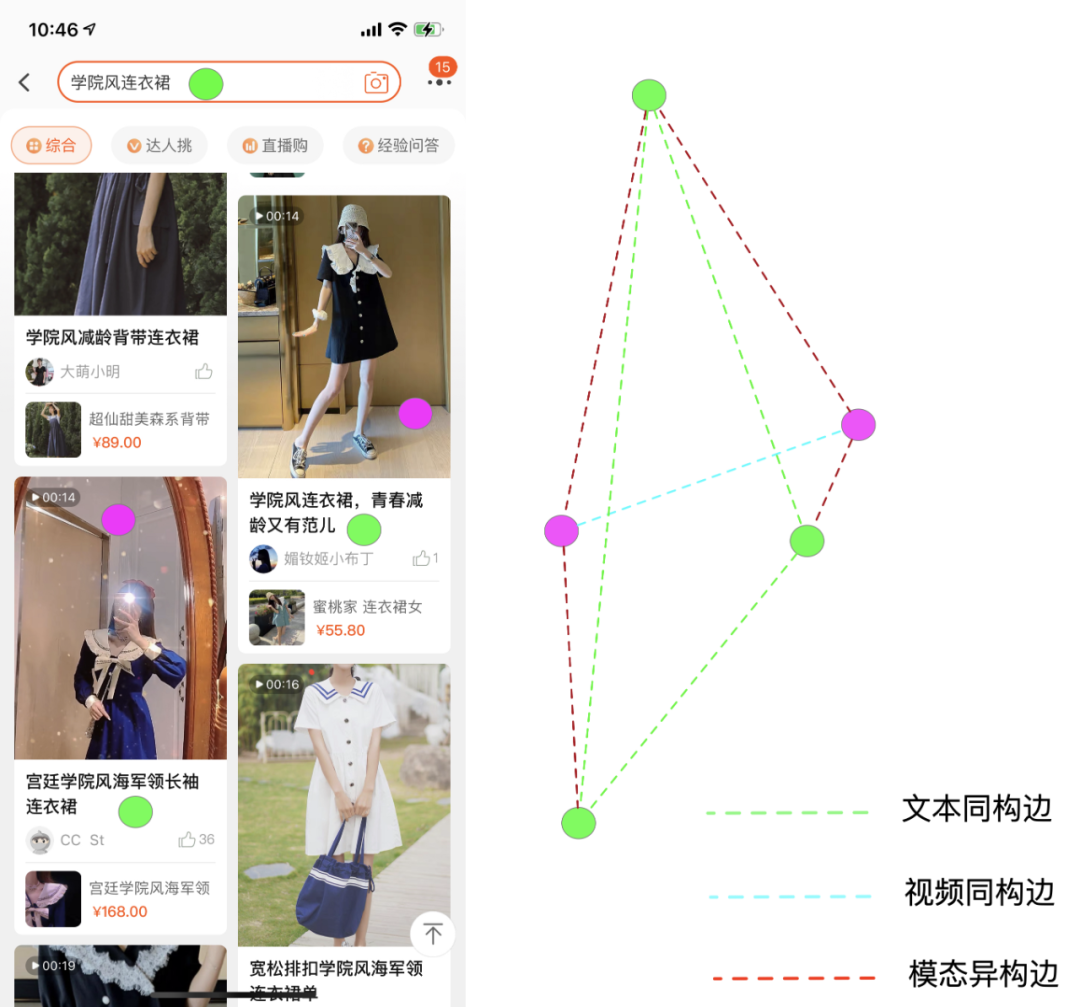
建图的合理性和准确性是影响图结点特征学习的重要因素,从提升结点覆盖率和构边置信度两个目标出发,本文采用先验特征相似和后验点击行为对视频和主题标签构建图网络。
基于用户点击行为建图
- 文本-视频 异构图:在云主题搜索、内容搜索、淘宝经验、手淘搜索等搜索场景中用户在主题标签或query下挂的视频列表中触发的点击行为作为文本-视频异构构边的依据。
- 文本-文本/视频-视频 同构图:在云主题搜索、内容搜索、淘宝经验、手淘搜索等搜索场景,同一用户在同一query下点击的视频有高度相关的语义,同一用户在聚合主题下点击的外透视频内容也十分类似,这些视频两两构边。同一视频挂靠的主题标签和搜索query也同理构边。
基于语义相似度建图
- 文本-文本/视频-视频 同构图:对于新样本和冷启动样本采用文本或视频预训练模型提取的特征计算语义相似度,分别在视频池和语料库中选取相似度最高的TOP10样本构边。对于新样本和冷启动样本采用文本或视频预训练模型提取的特征计算语义相似度,分别在视频池和语料库中选取相似度最高的TOP10样本构边。
-
邻结点采样
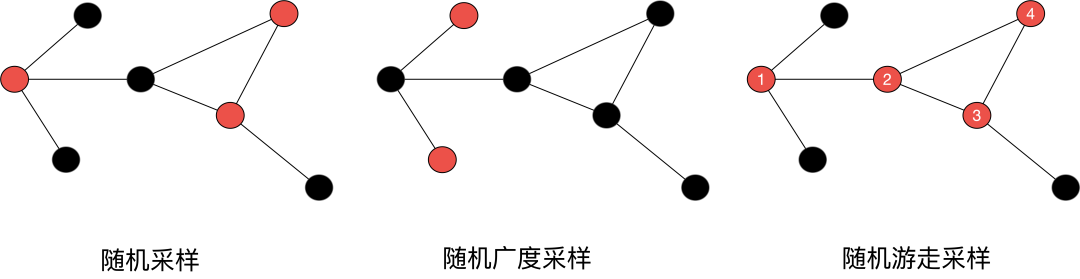
图结点邻居采样的方式常用包括:随机采样,随机广度采度,随机游走采样Random Walk。考虑到经典随机游走算法对于度大节点的偏向性问题,本文采用修正改进版本的游走策略,降低度大节点的游走概率, 结点
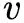 对邻居结点采样概率为:
对邻居结点采样概率为:
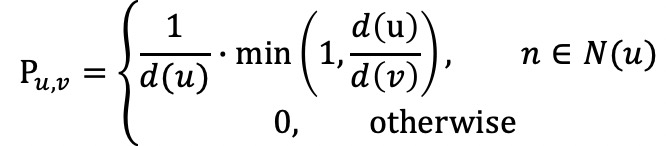
其中,
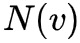 表示结点
表示结点
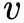 的邻结点集,
