贝壳找房语言模型系列实践篇在房产领域的实践
贝壳找房【语言模型系列】原理篇一:从 one-hot 到 Word2vec
贝壳找房【语言模型系列】原理篇二:从 ELMo 到 ALBERT
随着预训练模型在各大榜单的不断屠榜,学术界和工业界对于预训练模型的研究也愈加狂热。预训练语言模型一般基于海量语料,消耗大量的硬件资源以及时间成本,利用无监督的方法学习一个语言模型,随之应用到各种任务中,带来效果上的提升。
贝壳找房作为中国互联网房产领域领先的服务平台,业务场景中包含了大量的自然语言处理任务,积累了大量的房产领域文本语料,如何更好的利用这些海量的语料,完成各种业务场景的提效,是贝壳找房语言智能与搜索团队面临的挑战之一。
一、模型选择
一般来讲,使用预训练模型分为三个阶段:选择模型、领域预训练、微调(fine-tuning),如下图所示。
预训练过程:
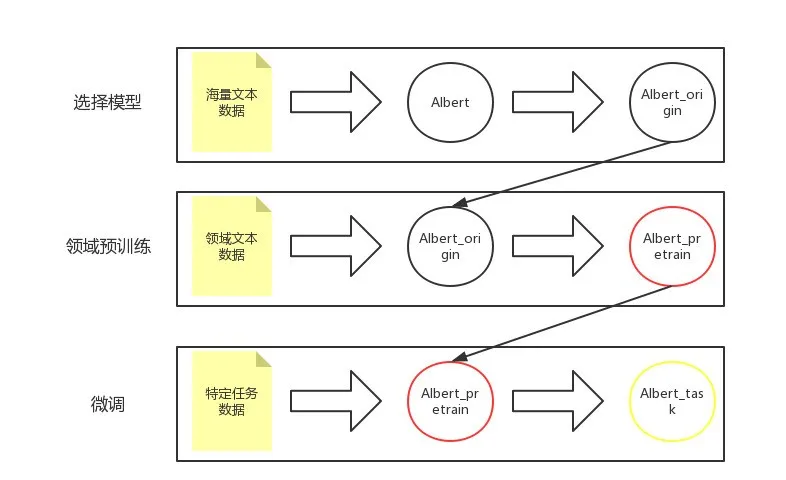
模型的选择是最基础,也是很大程度上决定最终应用效果和性能的关键一步。
谷歌提出的预训练语言模型 BERT 算是 NLP 领域近年来取得的重大进展及里程碑事件之一。虽然 BERT 效果显著,但是由于其庞大的参数量,使得其在现实场景的工程落地中步履维艰,难以真正的部署到线上使用。幸运的是,如今已经有很多算法对其进行了改进,使得模型更”接地气“,能够应用到具体的任务场景中,比如 2019 年提出的 ALBERT。
ALBERT 在参数量上做了很多文章,将 BERT 中 100 多 M 的参数量缩小到 12M(base),甚至是 4M(tiny),极大的提升了训练和推理速度,且效果基本保持一致。为了更好的进行线上工程化,选用 ALBERT 基于中文语料训练的 tiny 版本模型。tiny 版本只有 4 层 transformer,在推理速度上会大大提升。
二、领域预训练阶段
为了在特定领域的任务中取得更好的效果,通常会用特定领域的语料在公开的预训练模型基础上进一步训练,学习更多的关于该领域的语义信息。房产领域中的文本语料特点突出,具有很多房产领域特有的语言习惯和专业词汇,因此利用房产领域的文本进行进一步的领域预训练十分必要。
2.1 数据准备
综合贝壳找房多个业务场景下的语料(小贝助手、智能客服、看点、房评等),共准备了约 30G 左右的房产领域语料。
利用房产领域语料进行预训练,需要将大量的房产领域语料转成 tfrecord 格式,以便于进行快速的预训练。tfrecord 的生成主要消耗大量的 CPU 资源,对 GPU 资源没有依赖。一般来讲,我们会把预训练语料进行切分,以便在有限的内存资源中完成 tfrecord 的生成。这里我将原始语料切分为 317 份,每份 50 万行数据,依次生成 tfrecord。
2.2 算力和训练时间
由于 ALBERT_tiny 的参数量相较于 BERT 来讲减少了很多,所以在正常的 GPU 中也可以跑起来,且预训练速度也还可以接受,主要参数如下所示。
数据量预训练参数所用资源所用时间30Gtrain_batch_size=512 max_seq_length=128 num_train_steps=300004 块 v10042h
三、fine-tuning 阶段
经历过算法模型工业实践洗礼的同学,一定能够深刻的体会到工业中高质量数据的难得和重要,通常我们都没法拿到数量足够多的训练集。所以如何在只拥有少量数据集的情况下,取得较好的训练效果,就成了工业实践中比较常见的一个问题,而 fine-tuning 就很好的解决了这个问题。
所谓的 fine-tuning 阶段就是”站在巨人的肩膀上看世界“,这里的“巨人”就是我们前面提到的领域预训练。预训练模型在领域预训练阶段进行的是无监督训练,会学习到大量的领域知识,因此在 fine-tuning 阶段将预训练模型的参数作为具体任务的初始化参数,能够在具体的任务中使用更少的数据,得到更好的训练效果。
当前我们在房产领域中进行了两个任务的实践–意图识别和句式识别,并已经将意图识别的模型成功应用到线上,且取得了不错的效果。
