用机器学习怎样鉴别不可描述的网站

前两天教师节,人工智能头条的某个精神股东粉群里,大家纷纷向当年为我们启蒙、给我们带来快乐的老师们表达感激之情。
很多人表示,他们的硬盘里,至今还保留着当时她们上课时候的视频。有一些现在网站上已经很难找到了,于是大家又纷纷开始互相交流跟随这些老师学习实践的心得体会。

👆禅师最喜欢的教师
后来禅师想起来,另一个人工智能头条的精神股东粉群 西部世界 里,有人提到过他写了一篇Chat,利用 NLP 来鉴别是普通网站和不可描述网站,还挺有点意思,一起来看看吧。

互联网中蕴含着海量的内容信息,基于这些信息的挖掘始终是诸多领域的研究热点。当然不同的领域需要的信息并不一致,有的研究需要的是文字信息,有的研究需要的是图片信息,有的研究需要的是音频信息,有的研究需要的是视频信息。

本文就是根据网页的文字信息来对网站进行分类。当然为了简化问题的复杂性,将以一个二分类问题为例,即如何鉴别一个网站是不可描述网站还是普通网站。你可能也注意 QQ 浏览器会提示用户访问的网站可能会包含色情信息,就可能用到类似的方法。本次的分享主要以英文网站的网站进行分析,主要是这类网站在国外的一些国家是合法的。其他语言的网站,方法类似。
一,哪些信息是网站关键的语料信息
搜索引擎改变了很多人的上网方式,以前如果你要上网,可能得记住很多的域名或者 IP。但是现在如果你想访问某个网站,首先想到的是通过搜索引擎进行关键字搜索。比如我想访问一个名为 村中少年 的博客,那么只要在搜索引擎输入 村中少年 这类关键词就可以了。图1是搜索 村中少年 博客时候的效果图:
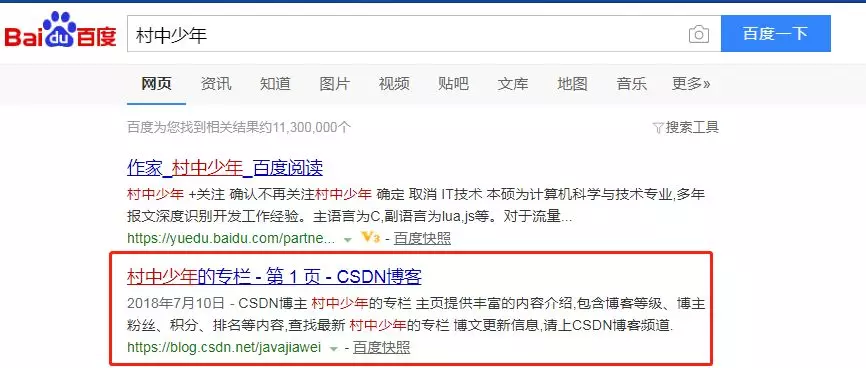
红色部分便是匹配上搜索关键词的部分,一个页面能够展示 10 个条目,每个条目的标题就是相应网站网站的的 title,对应网页的 `` 中间的内容,每个条目所对应的剩下文字部分便是网站的 description,是网页中诸如 ` 👆图2

👆图3
可以看到对于正常的网站来说 free,online,news,games,business,world,latest 是较为热门的词汇;对于不可描述网站来说,图中显示较大是对应较为热门的词汇。
有了一个个单词之后,需要将这些单词转化为一些模型能够接受的输入形式,也就是词向量。一种常见的方法就是构建一个 N * M 的矩阵,M 大小是所有文本中词的个数;N 的大小是所有文本个数,在本文的环境中就是 title,description 或者 keywords 的(即网站的)个数。
矩阵每一行的值,就是经过上述方法切词之后,词库中每一个词在该 title 上出现的频率,当然对于没有在该 title 出现的词(存在于其他 title 中)计为 0 即可。
可以预见,最终形成的是一个稀疏矩阵。Sklearn 也提供了一些方法,来进行文本到数值的转换,例如 CountVectorizer,TfidfVectorizer,HashingVectorizer。由前面的分析可知,title,description,keywords 是较为特殊的文本,会出现很多关键词的堆积,尤其对于不可描述网站,同时相应的预料数据有限,因此本文使用的是 CountVectorizer 来进行简单的词频统计即可,代码如下:
四,模型的训练识别以及比较;
有了第三个步骤的词向量的数值特征,接下来就是训练模型的选择了。对于文本分类问题来说,较为经典的就是朴素贝叶斯模型了。贝叶斯定理如下:
P(A|B) = P(B|A) P(A) / P(B)
表示的是 A 在 B 条件下的概率等于 B 在 A 条件下的概率乘以A出现概率除以 B 出现概率。对应到我们这个场景就是 B 是每一个 title 的特征,设 B=F1F2...Fn,即上述形成的稀疏矩阵的每一行,表示的是在该 title 中,词库中所有词在对应位置上出现的频率。
A={0,1},表示具体的类别,即是不可描述网站还是普通网站。因此上述公式可以表示为:

对于 P(Fn|C) 表示的某个类别下某个单词的概率(P(sex|0),表示不可描述网站集合中所有词中,sex 单词出现的概率),P(C) 表示某个类别的文本占比(p(0)表示不可描述网站数量占比),这些都是可以对文本进行统计得到的。而 P(F1F2…Fn) 是一个与类别无关的量,可以不与计算。因此可以看出最终是计算具有 F1F2…Fn 特征的文本属于不可描述网站(P(0|F1F2…Fn))和普通网站(P(1|F1F2…Fn))的概率,哪个概率大就归为那一类。当然关于朴素贝叶斯模型的原理,由于篇幅有限,就不过的阐述了。
由前面分析发现 title,description 以及 keywords 对于搜索引擎都是较为重要的信息,因此分别提取了网页的 title,description 以及 keywords,并单独测试每一份的语料数据。
如果直接使用 train_test_split 对所有语料进行切分,则有可能会使得正常语料和色情语料在训练和策测试数据中的比例不一致,为了保证结果的可靠性,使用 train_test_split 分别对于正常语料和色情语料按照 7:3 的比例进行切分。然后将每一分切分后的训练和测试数据进行合并,使用朴素贝叶斯模型对于数据进行预测,采用多项式模型,代码如下:

通过多次随机的按照 7:3 的比例切分正常语料和色情语料分别作为训练集和测试集发现,以
description(0.8921404682274248,0.9054515050167224,0.8979933110367893,0.9037792642140468,0.8904682274247492)
keywords(0.8912319644839067,0.8890122086570478,0.8901220865704772,0.8912319644839067,0.8856825749167592)
作为语料数据的时候,识别结果最好,都集中在 90% 左右。
而以 title(0.8081884464385867,0.8059450364554123,0.8132361189007291,0.8104318564217611,0.8093101514301738) 的效果最差,集中在 81% 左右。
分析原因发现,经过切词后,有不少的 title 为空,或者 title 只有很少单词的情况。形成的特征较弱,这种单词较少的情况是导致识别率不高的重要原因。例如 title 只有一个单词 video,由于该词在色情语料中属于高频词汇,在正常词汇中出现的频率也不低,因此只根据 title 就使得识别结果会随着语料的不同而不同。虽然对于搜索引擎来说,title 的权重大于 description,description 的权重大于 keywords。
但是对本文所述场景来说 description 的权重大于 keywords;keywords 的权重大于 title。也就是说当网页没有 description 时候,考虑使用 keywords 作为语料输入;当网页没有 description,keywords 时候,考虑使用 title 作为语料输入。
可以看到通将 4000+ 网站个作为训练的输入,以及 1700+ 网站作为测试。识别准确率稳定在 90% 左右,证明说明该方法是可行的,具有一定的应用价值。
当然在分析最终识别结果的过程中,还发现起始很多的色情语料被标记成了正常语料。原因在于,正常语料的来源是 alex 排名靠前的网站。在这其中是有部分的不可描述网站的。
同时相关的调查也发现不可�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%94%A8%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%80%8E%E6%A0%B7%E9%89%B4%E5%88%AB%E4%B8%8D%E5%8F%AF%E6%8F%8F%E8%BF%B0%E7%9A%84%E7%BD%91%E7%AB%99/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


