腾讯技术微信图片翻译技术优化之路
作者:poetniu,腾讯 WXG 应用研究员
微信(WeChat)作为 12 亿+用户交流的平台,覆盖全球各个地区、不同语言的用户,而微信翻译作为桥梁为用户间的跨语言信息交流提供了便利。目前微信翻译每天为千万用户提供数亿次的翻译服务,且团队技术持续钻研,累计发表数十篇顶会论文、夺得多项 WMT 冠军。随着翻译质量的提升,微信翻译的应用形态从文本逐步扩展到图片、语音、网页、文档、视频等众多场景。本文以微信图片翻译为例介绍近一年的技术优化。
文章术语
- ViT:Vision Transformer
- NLP:自然语言处理
- 段落:指图片中语义完整且位置独立的文本区域
- CNN:卷积神经网络
- NMT:神经网络机器翻译
- Image Inpainting:图片修复
- GAN:Generative Adversarial Networks、生成式对抗网络
1. 微信图片翻译 1.0
首先简要介绍微信图片翻译 1.0 版本的技术方案,重点梳理其中的关键问题。
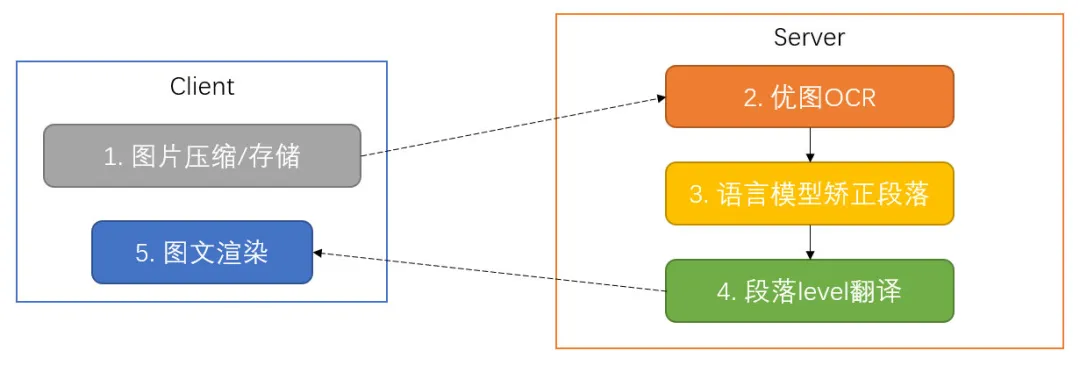
1.0 版本中微信图片翻译采用相对简单的方案,主要分为两个模块:后台 Server 负责图片的文字识别、段落合并、段落翻译等,客户端根据文字识别和翻译结果渲染生成翻译图片。整体 pipeline 如下图所示:
首先通过一批图片例子来看 1.0 版本的效果,这里我们对比竞品如有道、搜狗等图片翻译,如下图所示:

通过上述例子,对于图片翻译中间的关键步骤进行简单对比得到如下结果:
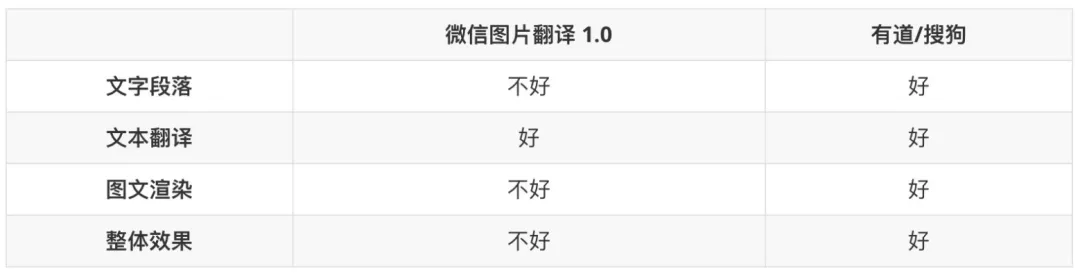
因此,整体上来看 1.0 版本的图片翻译效果体验还有很大的提升空间,其关键模块的效果都需要进行较大的优化,特别是 文本段落、图文渲染 最直接影响用户体验的模块。
2. 微信图片翻译 2.0
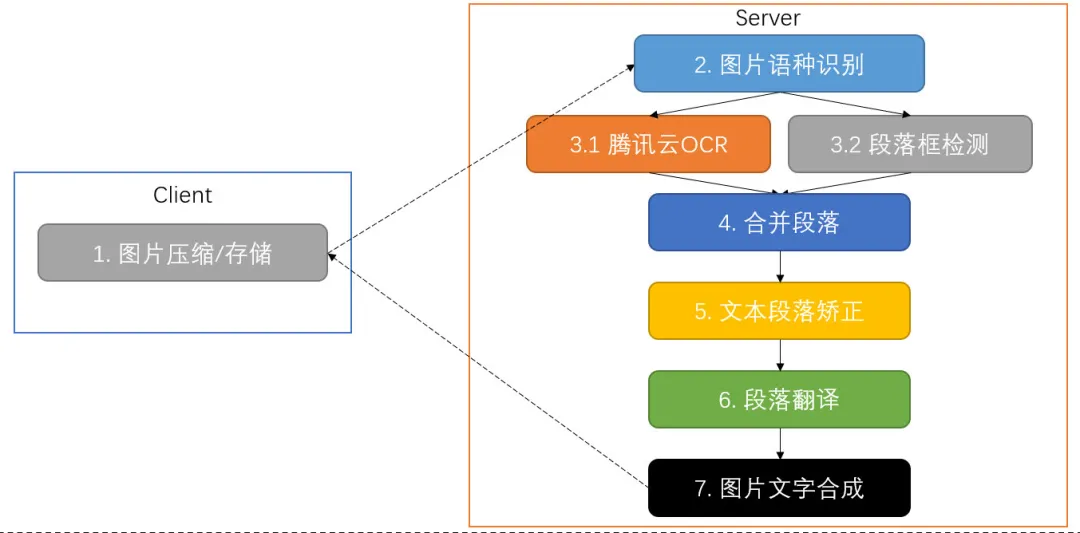
基于上述 1.0 版本存在的主要问题,在 2.0 版本我们重点优化了以下 前、后处理 模块:
- 增加图片 语种识别 模块:判断图片的语种分布。
- 增加图片 段落框检测 模块:检测图片中的段落框,用于基础段落拆分。
- 增加 文本段落 矫正模块:判断文本是否需要合并或者拆分为新的段落。
- 增加 图文合成 渲染模块:在 Server 端直接进行图片和译文的合成。
于是,整体微信图片翻译 2.0 版本的 pipeline 如下:
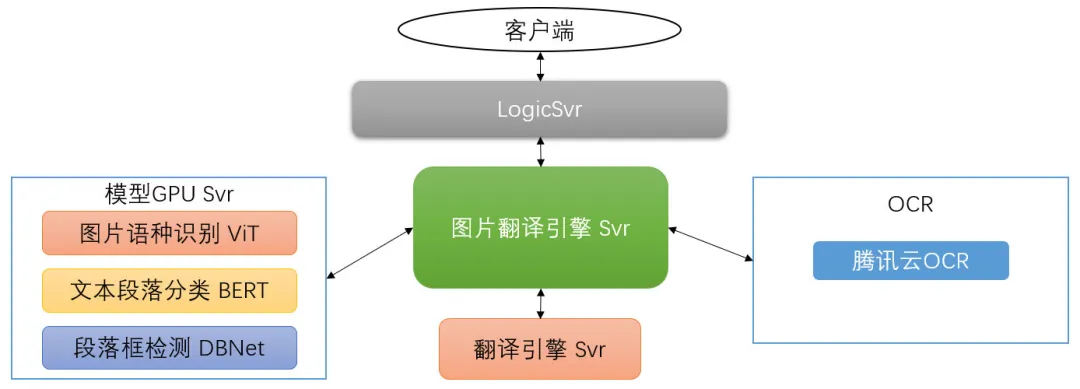
主要模块关系如下图所示:
2.1 图片语种识别
图片语种识别是给定一张图片,判断其中是否包含文字,进一步判断图片中文字所属的语种,即 Image Script Identification。