的邻结点集,
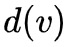 、
、
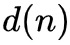 分别表示结点
分别表示结点
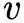 和
和
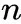 的度数。
的度数。
-
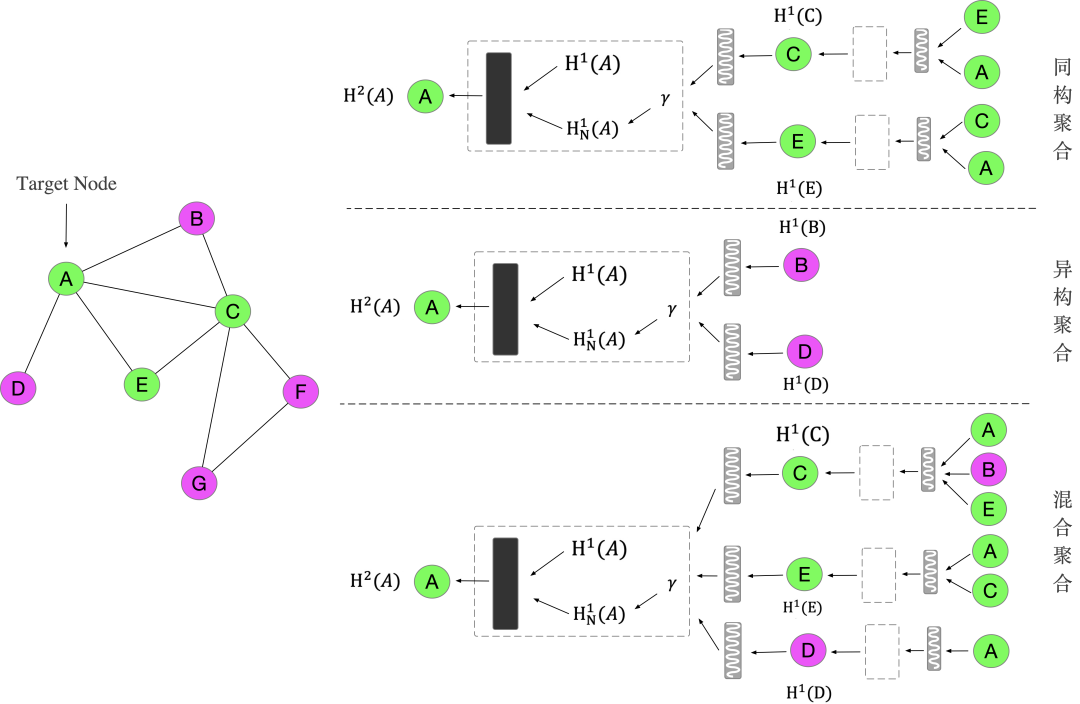
特征聚合
在图结点特征聚合上本文采用pooling聚合,先对每个邻居结点上一层embedding进行非线性转换,再按维度应用 max/mean pooling,捕获邻居集上的显著特征以此表示目标结点embedding。具体pipeline如下:

在特征聚合策略上,考虑跨模态检索的目的是实现不同模态数据在高维空间的语义对齐,消除数据模态差异的存在,因此本文根据聚合邻结点的类型,尝试采用实验了三种不同的聚合策略:
- 同构聚合,目标结点只聚合同模态的邻结点
- 异构聚合,目标结点只聚合不同模态的邻结点
- 混合聚合,目标结点随机聚合邻结点
在第四小节的实验对比可以看出同构聚合策略性能最佳。
▐度量学习
-
正负样本设置
跨模态训练任务的视频-文本异构正样本通过异构边直接获取,异构负样本的选择采用自适应五元组损失AOQ Loss[16]采用Batch内在线难样本挖掘Online Hard Sample和离线难样本挖掘Offline Hard Sample选择在线局部负样本和离线全局负样本。
单模态训练任务的视频-视频、文本-文本的同构正样本分别来自同构边的一跳和二跳游走采样邻结点,负样本在全图进行随机采样。
-
目标优化函数
本文设计的损失函数包括两部分:
- 同模态度量损失和有无边二分类损失。同模态度量损失是距离约束,保证在高维度量空间拉近正样本距离,拉远负样本对距离;有无边二分类损失本质是根据图的结构构建正负样本的相关性约束。
