腾讯信息流热点挖掘技术实践

分享嘉宾:罗锦文 腾讯 研究员
编辑整理:Jane Zhang
出品平台:DataFunTalk
导读: 当前各大资讯社交类APP都在显著的版面展示或者推荐热点相关内容,信息流应用能否快速发现热点、引导用户阅读热点,是影响用户体验的重要因素。本次分享主要介绍腾讯在热点挖掘方面的工作。基于搜索数据和自媒体文章,通过时序分析方法和内容聚类相结合的方法挖掘热点,并将热点聚类成事件和话题。用户搜索和媒体生产能够从消费和生产两个方面更加准确的度量热度,事件和话题同时能够辅助用户理解,做到热点的个性化下发,从而提升信息流热点体验。本文主要内容包括:
- 项目背景
- 相关研究方法
- 热点计算框架
- 热点挖掘
- 热点应用
01 项目背景
1. 热点应用场景
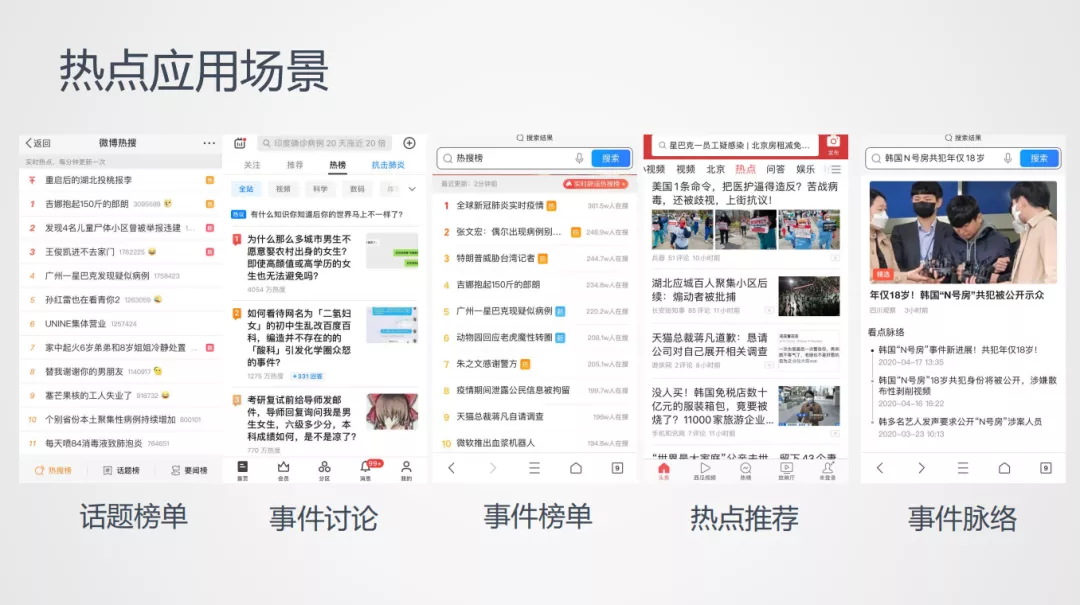
当前各大资讯类的产品都在显著的版面上展示和推荐热点相关内容,针对热点内容的推荐和呈现也变得非常多元化,比如:微博有微博热搜榜;知乎通过事件讨论的形式运营热点;百度有历史悠久的百度热搜榜;头条通过兴趣推荐的方式做热点分发频道,腾讯在对大事件做脉络运营。当前各大产品都对热点进行了大量的投入,我们基于腾讯看点丰富的视频数据,深挖用户的兴趣内容,接下来看下我们在腾讯看点的推荐频道页。
2. 热点核心推荐问题
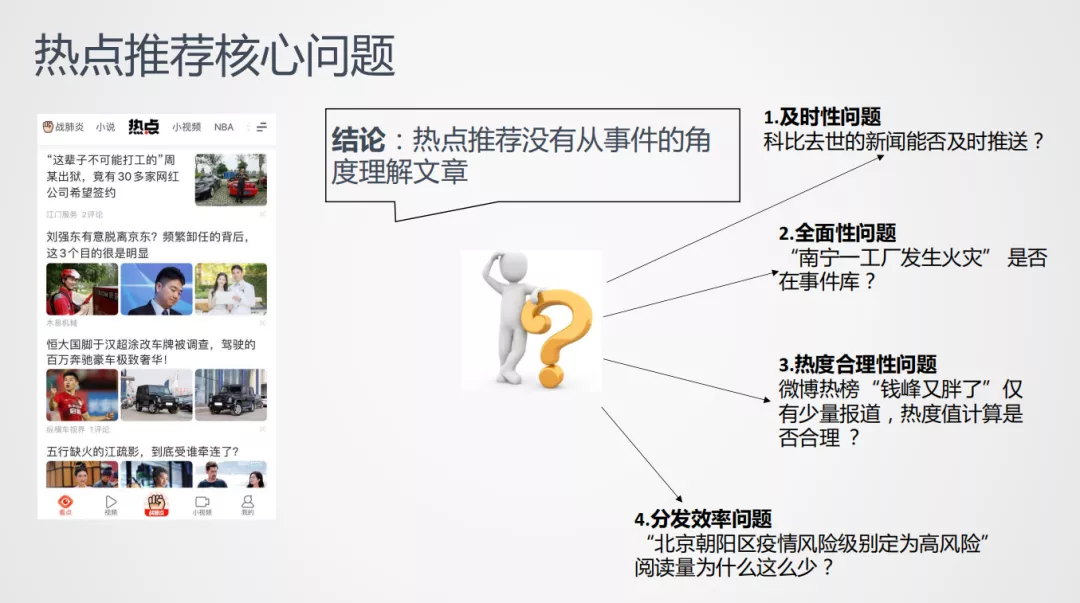
这里对腾讯看点进行问题的分析,当前基于热点的问题存在以下几个问题:
- 及时性。热点挖掘需要及时监控全网站点,以科比去世为例,及时发现这一事件,并挖掘出来对应报道,才能有效帮助热点进行推荐和分发。
- 全面性问题。不同站点对热点的呈现不同,需要将事件榜单、话题榜单和对应的多种报道合理组织起来。比如,当一篇"南宁-工厂发生火灾"文章入库后,热点挖掘能否判断已有的挖掘结果与之对应,才能更好地进行推荐。
- 热度合理性问题。热度值是热度的重要特征,不同的数据源的事件热度各有不同,比如微博热搜榜当时有"钱峰又胖了"的话题,排在微博热搜榜很高的位置上,但是由于不同媒体的受众不同,在看点这边就很少有文章报道或者有用户去阅读。
- 热点分发的问题。热点文章和视频都有冷启动的问题,如在北京朝阳疫情定为高风险时,大部分是根据兴趣点推荐的,最近一段时间大家的用户画像中提出来"疫情"这个特征,如果基于疫情进行下发,非北京地区的用户不关注这个文章,这会降低系统的分发效率。因此要进行泛化,比如泛化到"北京疫情"这样的话题,来做用户分发,以此解决这篇文章冷启动的问题。
接下来能看到热点推荐有没有从事件推荐的角度来理解文章。有没有从事件的角度来理解文章,是提升热点推荐效果需要重点讨论的点。带着这几个问题,来看看传统的相关研究是怎么解决这个问题的。
02 相关研究方法
1. 事件抽取
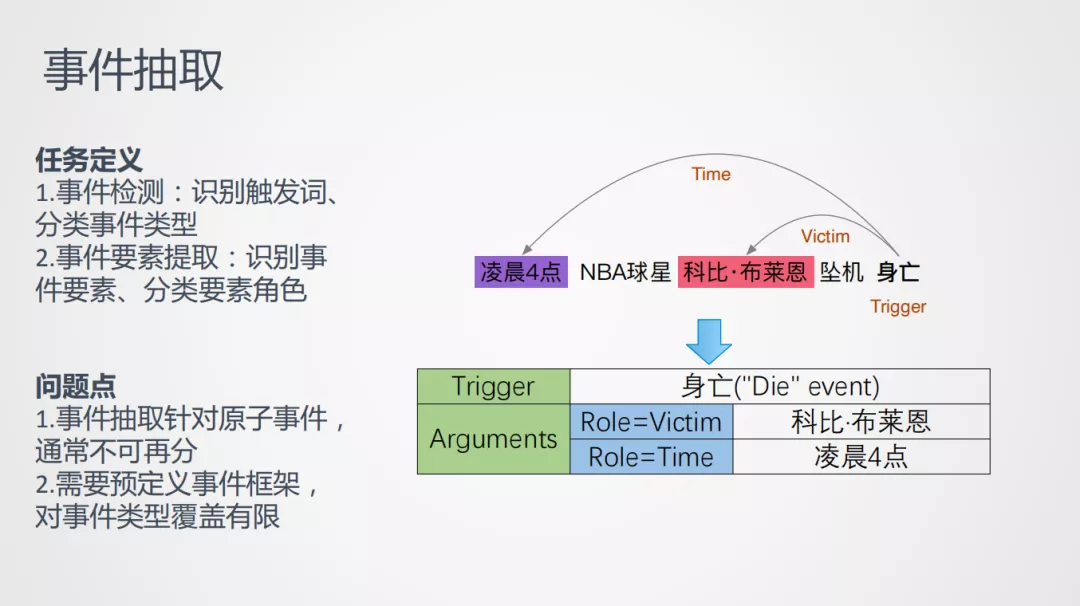
任务定义:
作为信息抽取的一个重要任务,事件抽取是从一个无结构化的文本中自动抽取出来结构化的知识。以ACE任务为例,事件抽取可以分为事件检测和事件要素提取。事件检测是识别句子中的触发词trigger,这个词是描述时间的核心动作,然后根据预先定义好的框架,进行事件类型分类,因此事件分类是一个封闭集合。我是科比的粉丝,专门研究过科比不幸遇难时的相关报道,以科比去世为例,这里"凌晨四点,NBA球星科比布莱恩坠机身亡",可以识别出trigger词为"身亡",事件类型分类为die – 死亡事件类型,对应的事件要素是:event frame,包括:施害者、受害者、事件、地点等。通过事件提取的方式,能提到时间是"凌晨四点",受害者是"科比·布莱恩",把受害者和时间对应起来。这就是一个比较完整的事件抽取过程。
问题点:
可以看到事件抽取任务,是针对原子事件,通常是不可再分的,如通常提及的"新冠疫情爆发",“南方洪水成灾”,这是有很多子事件的,不能通过事件抽取挖掘出来,同时事件框架要提前定义好,但是事件类型有限,难以覆盖新涌现出来的事件,因此只将事件抽取作为一个重要的特征抽取工具。
2. 话题检测与追踪 ( TDT )
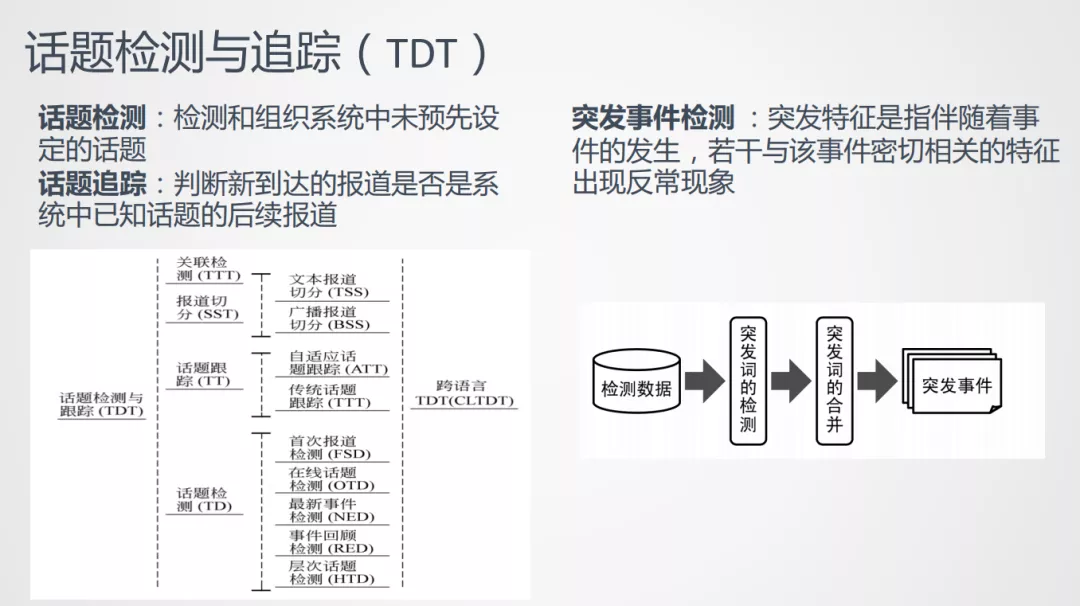
接下来的任务和热点挖掘更相关,就是话题检测与追踪中的TDT任务,这个任务有20多年的历史了,定义的是处理新闻报道的系统。输入可以是固定的文章或者流式数据,结果是以聚类的方式将文档组织起来的话题。
话题检测: 检测和组织系统中未预先设定的话题,也就是新话题的发现。
事件追踪: 新到达系统的报道是否是已知话题的后续报道,也就是把新到达的文章和已有话题算相似度。
通常研究方法分为2类:
- 第一类算法是寻找TDT任务中的新的聚类算法,或对已有聚类算法的改造,常用的算法有:k-means、DBSCAN、层次聚类;