传统的图片分类技术主要是基于 CNN 结构,受益于其自身的 inductive biases (模型先验假设,如 translation equivariance 即转换等变性,通过 kernel 参数共享实现;locality 即局部性、通过卷积操作实现),在各个图片分类数据集取得领先的结果。而近年来随着 Transformer 结构在 NLP 领域取得突破的进展,诸如 NMT、BERT、GPT 等模型在机器翻译、文本分类、文本生成等任务得到广泛的应用。CV 领域研究者也尝试将 Transformer 结构引入到图像任务中,特别是今年谷歌提出统一的 Vision Transformer(ViT) 模型[1] 在大规模数据集的训练下,尽管缺少相应的 inductive biases,但是依旧超越 CNN 的效果。
也由此引起一股 ViT 的研究热潮,比如 Facebook 随即提出 DeiT [2]、微软提出 BEIT [3]、SwinTransformer [4]、清华提出 DynamicViT [5]等,这些工作基本都是在原始 ViT 的基础上优化预训练策略、模型结构(层次化、动态化)等来提升效果。
因此这里图片语种识别的方案也是基于 ViT,并且在 ViT 基础之上做了模型结构层面的加速优化提出 ShrinkViT。
2.1.1 ViT
原始 ViT 结构如下图(源自[1]):
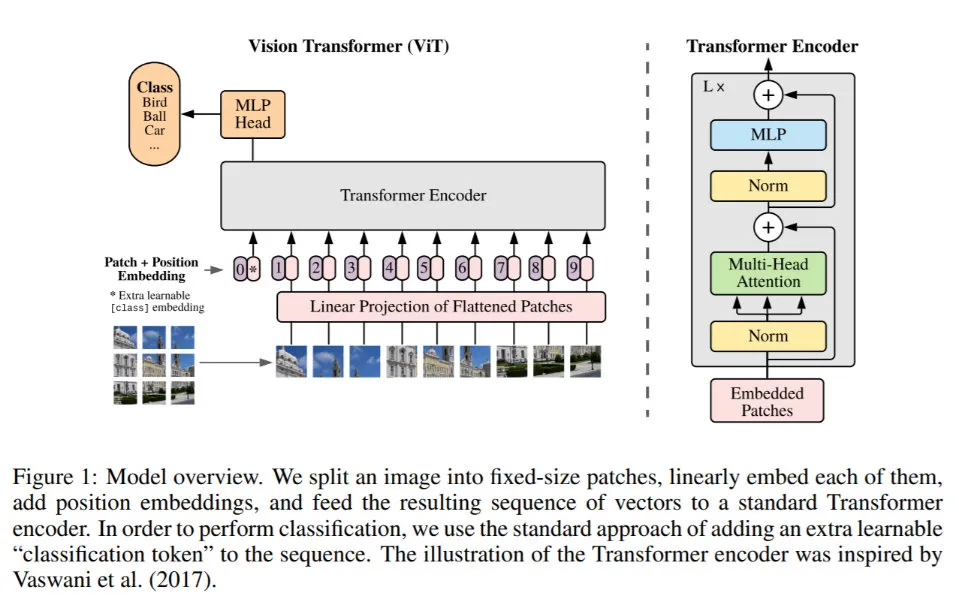
这里简要介绍 ViT 的 forward 过程:
- 将原始图片切分为固定大小(如 16 16\\ 3)的 patches。
- 对于每一个 patch 进行 Conv 转换,输出 representation 作为 patch token embedding。之后的操作类似于 NLP 中 Transformer 对于 QKV 的操作,线性映射 + position embedding。
- Patches 序列头部增加分类 cls token,之后对 cls token + patch sequence 进行多层 Transformer block 操作(Multi-Head-Self-Attention)。
- 拿到 cls token 的 final representation 作为图片的表示,经 MLP + softmax 分类。
我们基于开源的预训练 ViT 模型 [7] 在图片语种分类数据集进行 finetune,相比从 0 开始训练效果更好,头部语种 F1-score 可以达到 90% 以上,并且训练可以快速收敛。
2.1.2 ShrinkViT
可以看到 ViT 需要对原始图片每一层的 patch token sequence 进行 self-attention,计算量是 平方 复杂度,线上耗时压力较大。而对于图片语种识别任务来讲,我们只需要关注图片中有文字的 patch 即可(如下图例子中红色圈对应区域)。

因此很自然的想法是在训练过程中动态控制 patch tokens 的长度,将非文字的 patch 过滤掉,不参与后续的计算。工作[5] 也是基于此策略来优化提出了 DynamicViT,但是论文中的方法需要显式过滤的 patch 采用了离散的操作,导致了训练梯度无法传递的问题,同时论文中基于传统 CNN 大模型作为 Teacher 模型来蒸馏学习 ViT Student 模型较为复杂,不易复现。
