深度学习推荐系统中各类流行的方法上
来源 Microstrong 扫描文末二维码关注作者
Embedding 方法概览:
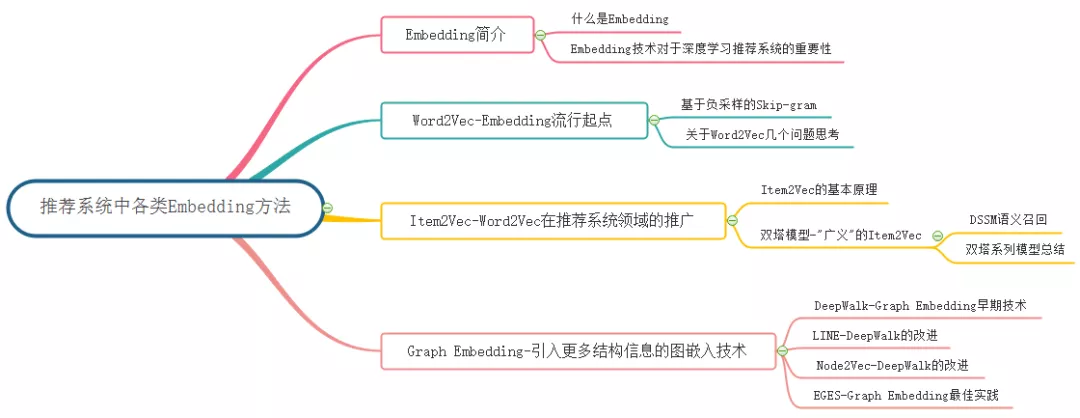
1. Embedding 简介
Embedding,中文直译为“嵌入”,常被翻译为“向量化”或者“向量映射”。在整个深度学习框架中都是十分重要的“基本操作”,不论是 NLP(Natural Language Processing,自然语言处理)、搜索排序,还是推荐系统,或是 CTR(Click-Through-Rate)模型,Embedding 都扮演着重要的角色。
1.1 什么是 Embedding
形式上讲,Embedding 就是用一个低维稠密的向量“表示”一个对象,这里所说的对象可以是一个词(Word2Vec),也可以是一个物品(Item2Vec),亦或是网络关系中的节点(Graph Embedding)。其中“表示”这个词意味着 Embedding 向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性。
1.2 Embedding 技术对于深度学习推荐系统的重要性
在深度学习推荐系统中,为什么说 Embedding 技术对于深度学习如此重要,甚至可以说是深度学习的“基本核心操作”呢?原因主要有以下四个:
(1)在深度学习网络中作为 Embedding 层,完成从高维稀疏特征向量到低维稠密特征向量的转换(比如 Wide&Deep、DIN 等模型)。 推荐场景中大量使用 One-hot 编码对类别、Id 型特征进行编码,导致样本特征向量极度稀疏,而深度学习的结构特点使其不利于稀疏特征向量的处理,因此几乎所有的深度学习推荐模型都会由 Embedding 层负责将高维稀疏特征向量转换成稠密低维特征向量。因此,掌握各类 Embedding 技术是构建深度学习推荐模型的基础性操作。
(2)作为预训练的 Embedding 特征向量,与其他特征向量连接后,一同输入深度学习网络进行训练(比如 FNN 模型)。 Embedding 本身就是极其重要的特征向量。相比 MF 等传统方法产生的特征向量,Embedding 的表达能力更强,特别是 Graph Embedding 技术被提出后,Embedding 几乎可以引入任何信息进行编码,使其本身就包含大量有价值的信息。在此基础上,Embedding 向量往往会与其他推荐系统特征连接后一同输入后续深度学习网络进行训练。
(3)通过计算用户和物品的 Embedding 相似度,Embedding 可以直接作为推荐系统的召回层或者召回策略之一(比如 YouTube 推荐模型等)。 Embedding 对物品、用户相似度的计算是常用的推荐系统召回层技术。在局部敏感哈希(Locality-Sensitive Hashing)等快速最近邻搜索技术应用于推荐系统后,Embedding 更适用于对海量备选物品进行快速“筛选”,过滤出几百到几千量级的物品交由深度学习网络进行“精排”。
(4)通过计算用户和物品的 Embedding,将其作为实时特征输入到推荐或者搜索模型中(比如 Airbnb 的 Embedding 应用)。
2. Word2Vec-Embedding 流行起点
关于 Word2Vec 的入门文章请看我之前的一篇文章: 深度浅出 Word2Vec 原理解析,Microstrong,地址: https://mp.weixin.qq.com/s/zDneR1BU6xvt8cndEF4_Xw
2.1 基于负采样的 Skip-gram
这里我单独把基于负采样的 Skip-gram 模型再详细描述一次,是因为这个模型太重要了,稍后我们讲解的 Item2Vec 模型和 Airbnb 论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb 》提出的模型都借鉴了基于负采样的 Skip-gram 模型的思想。所以,我们务必要把基于负采样的 Skip-gram 模型理解透彻。