- 第二类算法是挖掘新的聚类特征来提高TDT任务的计算效果,如使用文本的语义特征、分类特征、实体特征、上面事件抽取提到的特征,和任务结合起来,计算更准确的相似度。当然TDT也有很多别的子任务,大家有兴趣可以去看一下。
突发事件监测: TDT为我们处理海量数据提供了很多新的解决思路,之后衍生出来了突发事件检测任务,值得关注。突发特征指的是伴随着事件的发生,若干与该事件密切相关的特征出现反常现象,比如文档、词语的爆发,比如南方下暴雨,暴雨这个词就会比去年或者前几个月的时序有明显的不同,最近是一个显著爆发的特征。我们可以通过检测突发特征来发现事件,这类研究目标与TDT任务不同,不再局限于传统的新闻报道,可以针对多类型的数据,比如微博、搜索、视频数据,受此输入的影响,我们将时序分析方法和话题聚类相结合,来提升热点挖掘的效果,以上方法都能很好地指导我们进行热点挖掘的工作。
接下来针对腾讯海量的数据和数据类型多的特点,提出了我们自己的热点计算框架,下面简单介绍。
03 热点计算框架
1. 总框架
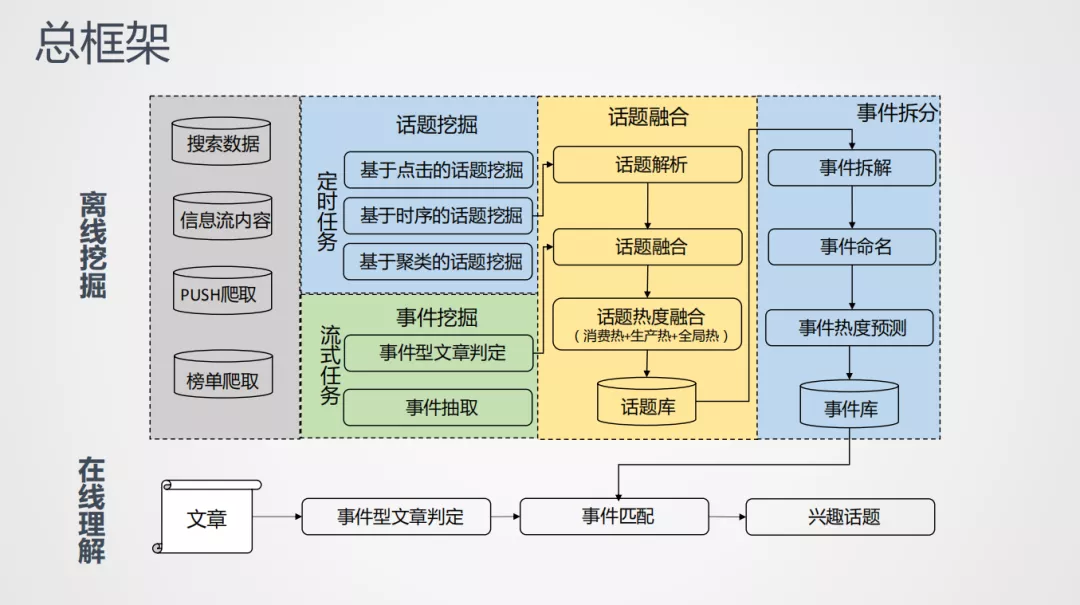
整体分两部分:离线挖掘和在线理解,离线挖掘内容非常丰富,着重讲这块。
离线挖掘流程:先是资源引入,有3个不同的端,腾讯看点浏览器、qq浏览器、qq里的腾讯看点频道,接入丰富的数据之后,通过话题抽取,来提取热点特征,进行话题融合,把挖掘到的结果聚类成话题,再把话题拆分成对应的事件。
为什么先做话题聚类,再做事件拆分呢?