这里借鉴 CNN 中 Conv 操作考虑图片局部特性和参数共享带来的转换等变性,我们考虑结合 Conv 操作到 ViT 中来提取 high level patch representations,同时在 Conv 过程中可以通过 kernel size 控制生成 patch 的数量,在保证信息不丢失的同时达到缩减 patch tokens 数量的目的,我们命名为 ShrinkViT。
ShrinkViT 对比 ViT 的模型结构如下图所示:
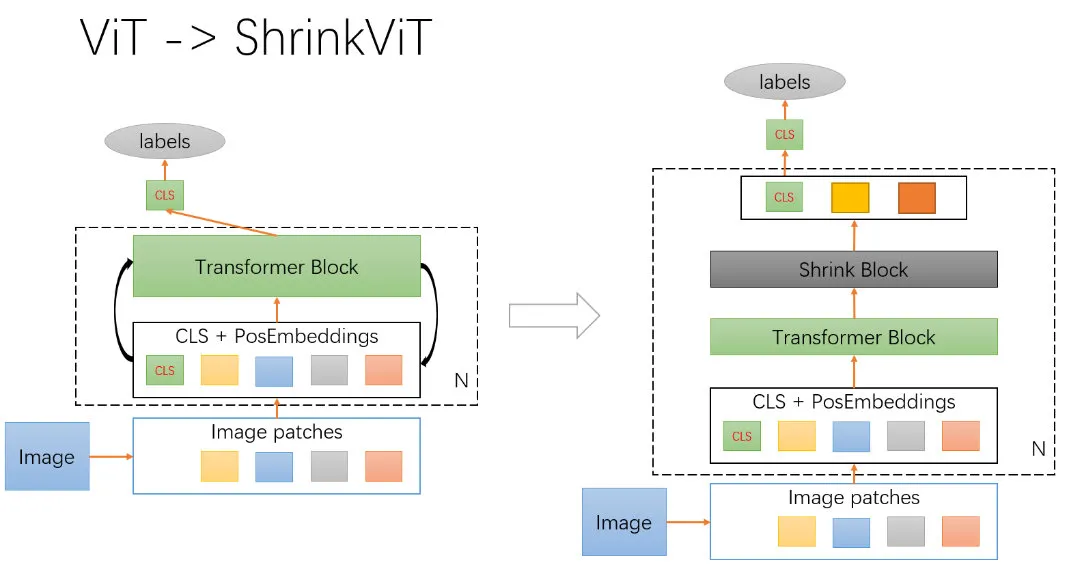
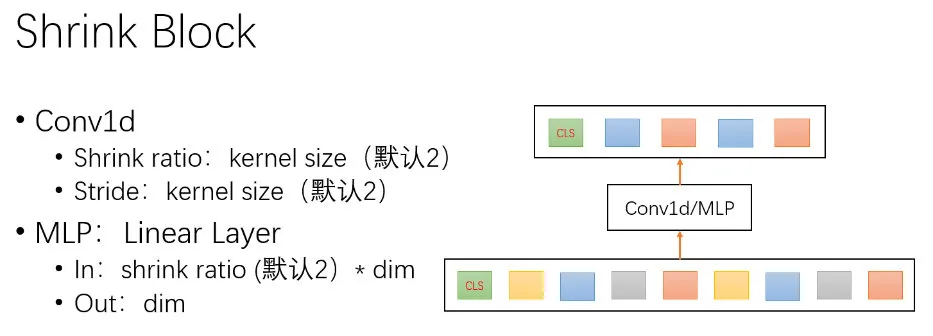
这里我们在原始 Transformer block 结果之后增加 Shrink Block,可以通过 Conv1d 实现(也可以通过 MLP 实现),如下图所示:
 实际当中,考虑模型的效果不一定每一层都需要加 Shrink Block,基础的 ViT depth=12,以下结果是我们在 3、6、9 层分别加入 Shrink Block 的离线实验结果:
实际当中,考虑模型的效果不一定每一层都需要加 Shrink Block,基础的 ViT depth=12,以下结果是我们在 3、6、9 层分别加入 Shrink Block 的离线实验结果:

注:ViT 采用 base 结构(patch_size=16, embed_dim=768, depth=12, num_heads=12)。从以上结果可以看到,引入 Shrink Block 在保证模型效果的同时,模型参数仅少量增加(3MB),但是计算量减小到原来的一半(**49** **GFLOPs -> 24 GFLOPs** ),耗时也相对减少(**14ms -> 8ms** )。优化之后的 ShrinkViT 目前已部署上线,GPU 服务耗时减少**30ms** 。
2.2 图片段落框检测
目前 OCR 的结果是在 行粒度 进行文字检测和识别:
- 如果直接利用行粒度的识别结果做下游的翻译任务,出现的问题是:单个行的文本信息不完整,导致翻译结果信息缺失、难以理解。
- 如果全部文本整体调用翻译的话,一方面文本内容过长可能导致翻译超时 or 翻译结果中错误累计等问题,另一方面翻译之后的结果无法很好的拆分,保持跟原文的一一对应关系,最终展示排版结果较差。
因此在 OCR 之后,基于 段落粒度 来进行结果合并和下游翻译、图文合成等任务。这里 段落 主要是定义为文本内容完整且位置独立的文本区域。如下图绿色框表示(两张图分别包含了 4 个和 3 个文本段落):

2.2.1 图片文档分析
图片的段落框检测可以属于图片文档分析(Document Image Analysis,DIA,包括如图片文档分类、文档版面分析、表格检测等)中的任务之一,近年来业界相关的工作有 LayoutParser [11]、LayoutLM [13,15]、LayoutLM2 [12,13]等。
LayoutParser 是基于 Facebook(Meta)目标检测框架 Detectron2 [14]搭建的图片文档版面分析工具,基于开源数据集提供部分预训练模型。但是主要问题是开源的数据集和模型基于单一场景数据,如表格、学术论文、新闻报纸结构等,而且多数框是基于 4 点坐标,不能满足实际复杂业务场景。
