解密商业化广告投放平台技术架构
转载自 DataFunTalk 社区 大家可以关注他们的公众号, 内容很干货
导读: 互联网广告是流量商业变现的重要途径之一,涉及服务平台、检索引擎、算法策略、数据工程等多个方向。本次分享的主题为商业化广告投放平台技术架构,分享的内容集中在工程领域,结合业界广告投放平台的通用技术范式,分享智能营销平台是如何打造高性能、高可用、可扩展平台架构的,从服务化、数据传输分发、广告投放引擎、计费、海量数据实时报表等方向切入,深入浅出的阐述一套最佳实践。
——业务介绍——
1. 广告业务简介

商业化是互联网公司营收的重要来源,业界比较大的商业化产品有 Google AdWords、Facebook Ad、百度凤巢、头条巨量引擎、腾讯广点通等产品,阿里电商场景的变现平台是阿里妈妈。目前国内互联网广告的营收年规模达数千亿元。
广告平台一般由三方组成:网站主、广告主、用户。
- 网站主: 有流量资源的变现需求。
- 广告主: 有投放预算,希望在流量资源上找到合适的人进行推广。
- 用户: 得到更好的广告推荐结果。
2. 智能营销平台简介 & 通用的广告系统组成
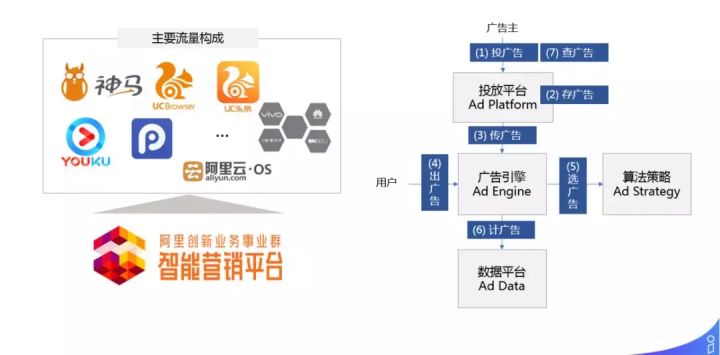
阿里创新事业群智能营销平台的主要流量构成包括:神马搜索、UC 浏览器、UC 头条、优酷、阿里云 OS 以及手机厂商、网盟第三方流量等。
通用的广告系统组成如右图,主要包括4部分:投放平台、广告引擎、算法策略、数据平台。
运转的流程如下:
首先,广告主有一定的预算,选择在什么样的流量上投广告,这样就有了输入;然后存广告,通过投放平台来完成,把投放所需的设置、预算、创意等数据实时传输到检索系统;每当用户发起一次检索请求时,简单来说后台相当于做召回+优选,把最合适的 TOP 候选广告返回给用户;还有一部分是计广告,通过数据平台来完成;最终广告主来查广告绩效展点消数据。
本次分享主要聚焦在如下5个环节:

——投广告——
业务微服务化构建
第一,来看如何投广告,包括无状态的服务层,来满足广告主进行预算设置、存广告、建创意等操作诉求。
1. 单体模式到微服务化 ( MSOA ) 的过渡
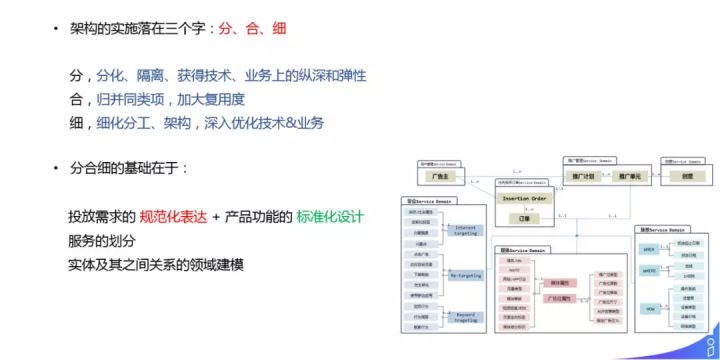
任何一个大的产品,都会遇到从单体过渡到微服务的过程,其架构的实施方法论落在三个字:分、合、细:
- 分: 分化、隔离、获得技术、业务上的纵深和弹性。
