深度学习在腾讯广告推荐系统中的实践

分享嘉宾:郭跃超 腾讯 应用研究员
编辑整理:康德芬
出品平台:DataFunTalk
导读: Angel是腾讯自研的分布式高性能的机器学习平台,支持机器学习、深度学习、图计算以及联邦学习等场景。Angel的深度学习平台已应用在腾讯的很多个场景中。所以今天会为大家介绍Angel:深度学习在腾讯广告推荐系统中的应用实践,介绍的内容会围绕着下面几点展开。
- Angel机器学习平台
- 广告推荐系统与模型
- 模型训练和优化
- 优化效果
01 Angel机器学习平台
1. Angel机器学习平台架构
Angel机器学习平台是腾讯自研的基于传统Parameter Server架构的高性能分布式的机器学习平台如图1所示,详细架构图如图2所示。它是一个全栈机器学习平台,支持特征工程、模型训练、模型服务、参数调优等,同时支持机器学习、深度学习、图计算和联邦学习等场景。已经应用在众多业务如腾讯内部广告、金融和社交等场景,吸引了包括华为、新浪、小米等100多家外部公司的用户和开发者。
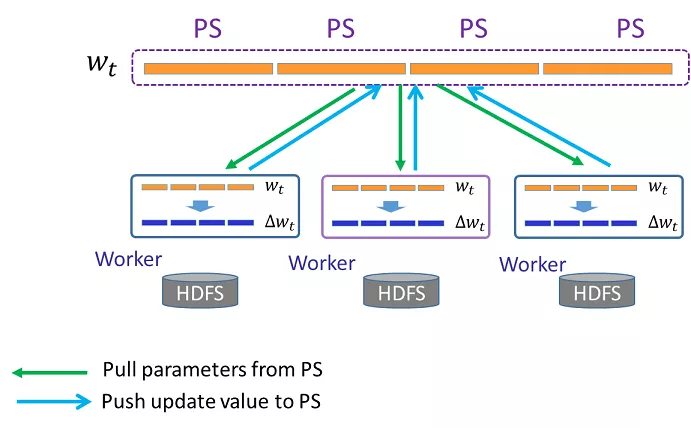
Fig1 Angel机器学习平台
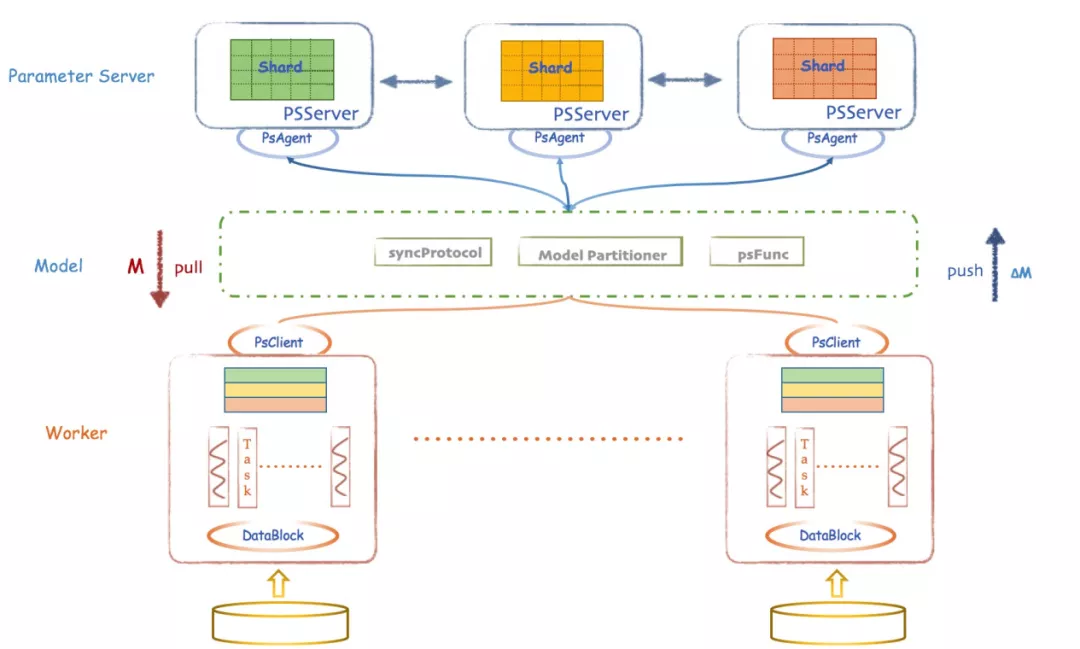
Fig2 Angel机器学习平台架构图