LayoutLM 和 LayoutLM2 等是 Microsoft 提出结合图片和文本的图片文档版面分析预训练模型(参考 BERT 和 Transformer),如下图(图片分别来自[15]、[12])所示:
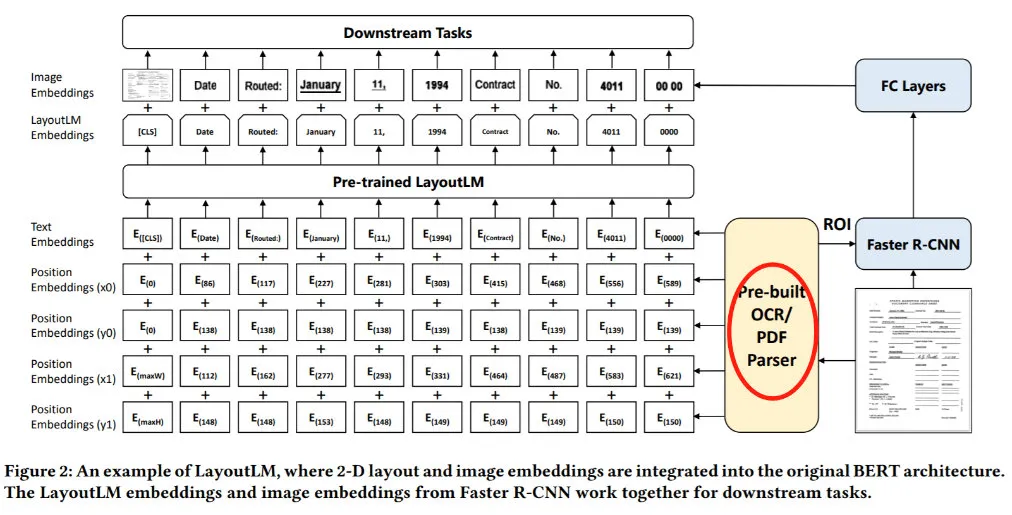
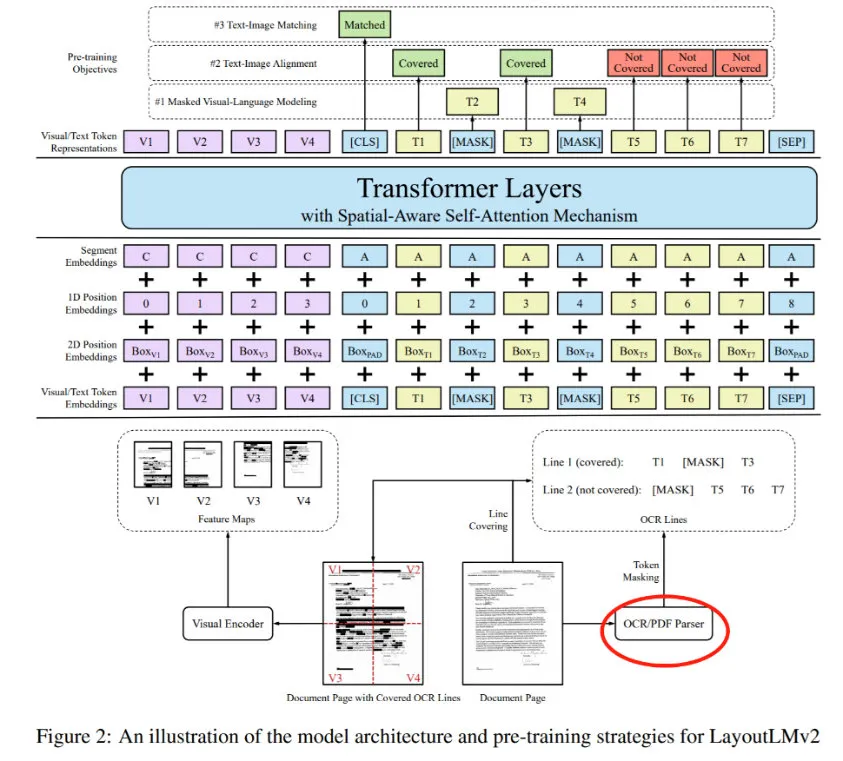
LayoutLM、LayoutLM2 等第一步需要提取 token level 的文本和对应 bounding box 信息, 数据预处理 代价较大。
2.2.2 DBNet段落框检测
综上,这里我们借鉴 LayoutParser [11]的方法,来做段落 level 的文本框检测。考虑到段落框可能是任意形状(多边形),这里采用基于 分割 (segmentation-based)的 DBNet [9],主体结构如下图(源自[9])所示:
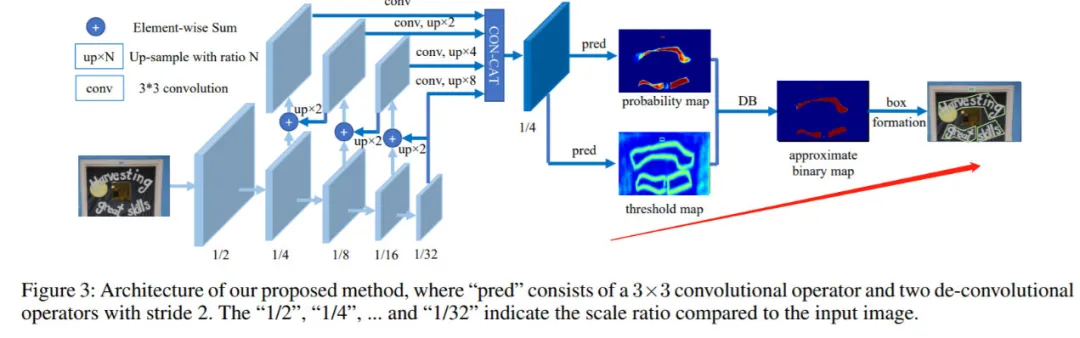
直接利用 DBNet 训练段落框的检测模型,相比文本行的检测,实验中我们发现有以下的问题:
- 文本行一般是规则四边形,4 点坐标即可表示,而段落框更多是 不规则多边形 、需要任意多点坐标才可以完整表示。
- 在 probability map 训练中,文本行标注数据中框中的像素点作为正例样本,但是段落框中存在背景像素点(如段落中文本行之间的空白区域、段落标注中的噪音区域等),导致训练效果不佳。
- 检测任务中一般对于文本框区域进行一定比例的向内收缩(如 DBNet 中 shrink ratio 设置),主要是解决相邻文本行比较相近的问题,收缩之后的预测结果可以更好的分割相邻行,对于检测结果再进行反比例的扩展。而 段落框本身 和 段落框之间的距离 相对文本框大很多,因此 shrink 的影响对于段落框较大。
- 基于分割的检测模型通常都需要 后处理 逻辑选择最终的结果,原始 DBNet 的后处理逻辑对于复杂多边形的情况在 多边形近似 和 候选打分处理 过程存在误差,导致生成的段落框不够精确。
- 文本行基于单行数据,不需要考虑行的图像属性,比如字体风格,行的高度等。但是对于段落框,不同风格的段落往往属于不同的段落(如标题和正文)。
因此,这里在 DBNet 的基础之上,我们在训练样本 label、模型参数、模型结构 Loss、后处理逻辑等方面进行了相应的优化:
- 段落框的训练标注数据 label 采用多点坐标,并且标注坐标尽量贴合原始文本区域,避免引入更多的背景像素。
- 训练过程中段落框 shrink ratio 调高到 0.9,使得预测 probability map 尽量贴合原有文本区域大小,减少 shrink 的影响。
- 在调大 shrink ratio 的同时需要加大 threshold map(即段落框边界)loss 的权重,使得模型更好的分割段落。
- 优化 DBNet 后处理逻辑,加入图片腐蚀操作并且动态调节多边形近似参数,保证预测段落框的轮廓更加精确。