- 跨模态自适应五元组度量损失。在线难样本挖掘有两个主要不足:
- 负样本选择策略具有局部性、“难度"不足;
- 对于正样本对和负样本对的惩罚力度一致,不同难度的样本对应有不同的优化更新力度。
本文采用自适应五元组损失损失,自适应调整正样本对、在线负样本对、离线负样本对的更新权重,达到在相似度方面正样本对>在线负样本对>离线负样本对的目的。
损失公式表达:
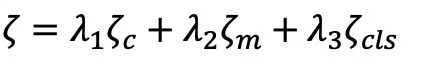
同模态度量损失:
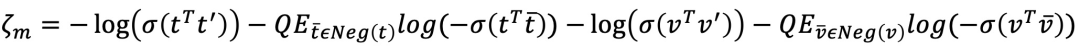
同模态有无边二分类损失:
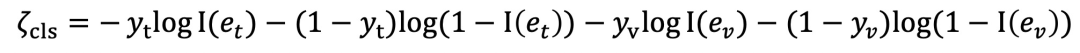
跨模态度量损失:
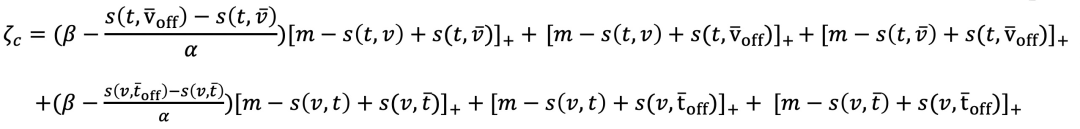
其中
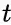 表示文本768维特征向量,
表示文本768维特征向量,
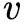 表示视频768维特征向量,
表示视频768维特征向量,
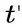 表示文本正样本,
表示文本正样本,
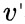 表示视频正样本,
表示视频正样本,
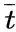 表示文本局部负样本,
表示文本局部负样本,
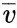 表示视频局部负样本,
表示视频局部负样本,
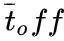 表示文本全局负样本,
表示文本全局负样本,
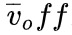 表示视频全局负样本,