还以科比去世为例。当时描述这个话题,一部分报道的是"科比意外身亡",另一部分报道"科比妻子悲痛欲绝",以及"明星悼念科比"。当事件在凌晨刚发生的时候,只有一个媒体和几家论坛报道了这个事情,算法比较难把主要描述"明星悼念科比"和"科比意外身亡"的文章拆成两个,看做一个更加合理,文章增加一两个小时后,很多媒体从不同的角度描述这个事件,文章的丰富程度足以支撑我们把这个话题拆封成合理的较细的粒度,这个细分是比较符合用户兴趣的,比如女性用户更加关心科比妻子的情况,而对一些外国明星悼念科比不那么感兴趣,因此能够以更加有针对性的事件的粒度推荐,提升热点推荐的效果。
详细流程:
① 热点挖掘
热点挖掘是为了满足全面性、及时性的要求,把热点挖掘拆为定时任务和流式任务。
- 定时任务:主要是搜索点击的特征、搜索词文章中的关键词的时序特征,与文章内容聚类的方式结合,把描述相近资源的文章聚合在一起,以话题形式组织起来。
- 流式任务:将入库的文章,及时通过事件判断过滤掉非事件内容,提升计算流程的时效性。
② 话题融合
经过话题挖掘和实践挖掘后,进行话题融合。话题是对向上泛化,需要话题解析模块,将不同输入来源的热点信息以特征提取,与流式处理的融合,组织成话题的粒度;最后通过话题融合模块,从3个不同的角度定义一个热度,这样定好的热度,更加符合平台用户的热度感知,这样能帮助我们进行热点推荐。
③ 事件拆分
得到话题后,为了有效组织事件内容,需要对话题进行拆分,通过对事件命名的方式,把事件以简短的名称组织起来,得到事件tag,这样能支持线上使用,如事件榜单、事件脉络等,事件的核心词和热词进行热度匹配,把事件统一管理起来服务于热点相关的应用。
为什么要做话题库和事件库?
以近期的"暴雨资讯"为例,用户感兴趣的是"安徽特发特大暴雨"的事件内容,而非提及暴雨的文章 ( 比如"日本暴雨导致山洪爆发" ),我们需要把不同的数据源以话题库的形式组织起来,帮助热点推荐以跳出关键词 ( “暴雨” ) 推荐的限制,为用户提供更加符合其兴趣的内容。有了热点计算框架后,我们看看在应用场景上如何落地。
04 热点挖掘
**1. QueryLog热点挖掘 **
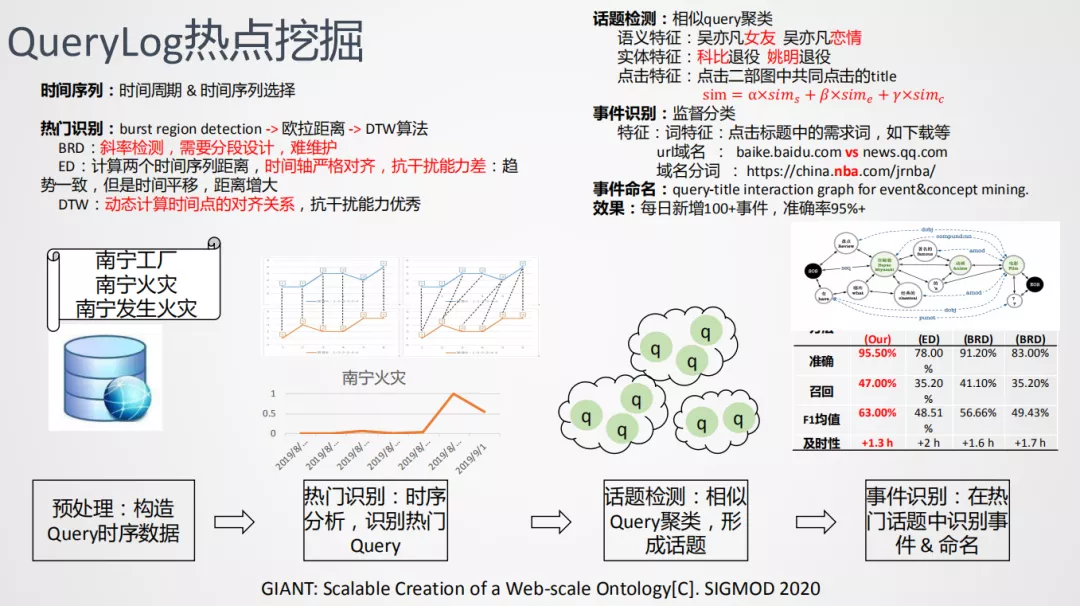
第一个是基于query的热点挖掘。
① 预处理:构造Query时序数据
基于这样的假设:如果热点热门,用户有了解详细内容的需求。会通过query去搜索事件详情,因此我们以query为数据来源,这是一个显而易见的事情。如南宁发生火灾,用户会搜索南宁工厂,了解具体的伤亡情况。用户的搜索多种多样,基于突发热点能检测的方式,常见的是根据搜索词构建时间序列,使用BRD算法计算突发性,突发性需要进行分段处理、斜率检测、需要做分段设计,难以维护。我们构造了query热点计算流程来解决这个问题。