- 合: 随着业务的增长,要加大复用度,归并同类项。
- 细: 细化分工、架构,深入优化技术&业务。
当业务发展到足够大的时候,最终会采用 MSOA 架构。
分合细的基础在于:如何把这些服务给拆开,对于投放平台来说,需要对投放需求进行规范化的表达和产品功能的标准化设计。把这些领域模型建起来之后,服务自然就有了划分的依据。
2. 微服务化分层体系建设
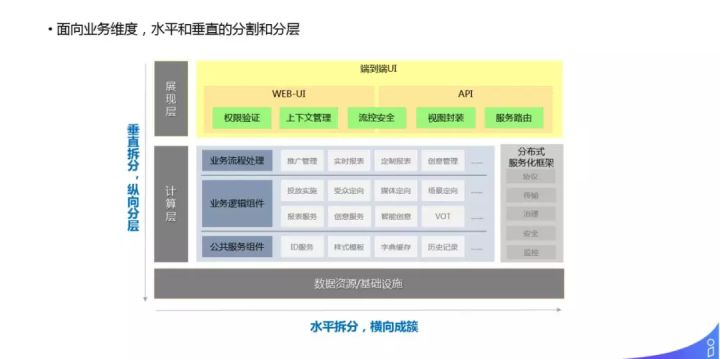
上图为拆分之后的投放服务架构图,水平拆分成簇,纵向拆分成层。外层是 API 和 WEB 端,进行相应的权限验证、流控等;中间为计算层,细分出来各个服务,包括面向业务流程处理、业务逻辑组件以及公共服务组件三层;最底层是基础设施和数据资源。把所有的服务串联起来的就是分布式服务化框架。
3. 微服务化与服务治理
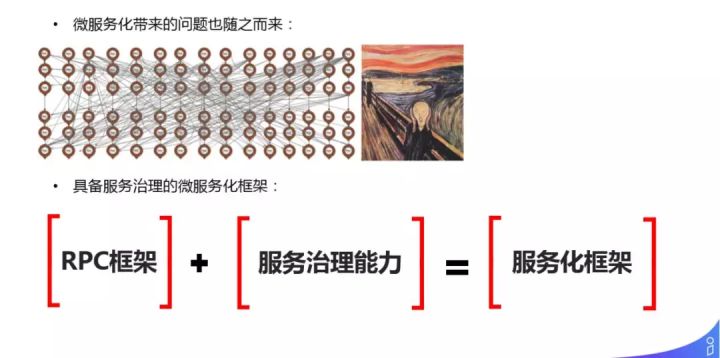
做平台方向的团队可能需要几十人上百人,而服务则可能有几十上百个,它们所组成的网络会非常混乱,最终难以治理。我们需要具备服务治理能力的微服务化框架来解问题,包括 [ RPC 框架 ] 和 [ 服务治理能力 ]。
4. 分布式服务化框架一览

业界的分布式服务化框架一览,如上图所示。这里有的是 RPC 框架,有的才是真正合格的服务化框架,对于投放平台,需要的是一个服务化的框架。我们拆分来看,先认识下 RPC 框架:
① 体系化认知 RPC
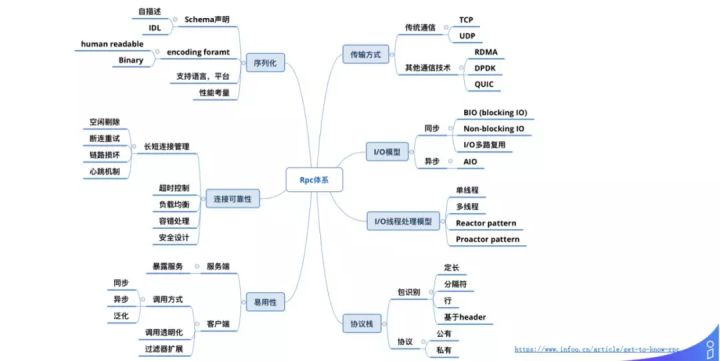
RPC 体系的脑图如上所示,作为 PRC 框架应具备如下功能:
1. 传输方式:我们要看是采用的传统 TCP 或者 HTTP 技术,还是运用的最新技术,如阿里很多基础产品是用 RDMA 网络的,或者采用一些用户态的协议,不走 TCP 协议,来做 kernel bypass。
2. I/O 模型:是采用同步还是异步的,可以选用 Blocking IO 或者 Non-blocking IO,I/O 多路复用最有名的是基于 epoll 的,大部分走 TCP 协议的都采用的是 epoll;异步的 AIO 网络通信在 Windows 下用的比较多,在 Linux 上 AIO 主要应用在磁盘 IO 相关。
3. I/O 线程处理模型:可以分为单线程、多线程,以及各种 pattern,大多数情况下都会选择 Reactor pattern,基于 I/O 多路复用 epoll 这种形式。