表示视频全局负样本,
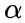 、为超参数,
、为超参数,
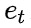 表示文本同构边,
表示文本同构边,
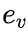 表示文本同构边,
表示文本同构边,
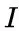 表示指示函数,
表示指示函数,
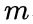 表示距离间隔,
表示距离间隔,
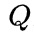 表示负样本数量。
表示负样本数量。
-
训练细节
整个检索模型以端到端的方式进行训练,训练分两轮。第一轮次训练跨模态部分度量学习仅采用在线难挖掘损失,训练优化过程进行学习率warm up。早期训练容易出现模型崩塌现象,hard triplet loss促使各样本点映射到同一个点,loss收敛到margin。为解决该问题FaceNet采用semi-hard triplet loss可以使模型训练更加稳定、收敛更快,但达不到hard triplet loss的更优解。本文选择在学习率warm up期间采用负样本在线随机采样,模型训练稳定之后采用在线难样本挖掘训练直到收敛。第一轮次训练完成之后,训练样本进行全局语义检索寻找全局难负样本,构建五元组进行第二轮次训练。
在原始训练数据的基础上,本文尝试进一步采用半监督学习的方式进行训练数据的扩量,训练完成的模型在万象城视频库召回更多的伪匹配样本,训练数据的扩量带来更大的性能提升。
实验
▐度量学习
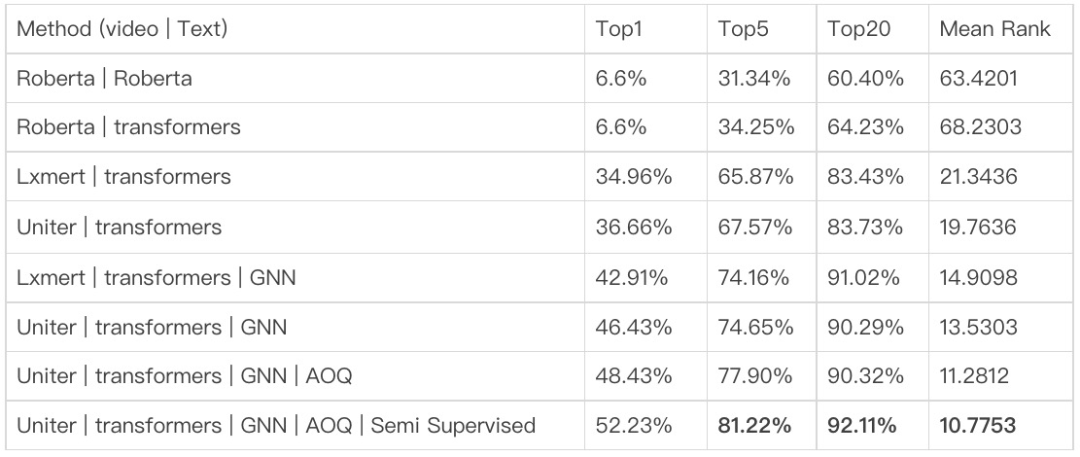