② 热门识别:时序分析,识别热门Query
首先是构造这个时序之后,通过时间序列分析来识别热门query,具体做法:定义一个热门query的趋势模板,前面几天平滑,最近有一个上升的趋势;或者小幅度上升,近期然后突然下降、热度减退的模板,这样计算事件的相似度,如果符合,就认为是热门的query,否则就不是。
相似度计算最开始是使用欧拉距离,需要把时间轴上的两个点做严格对齐。虽然趋势一致,但是欧拉对齐会导致相似度计算值较低,会带来bad case,后来使用DTW ( 动态时间规划 ) 算法,使用动态规划的方式来对齐时间序列,能更好捕捉趋势相似的情况。
③ 话题检测:相似Query聚类,形成话题
挖掘到热门query之后,可以发现用户的搜索比较随意,同一个事件的描述也是多种多样,对应多个query,所以需要把相同事件的query聚集起来,构造一个话题,与TDT中的无监督有所不同,搜索可以使用点击二部图的方式,以不同的query 可以点到同一个标题时,认为这两个query相似,结合语义特征,比如"吴亦凡女友"和"吴亦凡恋情",语义比较相似;还有实体特征,“科比退役"“姚明退役”,虽然两个都带有"退役”,看起来字面相似度较高,但是"科比"和"姚明"在事件中是不同的主题,可以对相似度降权。最后对相似度的综合得到更好地query相似度量,得到话题聚类结构。这里可以看到将query到话题的聚类。
最后,我们可以看到用户行为的话题检测,可以帮我们有效度量话题的消费热度。为什么是消费热度呢?是因为用户非主动搜索内容,表示用户有主动的消费意愿,所以是消费热度。这也是非常有效的话题度量方式。
④ 事件识别
在话题检测之前,当话题达到可拆分时,我们会对事件做拆分。常见的话题会伴随非事件的话题,比如热门美剧更新时,会出现热度突发,这样会混合这些query,因此基于监督做事件分类。比如词特征、点击信息,把"下载"去掉,url中的站点信息、域名信息加入进去,train一个分类器,可以有效识别出来哪些是事件、哪些是非事件。
事件命名,组里的同学在之前通过词法分析工具的基础上,提取了一个新的事件命名方式,基于query 和title构造图模型,来挖掘事件concept和event的命名。这是之前话题挖掘的延续,这个任务已经发表在SIGMOD 2020上,大家有兴趣可以做详细阅读。当前挖掘效果每天新增100+事件,准确率人工评估95+。可以看到对当前的挖掘效果,在传统上的提升。