- 在原有 probablility map 和 threshold map 的基础之上预测段落中行间分割 map,用于后处理中分离不同风格(行高)的段落框。
整体上在引入上述(1)(2)(3)(4)(5)的优化,实验中段落框的检测效果(h-mean 值)效果提升显著,达到预期可用的结果。优化前后的 段落框检测 结果对比样例如下图:

2.3 文本段落矫正
上述段落结果主要是基于 视觉信息 (图像层面)来做段落的检测,但是在实际 case 存在一定的情况,需要从 文本 的角度做进一步的段落检测。如下场景:
- 视觉上不属于同一段落,但是从文本语义角度判断属于同一个段落,如下图中上半部分两块文字区域。
- 视觉上属于同一个段落,但是从文本角度判断应该拆分为不同的段落更好,如下图中选择题部分,对于序号 1. 2. 3. 或者 a. b. c. 起始的段落需要保持原有的段落顺序,因此拆分为不同的段落更加合理。
- 另外在视觉模型效果存在误差的情况下,基于文本的段落模型可以提供额外的参考。

因此,这里我们构建了基于 文本(语义) 层面的段落检测模型,对段落结果进行一定程度的矫正。
文本段落检测即判断给定的两个文本片段(非完整句子)是否应该拼接组成一个段落。相关的方法主要有以下:
- Language Model:计算两个文本的语言模型打分,问题是需要人工设定阈值规则,不够通用。
- Sentence Ordering:建模两个句子的顺序,默认是完整的句子,预测不同的连接词,场景不适合。
- Sentence Generation:重新生成新的文本段落,seq2seq 生成模型,往往引入新的生成错误,且速度较慢。
上述相关的方法一定程度都不适应于文本段落任务,因此我们直接通过 文本分类 任务来判断两个文本 span 是否属于一个段落。
2.3.1 BERT 文本段落分类
得益于开源大规模预训练模型如 BERT [9]在各类 NLP 任务中取得 SOTA 的效果,因此这里我们基于开源 BERT [10] finetune 搭建文本段落分类模型。对于两个任意文本 span:[w11 w12 w13 … w1n]、[w21 w22 w23 … w2m],将其拼接为[CLS w11 w12 w13…w1n SEP w21 w22 w23…w2m SEP]作为原始输入。如下例子:
[CLS] sector follow [SEP] the industry [SEP]
[CLS] several members represent the irish national [SEP] india , aboard the [SEP]
之后进行 BERT Encoder,在输出层拿到 CLS token representation 与 output weights 矩阵计算,之后计算 Softmax 得到各个 label 的概率分布。整体结构如下图:
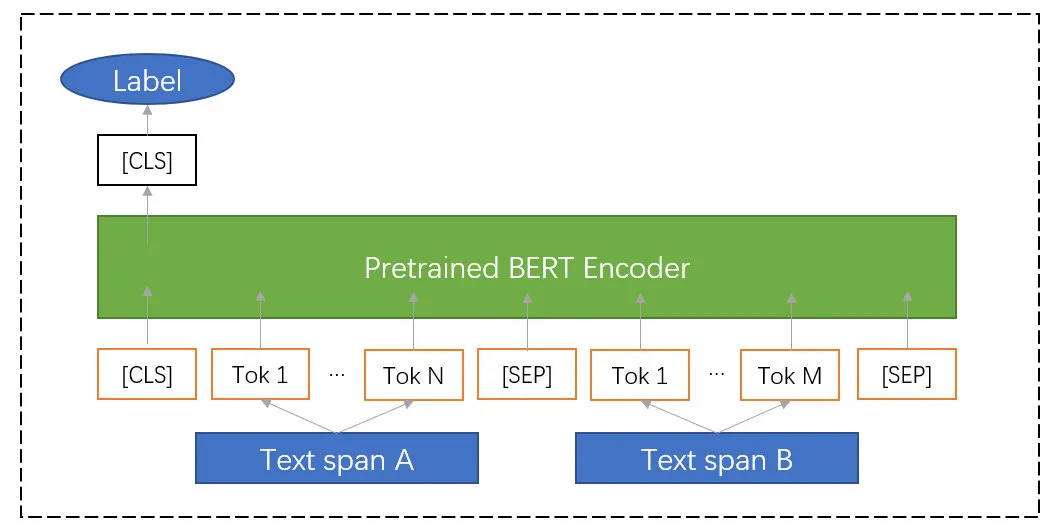
训练数据方面,我们基于开源大规模 wiki 单语语料数据构造大批量的伪数据作为 BERT 分类器初始训练数据,之后在有限的标注数据进行 finetune。整体分类 Accuray 在 90% 以上。
