知识增强信息流推荐在保险行业的应用
作者:深度学习应用组 平安寿险PAI
全文框架概览
一、背景介绍
信息流推荐是当今互联网中AI能力的一个重要应用领域,相关的推荐技术也经历了从简单的协同过滤和关联规则、特征工程加集成学习、FM算法直到深度学习推荐系统的过程。
优秀的信息流推荐系统需要充分利用待推荐文章中的文本信息,通过表示学习算法将文本内容合理表征成语义特征,再结合用户的行为以及画像等来进行内容的推荐。
传统的文本表征方法是通过word2vec嵌入等方式将构成文章的字词转化为向量,再进一步结合神经网络等模型来提取篇章语义向量,但这个过程中外部的显示知识并没有被很好的融合进来。如果使用预训练语言模型的话,外部语料蕴含的知识信息在某种程度上会被引入,可是由于引入方式比较间接所以其可以利用的知识深度比较有限,因此需要寻找更加直接地融入知识到文本的技术手段。
知识图谱是当前整个NLP领域的热门方向之一,我们尝试通过将外部图谱知识结合预训练语言模型来优化文章语义向量的表征,从而提升信息流推荐的效果,并在平安寿险的新闻信息流平台进行了相关的实践,获得了不错的应用效果,有效提升用户体验,下面进行具体介绍。
二、信息流推荐典型模型介绍
DIN【1】(Deep Interest Network for Click-Through Rate Prediction)算法:
DIN是当前利用深度学习神经网络进行信息流推荐的代表性算法。DIN算法针对的是业界中点击率预测(Click-Through Rate, CTR)的任务,可以很好的辅助在线广告的信息流推荐。
文章指出通过 Embedding + MLP方式进行基于深度学习模型的推荐算法结构已经被广泛引用于实践中。在这些方法中,大规模稀疏输入首先将特征映射到低维嵌入向量中,然后以分组方式转换为定长向量,最后将它们串联在一起传入多层感知器(MLP)以学习特征之间的非线性关系。