Angel机器学习平台设计时就考虑到了很多问题,首先是易用性,Angel机器学习平台编程接口简单,可快速上手使用,支持训练数据和模型的自动化切分,减少用户的干预,简单易用。然后是可扩展性方面,Angel提供了PsFun接口,继承特定的类可实现自定义参数更新逻辑和自定义数据格式和模型切分方式等。之后是灵活性,Angel实现了ANGEL_PS_WORKER和ANGEL_PS_SERVICE两种模式,ANGEL_PS_WORKER模式下模型的训练和推理服务由Angel平台自身的PS和Worker完成,这种模式主打速度。而ANGEL_PS_SERVICE模式下,Angel只启动Master和PS,具体的计算交给其他计算平台(如Spark,TensorFlow)负责,Angel只负责提供Parameter Server的功能,主打生态来扩展Angel机器学习平台的生态位。Angel通信模式支持BSP、SSP、ASP等通信协议,满足各种复杂的实际通信环境的要求。最后是稳定性,Angel的PS容错采用CheckPoint模式,Angel每隔一段时间会将PS承载的参数写入到分布式存储系统中,如果某个PS实例挂掉,PS会读取最后一个CheckPoint重新进行服务。Angel的Worker容错方面,如果Work挂掉,Master会重新启动一个Work实例,该实例会从Master上获取挂掉时参数迭代信息。Angel的Master任务信息也会定期存储到分布式存储系统中,如果Mater挂掉,会借助Yarn Master重启机制重新拉起一个Master并加载信息从之前的断点开始任务。Angel还有有慢work检测机制,如果某个Work运行过慢其任务会被调度到其他的Work上进行。