4. 协议栈:数据可以点对点传输之后,如何识别这些数据,主要就是协议栈的工作。大多数框架都采用基于 header+payload 的方式。
5. 序列化:当点对点的实时的识别出一个具体的包之后,需要序列化的解析包里的数据。
6. 连接可靠性和易用性:可以快速的传输和识别包之后,还要面临可靠性的保证,以及暴露给上层的调用方式,如何更好的调用服务,是用同步、异步,还是泛化调用类似的问题是需要考虑的。
这些范畴,共同组成了 RPC 体系,但是光有这些是不足的,最终还要落在服务治理上:
② 服务治理能力
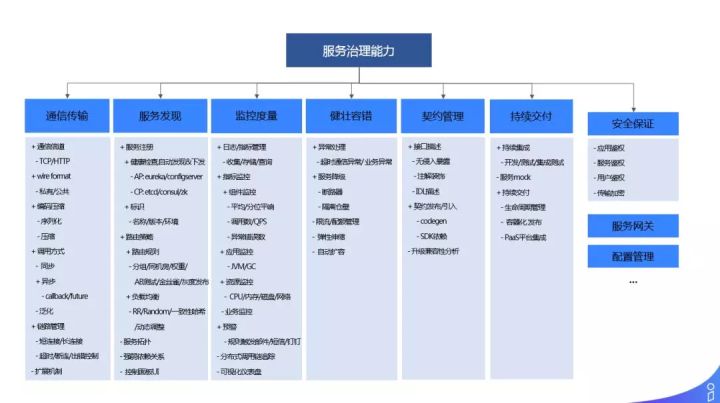
服务治理能力包括:
- 通信传输:这是最基本的。
- 服务发现:包括服务注册,自动的下发和发现;客户端路由的规则,是同机房路由还是打标分组路由;以及负载均衡的策略,是 RR 还是 Random 等;有了这些之后,可以做服务的拓扑和强弱依赖分析。
- 监控度量:从 logging、tracing、metric 三个维度进行监控。
- 健壮容错:如何 design for failure 做处理异常,做服务的降级和限流。
- 契约管理:管理服务的 IDL 以及进行兼容性分析。
- 持续交付:开发测试,整个应用的生命周期管理,更多的是与 PaaS 平台相结合。
- 安全保证:应用鉴权、服务鉴权、用户鉴权、传输加密等。
通过这些模块,共同构成了服务的治理。
现阶段我们的服务治理方案如下:
- 服务化框架:HSF
- 容器隔离:Pandora-boot
- 配置管理:基于 Diamond
- 监控度量:Metrics+Tracing+Logging ( ARMS+SLS+鹰眼 )
- 健壮容错:Sentinel
- 基础设施:基于 K8S 的云平台
- 持续交付:基于 Aone 的 Paas+CD 平台
发展未来上来看,云原生是一个方向,代表了先进的生产力,这当中服务的架构设计、开发交付都会被重塑,一些变化主要在于:
- 资源效率:重点在于容器化、调度、混部。
- 开发效率:注重编排、敏捷 CI/CD;Service Mesh、Serverless 等基础设施的下层和 business logic focus 的专注。
- 标准与开放:开源、社区和生态的建设。
个人理解: 万变不离其宗,云原生解决的问题覆盖了服务治理,天然的利用 “云” 去解决,而非某个框架或者 vendor lockin 的能力。
——存广告——
OLTP 海量数据存储
