这些上下文相关的表示到底有多上下文化
作者:Kawin Ethayarajh
编译:ronghuaiyang
原文: 英文原文: https://kawine.github.io/blog/nlp/2020/02/03/contextual.html
导读: 具有上下文信息的词表示到底有多大程度的上下文化?这里给出了定量的分析。
将上下文信息放到词嵌入中 — 就像BERT,ELMo和GPT-2 — 已经证明了是NLP的一个分水岭的想法了。使用具有上下文信息的词表示来替换静态词向量(例如word2vec),在每个NLP任务上都得到了非常显著的提升。
但是这些上下文化的表达到底有多大程度的上下文化呢?
想想“mouse”这个词。它有多种词义,一个指的是啮齿动物,另一个指的是设备。BERT是否有效地在每个词的意义上创造了一种“mouse”的表达形式?或者BERT创造了无数个“mouse”的形象,每一个都是和特定的上下文相关?
在我们的EMNLP 2019论文“How Contextual are Contextualized Word Representations?”中,我们解决了这些问题,并得出了一些令人惊讶的结论:
-
在BERT、ELMo和GPT-2的所有层中,所有的词它们在嵌入空间中占据一个狭窄的锥,而不是分布在整个区域。
-
在这三种模型中,上层比下层产生更多特定于上下文的表示,然而,这些模型对单词的上下文环境非常不同。
-
如果一个单词的上下文化表示根本不是上下文化的,那么我们可以期望100%的差别可以通过静态嵌入来解释。相反,我们发现,平均而言,只有不到5%的差别可以用静态嵌入来解释。
-
我们可以为每个单词创建一种新的静态嵌入类型,方法是将上下文化表示的第一个主成分放在BERT的较低层中。通过这种方式创建的静态嵌入比GloVe和FastText在解决单词类比等基准测试上的表现更好。
回到我们的例子,这意味着BERT创建了与上下文高度相关的单词“mouse”的表示,而不是每个单词都有一个表示。任何“mouse”的静态嵌入都会对其上下文化表示的差异造成很小的影响。然而,如果我们选择的向量确实最大化了可解释的变化,我们将得到一个静态嵌入,这比GloVe或FastText提供的静态嵌入更好。
上下文化的度量
上下文化看起来是什么样的?考虑两个场景:
A panda dog runs.
A dog is trying to get bacon off its back.
