篇论文大事业群这是腾讯在斯德哥尔摩的之夜
7 月,全球 AI 人才荟聚瑞典斯德哥尔摩,前来参加学界顶尖会议 ICML 和 IJCAI。在两个会议交接之际,腾讯在当地时间 14 日晚举办了 TAIC 大会,与三位特邀嘉宾、腾讯七大事业群代表探讨前沿 AI 研究与应用。

据机器之心了解,今年腾讯共有 17 篇论文被 ICML 2018 接收,15 篇论文被 IJCAI 2018 接收。本次活动设有三个特邀 keynote,以及五个分论坛,介绍了腾讯在人工智能领域的多元探索和全方位布局。
IJCAI 第 27 届回顾和工程化的标准建立
作为特邀嘉宾,香港科技大学主任教授,腾讯微信-港科大人工智能联合实验室主任杨强教授在开场演讲中表示,「中国队虽然没有进入足球世界杯,但我们进入了人工智能的世界杯,能有今天非常不易。」

1969 年,人们在华盛顿举办了第一届 IJCAI 大会,自那时起,中国学者的出席人数和论文提交量逐年递增。1995 年,参会的韩家炜、张钹等教授还在一起讨论该如发扬中国学界的声音,而中国科学院的教授更为了中国承办学术顶会四处奔走。快进到 2018,中国学者递交的 IJCAI 文章数目已经超过了美国同行,并在一些子方向的研究上开始领先。
杨强教授提到今年 IJCAI 将颁发首个以人工智能领域创始人之一马文·明斯基命名的 Marvin Minsky Award,获奖团队是 Demis Hassabis 带领的谷歌 AlphaGo 团队。他鼓励台下观众,「目前我们看不到 Minsky 奖项花落中国。这个才是真正的 AI 世界杯,能不能入围取决于下一代的努力。」
亲眼见证人工智能过去十几年在发展上的「三起两落」,杨强教授强调了工程化落地的重要性,并认为我们应当谨防下一次泡沫来临。
Petuum 公司创始人兼 CEO、卡耐基梅隆大学计算机学院教授,机器学习系副主任邢波在接下来的演讲中表示,人工智能在工程化的路上任重道远。举一个例子,造飞机引擎的工程师会排列近上百万个零件,进行系统的配置和升级。但算法的部署上还达不到相似的「制造」标准化,欠缺可操作性、可解释性和可重复性。

该如何建立这个工程流程呢?「例如一个最简单图像分类的回归算法,现在没有统一标准或者用什么样的 API 来进行工程化。在工程化的过程中,为了提升模型,你可以加入贝叶斯先验条件,加入正则化,加入约束,还可以把不同的模型统一起来。这是一种思考方式,模型本身是可拆分、可组合的。好处是所产生的算法和模型能够更加适合做分析,能够提供一个导向性。我们还要考虑算法以外,用一个具体问题的适用性,把工程化思路走得更远。」
邢波教授补充道,「我们可以把这个过程收集成一个个库,编写成一个手册。一旦形成严格的工程习惯,把复杂的流程变成选择项。」
另一个问题是人工智能可解释性,包括数据可解释性、模型可解释性、推理可解释性、和过程可解释性。邢波表示,如果人工智能是一个大系统,从接触原始数据开始,它包罗的方面就已经非常复杂了。目前模型的使用上还是缺乏清晰的因果关系,还处于一个炼金术阶段,离化学和化工厂这种可解释性强还有差距。
腾讯技术落地的先锋队:优图实验室
腾讯优图实验室总经理、杰出科学家贾佳亚教授随后上台,向大家介绍了腾讯优图实验室(X-Lab)在人工智能技术上的发展。
优图成立于 2016 年 4 月,分别在上海、深圳、合肥、香港设有实验室,也将在北京和硅谷设立分支,拥有近 200 人的团队。
相较于专注于前沿技术的 AI LAB,优图的定位更加偏向于应用方向。「我们拥有 2 亿兆人脸的数据库,13 个方向识别方案,有超过 70 个产品使用的其技术。每天对外调用服务的次数超过 20 亿次。」
贾佳亚教授认为,视觉具有可落地的特性,例如来到斯德哥尔摩,很多人都会拍照发朋友圈,使用相机美颜或者 P 图软件进行修改。「我们在选择自己的课题时,致力于做有趣,能看到、感受到、理解到的视觉。」