1. 广告数据存储
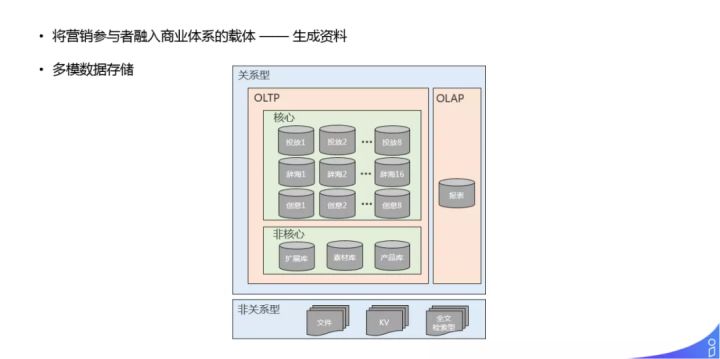
数据存储可以看做有状态的存储层,要把这些生产资料,存在广告系统中。我们采用的是多模数据存储的方式,OLTP 大部分都是 MySQL 分库分表,OLAP 有相应的报表平台,非关系型的有 OSS、KV 存储以及基于 ES 的全文检索。
2. 体系化认识数据库
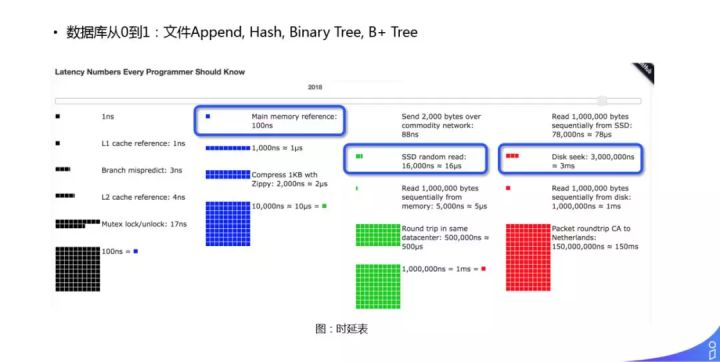
如果数据库从0到1开始做,最简单通过一个文件把相应的字段存起来,可以用到的数据结构有:Hash,Binary Tree,B+Tree。但是采用这些方式,会面临着不同的时延问题,如图所示:访问内存大概是 100ns,访问 SDD 大概是 16μs,但是一次 Disk seek 需要 3-10ms。所以,为了减少随机 IO,Hash 和 Binary Tree 都是不合适的。因此,有了 B+Tree 这种 MySQL 使用的索引数据结构。
① MySQL InnoDB 引擎
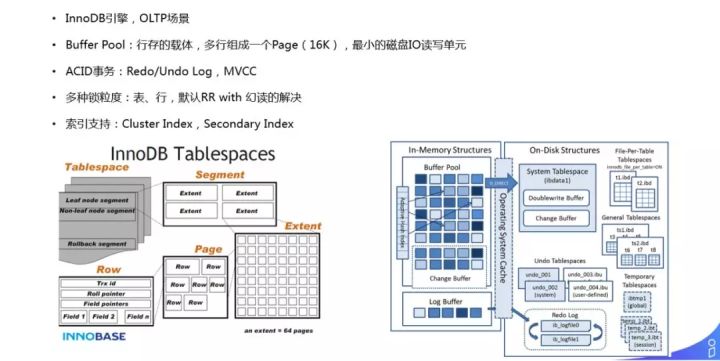
我们大部分数据都是 MySQL 存储的,且采用的是 InnoDB 引擎,主要面向的是 OLTP 场景。InnoDB 引擎是行存,多行组成一个 Page,多个 Page 组成一个 Extent,而每个索引的叶子节点和非叶子节点又由 Segment 这个概念维护,最终形成了一张表 ( tablespace )。每次检索实际就是按照刚刚提到的 B+ Tree 做点查或者范围查询,可以走 clustered index 或者 secondary index 或者 full scan。
我们不止要把数据存起来,还需要有 SQL 和 ACID 功能,Durability 是靠 Redo Log 来做的,保证数据不丢失;还要满足 Isolation,也就是事务之间是有并发的,并且要进行隔离,不能互相影响,采用 Undo Log+MVCC 机制来实现。InnoDB 还有很多好处,比如它是基于行锁的,有索引的支持等。右图为 MySQL 官方的架构图,大家可以官方查询下资料。所以,通过 MySQL 可以把广告数据高并发、可靠的持久化存起来。
② 阿里云自研 X-Engine 引擎
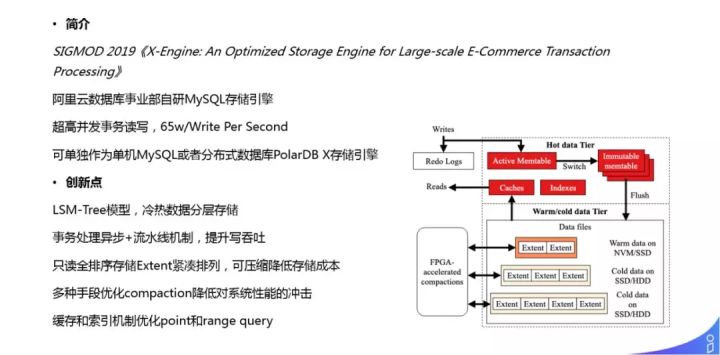