但这种做法的问题在于无论候选广告是什么,用户特征都被压缩为固定长度的表示向量,然而使用定长的向量将成为技术的瓶颈,会使从丰富的历史行为中捕获用户的不同类型的兴趣造成困难。
深度兴趣网络(DIN)通过设计一个局部激活单元来自适应地学习从历史行为对用户兴趣进行表征的方法,从而大大提高了模型的表达能力。此外,还提出了两种技术:mini-batch aware regularization和一种自适应激活的激活函数,来进一步辅助训练超大规模参数的网络结构。在两个公共数据集以及阿里巴巴真实生产数据集中与其他深度学习进行CTR的方法相比,该方法表现很不错。算法的具体流程图如下所示,通过DIN的流程可以大致了解当前深度信息流推荐的核心做法。
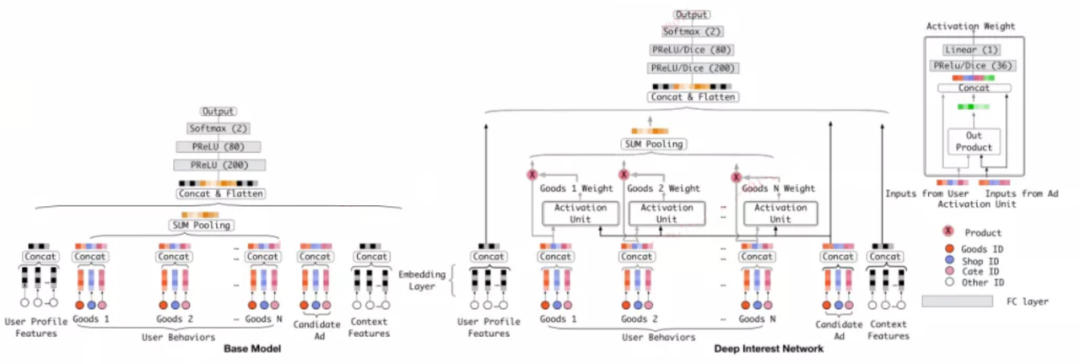
图1. DIN模型框架图
KRED【2】(Fast and Accurate Knowledge-Aware Document Representation Enhancement for News Recommendations)算法:
知识图谱包含结构良好的外部信息可以对推荐系统有所帮助,可以利用知识图谱对推荐进行知识增强。
推荐系统在知识图谱中进行实体链接,通过链接知识图中的实体,将知识和推荐更好的结合到一起去。但是,这种方法应用到新闻推荐中存在着一定的问题,由于文章的主体不同每篇文章相同的实体实际上可能在知识图谱中所关联的重要实体以及语义信息的相关权重可能不同,如何对这种情况进行优化是个很重要的问题,在我们的APP新闻推荐的场景下这个问题其实也十分重要。
KRED算法提出了一种快速有效的将知识增强应用于新闻文档推荐的表示增强的模型,该模型由三个核心部分组成:①实体表示层;②上下文嵌入层;③信息蒸馏层。
实体表示层代表实体本身和图谱中周边实体的embedding表示的集合;上下文嵌入层旨在区分各种实体的动态上下文信息,例如出现的频率,实体的类别和出现的位置;信息蒸馏层将聚合实体嵌入在原始文档向量的指导下对实体的表征向量进行聚合。