Angel机器学习平台任务提交执行简单,具体步骤如图3所示,进入Cient后,启动一个PS实例,该PS会从Client端加载模型,之后Client会启动多个Work,Work会加载训练数据开始训练和学习,push和pull会进行参数的拉取和更新,训练完成后将模型存入指定的路径。
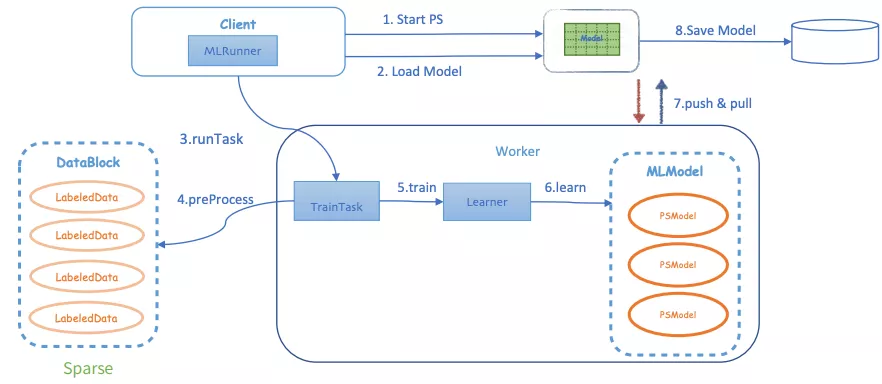
Fig3 Angel机器学习平台提交执行流程图
Angel机器学习平台在代码结构设计上做了很多的抽象,这样的设计方式可扩展性强,整个结构主要分为四层如图4所示。核心层(Angel-Core)是基础层,主要包括PSAgent、PSServer、Work、Network和Storage等。机器学习层(Angel-ML)提供基础数据类型和方法,同时用户可根据PsFunc定义自己的方法把私有模型接入。接口层(Angel-Client)可插拔式扩展,支持多种用途比如接入TensorFlow和pyTorch等。算法层(Angel-MLLib)提供了封装好的算法如GBDT、SVM等。
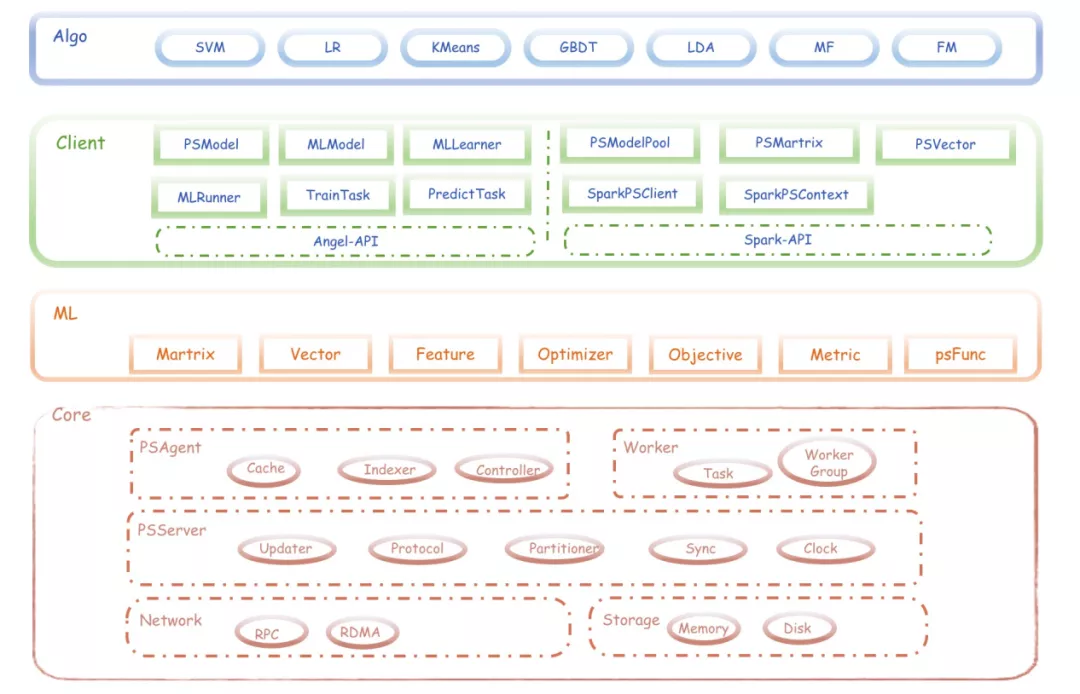
Fig4 Angel机器学习的代码结构
2. Angel机器学习平台在深度学习方向上的拓展和应用
深度学习常用的分布式计算范式有两种,分别是MPI ( 基于消息模型的通信模式 ) 和Parameter Server,如图5所示。