在海量数据高 TPS 场景下,阿里也在做一些优化。这里介绍下 X-Engine 引擎,阿里在 SIGMOD 2019 发表的一篇论文:《X-Engine:An Optimized Storage Engine for Large-scale E-Commerce Transaction Processing》,X-Engine 可以实现超高并发事务的读写,可以达到 65w/Write Per Second,读的话和 InnoDB 差不多,主要是优化写的方向;可单独作为单机 MySQL 或者分布式数据库 PolarDB X 存储引擎。马上在阿里云上就可以看到云上产品。X-Engine 的创新点,如图所示,这里不再细说。
3. 数据库存储架构
① 可扩展
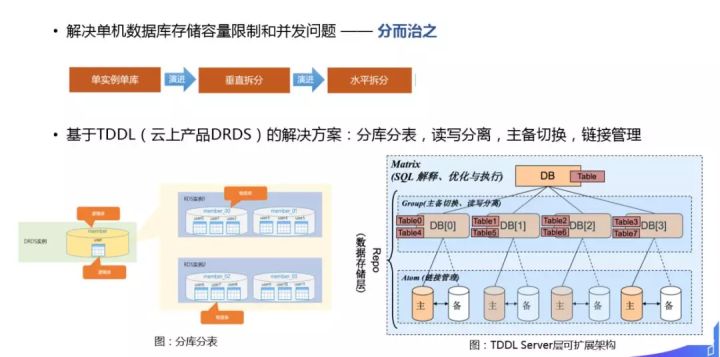
刚刚介绍了存广告的基础,由于广告产品产生的数据量非常大,尤其是搜索广告的关键词维度,基本都是百亿的量级,如何做扩展,是一个很重要的问题。常用的解法是 分而治之,做垂直拆分和水平拆分。
我们是基于 TDDL ( 云上产品 DRDS ) 的解决方案,来做分库分表,读写分离,主备切换以及链接管理的。
② 高可用
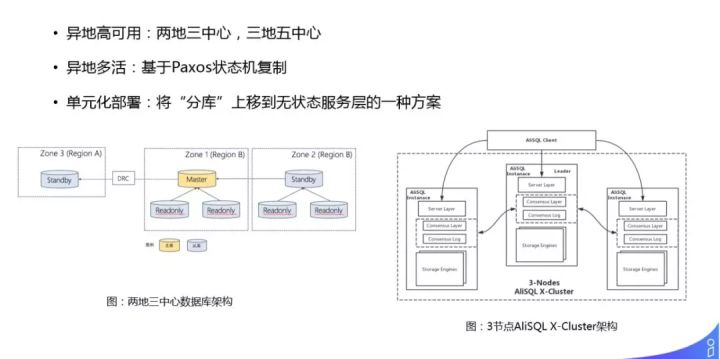
对于数据库高可用的保证,常常采用:
- 异地高可用:两地三中心 ( 如左图,主库和备库都在同一个 Region B 中,但是它们分了两个机房来做相应的同步,同时通过 DRC 把数据异步的传到另外一个 Region 中,这两个 Region 可能距离非常远有上千公里,所以是两地三中心的架构 ),可以扩展成三地五中心。
- 异地多活:基于 Paxos 状态机复制,可做跨地域一致性保证。
- 单元化部署:将 “分库” 逻辑上移到无状态服务层的一种方案,某一批用户被固定路由到某个地域,一套产品形成若干个封闭单元。
③ 一致性
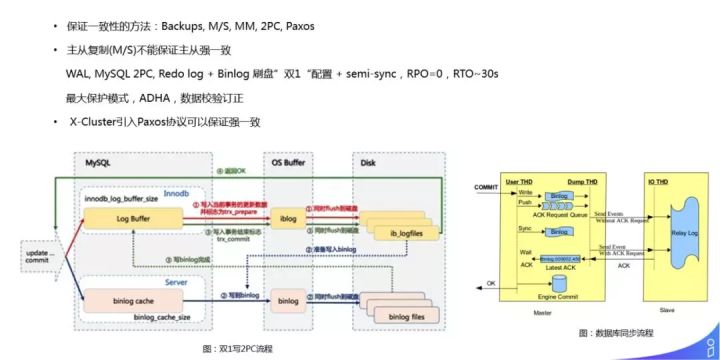
基于传统的 MySQL 主从复制机制,使用 “双1”+semi-sync 的保守配置,还是不能保证主从一致性,如图所示这里不再赘述。为了解决这个问题,我们有很多的 workaround,如开 MP 最大保护模式,强制主从必须同步,或者阿里内部有很多工具,例如 ADHA 来做主从切换的保证,以及数据的校验订正等。现在流行的优雅解决方案还是要依赖于 Paxos 协议保证多副本强一致,例如阿里云金融级 RDS。
4. 分布式数据库发展趋势