贾佳亚教授将人工智能区分为前景视觉(Front-End AI),包括图像编辑,处理和创作;以及背景视觉(Back-End AI),包括识别,分割和推理。
贾佳亚介绍到,「早在 2004 年,我还在微软亚洲研究院的时候,就着手研究图片的背景转移或者融合。到了 2017 年,我们重新捡起这个课题,用深度学习打磨了整个框架,做了一个大规模的训练,实现了自动图片背景分割。在这之后,还可以对背景进行再创作。去年我们做了一个叫做 Makeup-Go 一键卸妆的功能,还原美妆加工前的素颜。」
在后端,优图实验室的内部系统可以实现几千种物品的识别,在几十亿图片上训练迭代,有非常高的精准度。优图团队同时是做自动驾驶场景分割最好的团队,在各类比赛成绩斐然。
在 keynote 分享结束后的分论坛中,腾讯 7 大事业群的代表分别结合各自不同的业务与参会的 AI 学者进行了分享交流。
腾讯「无量系统」:大规模模型训练和预测服务
腾讯云计算高级研究员袁镱在分会坛向观众介绍了腾讯的大规模模型训练和预测服务业务。互联网公司有大量的数据,整个倾向就是走大模型的路线,腾讯也开发了「无量系统」,支持 LR/FM/FFM/DNN 等多种常用模型的大规模训练和预测服务,现已在手机浏览器业务中投入使用。
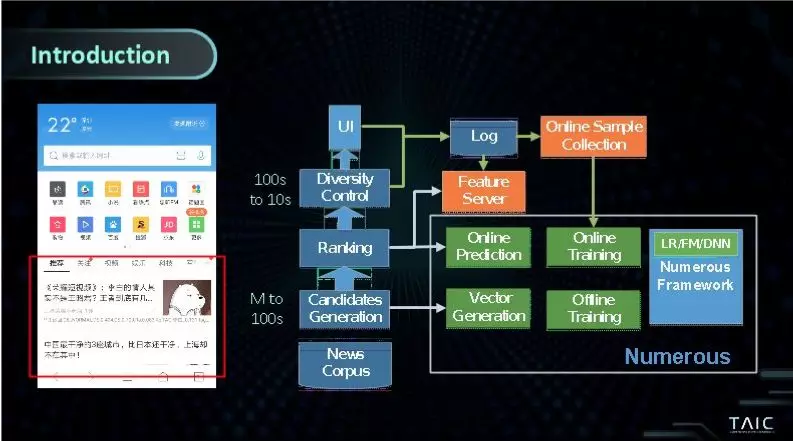
腾讯有 18-19% 的盈利依赖广告收入,根据公司第一季财报显示,这一部分的收入还在持续增长。网页、图文、视频等推荐场景的广告跟模型有很大的指标关系:把模型的 AUC 拉高百分之一,整个点击率就会提升百分之一,对于整个公司来说是亿级收入的提升。
LR 模型百亿级别,DNN 模型是千亿级别。要训练这样的模型,所需要的参数量非常的大,模型的规模是到 PB 级别的。超大规模模型在训练和上线服务都面临着很大的挑战。首先,该如何快速训练这样的模型?首先需要有高性能系统的训练,因为公司没有资源等十天半个月去迭代。其次,TB 模型的大小是几十个 G,这样大小的模型上线可能机器都装不下这个模型。
据袁镱介绍,腾讯无量系统基础定位就是做超大规模的模型训练和整个平台的上线,已经能够完成百亿样本 / 百亿参数模型的小时级训练能力,并且已经构建起自动化模型管理系统「无量模型管理」,能够离线训练任务,在线训练集群和在线预测服务之间无缝运转。
推荐系统在内容领域(新闻、视频)的应用和前沿研究
数据专家凌国惠在分论坛介绍了数据分析以及 AI 技术在微信生态系统中的应用和前沿研究。