Skip-gram 模型是由 Mikolov 等人提出的。下图展示了 Skip-gram 模型的过程。该模型可以看做是 CBOW 模型的逆过程,CBOW 模型的目标单词在该模型中作为输入,上下文则作为输出。
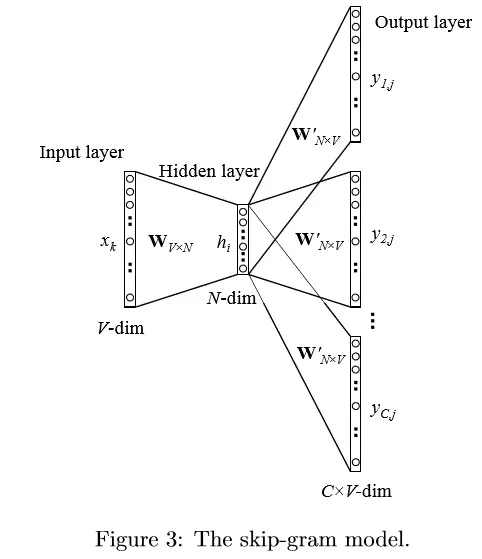
我们使用 v_{wi} 来表示输入层中唯一单词(也叫中心词)的输入向量,所以这样的话,对隐藏层 h 的定义意味着 h 仅仅只是简单拷贝了输入层到隐藏层的权重矩阵 W 中跟输入单词 W_I相关的那一行。拷贝公式得到:
h = W^{T}_{(k,\cdot)} :=V^{T}_{w_{I}}
在输出层,我们输出 C 个多项式分布来替代仅输出一个多项式分布。每个输出是由同一个隐藏层到输出层矩阵计算得出的:
p(w_{c,j} = w_{O,c}|w_{I}) = y_{c,j}=\frac{exp(u_{c,j})}{\sum_{j^{\prime} =1}^{V}{exp(u_{j^{\prime}})}}
这里w_{c,j}是第c个输出面上第j个单词;w_{O,c}是中心词对应的目标单词中的第c个单词;W_I 是中心词(唯一输入单词);y_{c,j}是第c个输出面上第j个单元的输出值;u_{c,j}是第c个输出面上的第j个单元的输入。因为输出面共享同一权重矩阵,所以有:
u_{c,j}=u_j=V^{‘T}_{w_j} *h, \quad for \quad c=1,2,…,C
V^{‘T}_{w_j}是词汇表第j个单词的输出向量,可由W’ 矩阵中的所对应的一列拷贝得到。
Skip-gram 的损失函数可以写为:
\begin{aligned} E &= -logp(w_{O,1},w_{O,2},…,w_{O,C}|w_{I}) \\ &= -log \prod_{c=1}^{C}\frac{exp(u_{c,j^{*}_{c}})}{\sum_{j^{\prime} =1}^{V}{exp(u_{j^{\prime}})}} \\ &= -\sum_{c=1}^{C}{u_{j^{*}_{c}} } + C \cdot log \sum_{j^{’} =1}^{V}{exp(u_{j^{’}})} \end{aligned}
由于语料库非常的大,直接计算中心词与词库中每个单词的 softmax 概率不现实。为了解决这个问题,Google 提出了两个方法,一个是 Hierarchical Softmax,另一个方法是 Negative Sampling。Negative Sampling 的思想本身源自于对 Noise Contrastive Estimation 的一个简化,具体的,把目标函数修正为:
log \sigma(v^{‘T}_{w_{o}} v_{w_{I}} )+\sum_{i=1}^{k}{E_{w_{i}\sim P_{n}(W) }[log\sigma(-v^{‘T}_{w_{i}}v_{w_{I}})]}
P_n(W) 是噪声分布 ( noise distribution )。即训练目标是使用 Logistic regression 区分出目标词和噪音词。另外,由于自然语言中很多高频词出现频率极高,但包含的信息量非常小(如’is’ ‘a’ ’the’)。为了平衡低频词和高频词,利用简单的概率丢弃词w_i :
P(w_{i})=1-\sqrt{\frac{t}{f(w_{i})}}
其中f(w_i)是 w_i的词频,t的确定比较 trick,启发式获得。实际中t大约在{10}^{-5} 附近。
推荐阅读 Airbnb 论文:
【1】Grbovic M, Cheng H. Real-time personalization using embeddings for search ranking at airbnb[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 311-320.