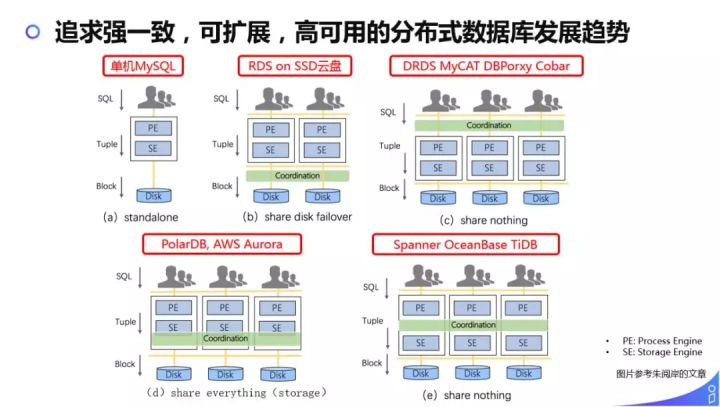
追求强一致,可扩展,高可用的分布式数据库的发展趋势主要分为5个阶段:
(a) Standalone -> (b) share disk fallover -> (c) share nothing -> (d) share everything -> (e) share nothing
目前我们处于基于 share nothing 架构的 DRDS 来实现,业务体量到达一定规模的时候,未来一定是朝着高扩展性、高可靠、成本优先的方向发展的,我们也会持续跟进数据库行业的发展,做更好的技术演进和选型。
——传广告——
广告传输流建设
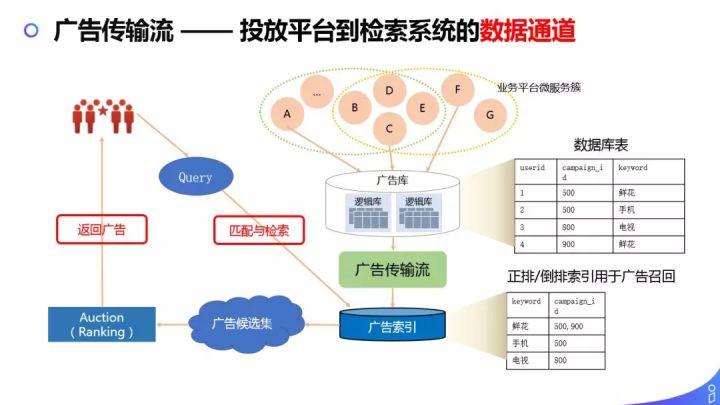
现在广告已经投完了,并且存在了数据库中,接下来就要把广告实时传输到检索系统。如上图,大致介绍了传输流。刚刚提到的服务层,可以有服务治理,广告库存在 MySQL 中,我们通过传输流实时把数据传输到检索端,做建库到广告索引中,以搜索场景为例,用户发起一个 query,需要匹配与 query 相关所有的广告,生成候选集,再进行相应的 Auction 和 Ranking 工作,最终返回给用户1条或几条广告。所以广告传输流非常重要,传输的是召回候选集的生成资料,是连接业务系统和检索系统的关键链路。
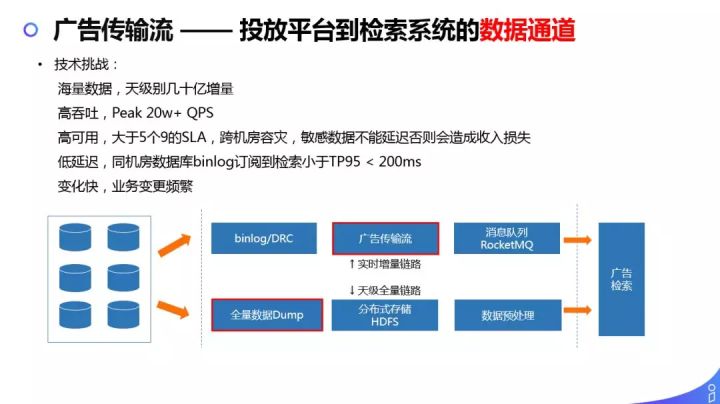
这条链路上,我们面临的挑战有:
- 海量数据,天级别几十亿增量。
- 高吞吐,Peak 20W+ QPS。
- 高可用,大于5个9的 SLA,跨机房容灾,计划下线等敏感数据不能延迟否则会造成收入损失。
- 低延迟,同机房数据库 binlog 订阅到检索 SLA TP95<200ms。
- 变化快,业务变更频繁。
我们的方案是分库分表之后,通过 binlog/DRC 组件来接广告传输流做实时增量链路,检索端订阅 message queue 来感知变化;全量数据 Dump 会存在分布式存储上,检索端可以天级别的 base+delta 的方式重建索引。
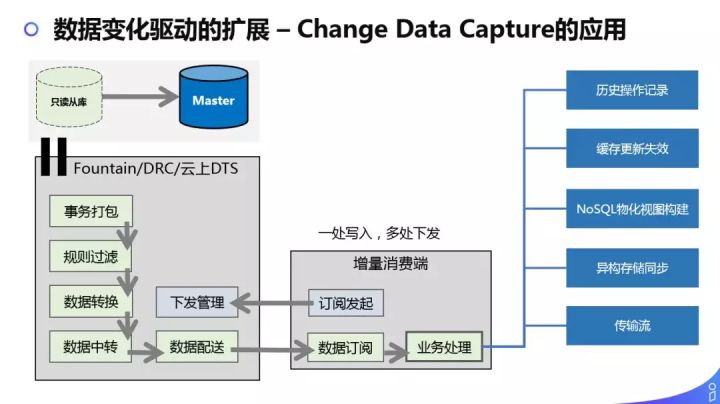
