部署基于嵌入的机器学习模型的通用模式
作者:Robbe Sneyders
编译:ronghuaiyang
给大家介绍一下如何在生产中部署基于嵌入的机器学习模型。
由于最近大量的研究,机器学习模型的性能在过去几年里有了显著的提高。虽然这些改进的模型开辟了新的可能性,但是它们只有在可以部署到生产应用中时才开始提供真正的价值。这是机器学习社区目前面临的主要挑战之一。
部署机器学习应用通常比部署传统软件应用程序更复杂,因为引入了一个额外的变化维度。虽然典型的软件应用程序可以更改其代码和数据,但是机器学习应用程序还需要处理模型的更新。模型更新的速度甚至可以非常高,因为模型需要定期地根据最新的数据进行再训练。
本文将描述一种更复杂的机器学习系统的一般部署模式,这些系统是围绕基于嵌入的模型构建的。要理解为什么这些系统特别难以部署,我们首先要看看基于嵌入的模型是如何工作的。
基于嵌入的模型

图1,嵌入空间的图
基于嵌入的模型正在所有机器学习领域中出现。它们最近在NLP领域掀起了一场革命,是大多数现代推荐系统的核心。谷歌使用嵌入来为搜索查询找到最佳结果,而Spotify使用嵌入来生成个性化的音乐推荐。
简单地说,这些模型将它们的输入投射或“嵌入”到向量表示或嵌入中。视觉模型嵌入图像,语言模型嵌入单词或句子,而推荐系统对用户和物品做同样的事情。
生成的嵌入非常强大,因为它们可以以相对低的维数来描述数据集的结构。在得到的向量空间中,相似的输入记录被紧密地映射在一起,而不同的物品被映射到相隔很远的地方。这可以用来比较复杂的物品,这在原始数据空间中是不可能的。
这些嵌入可以在不同数据域的模型之间共享,解决新问题的新模型可以构建在这些模型之上。不难想象,这样一个完整的机器学习模型系统会有多大的价值。
基于嵌入的系统
不幸的是,单个嵌入本身并不是很有用,只有与其他嵌入进行比较才会变得强大。由于每次都重新计算所有嵌入是不可行的,而且常常是不可取的,所以它们通常是预先计算好的,并保存在实时数据存储中以供比较。
这正是这些系统难以部署的原因。每次模型更新时,都需要重新计算所有的嵌入。对于具有数百万条记录的系统,这可能需要很长时间,在此期间,系统的正常操作不能受到影响。即使在较小的系统中,这样的更新也不是即时的,如果管理不当,可能会导致不一致的结果。
我们将研究两个基于嵌入的系统,搜索引擎和推荐系统,并定义一个适用于这两个系统的通用部署策略。虽然这些系统是相似的,但它们的差异足以为广泛的基于嵌入的系统提供泛化。

图像2,搜索引擎(左),推荐系统(中间),泛化的嵌入系统(右)
搜索引擎
我们的搜索引擎的目标是为搜索查询找到最匹配的文档。它由三个组件组成:应用程序、模型和嵌入数据存储。当应用程序接收到搜索查询时,它调用模型将查询转换为嵌入,然后使用该模型在数据存储中的文档嵌入中执行相似性搜索。
推荐系统
我们的推荐系统的目标是向用户推荐最感兴趣的项目。它包含三个组件:应用程序、用户嵌入数据存储和物品嵌入数据存储。要向用户推荐物品,应用程序首先从用户数据存储中获取用户的嵌入,然后使用它在物品数据存储中执行相似度搜索。
这两个系统最大的区别是在搜索引擎中存在一个在线模型,而所有的嵌入都是在推荐系统中预先计算好的。但是,在这两个系统中可以识别出相同的三个功能组件:
-
嵌入生成器,根据其输入返回嵌入结果。在搜索引擎中,是通过模型将搜索查询转换为嵌入。在推荐系统中,是通过id来从数据存储中得到用户的嵌入。
-
嵌入服务器,它托管预先计算的嵌入来进行相似度搜索。
-