据介绍,微信拥有超过 10 亿的月度活跃用户,用户与用户的连接形成庞大的复杂网络,在此复杂网络上,进行了社区识别、强关系、弱关系、影响力、传播、社会分层等研究,广泛应用在社交广告、线上金融、以及传播预测等业务上。其中社交 Lookalike(相似人群拓展)系统,很好融合了上面挖掘的社交数据,协助微信广告投放到更有针对性的目标用户群体,在广告效果尤其在互动率(对广告点赞、评论)方面,有着显著表现。
除了上述的广告领域,AI 技术也广泛应用在微信业务中:微信智聆和微信翻译是业界领先的 AI 引擎,每天为 10 亿用户提供高质量语音识别和翻译服务,并且通过微信开放平台接入了大量的小程序和第三方 APP;微信搜一搜和看一看使用 AI 技术为用户提供精准的搜索服务和个性化阅读推荐服务;微信智聆和微信智能对话系统通过腾讯云小微平台对外开放,帮助智能硬件厂商实现语音人机互动,目前已经应用在数十家硬件厂商的产品中。
新闻算法总监范欣介绍了腾讯新闻中的推荐架构、算法设计、以及创新业务算法。腾讯着重研究对新闻内容理解、个性化推荐,以及帮助用户实现沉浸式一站式的阅读体验。近年来,腾讯的内容从编辑内容进入专业内容+自媒体时代,现已拥有千万级别的内容池。用户消费的内容也从单纯的图文,进入了多样化的模式,包括短视频、知识问答、话题讨论、名人号和评论等等。范欣表示在辅助内容生产的生态进化基础上,还需要帮助用户实现「一站式的阅读体验」。
从技术上来说有三个部分:1)深度理解挖掘内容,完善内容兴趣表征的构建;2)实现多模态模型的结构化,通过构建新闻内容领域的知识图谱,结合内部和外部数据做事件发现和聚类;3)精准构建用户画像,做多维度表征和基于语义、行为的兴趣挖掘。这种整合将摆脱基于少数维度匹配的方法,根据内容、用户、环境整体的匹配,提供更合理、更有价值的个性化内容。
深度学习时代的游戏和社交广告
游戏和广告是腾讯最大的收入来源。从 2004 年开始运营,腾讯游戏在 PC、Mobile 等多平台发布超过 300 款不同游戏,在用户数量和收入上已是世界第一。Turing Lab 总监张力柯,游戏 AI 专家殷俊,数据挖掘高级研究员李英杰分别就深度学习在游戏中的应用等话题进行了分享。殷俊表示现在将 AI 技术应用到游戏工业的研发体系中会遇到很多新问题。

针对听众提出的「能否不再使用传统的行为树和人为规则,而对原始游戏画面直接采用增强学习/模仿学习等算法来自动实现游戏 AI」这个问题,张力柯认为,尽管学界近年来在早期 Atari 游戏上使用深度增强学习算法取得了不小突破,但早期游戏多是简单的 2D 画面,玩法单一,并不存在现代游戏中大量的 3D 画面特效干扰、庞大的状态空间和多样化的局部奖励等等,而这些都是在实际应用上需要付出巨大努力去克服的技术挑战。在这次 AI 大会中,很多学者开始尝试用 Imitation Learning 和 Inverse Reinforcement Learning 等方式来解决。就目前而言,不管是无人驾驶还是游戏自动测试,通常都采用多种技术互补的方案。
针对游戏用户体验的方向,李英杰提出了一个玩家成长路径的问题,「不同类型玩家玩同一个游戏的方式将会大不相同。以王者荣耀为例,用户都是从三个基础英雄出发,如何演变成各人不同的后续英雄使用序列?是自身个性还是关键时刻的事件主导,要用什么模型和抽象层级去表现这个路径?」
特邀嘉宾南大计算机系的俞扬教授补充道,强化学习在工业应用上还有很多需要解决的问题:譬如在游戏里,机器人玩家是很容易被辨识出来的,那么让 AI 在呈现上更逼真,贴近人类玩家也是一个重要的研究方向。
来自腾讯社交广告的机器学习专家周星、刘海山就广告场景下的深度学习技术应用做了详细介绍。总体上,AI 能力已经融入到腾讯社交广告系统的各个环节中,包括对文本的自然语言处理,对广告素材的分析挖掘,广告检索和排序等。两位专家从智能定向、智能出价和智能创意三个方面做了进一步的技术阐述。
智能定向方面,腾讯社交广告正在尝试打破这种传统,通过机器学习技术,自动理解广告,从而实现受众和广告的精准匹配;智能出价方面,两位专家详细介绍了 oCPA 的能力和实现方式,广告主只需要提供希望的目标转化成本,系统会基于目标转化成本和 pCVR(点击到转化的预估概率)对广告在线智能实时出价。为了做到精准的预估,腾讯社交广告开发了可以训练千亿样本和特征的大规模离散深度学习平台 Thousand Sunny,自上线以来广告主转化率提升 10%。智能创意方面,重点阐述了动态商品广告及其背后的技术,讲解了如何通过深度学习技术实现广告商品的千人千面,以及广告素材的自动生成。
此外,在分论坛中,深海实验室负责人辛愿面向与会者交流了腾讯金融在 AI 领域里,尤其与 decentralized training、privacy preserving、malware and anomaly detection 相关的应用情况和前景。
探索前沿技术与业务:AI Lab
腾讯 AI Lab 计算机视觉中心负责人、杰出科学家刘威博士,向大家介绍了 AI Lab 在人工智能上前沿技术与业务的探索。并且也计算机视觉的研究与落地成果作为代表,与参会者进行了题为「多媒体 AI」的技术分享。
腾讯 AI Lab 是腾讯的企业级 AI 实验室,于 2016 年 4 月在深圳成立,目前在中国和美国有 70 位顶尖研究科学家及 300 位应用工程师。腾讯 AI Lab 强调研究与应用并重发展,基础研究关注机器学习、计算机视觉、语音识别及自然语言处理等四大方向,研究论文已覆盖国际顶级学术会议。据了解,今年腾讯 AI Lab 共有 16 篇论文被 ICML 2018 接收,21 篇文章被 CVPR 2018 接收,18 篇文章被 ECCV 2018 接收,5 篇文章被 ACL 2018 接收。相应的技术也落地于腾讯公司的多个产品中。
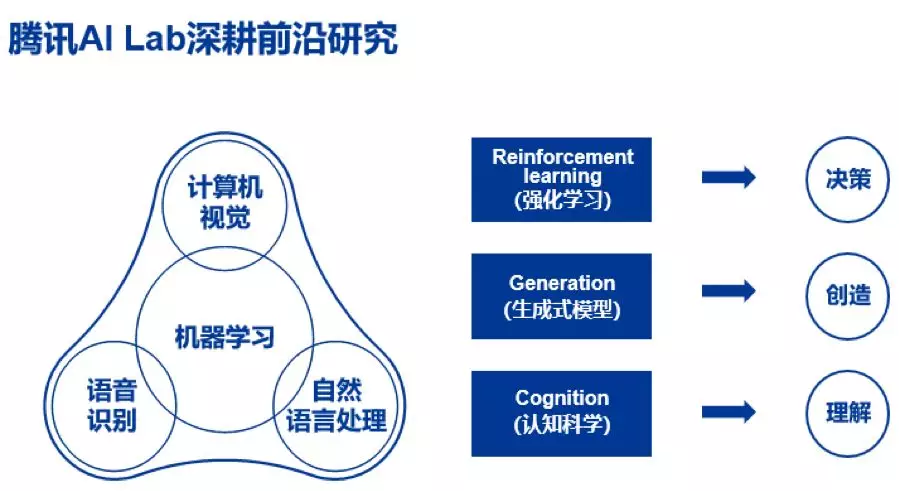
针对计算机视觉中心的研究,刘威博士介绍到,计算机视觉中心的目标是在多媒体 AI 的研究领域上达到世界一流水平,探索 vision+X 的前沿学术研究和相应技术在腾讯产品中的落地。