2.2 关于 Word2Vec 几个问题思考
熟悉了 Word2Vec 的基本原理后,我们来探究几个关于 Word2Vec 的经典面试题。
(1) Hierarchical Softmax 方法中哈夫曼树是如何初始化生成的?也就是哈夫曼树是如何构建的呢?
答:Hierarchical Softmax 依据词频构建 Huffman 树,词频大的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多。
(2)Hierarchical Softmax 对词频低的和词频高的单词有什么影响?为什么?
答:词频高的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多,在训练的过程中,低频词的路径上的参数能够得到更多的训练,所以 Hierarchical Softmax 对词频低的单词效果会更好。
(3)Hierarchical Softmax 方法中其实是做了一个二分类任务,写出它的目标函数?
答:L(\theta)=\sum^m_{i=1}y_ilogh_\theta(x_i) + (1-y_i)log(1-h_\theta(x_i)),其中 y_i 是真实标签,h_\theta(x_i)是模型预测的标签。
(4)Negative Sampling 是一种什么采样方式?是均匀采样还是其它采样方法?
答:词典 D 中的词在语料 C 中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小。这就是我们对采样过程的一个大致要求,本质上就是一个带权采样问题。
(5)详细介绍一下 Word2Vec 中负采样方法?
答:先将概率以累积概率分布的形式分布到一条线段上,以 a=0.2,b=0.3,c=0.5 为例, a所处线段为[0,0.2] ,b所处线段为 [0.2,0.5] , c 所处线段为 [0.5,1] ,然后定义一个大小为M 的数组,并把数组等距离划分为 m个单元,然后与上面的线段做一次映射,这样我们便知道了数组内的每个单元所对应的字符了,这种情况下算法的时间复杂度为O(1) ,空间复杂度为O(M) , m越小精度越大。
最后,我们来聊一聊 Word2Vec 对 Embedding 技术的奠基性意义。Word2Vec 是由谷歌于 2013 年正式提出的,其实它并不完全由谷歌原创,对词向量的研究可以追溯到 2003 年论文《a neural probabilistic language model》,甚至更早。但正是谷歌对 Word2Vec 的成功应用,让词向量的技术得以在业界迅速推广,使 Embedding 这一研究话题成为热点。毫不夸张地说,Word2Vec 对深度学习时代 Embedding 方向的研究具有奠基性的意义。
从另一个角度看,在 Word2Vec 的研究中提出的模型结构、目标函数、负采样方法及负采样中的目标函数,在后续的研究中被重复使用并被屡次优化。掌握 Word2Vec 中的每一个细节成了研究 Embedding 的基础。从这个意义上讲,熟练掌握本节内容非常重要。
3. Item2Vec-Word2Vec 在推荐领域的推广
在 Word2Vec 诞生之后,Embedding 的思想迅速从自然语言处理领域扩散到几乎所有机器学习领域,推荐系统也不例外。既然 Word2Vec 可以对词“序列”中的词进行 Embedding,那么对于用户购买“序列”中的一个商品,用户观看“序列”中的一个电影,也应该存在相应的 Embedding 方法,这就是 Item2Vec 方法的基本思想。
推荐阅读 Item2Vec 论文:
【1】Barkan O , Koenigstein N . Item2Vec: Neural Item Embedding for Collaborative Filtering[J]. 2016.