3.1 意图识别
3.1.1 定义
意图识别,简单来说就是读懂一个 query 表达的意图,比如识别出“我想要一个带阳台的大房子”表达的意图是“找房”,其实直白的说,意图识别就是一个多分类任务。房产领域的意图识别主要分为用户意图识别和经纪人意图识别,其中用户意图体系复杂,任务难度较大,我们这次的实践也是挑了这块难啃的骨头。
3.1.2 整体架构
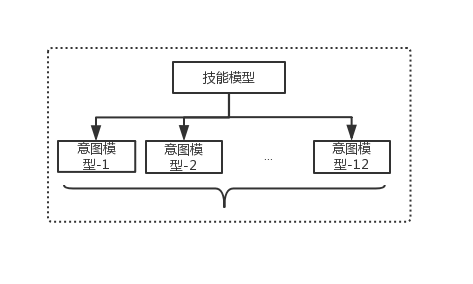
我们在建立用户意图体系的过程中,定义了 256 个意图类别,由于意图种类过多,难以使用一个模型进行分类表示,所以我们又将 256 类意图进行向上归类,定义了 13 个技能类别(包含一个 other 类别),每个技能下对应着一部分意图。在预测过程中,query 先经过技能模型,得到技能的标签,然后根据技能标签决定调取哪个意图模型。所以,我们一共有 1 个技能模型和 12 个意图模型,如下图所示。
模型架构:
3.1.3 albert 登场
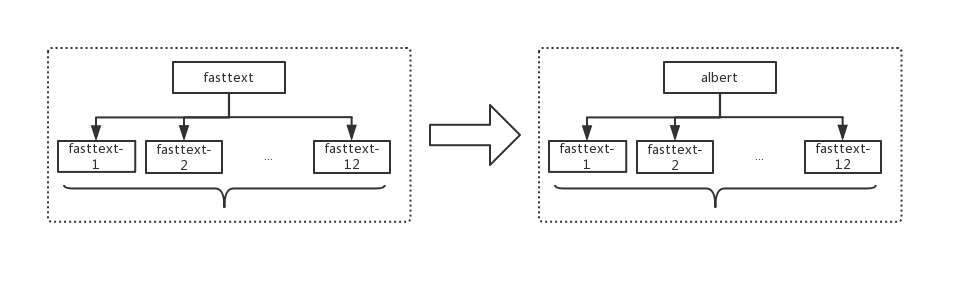
在这个模型体系中,起初的技能模型和意图模型都是用的 fasttext。fasttext 虽然是一个很优秀的模型,但也有其缺陷。fasttext 模型对 query 的语义信息识别不充分,对“词”的依赖程度过高,比如技能标签是房屋信息的 query 大多为疑问句,导致 query 中经常出现”吗“这种疑问词,使得可能将“吗?”这种 query 识别成房屋信息。而 albert 这种预训练模型能够获取 query 的语义信息,内部采用注意力机制,对 query 中的每个词分配不同权重,可以在一定程度上避免这种问题的出现。所以我们将技能模型替换为了 albert,如下图所示。
模型架构替换:
3.1.4 效果
我们在对意图识别整体架构体系进行变更之前,完成了两版评测–线下模型评测及线上评测。
在线下评测过程中,我们在同等训练集、测试集的情况下,对 fasttext 和 albert 在技能层的效果进行了对比,结果如下
模型评测任务效果(acc)fasttext意图识别技能层0.75albert_origin+fine-tuning意图识别技能层0.804albert_pretrain+fine-tuning意图识别技能层0.832
其中,albert_origin 是没有进行领域预训练的模型,直接使用了作者公开的预训练模型,albert_pretrain 是利用了房产领域数据进行预训练之后的模型。这里 albert 的效果是在预训练模型的基础上进行微调(fine-tuning)的结果。可以看出来,在线下评测中,技能层的模型由 fasttext 更替到 albert 后,其准确率由 0.51 上升到 0.632,提升了 12.2 个百分点,这个程度的提升还是很明显的。同时 albert_origin 和 albert_pretrain 也存在着 2.8 个点的差异,说明领域预训练是很有必要且效果显著的。
在上线之前,我们还进行了线上模拟评测,采用了 GSB 的评测方法,即对一批线上语料,分别使用两个意图识别架构进行预测,并人工标出预上线的架构相较于线上架构的影响。这里的影响包括正向(good)、相同(same)、负向(bad),其中 good 指的是新架构预测正确的 case 数量,bad 是指线上架构预测正确的 case 数量,same 指的是两个架构预测结果相同。由此来评测出新体系上线后对于线上的作用效
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%B3%BB%E5%88%97%E5%AE%9E%E8%B7%B5%E7%AF%87%E5%9C%A8%E6%88%BF%E4%BA%A7%E9%A2%86%E5%9F%9F%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