应用程序,它从嵌入生成器中获取嵌入,并将其发送到嵌入服务器执行相似搜索。
我们使用这个通用系统演示部署模式。
不停机部署新模型
当对模型进行再训练或调优时,数据在嵌入空间中表示的方式将发生变化。为了获得一致的结果,嵌入生成器返回的嵌入和存储在嵌入服务器中的嵌入应该由相同的模型版本生成。
准备新模型部署的第一步是使用新模型重新计算系统中所有记录的嵌入,并将它们存储在新的数据存储中。最直接的方法是批量计算,与实际系统分离。重新计算所有嵌入后,新的嵌入生成器和服务器就可以部署到活动系统中。
一种简单的方法可能是尝试同时部署新的嵌入生成器和服务器。但是,即使它们都可以完全同步地切换到新版本,这在实践中很难实现,这种方法仍然不足以保证一致的结果。来自旧的嵌入生成器的过时的嵌入可能已经在运行中,并且只有在更新之后才能到达嵌入服务器,从而导致相似度搜索不匹配。
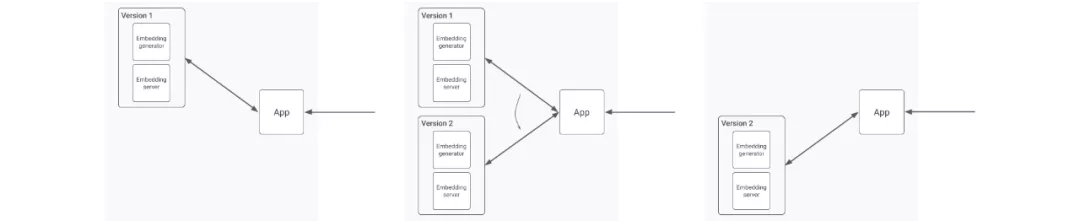
图3,嵌入生成器和服务器的新版本都与旧版本部署在一起,因此应用程序可以轻松的切换
很明显,为了确保连续性,从单个应用程序调用的角度来看,更新应该是原子性的。当应用程序从生成器获取嵌入时,它应该始终在具有匹配版本的嵌入服务器中执行相似度搜索。为了实现这一点,两个组件的新旧版本至少需要同时部署,在此期间,两个版本之间的切换可以在应用程序调用级别进行。之后,旧版本可以简单地删除。
图3显示了如何以这种方式将连续的应用程序调用切换到新版本,而不会导致任何停机或不一致。
进入流模式
现代系统通常比我们最初引入的简单系统更复杂,因为它们处理的数据需要不断更新。新文件需要添加到我们的搜索引擎,或现有的文件可能得到更新。新用户可以订阅我们的推荐系统或更新他们的资料,而新的物品可以定期添加到目录中。
有些系统可能可以通过批量计算这些更改,并定期用新的数据存储替换旧的数据存储,但是这样做会在系统中出现新的或更新的记录之前增加很大的延迟。随着流更新成为越来越多系统的需求,需要一种流本地部署策略。为了得到这个策略,我们将首先重新引入我们的搜索引擎和推荐系统作为流式系统。
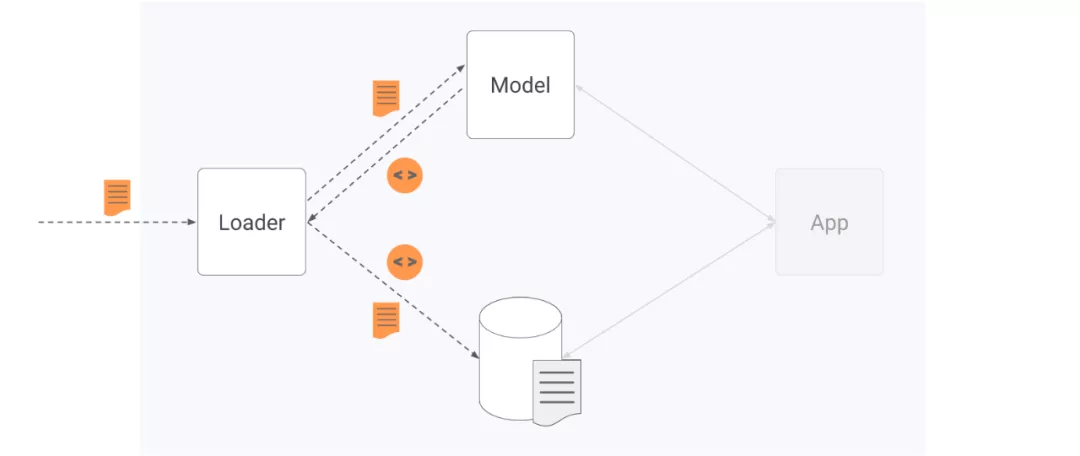
图4,加载流更新到搜索引擎。
升级我们的搜索引擎流更新几乎是微不足道的,因为它已经托管了一个在线嵌入计算模型,可以在数据加载期间重用该模型进行流推理。系统中引入了一个新的数据加载器组件,用于编排传入的文档更新。它首先将传入文档嵌入在线模型,并将生成的嵌入写入嵌入数据存储。
升级我们的推荐系统需要更多的努力,因为流式更新需要一个在线模型,这以前不是系统的一部分。在添加了在线模型和数据加载器组件之后,数据加载流相当于搜索引擎的数据加载流。数据加载器首先调用在线模型来嵌入项和用户,并将生成的嵌入写入相应的数据存储。
由于两个系统是等价的,为了简单起见,我们将使用搜索引擎来演示流模型的部
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%83%A8%E7%BD%B2%E5%9F%BA%E4%BA%8E%E5%B5%8C%E5%85%A5%E7%9A%84%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E7%9A%84%E9%80%9A%E7%94%A8%E6%A8%A1%E5%BC%8F/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