检索衡量指标采用检索召回准确率Top1,Top5,Top20 以及Mean Rank值。1K淘宝样本对检索性能如下。基于预训练Roberta文本特征的视频文本-标签文本检索方式与基于多模态特征的视频多模态-标签文本的检索方式性能有明显差距,视频多模态信息的互补增益更好地实现淘宝视频内容理解。视频多模态-标签文本的检索方式在引入图神经网络算法后在Top1准确率上有超过9.0%的性能提升,图结构信息的引入进一步提升了视频和文本结点的语义表征能力。模型在度量学习上结合离线全局负样本采样和在线局部负样本采样的方式在Top1准确率上提升2.0%,采样不同难度的负样本使模型收敛到更优点。本文尝试通过半监督的方式扩量训练集召回更多伪匹配样本,对模型性能有更佳的增益。
▐公开数据集实验
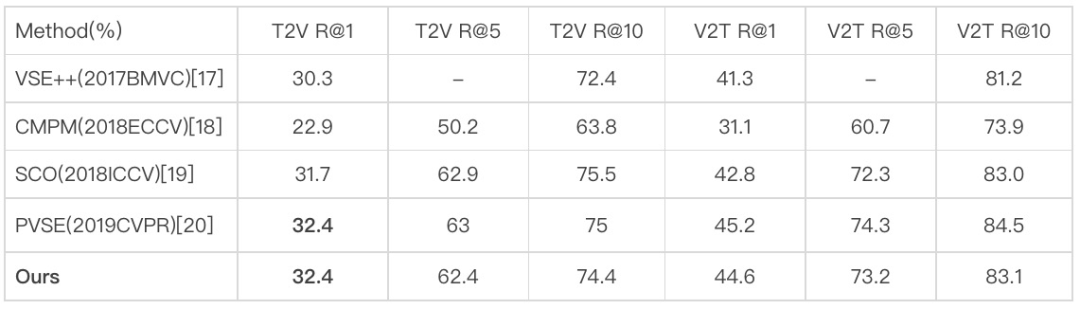
本文算法应用于MSCOCO Retrieval数据集做性能测试。MSCOCO Retrieval数据集的5K检索任务性能结果对比如下,其中对比方法主要限定采用双塔模型结构、特征提取无需模态间交互对齐计算、适用于大规模检索的方法。本文工作达到了于同期前沿工作具有竞争力的性能。
▐消融对比及可视化
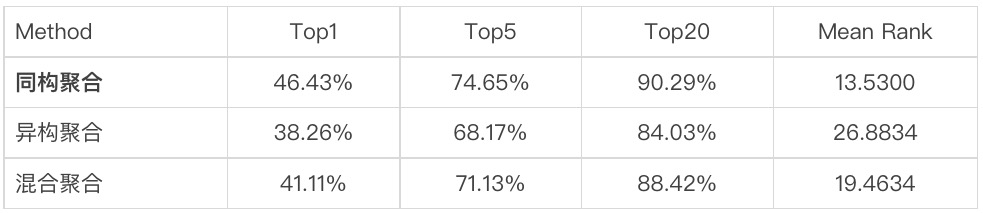
- 聚合策略
图结点表示的三种不同的聚合策略性能结果对比如表所示,本小节实验结果在模型[Uniter | transformers | GNN]实现,检索衡量指标同样采用检索召回准确率Top1,Top5,Top20 以及Mean Rank值。
异构聚合策略比同构聚合策略在Top1准确率跌落几个百分点,存在的原因有:
- 图网络构建准确率还不够高,采样的异构结点与目标结点存在语义不配现象;
- 不同模态数据在聚合过程中非线性变换处理没有根据模态差异设置不同的优化参数,目前采用的聚合过程的线性层采用共享参数。
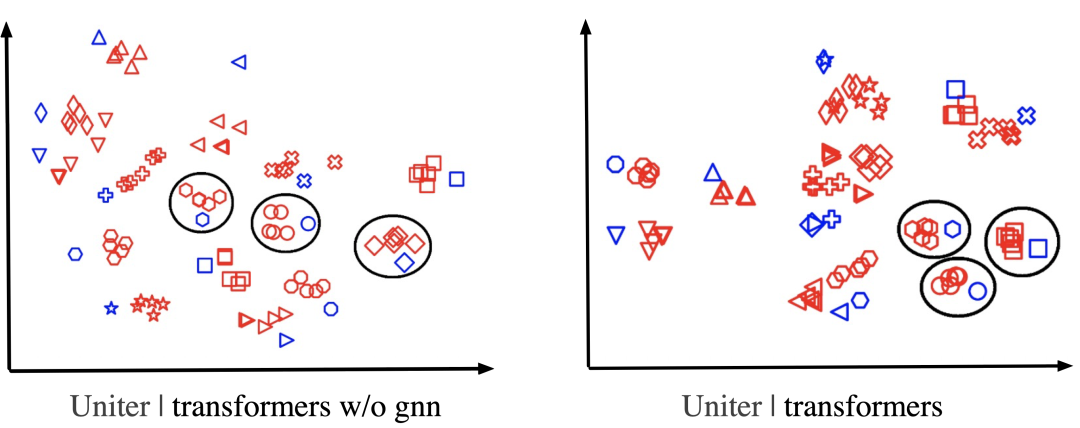
- 样本可视化