这两种范式均在Angel平台上有实现,对于Parameter Server范式的实现如图6所示,Angel Work可通过Native C++的API接口接入常用的深度学习的OP如PyTorch或者Tensorflow等,在训练的起始端Angel PS会把模型Push到每个Worker上,Worker会加载到对应的OP上进行训练,每次训练完成后会将梯度信息回传到PS上进行融合,以及应用优化器得到更新的参数,完成后又会分发到每个Worker上,重复上述过程直到训练结束,最终将模型保存到指定路径。这种方案Angel PS提供了一个梯度PS的控制器,来接入多个分布式的Worker,每个Worker上可以运行一些通用的深度学习框架例,这种方案PyTorch版本的工作我们已经完成,并已经开源了(PyTorch on Angel)。另外一种是MPI AllReduce范式如图7所示,这种范式梯度信息是通过AllReduce方法进行融合的,在这种范式的实现上,Angel PS是一个进程控制器,会在每个Work上拉起一个进程,这个进程可以是PyTorch或者是Tensorflow等进程,这种范式对用户侵入少,用户开发的算法不需要太多的修改即可接入到Angel平台进行训练。
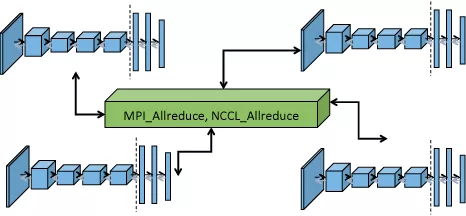
MPI范式
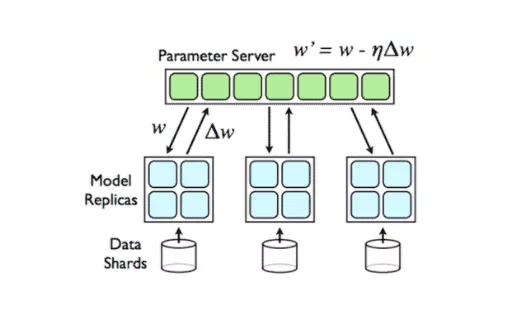
Parmeter Server范式
Fig5 深度学习领域分布式计算常用的两种范式
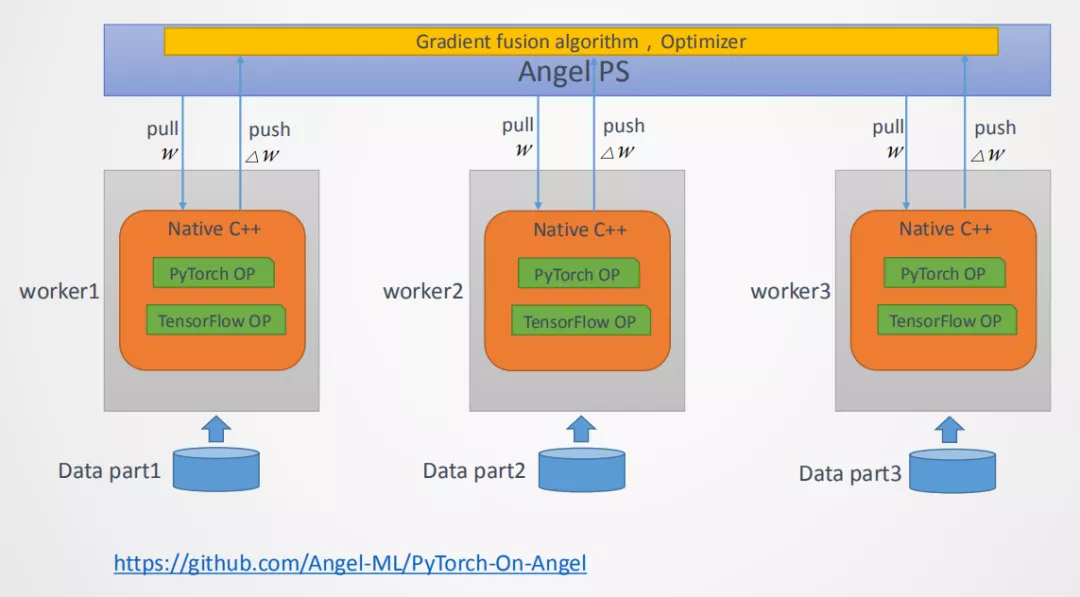
Fig6 Parameter Server范式在Angel上的实现
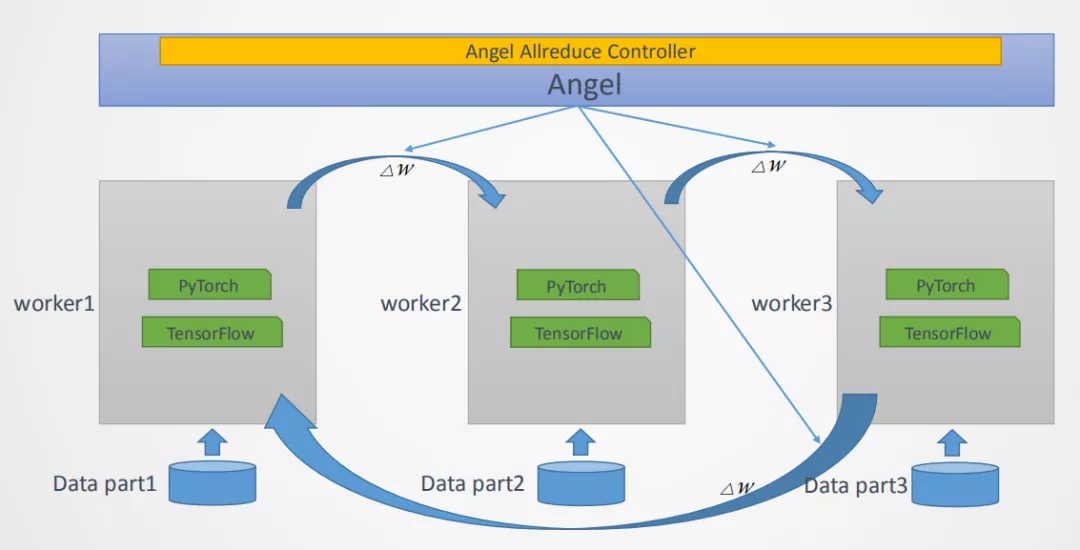