== 意味着没有上下文化(即我们用word2vec得到的东西)。 != 意味着存在某种上下文化。困难在于量化这种情况发生的程度。由于没有确定的上下文相关性度量,我们提出三个新的度量:
-
Self-Similarity (SelfSim) :一个词在其出现的所有上下文中与自身的平均余弦相似度,其中该词的表示来自给定模型的同一层。例如,我们对所有不一样的cos(, )取平均值来计算(‘dog’)。
-
Intra-Sentence Similarity (IntraSim) : 一个词与其上下文之间的平均余弦相似度。对于第一个句子,其中上下文向量:
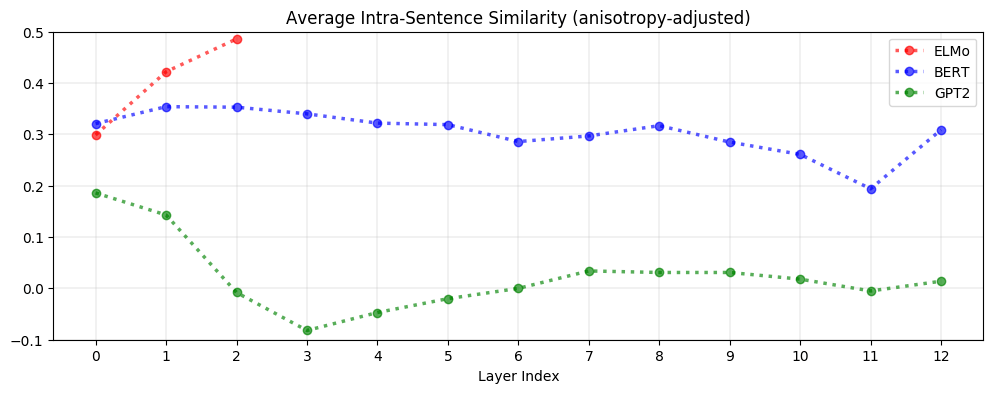
帮助我们辨别上下文化是否朴素 —— 就是简单的让每个单词与其相邻的单词更相似 —— 或者是否更微妙,认识到在相同的上下文中出现的单词可以相互影响,同时仍然具有不同的语义。
-
Maximum Explainable Variance (MEV) : 在一个词的表示法中,可以用它的第一个主成分来解释这个词的变化的比例。例如,(‘dog’)是通过,,以及数据中其他每个’dog’实例的第一个主成分来表示变化的比例。(‘dog’) = 1表示不存在上下文化:静态嵌入可以替换所有上下文化的表示。相反,如果(‘dog’)接近0,则静态嵌入几乎不能解释所有的变化。
注意,这些度量都是针对给定模型的给定层计算的,因为每个层都有自己的表示空间。例如,单词‘dog’在BERT的第一层和第二层有不同的self-similarity值。
各项异性调整
当讨论上下文时,考虑嵌入的各向同性是很重要的。(即它们是否在各个方向均匀地分布)。
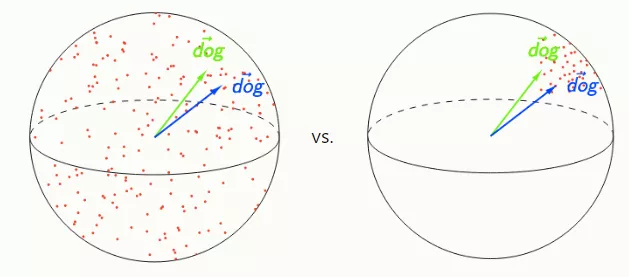
在下面的两个图中,(‘dog’) = 0.95。左边的图片显示,“dog”这个词没有很好的上下文化。它的表现形式在它出现的所有上下文中几乎都是相同的,而且表示空间的高各向同性表明0.95的self-similarity是非常高的。右边的图像则恰恰相反:因为任何两个单词的余弦相似度都超过了0.95,所以‘dog’的自相似度达到0.95就没什么了不起了。相对于其他单词,‘dog’会被认为是高度上下文化的!

为了调整各向异性,我们为每个测量值计算各向异性基线,并从相应的原始测量值中减去每个基线。但是有必要对各向异性进行调整吗?有!如下图所示,BERT和GPT-2的上层是极具各向异性的,这表明高的各向异性是上下文化过程的固有特征,或者至少是其结果:
特定上下文