本文抽取部分测试样本,模型提取文本特征和视频特征并进行进行T-SNE处理可视化,如下图所示,其中蓝色表示文本样本,红色表示视频样本,可以看出同内容语义的文本视频来高维空间得到很好的聚类效应,并且同其他不同内容语义的样本保持一定间隔距离。GNN的引入使得同模态正样本之间的距离更加拉近。
- 主题标签召回示
主题标签在千万级首猜精品视频池进行向量检索,手淘全屏页[3]主题标签召回示例case:

讨论和展望
本文对淘宝内容场景下的文本视频跨模态检索问题进行了研究和讨论,指出跨模态检索当前存在的训练样本稀疏均衡问题、跨模态度量学习的技术挑战和高效检索问题,并对此做出了深入分析,提出了结合GraphSAGE图网络算法的双塔跨模态检索模型,分别对同模态和跨模态进行多目标学习,保证同模态判别性的同时,实现跨模态特征的对齐,线下实验验证和业务评测验证了本文算法有效性。本文对文本-视频跨模态检索技术的研究主要通过文本和视频全局特征构建双塔度量模型,后续会继续深耕:
- 探索文本-视频的特征细粒度对齐,解构视频多模态特征,实现不同模态特征与文本的解耦对齐。
- 探索文本-视频特征度量学习,实现精度更细的局部度量。
参考文献
[1] 让机器读懂视频,淘宝短视频超大规模标签理解
[2] 短视频全屏页的认知理解和运用
[3] 多模态内容的表达学习及应用
[4] 多模态表征学习在短视频推荐场景上的应用探索
[5] PAI-EasyMM: 通用多模态学习框架
[6] 多模态学习在夸克图搜中的应用
[7] 跨模态检索初探-躺平搜索首图挑选
[8] 基于多模语义相关�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%98%E7%B3%BB%E6%8A%80%E6%9C%AF%E6%B7%98%E5%AE%9D%E8%A7%86%E9%A2%91%E7%9A%84%E8%B7%A8%E6%A8%A1%E6%80%81%E6%A3%80%E7%B4%A2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