通过对真实新闻阅读推荐的数据集进行了广泛的实验,证明了KRED模型针对包括个性化新闻推荐,文章分类,文章受欢迎度预测和本地新闻检测等各种新闻推荐任务表现都十分不错。在我们的APP新闻推荐的过程中,也对KRED算法进行了充分的借鉴。KRED具体的算法流程图如下所示。
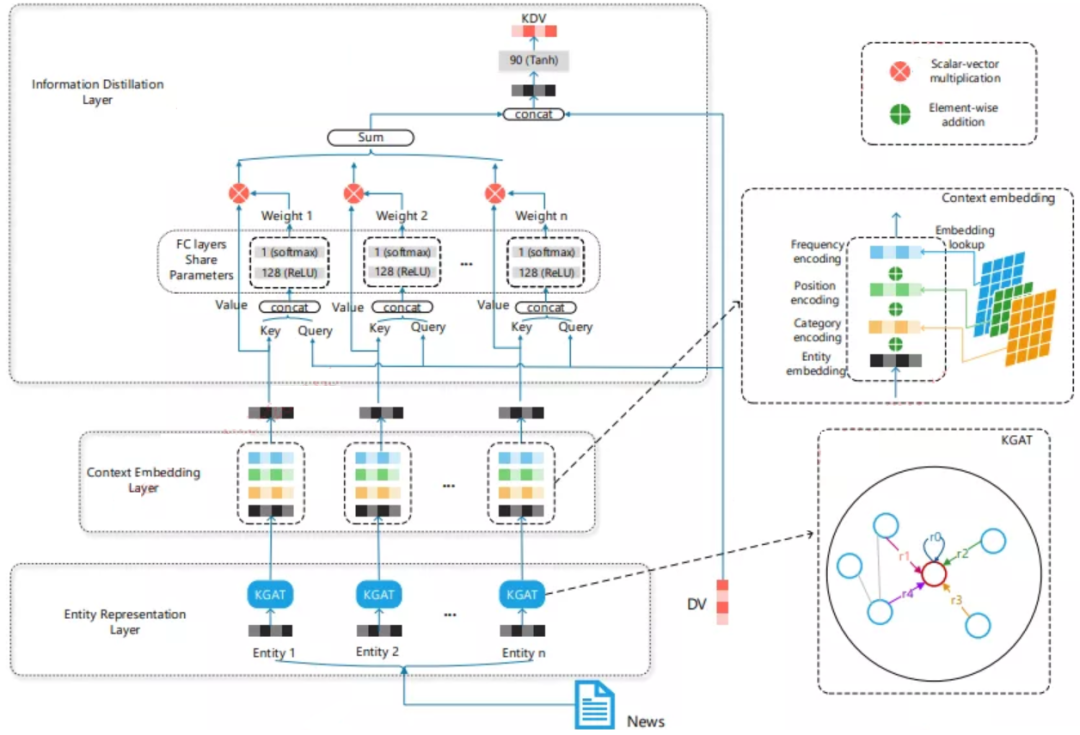
图2. KRED模型框架图
DAKUN【3】(Deep Action and Knowledge Union Neural Network for Content Recommendation)算法:
在CTR问题中,除了使用较大规模稀疏的原始特征,通过NLP(自然语言处理)方法提取丰富的语义向量也应该被充分的利用。现在很多的模型都在利用向量分解机来获得低维度的稠密表征向量来代表高维度的稠密表征向量,然后通过多层感知器捕获它们的深层交互,但它们忽略了低维度的语义向量特征。
DAKUN算法同时使用高维稀疏特征和低维稠密语义特征。DAKUN可以很好的挖掘用户对热门内容和语义阅读兴趣。通过对比内容推荐系统上的其他模型,DAKUN在保险领域的新闻信息流推荐中取得了最佳的结果。DAKUN具体的算法流程图如下所示。
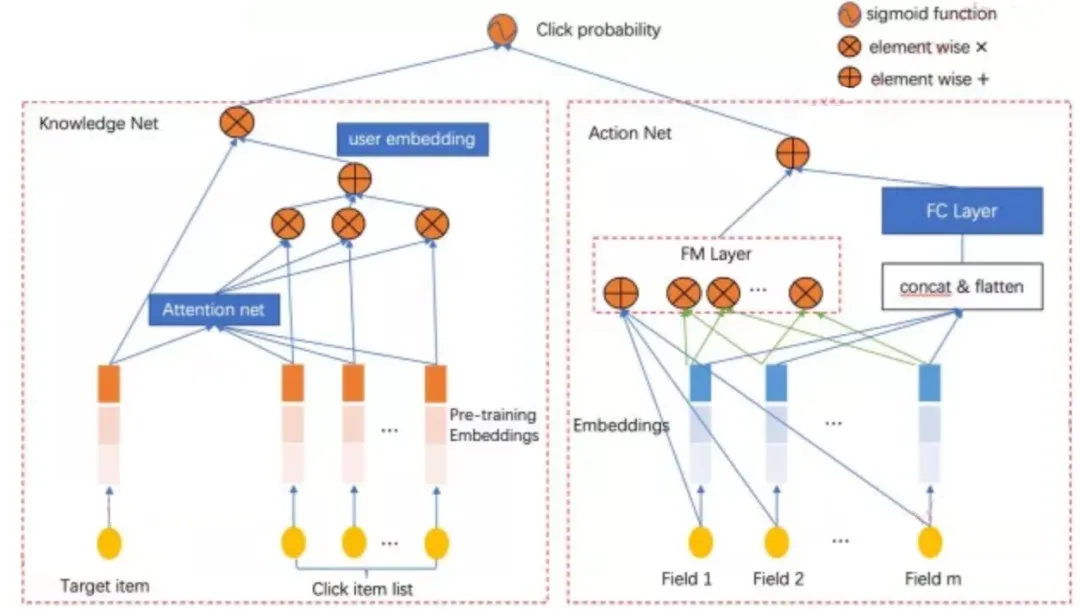
图3. DAKUN模型框架图
三、知识增强信息流推荐的实践
1. 信息流推荐中融合外部知识的必要性
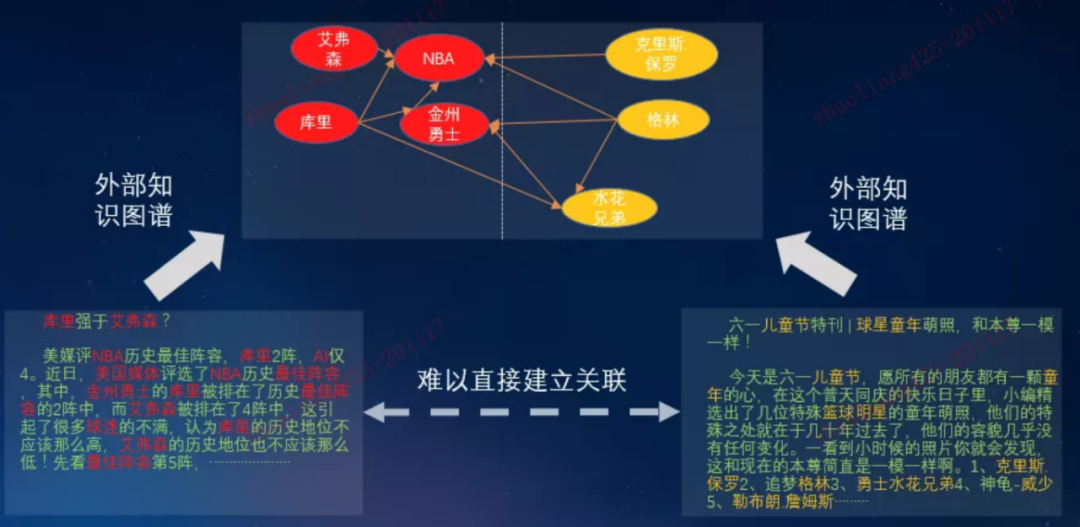
图4.信息流相关文章关联示例
信息流推荐的任务中,相似或者相关联的文章在向量空间中表示成相近的向量会极大的提升相应的推荐质量,我们主要的拓展性研究工作就集中在外部向量优化文章的内容表示的方向。