一般来说,在更高的层中,上下文化的表示更特定于上下文 。下图所示,自相似度的降低几乎是单调的。这类似于在NLP任务上训练的LSTMs的上层如何学习更多特定于任务的表示(Liu et al., 2019)。GPT-2是最具特定上下文化的,其最后一层中的表示几乎是与上下文相关程度最高的。
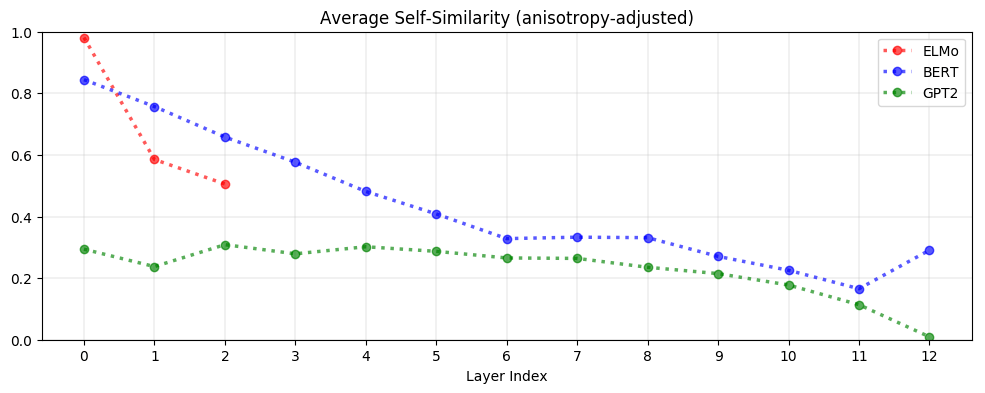
自相似度最低的停止词比如包括“the”。(最特定于上下文表示的词)。 一个词出现在多种上下文中,而不是其固有的一词多义,是其上下文化表示变化的原因。这表明ELMo、BERT和GPT-2并不是简单地为每个词赋予一个表示,否则,就不会这么少的词意表示会有这么多的变化。
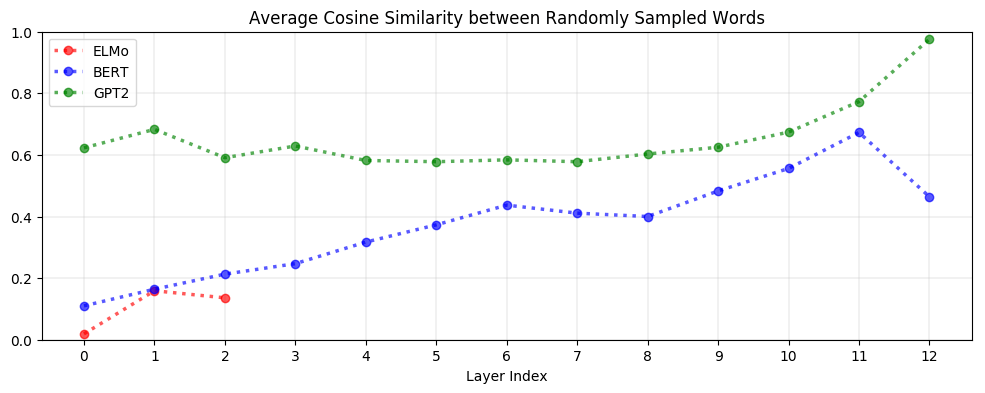
特定上下文表示性在ELMo、BERT和GPT-2中表现得非常不同。 如下图所示,在ELMo中,相同句子中的单词在上层中更相似。在BERT中,同一句话的上层单词之间的相似性更大,但平均而言,它们之间的相似性比两个随机单词之间的相似性更大。相比之下,对于GPT-2,同一句话中的单词表示彼此之间的相似性并不比随机抽样的单词更大。这表明,BERT和GPT-2的上下文化比ELMo的更微妙,因为他们似乎认识到,出现在相同上下文中的单词不一定有相同的意思。
静态 vs. 上下文化
平均而言,在一个词的上下文化表示中,只有不到5%的差异可以用静态嵌入来解释。 如果一个单词的上下文化表示完全与上下文无关,那么我们期望它们的第一个主成分能够解释100%的变化。相反,平均不到5%的变化可以被解释。这个5%的阈值代表了最佳情况,其中静态嵌入是第一个主成分。例如,没有理论保证GloVe向量与最大化可解释变化的静态嵌入相似。这表明,BERT、ELMo和GPT-2并不是简单地为每个词意义分配一个嵌入:否则,可解释的变化比例会高得多。
在许多静态嵌入基准上,BERT的低层上下文化表示的主成分表现优于GloVe和FastText。 这个方法将之前的发现归结为一个逻辑结论:如果我们通过简单地使用上下文化表示的第一个主成分为每个单词创建一种新的静态嵌入类型,结果会怎样?事实证明,这种方法出奇地有效。如果我们使用来自底层BERT的表示,这些主成分嵌入在涉及语义相似、类比求解和概念分类的基准测试任务上胜过GloVe和FastText(见下表)。
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