3.1 Item2Vec 的基本原理
由于 Word2Vec 的流行,越来越多的 Embedding 方法可以被直接用于物品 Embedding 向量的生成,而用户 Embedding 向量则更多通过行为历史中的物品 Embedding 平均或者聚类得到。利用用户向量和物品向量的相似性,可以直接在推荐系统的召回层快速得到候选集合,或在排序层直接用于最终推荐列表的排序。正是基于这样的技术背景,微软于 2016 年提出了计算物品 Embedding 向量的方法 Item2Vec。
微软将 Skip-gram with negative sampling(SGNS)应用在用户与物品的交互数据中,因此将该方法命名为 Item2Vec。相比 Word2Vec 利用“词序列”生成词 Embedding。Item2Vec 利用的“物品集合”是由特定用户的浏览、购买等行为产生的历史行为记录序列变成物品集合。通过从物品序列移动到集合,丢失了空间/时间信息,还无法对用户行为程度建模(喜欢和购买是不同程度的强行为)。好处是可以忽略用户和物品关系,即便获得的订单不包含用户信息,也可以生成物品集合。而论文的结论证明,在一些场景下序列信息的丢失是可忍受的。
Item2Vec 中把用户浏览的商品集合等价于 Word2Vec 中的 word 的序列,即句子(忽略了商品序列空间/时间信息)。出现在同一个集合的商品被视为 positive。对于用户历史行为物品集合w_1, w_2,…,w_K,Item2Vec 的优化目标函数为:
\frac{1}{K}\sum_{i=1}^{K}{\sum_{j=1}^{K}{logp(w_{j}|w_{i})}}
我们再来看一下,Skip-gram 是如何定义目标函数的。给定一个训练序列 w_1, w_2,…,w_T,模型的目标函数是最大化平均的 log 概率:
\frac{1}{T}\sum_{t=1}^{T}{\sum_{-c\leq j \leq c,j\ne 0}^{}{logp(w_{t+j}|w_{t})}}
通过观察上面两个式子会发现,Item2Vec 和 Word2Vec 唯一的不同在于,Item2Vec 丢弃了时间窗口的概念,认为序列中任意两个物品都相关,因此在 Item2Vec 的目标函数中可以看到,其是两两物品的对数概率的和,而不仅是时间窗口内物品的对数概率之和。
在优化目标定义好后,Item2Vec 训练和优化过程同 Word2Vec 一样,利用负采样,最终得到每个商品的 Embedding representation。利用商品的向量表征计算商品之间两两的 cosine 相似度即为商品的相似度。
3.2 双塔模型-“广义"的 Item2Vec
3.2.1 DSSM 语义召回
DSSM 模型是微软 2013 年发表的一个关于 query/doc 的相似度计算模型,后来发展成为一种所谓”双塔“的框架广泛应用于广告、推荐等领域的召回和排序问题中。我们自底向上来看下图所示的网络结构:
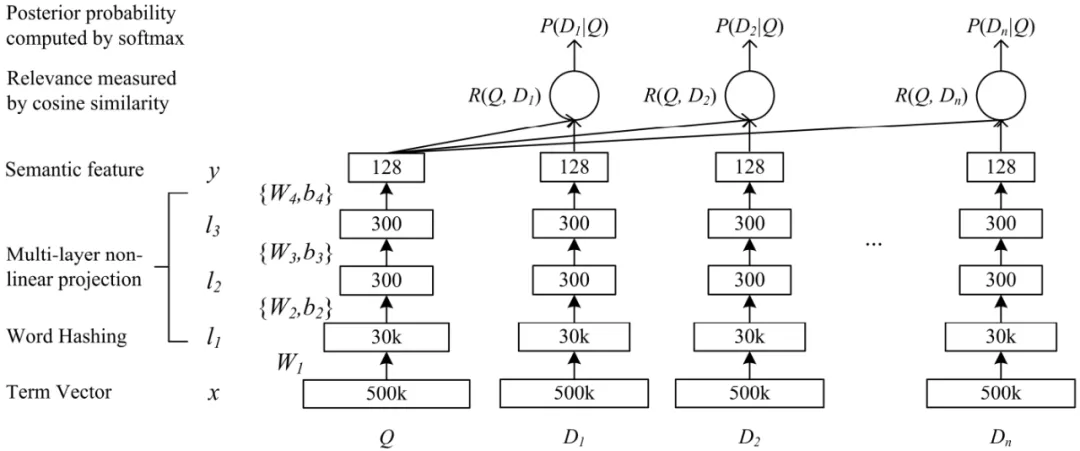