有了基于 BERT 的文本段落模型之后,在原始段落的基础上,我们对其进行矫正,基础的矫正策略如下:
- 判断同一个文本框相邻文本是否不属于同一个段落,若是则进行段落拆分。
- 判断不同相邻文本框相邻文本是否属于同一个段落,若是则进行段落合并。
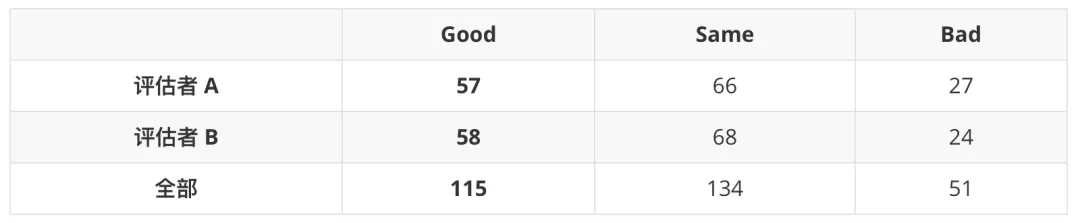
整体上,增加文本段落模型之后,我们对于图片翻译整体效果进行了端到端的 GSB 评估,相比没有文本段落模型的结果如下(随机采样 100 张图片人工评估):

如下例子:

其中第一张图片中 BERT 段落矫正模型可以将原属于同一图片段落的文本(“In-Store Pickup Sep 24” 和 “iPhone 13 Pro Max”)拆分为独立的两个段落。第二张图片中可以将原属于不同段落的相邻文本(“the information contained in your CAS” 和 “STATEMENT below when making your student”)合并为同一个段落,因此整体上翻译效果和排版更好。
从 GSB 的结果看出,文本段落模型对于图片文本段落框划分以及最终的图片翻译质量有明显的提升。
另外我们也尝试了其他模型结构(如 BERT 双塔结构分别建模两个 text span、BERT 建模 text 对应 bounding box 信息),相比基于 text pairs 拼接的 BERT 模型有一定的提升。不过因为模型结构的复杂带来额外的计算耗时,上线还需优化。
2.4 段落翻译
接下来需要对应每一个段落翻译为目标语言的文本,这里段落之间是并行调用翻译服务。
但是在实际场景中,可能某一些段落较长,比如超过 1024 个 tokens,一方面可能导致翻译超时、另一方面由于翻译模型采用 NMT seq-to-seq 结构,文本越长,错误累计越严重等问题。因此这里我们在请求翻译服务时对于过长的段落文本进行拆分为多个子句进行翻译,翻译之后再将结果进行合并。
2.5 图文合成渲染
图片翻译的最后一步则是将翻译完成的文本段落贴回原图所在区域,即图文合成过程。但是在合成过程中需要满足如下要求:
- 翻译文本与原文保持图片区域一致,即位置关系对应。
- 翻译文本与原文风格排版保持一致,如字体大小、文字颜色、背景色等属性。
- 合成图片排版清晰、翻译结果可读等。
从文章最开始微信图片翻译 1.0 版本的 badcase 可以发现,图文合成的结果对于最终的图片翻译体验尤为重要。与正常图文合成不同,这里第一步需要擦除原图文字内容、保留原图的背景,之后将翻译文字贴回原图位置,而且文字清晰可阅读。
2.5.1 Image Inpainting
从图片中擦除文字内容,且保留背景可以作为一种 图片修复 (Image Inpainting [16])任务,首先对于图片中的文字区域进行 mask 选定,之后对于图片中的缺失内容(mask 区域),进行重构恢复原有背景。