数据变化驱动的扩展,刚刚说的传输流只是其中的一个场景,可以扩展到很多场景中。都可以采用这种方式,做一个虚拟存库,开源的可以用 Fountain、Hiriver、Canal,以及阿里云的 DTS 等,可以做事务打包、规则过滤、数据转换等,最终到增量消费端,传输流只是其中的某一个场景来做平台端到检索端的同步,另外我们可以做历史操作记录,缓存更新失效,NoSQL 物化试图构建,异构存储同步等,想象空间会非常大,我们内部做了很多物化视图类的缓存和索引,辅助业务系统加速查询使用。
——计广告——
实时计费系统
1. 实时计费平台
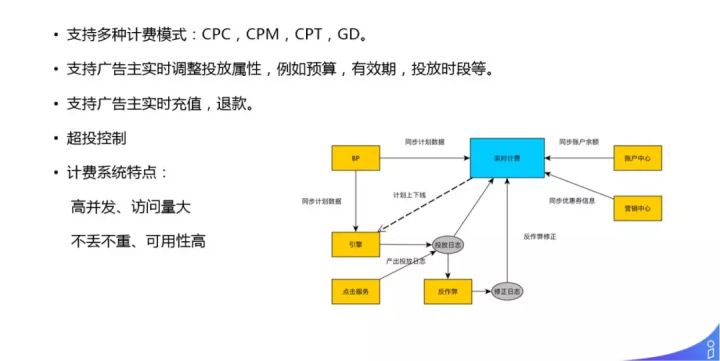
现在业界几乎都会实现一个实时计费平台,需具备基本的实时扣费和充值功能。计费广告最简单的模型是,广告主有钱,比如预算设置1000元,每次点击都要扣1~2元,最终扣完时,需要把这个广告下线,这是典型的 CPC 计费模式,还有 CPM,CPT,GD 等计费方式。计费平台还需要处理超投控制,避免平台利益受损。
实时计费系统特点是:高并发、访问量大、数据准确不丢不重、高可用性。
右图为实时计费平台的关系图:
用户中心来充值,业务平台同步一些计划的预算数据,引擎根据点击进行实时的扣费,计费系统要把计划上下线的信息,通过传输流实时传输给广告检索引擎。
2. 实时计费系统简介
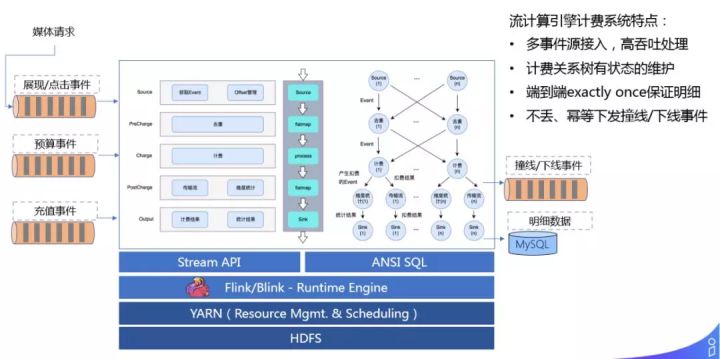
我们过去的计费系统是基于单机或者分布式的系统来开发的,现在的计费系统跑在 Flink上,我们接收媒体的请求,展现/点击事件、预算事件、充值事件这三类事件之后,基于 YARN、Flink 之上,通过 Stream API 来做相应的逻辑。每个计费事件来之后,会先做去重,然后再做计费,把明细数据存在数据库中,撞线/下线数据可以实时的通过队列传输给检索系统。采用流式计算引擎做计费的好处在于:
- 可以做到实时处理,敏感信息高优低延迟的幂等下发;
- 对于明细数据可以通过两阶段提交 sink 的方式,保证端到端 exactly once 语义,然后做聚批高吞吐的写入数据库;
- 有状态的存储账户状态,在面对 failover,修历史数据场景下可以做自动和灵活的处理。
总结下流计算引擎计费系统特点:
- 多事件源接入,高吞吐处理
- 计费关系树有状态的维护
- 端到端 exactly once 保证明细
- 不丢、幂等下发撞线/下线事件
——查广告——
OLAP 海量数据报表
1. 数据报表
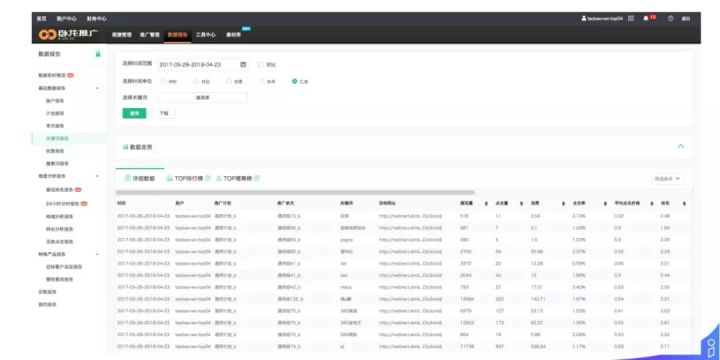
计费、展现的数据,都要给用户查看或进行分析。上图为某数据报表截图,某账户、单元、关键词维度下的展现、点击、消费数据。