Fig7 Allreduce范式在Angel上的实现
02 广告推荐系统与模型
1. 腾讯的广告推荐系统
腾讯大数据示意图,如图8所示,在线业务的数据如微信游戏等会通过消息中间件实时地传递到中台系统,中台系统包括实时计算、离线计算、调度系统和分布式存储,这些数据有的会进行实时计算有的会进行离线计算,数据的应用也是从消息中间件中获取其需要的数据。
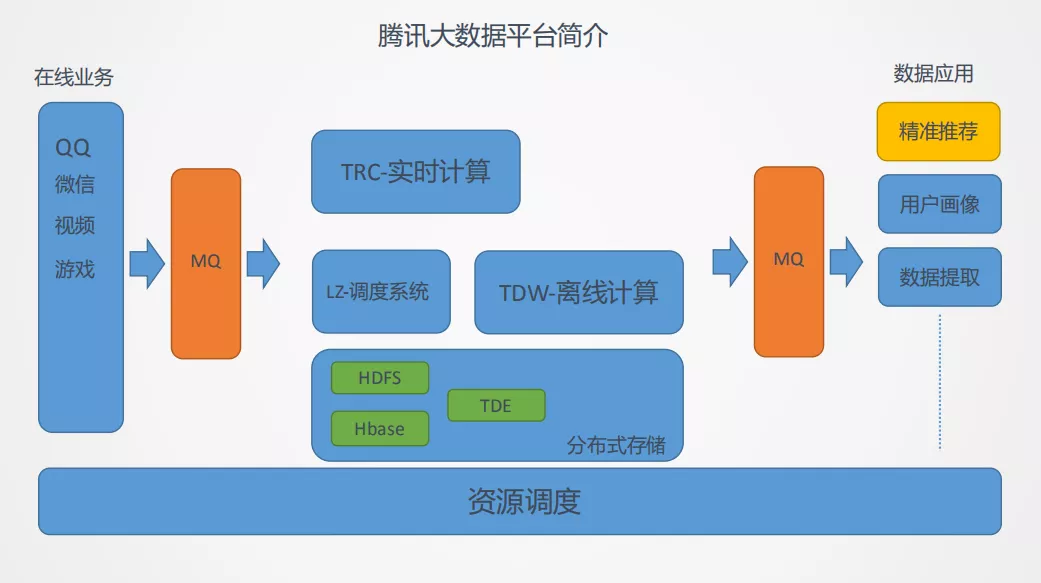
Fig8 腾讯大数据平台
腾讯的推荐广告推荐系统业务分层如图9所示,用户发送一个请求后会去拉取用户地画像特征,之后会对广告库的广告进行一个初步地排序和打分,打分之后会提取用户地特征信息,同时将广告库的ID数量降为百级别,在这个百级范围内会有一个精细的排序,完成后将广告推送给用户。整个推荐系统面临着下面的几大挑战,首先是数据来源多样化,数据既有线上数据也有历史落盘数据。其次是数据的格式多元化,包括用户信息、Item信息、点击率和图像等数据的多元格式。然后是增量数据多,用户请求频繁,广告库也在不断更新中。最后是训练任务多元化,整个推荐系统涉及到粗排、精排、图像检测和OCR等任务。为了解决上述问题,我们在精准排序任务上开发了一整套的软件框架"智凌"(基于TensorFlow)来满足训练需求。
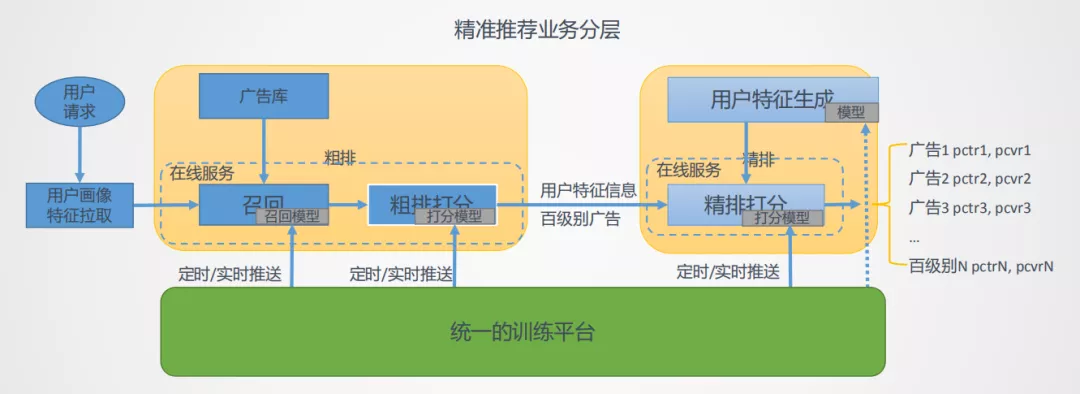
Fig9 腾讯广告推荐系统