常用的 Image Inpainting 方法主要是生成式模型,如 GAN、VAE、Flow-based models、Diffusion models [17,18]。GAN 的效果和应用最广泛,主要挑战是比较难训练,VAE 和 Flows 在特定领域效果不错,但是质量和广泛性不如 GAN,Diffusion models 最近得到比较多的关注,在语音合成(speech synthesis)方面接近人类的水平。另外在部分图片生成、超分辨率任务中超越 GANs [18]。这几类生成模型对比如下图(源自[17]):
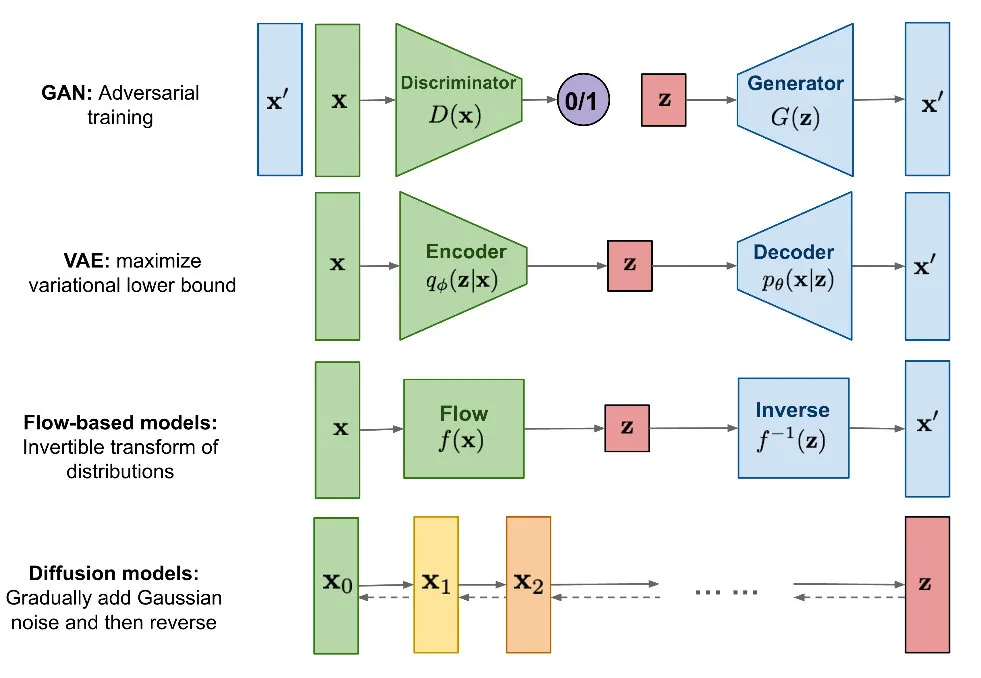
这里我们首先尝试主流基于 GAN [19,20] 的方法,基于 文本框和文字轮廓 分别标记文字 mask 区域,之后根据 Generator 网络重构生成 mask 区域,例子如下:
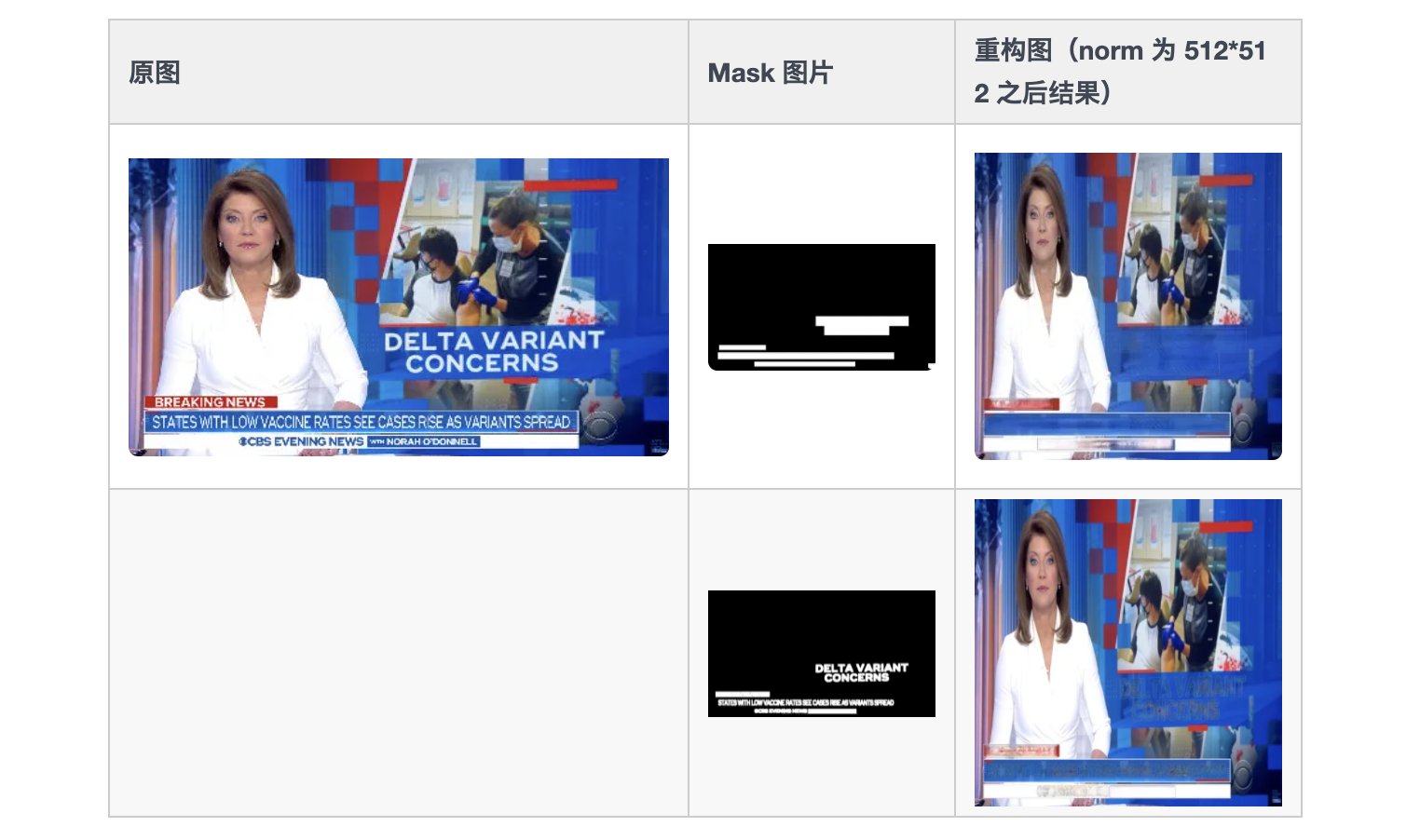
可以看到,上表第一行基于 bounding box 的 mask 图片,对于大范围单一背景(如蓝色背景)区域,GAN 的重构效果可以接受,但是对于复杂背景(如红色背景白色字、底部混合背景颜色排列)的重构效果比较差(多种背景色混合)。第二行基于文字 mask 的结果,生成式的 Image Inpainting 方法重构的区域依旧存在原文字轮廓模糊噪音、不够平滑。在图片翻译场景特别是要求背景和文字 对比清晰 的情况下,目前的模型效果不太适用。以下简单列举通用生成式 Image inpainting 方法不适用于本任务的原因:
- 图片翻译中待修复的背景色偏向 单一色 (如上图蓝色、红色、白色),与字体颜色对比鲜明。而传统 image inpainting 背景目标复杂多样。
- 图片翻译中待修复的背景偏向 按行(按列) 规则分布。而传统 image inpainting 任意形状分布。
- 图片翻译的结果同样要求背景色保持单一,与译文字体颜色对比鲜明。而传统 image inpainting 无此要求。
- GAN 等生成式模型在图片修复中 Conv 操作 会引入上下不同的行/列的信息,因此导致按行(按列)分布的背景引入周边行(列)的噪音数据。
而且 end2end 模型不方便动态调整,另外如果考虑重新训练模型,数据资源目前比较缺失。
2.5.2 基于 OpenCV 的图文合成
结合目前的实际情况,对于图片合成文字过程,考虑到基于 OpenCV 来实现第一版效果,拆分为多个步骤,可以灵活调整结果。主要步骤如下表:

2.6 结果评估&体验
微信图片翻译 2.0 版本主要优化目前已上线,同样以文章开头图片为例展示 2.0 版本的效果对比如下表所示:

从以上结果可以看看到,相比 1.0 版本,微信图片翻译 2.0 版本在文本段落识别、翻译质量和图文合成排版等多方面的体验得到了较大的提升。
同时对于微信图片翻译 2.0 和 1.0 版本,人工评估 GSB,2.0 版本提升显著,结果如下:
图片翻译 2.0 版本已上线到微信 iOS 客户端,体验方式:微信聊天框点击图片选择翻译、扫一扫图片翻译等入口,如下图:

另外对于新 2.0 版本图片翻译与旧 1.0 版本进行了线上真实用户的 ABTest,2.0 版本相比 1.0 版本,单个用户平均图片翻译文本句段增加 21% 。
数据反应出随着新版图片翻译各方面质量的提升,用户的翻译行为也变的更加活跃。后续 2.0 版本将灰度到全量微信用户。
3. 总结