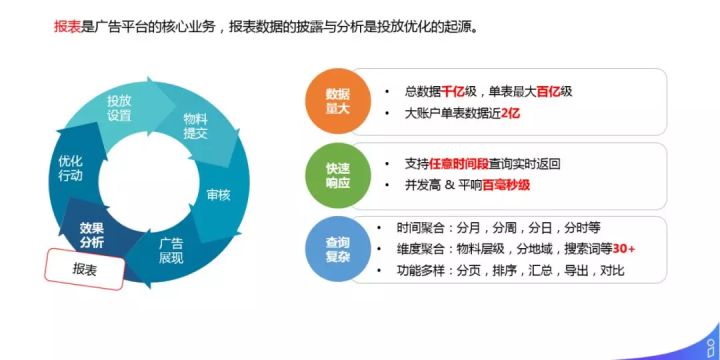
报表是广告平台的核心业务,报表数据的披露与分析是投放优化的起源。面临的问题:
- 数据量大: 总数据千亿级,单表最大百亿级;大账户单表数据近2亿。
- 快速响应: 支持任意时间段查询实时返回;并发高&平均响应百毫秒级
- 查询复杂:
① 时间聚合:分月,分周,分日,分时等。② 维度聚合:物料层级,分地域,搜索词等30+。③ 功能多样:分页,排序,汇总,导出,对比。
2. 技术选型思考
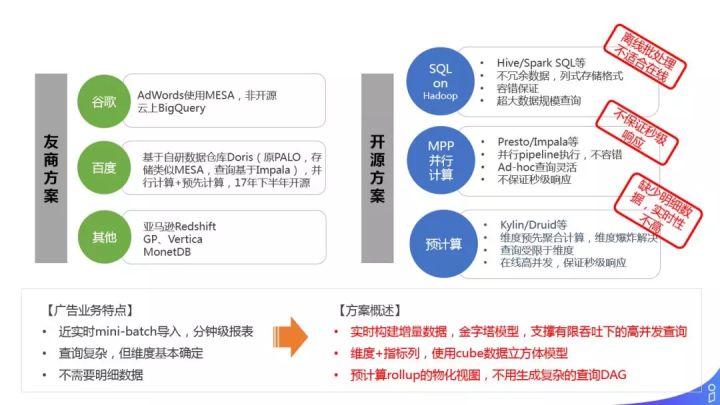
技术选型上的思考:
友商方案和开源方案如上图所示。根据我们广告业务特点:
- 近实时 mini-batch 导入,分钟级报表需求
- 查询复杂,但维度基本确定
- 不需要明细数据
我们的选型方案:
- 实时构建增量数据,金字塔模型,支撑有限吞吐下的高并发查询
- 维度+指标列,使用 cube 数据立方体模型
- 预计算 rollup 的物化视图,不用生成复杂的查询 DAG
3. 实时报表平台
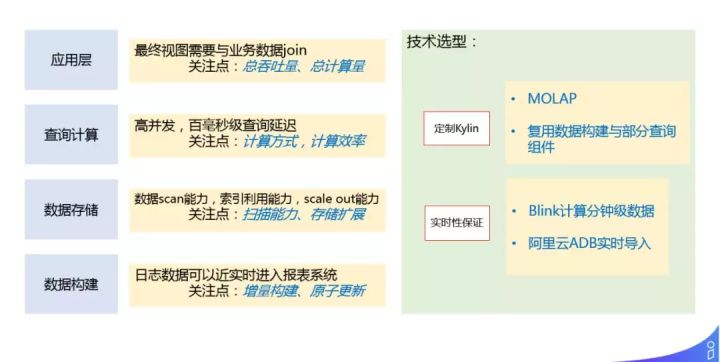
最终我们的实时报表平台,包括4层:
- 应用层:关注总吞吐量、总计算量,以及和业务的 join。
- 查询计算:关注高并发,百毫秒级查询延迟。
- 数据存储:有可扩展能力,并且有高效的 scan 能力。
- 数据构建:要保证增量构建和原子更新。
技术选型:
- 采用定制的 Kylin,是 MOLAP 多维的 OLAP 分析;复用数据构建与部分查询组件。
- 实时性保证,基于 Blink 计算分钟级数据,阿里云 ADB 实时导入事实表,Kylin 接入 ADS 来进行分钟级增量构建。
4. 报表平台关键技术点
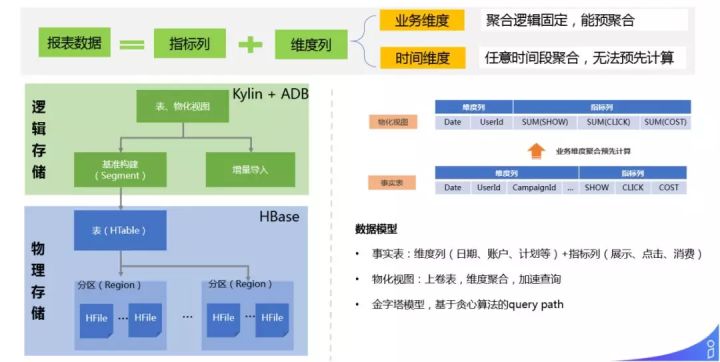
报表数据分为指标列和维度列,支持业务维度 ( 聚合逻辑固定,能预聚合 ) 和时间维度 ( 任意时间段聚合,无法预先计算 )。基于 Kylin 来做历史和小时级数据的查询,基于 ADB 来做实时分钟级数据的查询。这里的创新点采用金字塔模型做基于贪心算法的 query path 优化,在扫描数据量、IO 上做最优的查询计划。
5. CBO 优化之 TOP N 深分页优化
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