- 首先特征输入层将 Query 和 Doc(One-hot 编码)转化为 Embedding 向量,原论文针对英文输入还提出了一种 word hashing 的特殊 Embedding 方法用来降低字典规模。我们在针对中文 Embedding 时使用 Word2Vec 类常规操作即可;
- 经过 Embedding 之后的词向量,接下来是多层 DNN 网络映射得到针对 Query 和 Doc 的 128 维语义特征向量;
- 最后会使用 Query 和 Doc 向量进行余弦相似度计算得到相似度R,然后进行 softmax 归一化得到最终的指标后验概率P,训练目标针对点击的正样本拟合P为,否则拟合P为;
可以看到 DSSM 的核心思想就是将不同对象映射到统一的语义空间中,利用该空间中对象的距离计算相似度。这一思路被广泛应用到了广告、搜索以及推荐的召回和排序等各种工程实践中。
推荐阅读 DSSM 论文:
【1】Huang P S, He X, Gao J, et al. Learning deep structured semantic models for Web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.
3.2.2 双塔系列模型总结
事实上,Embedding 对物品进行向量化的方法远不止 Item2Vec。广义上讲,任何能够生成物品向量的方法都可以被称为 Item2Vec。典型的例子是曾在百度、Facebook 等公司成功应用的双塔模型,如下图所示。
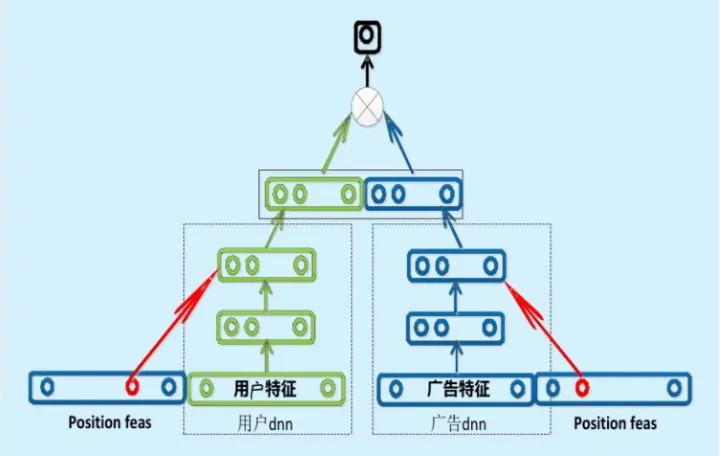
图:百度的“双塔”模型(来源于参考文献 11)
百度的双塔模型分别用复杂网络对“用户特征”和“广告特征”进行了 Embedding 化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。
在完成双塔模型的训练后,可以把最终的用户 Embedding 和广告 Embedding 存入内存数据库。而在线上 inference 时,也不用复现复杂网络,只需要实现最后一层的逻辑(即线上实现 LR 或浅层 NN 等轻量级模型拟合优化目标),再从内存数据库中取出用户 Embedding 和广告 Embedding 之后,通过简单计算即可得到最终的预估结果。
总之,在广告场景下的双塔模型中,广告侧的模型结构实现的其实就是对物品进行 Embedding 的过程。该模型被称为“双塔模型”,因此以下将广告侧的模型结构称为“物品塔”。那么,“物品塔”起到的作用本质上是接收物品相关的特征向量,经过“物品塔”内的多层�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E4%B8%AD%E5%90%84%E7%B1%BB%E6%B5%81%E8%A1%8C%E7%9A%84%E6%96%B9%E6%B3%95%E4%B8%8A/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