计算机视觉中心通过不断探索计算机视觉中的底层、中层、高层以及 AR/3D 等问题,致力于提升公司在学术领域和技术产品领域的品牌价值。底层视觉计算主要提升图像/视频质量。中层视觉问题主要提升图像/人脸/视频识别的能力,AI Lab 视觉中心在人脸的检测与识别屡次刷新公开数据集合上的性能,相应的技术也落地于公司的不同产品中,日调用量>6 亿次。高层视觉更聚焦于图像/视频的深度理解,AI Lab 视觉团队,在 MSCOCO 图像描述公开数据集合上,排名第一。并且在视频描述生成和视频热度预测上进行了前沿技术的探索,在 CVPR 2018 和 WWW 2018 发表多篇文章。在 AR&3D 方面,AI Lab 中心也探索了 SLAM 技术在终端上的应用与技术的探索。
计算机视觉中心 2018 年迄今论文发表 17 篇 CVPR(1 篇 oral,5 篇 spotlight),14 篇 ECCV,4 篇 ICML,2 篇 SIGIR,1 篇 WWW,4 篇 IJCAI,4 篇 AAAI,1 篇 PAMI,1 篇 IJCV。
腾讯 SNG 的量子计算+机器学习
2017 年底,腾讯社交网络事业群(SNG)首次公布量子实验室,香港中文大学教授张胜誉出任杰出科学家。正如当时 SNG 总裁汤道生所说的:「腾讯 SNG 正在大力投入技术,组建由优图实验室、音视频实验室和量子实验室三大实验室。」在 TAIC 上,SNG 的量子实验室与优图实验室与参与该分论坛的 AI 学者们进行了
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%AF%87%E8%AE%BA%E6%96%87%E5%A4%A7%E4%BA%8B%E4%B8%9A%E7%BE%A4%E8%BF%99%E6%98%AF%E8%85%BE%E8%AE%AF%E5%9C%A8%E6%96%AF%E5%BE%B7%E5%93%A5%E5%B0%94%E6%91%A9%E7%9A%84%E4%B9%8B%E5%A4%9C/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


