百度深度学习图像识别决赛代码分享
大赛官网: http://meizu.baiducloud.top/ps/web/index.html
初赛内容:从图片中识别四则运算式,算式可能包含数字0~9、运算符+-*、括号()。并且,算式的长度固定为5或7,包含三个数字,两个运算符,0或1对括号。下面是几个样例:

(4*8)+8

(0-2)+5

2*8-7
要求参赛者给出每张图片中的算式和运算结果。
训练集共100,000张图片,并附带标签。测试集共200,000张图片,无标签,预测结果上传后计算正确率,作为初赛的排名。
本文初赛、决赛代码 github 地址、初赛数据集获取方式:
关注微信公众号 datayx 然后回复 图像识别 即可获取。
问题描述
本次竞赛目的是为了解决一个 OCR 问题,通俗地讲就是实现图像到文字的转换过程。
数据集
初赛数据集一共包含10万张180*60的图片和一个labels.txt的文本文件。每张图片包含一个数学运算式,运算式包含:
3个运算数:3个0到9的整型数字; 2个运算符:可以是+、-、*,分别代表加法、减法、乘法 0或1对括号:括号可能是0对或者1对
图片的名称从0.png到99999.png,下面是一些样例图片(这里只取了一张):

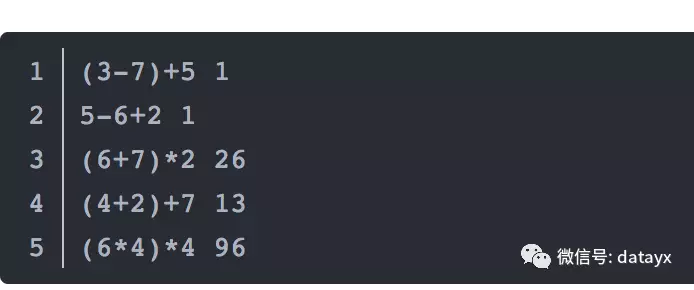
文本文件 labels.txt 包含10w行文本,每行文本包含每张图片对应的公式以及公式的计算结果,公式和计算结果之间空格分开,例如图片中的示例图片对应的文本如下所示:
评价指标
官方的评价指标是准确率,初赛只有整数的加减乘运算,所得的结果一定是整数,所以要求序列与运算结果都正确才会判定为正确。
我们本地除了会使用官方的准确率作为评估标准以外,还会使用 CTC loss 来评估模型。
使用 captcha 进行数据增强
官方提供了10万张图片,我们可以直接使用官方数据进行训练,也可以通过Captcha,参照官方训练集,随机生成更多数据,进而提高准确性。根据题目要求,label 必定是三个数字,两个运算符,一对或没有括号,根据括号规则,只有可能是没括号,左括号和右括号,因此很容易就可以写出数据生成器的代码。
生成器
生成器的生成规则很简单:

相信大家都能看懂。当然,我写文章的时候又想到一种更好的写法:

除了生成算式以外,还有一个值得注意的地方就是初赛所有的减号(也就是“-”)都是细的,但是我们直接用 captcha 库生成图像会得到粗的减号,所以我们修改了 image.py 中的代码,在 _draw_character 函数中我们增加了一句判断,如果是减号,我们就不进行 resize 操作,这样就能防止减号变粗:
if c != '-':
im = im.resize((w2, h2))
im = im.transform((w, h), Image.QUAD, data)
我们继而使用生成器生成四则运算验证码:


上图就是原版生成器生成的图,我们可以看到减号是很粗的。

上图是修改过的生成器,可以看到减号已经不粗了。
模型结构
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%99%BE%E5%BA%A6%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB%E5%86%B3%E8%B5%9B%E4%BB%A3%E7%A0%81%E5%88%86%E4%BA%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