本文主要是整理了微信图片翻译 2.0 版本近一年的各项优化,从 1.0 版本的问题出发,结合业务实际情况和前沿研究方向,诸如将 ViT 应用到图片 语种识别 &加速优化、基于分割的 DBNet 应用到 段落框检测 优化、基于 pretrained BERT 应用到 文本段落 分类优化,基于 OpenCV 在后端实现 图文合成 渲染等。而且新版本上线之后,用户的翻译行为得到明显提升。未来微信翻译将继续优化,提供更好的翻译服务。
4. 参考文献
- ViT:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- DEIT:Training data-efficient image transformers & distillation through attention
- BEIT: BERT Pre-Training of Image Transformers
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
- Attention is all you need
- https://github.com/facebookresearch/deit
- DBNet:Real-time Scene Text Detection with Differentiable Binarization
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 开源 BERT: https://github.com/google-research/bert
- LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
- LAYOUTLMV2: MULTI-MODAL PRE-TRAINING FOR VISUALLY-RICH DOCUMENT UNDERSTANDING
- https://github.com/microsoft/unilm
- https://github.com/facebookresearch/detectron2
- LayoutLM: Pre-training of Text and Layout for Document Image Understanding
- https://paperswithcode.com/task/image-inpainting
- [https://lilianweng.github.io/lil-log/2021/07/11/diffusion-models.htm
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E6%8A%80%E6%9C%AF%E5%BE%AE%E4%BF%A1%E5%9B%BE%E7%89%87%E7%BF%BB%E8%AF%91%E6%8A%80%E6%9C%AF%E4%BC%98%E5%8C%96%E4%B9%8B%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