“智凌"框架结构如图10所示,该框架最底层C++ core封装了MQ receiver和深度学习框架的一些OP类,最典型的是TensorFlow的dataset类,通过封装tensorflow的dataset类来提供从MQ获取数据的能力。数据抽象和处理在C++和Python上完成。然后是深度学习的framework(tensorflow)层提供各种深度学习的库。最后是具体的应用模型如DSSM、VLAD和一些图像算法的模型等。“智凌"软件框架具有算法封装完整、开发新模型较快、数据和算法隔离解耦较好、预处理逻辑方便修改和更新及兼容性好等优点,但同时对于Tensorflow框架侵入性修改多、单机多卡性能差、多机分布式不支持、算法和OP层面优化不够完全等缺点。图11是"智凌"在基础数据上的训练流程图,从图中看到从消息中间件中读取数据到本地的DataQueue中,DataQueue给每个在GPU节点上的模型分发Batch数据然后进行训练,训练完成后读取到CPU进行梯度融合和备份然后分发给各个GPU进行再训练,这种设计是面向单机结构的设计,CPU去实现梯度的融合和优化器的功能,CPU资源消耗大,这种设计很不合理,针对这种情况我们做了很多的优化后面会向大家介绍。
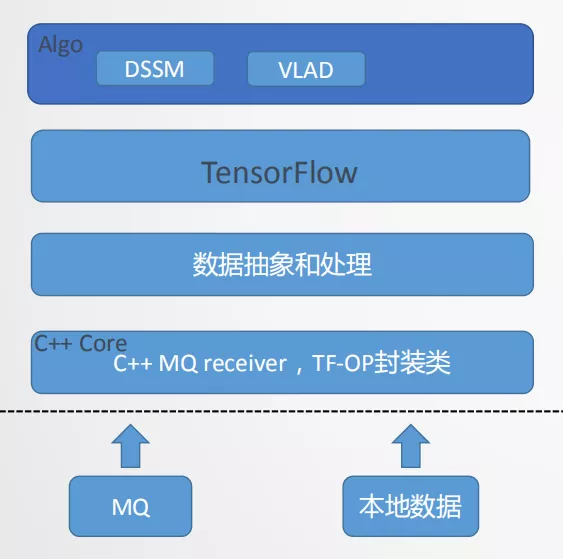
Fig10 “智凌"框架结构
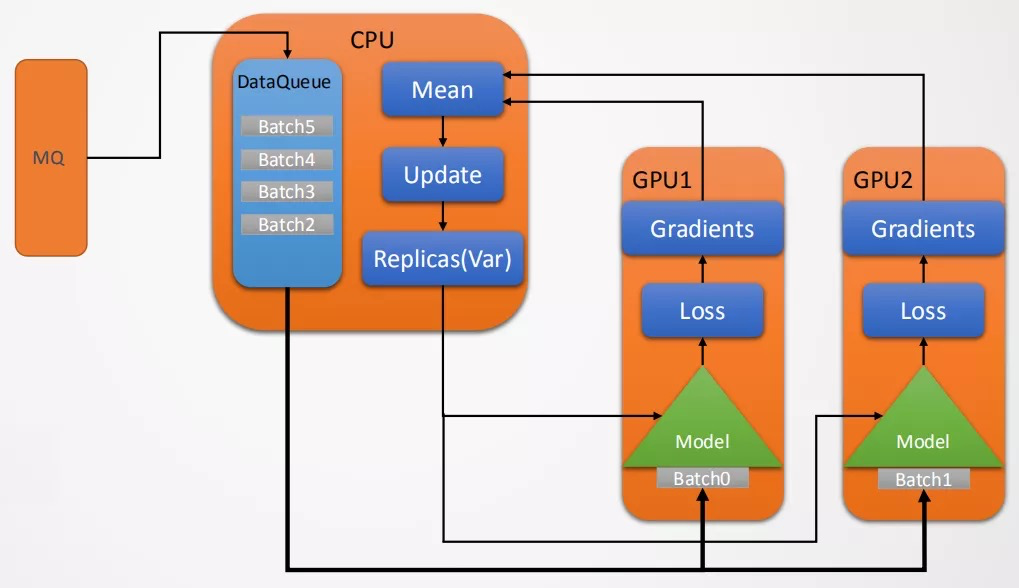
Fig11 “智凌"在基础数据上的训练流程图
2. 腾讯的广告推荐系统中的模型
DSSM增强语义模型如图12,在这里我们用该模型来计算用户和推荐ID之间的相关性并在此基础上计算用户对给定推荐ID的点击率,相关性和点击率计算公式分别是:
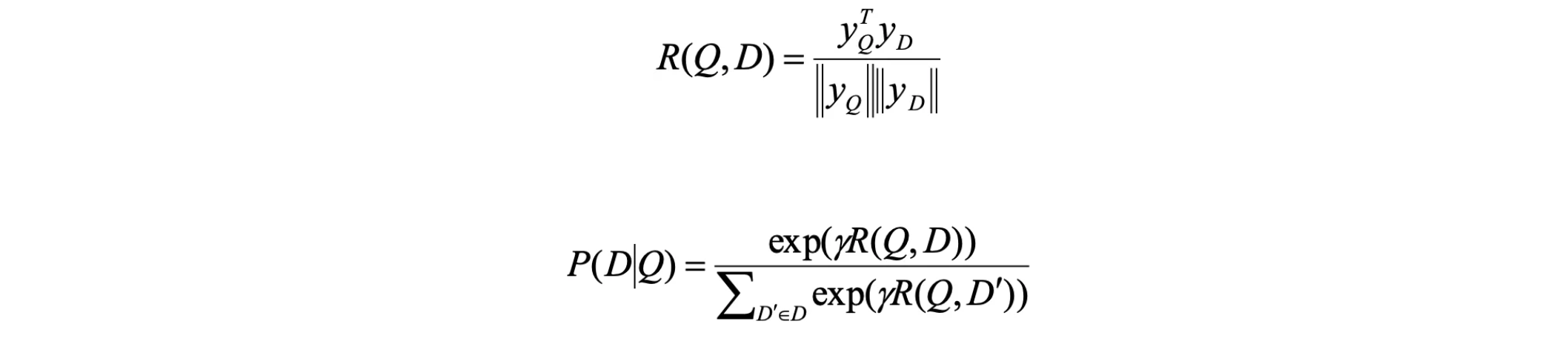
DSSM模型较为简单,分为Quey Id和Item Id并表达为低维语义向量,然后通过余弦距离来计算两个语义向量之间的距离。通过模型计算Query和Item之间的相关性,打分最高点就是我们要推荐的Item, 广告推荐系统中的DSSM模型要支持以下一些新的需求点:
- ID类特征维度亿级别;
- 变化快,每周有25%是新条目,支持增量训练。
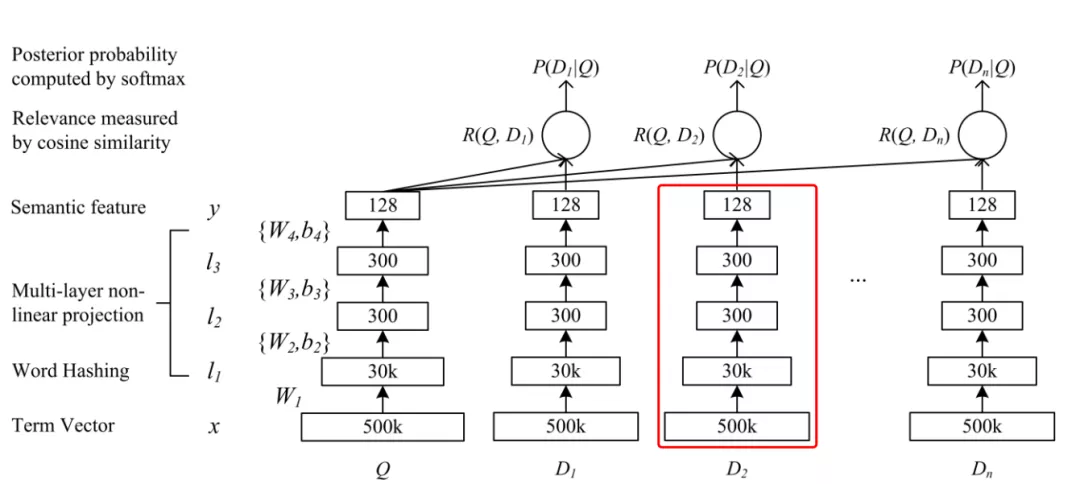
Fig12 DSSM模型
VLAD/NetVLAD/NeXtVLAD等模型我们主要用来判断两个广告之间的距离关系,传统的VLAD可以理解为一个聚类合并的模型,其向量计算公式为:
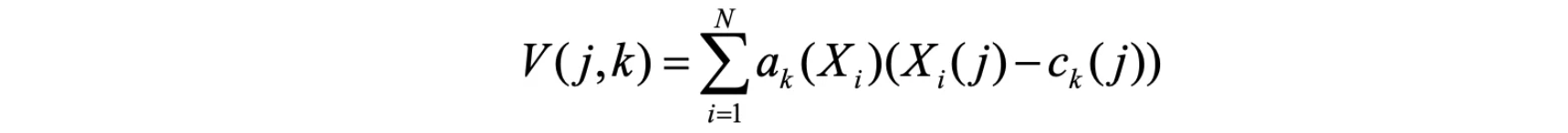
NeXtVLAD如图13则通过将ak符号函数变成一个可导函数来得到一个更好距离效果,NeXtVLAD的向量计算公式为:
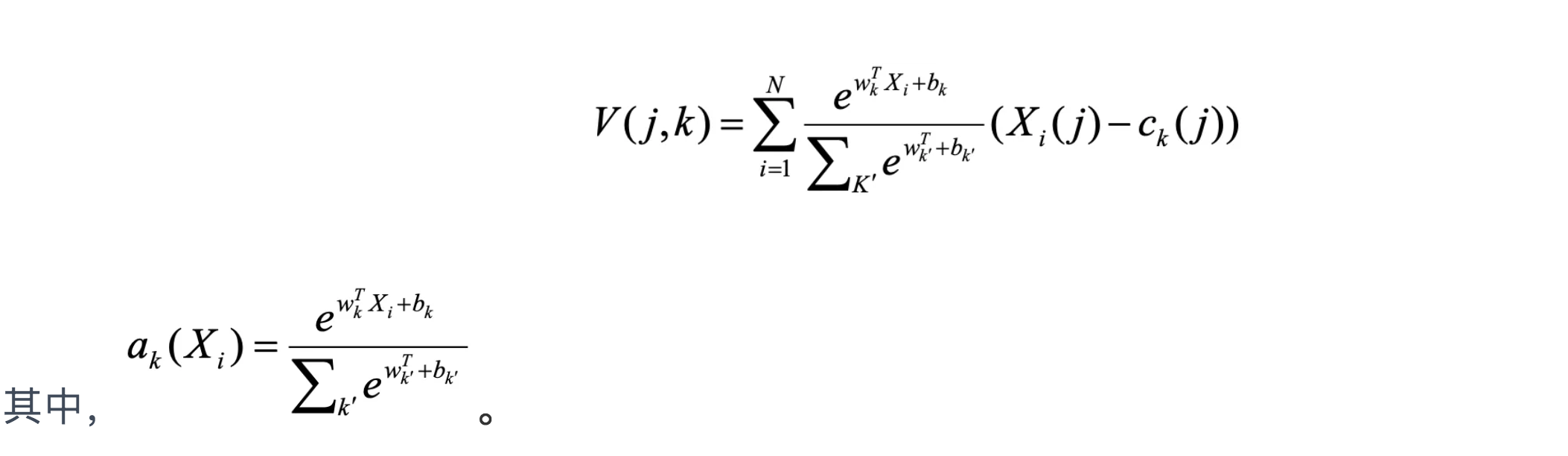
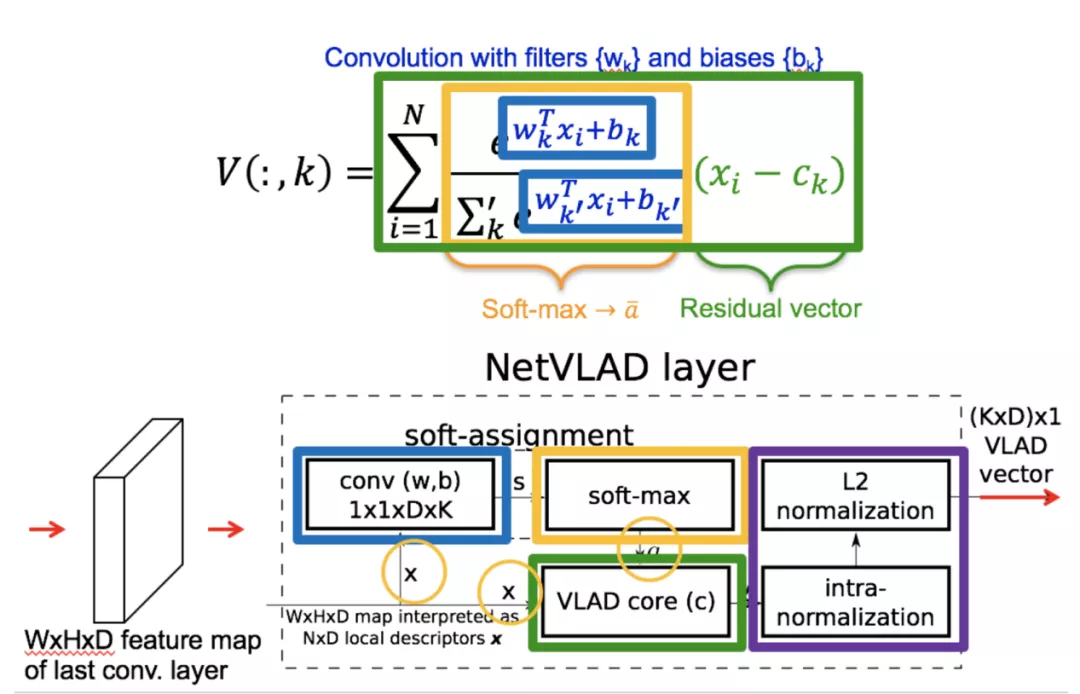
Fig13 NeXtVLAD模型
YOLO V3如图14是图像处理模型,在这里我们将其应用在OCR业务最前端做初检,它的特点是图片输入尺寸大(608 608,1024 1024),也因此YOLO模型的Loss部分占据比较大的计算。
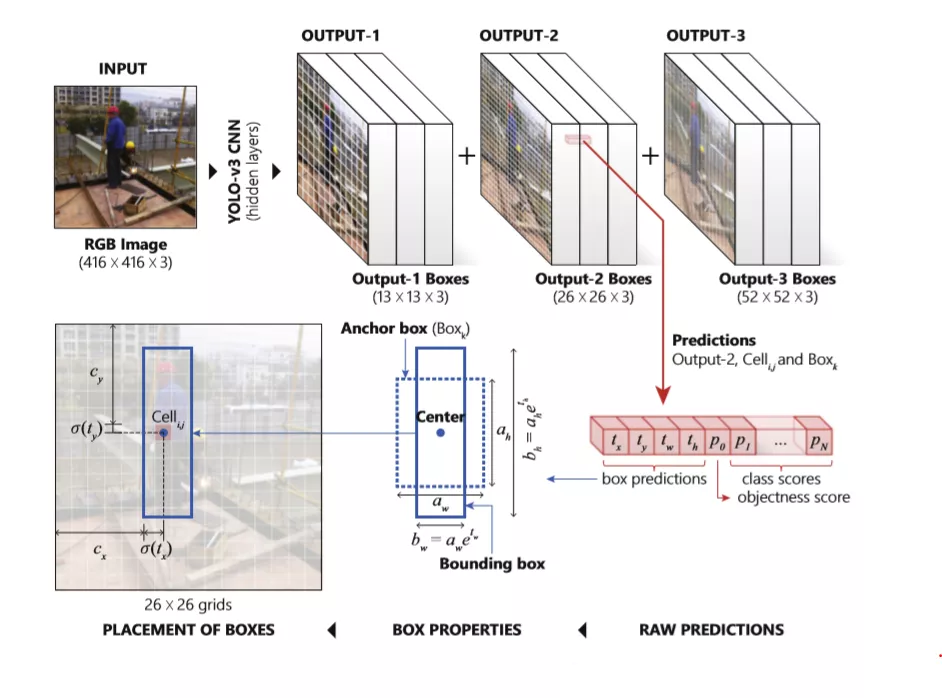