可以从图中看到同样是关于nba球星的两篇文章,如果仅仅直接通过字面关系有很多词汇之间的关联都无法直接建立起来,这样极大的降低了信息流推荐的质量,如何高效的利用外部知识将文章中较深层次的语义特征挖掘出来就十分重要。
而且需要注意的是,推荐任务的属性决定了不是简单的两篇文章之间进行比较,而是需要直接将一篇文章中所有通过外部知识可以利用的信息都利用起来,只有这样才可以从全部候选集中找的最适合场景的推荐文章。
2. 信息流推荐融入知识的Knowledge Enhancement Message (KEM) 模块
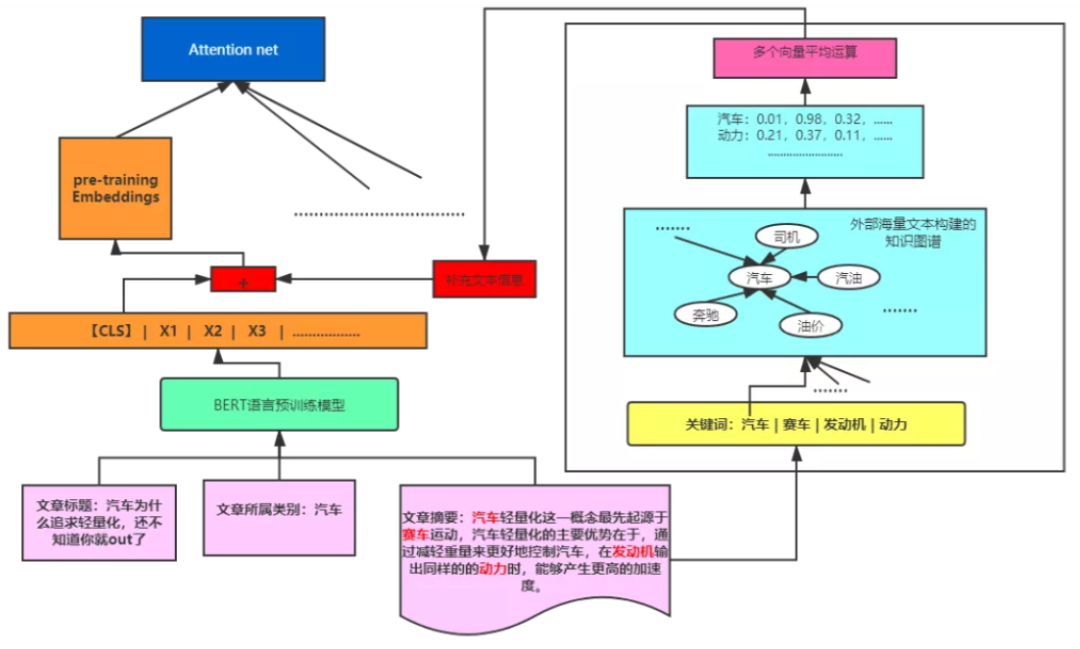
图5. KEM算法模块的框架示意图
为了将外部知识与信息流推荐更紧密的结合起来,在KRED模型的启发下我们构建了融合图谱知识的功能模块KEM (Knowledge enhancement message)。
KEM首先对每篇新闻文章进行实体的抽取,从文章中找到具有一定辨识度和物理意义的实体词汇,比如图中文章我们将汽车、动力、赛车、发动机,……等作为一篇文章的实体词代表。下一步,我们将定位到的关键实体词在XLore【4】中找到相应的向量表示,对找到的多个实体向量取其均值生成新的向量v。另一方面,文章的标题拼接文章的所属类别和文章的摘要信息作为综合文本信息的输入,将整体综合文本信息通过Bert语言预训练模型得到其【CLS】位的向量s。最后,将向量v与向量s进行拼接后得到的向量作为最�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%9F%A5%E8%AF%86%E5%A2%9E%E5%BC%BA%E4%BF%A1%E6%81%AF%E6%B5%81%E6%8E%A8%E8%8D%90%E5%9C%A8%E4%BF%9D%E9%99%A9%E8%A1%8C%E4%B8%9A%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