2. 资讯文章热点挖掘
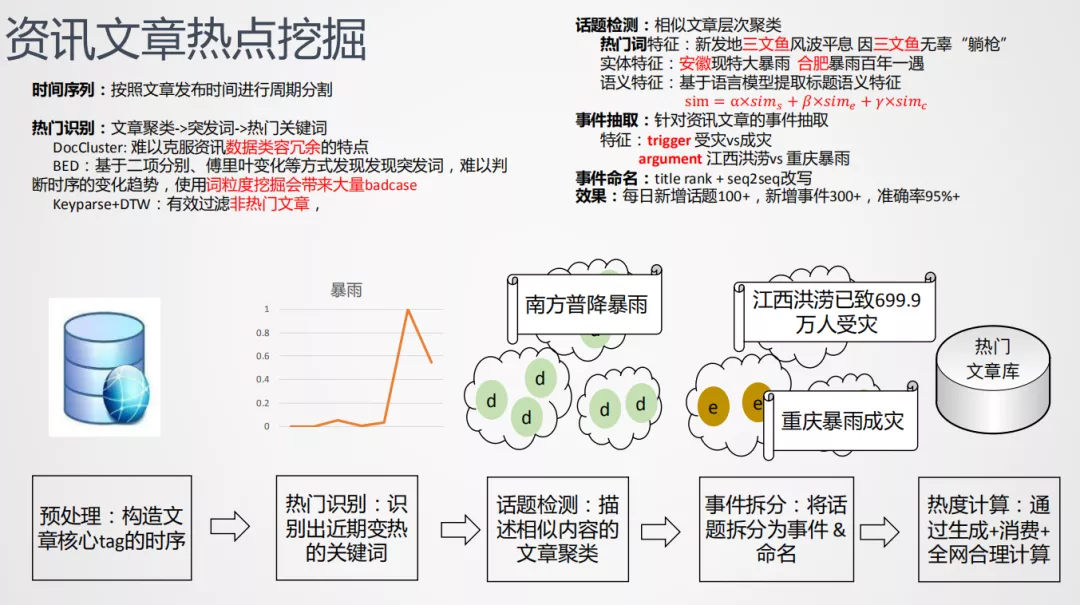
作为信息流服务的团队,每天打交道最多的是海量数据。当热门发生时,自媒体作者会主动跟进热点,创作文章跟进这些内容,比如当科比去世的一个小时后,即便是凌晨四点,作者也会也及时更新做报道。
挖掘主要是采用聚类的方式,离线的方式是将文章的数据按照固定发布时间做切分,通过batch learning对文章进行聚类,k-means、层次聚类这些方法会忽略这样的问题:每天有很多如描述刘德华过往文章,如果直接套用聚类算法会挖掘出来并非热点,会影响用户体验。热点文章包含时效性,如果直接套用聚类,没考虑时效性。传统的突发事件检测Graph event detection是基于二项分布或者傅里叶变化的方法发现突发次,这些突发次会持续一段时间的增长,而非突发的一个尖点。并且基于词粒度的挖掘会带来很多bad case,NLP同学都会发现这样的问题。切词的粒度不可控。
基于这些问题,提出了新的挖掘方式: 基于关键词和动态时间规划的方法来进行事件挖掘。
我们这里使用的处理方式:
① 预处理及热门识别
关键词描述文章主体,借助组内篇章理解的能力,将文章特征转换为关键词特征,与query挖掘相似,将关键词在文章库中出现的频次,构造时间序列,再用DTW算法与固定的模板做匹配,得到挖掘到的热门关键词。比如暴雨,或者前段时间北京6月份疫情,三文鱼突然热起来,通过这种方式挖掘出来"三文鱼"热门关键词,能召回很多描述新发地疫情相关的文章。当时召回的文章的acc和 recall都很高。接下来回到暴雨,通过暴雨召回所有和暴雨相关的文章,再构造热门关键词的实体特征,包括抽取的地点,安徽、合肥,加入实体特征,再用语言模型提取title的特征,计算相似度,3个相似度综合得到文章自底向下的层次聚类,从而得把南方暴雨聚成一个话题。而之前提到的"日本山洪爆发",虽然提到了暴雨,相似度较低,会聚类为一个孤立的点,可以过滤掉。
② 话题检测
在这之后,同样是聚类,得到的话题是自媒体创作的文章。自媒体作者可以认为
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E4%BF%A1%E6%81%AF%E6%B5%81%E7%83%AD%E7%82%B9%E6%8C%96%E6%8E%98%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