Fig14 YOLO V3模型
03 模型训练和优化
1. 数据流优化
前面的介绍中我们知道"智凌"软件框架是单管道数据流,现在我们将其优化为多管道如图15所示,即通过多机多数据流来解决单机IO瓶颈问题。原来的单管道数据中会有DataQueue,如果数据流很大会对IO造成很大的压力,优化为多对管道后为每一个训练进程GPU定义了一个DataQueue,通过这种分布式方法来有效解决IO瓶颈问题。这种情况下的管理工作是通过Angel PS(AllReduce版本)进程控制器来进行管理的。
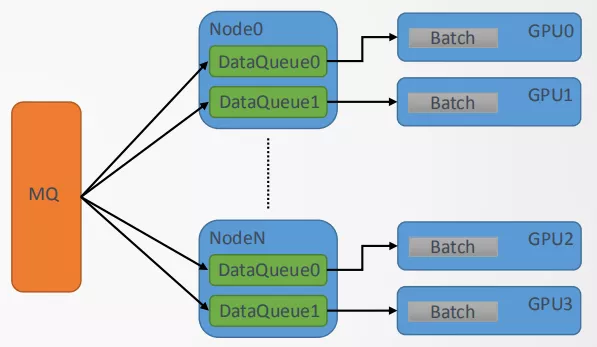
Fig15 “智凌"的多管道结构
2. Embedding计算优化
Embedding Lookup过程常会碰到如果在hash之前进行SparseFillEmptyRows操做会对空行填充默认值,增加过多的字符串操做,优化后我们先做hash操做然后再做SparseFillEmptyRows操做,去除耗时过多的字符串操作 ( 百万级别 ),节省CPU算力来提升QPS,此优化单卡性能约有6%的提升。
3. 模型算法层面优化
YOLO的Loss计算�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9C%A8%E8%85%BE%E8%AE%AF%E5%B9%BF%E5%91%8A%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


