阿里想为特征交互走一条新的路

文章作者:周国睿 阿里巴巴 高级算法专家
内容来源:知乎@周国睿
导读: 本文主要介绍阿里定向广告技术团队在CTR建模领域最新的工作CAN,CAN已经在双十一前全面在阿里定向广告落地,在线效果提升非常显著。一般文章会以事后的视角来写,这样思考会更完整,会屏蔽掉中途的一些旁枝末节,会显得思路更清晰也没犯啥蠢,不过这篇文章我想试试以顺序(流水账?)的视角来更真实的记录一下这个工作的诞生过程,具体对方法的描述,以及CAN的精简思路,大家看论文会体验更好一些:
CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
https://arxiv.org/abs/2011.05625
过去几年,我们团队一直在兴趣建模方面投入了非常多的精力,也产出了一些工作。其实我们一直还有另一条坚持的技术主线,表征建模。
01 第一次冲锋
在17年开始我就在表征建模上投入了大量的精力,毕竟是做NLP出身的,当然想蹭蹭过去学到的一些小技巧。最开始是想模仿Google做一个真·AI,当时XDL还没完全交接给工程同学,负责一部分XDL架构和开发的工作。当时想,如果各个业务线都在用XDL,如果我做一个parameter bank用来存放各类ID的embedding。各个业务线的模型训练任务通过这个parameter bank共享这些embedding参数,并且为它共享梯度,有没有可能学出一个淘宝体系里最普适的ID representation,最后学出一些我们意想不到的知识?后来这个想法告吹了,因为它背后更新/维护/多个业务线的耦合风险无法说服所有人,同时我当时接到的任务是把图像用到CTR任务里,这个方案看起来并不是为了完成这个任务目标最直接和现实的方式。到最后这个初始想法演变成了减少我们迭代负担的model bank,然后这个工作一直也没公开。
02 第二次冲锋
18年的时候,如何对十亿淘宝商品进行表征建模,或者简单点如何对item id学一个泛化性更强的embedding又开始来撩拨我的思想。想了一个res-embedding的方案,如果说直接学习每个item的embedding很难,那么把相似的item学习一个共享的mid embedding,再去学习每个item特有的信息 res embedding,用它们相加来表达一个item,相似item通过mid embedding共享信息可以缓解稀疏带来的学习难度,一定程度上提升泛化性。具体在如何找相似的item,以及如何设置mid时,我采用了图的方法,通过用户行为把item连接起来,最后这个方案有点类似后来比较火的graph sage。
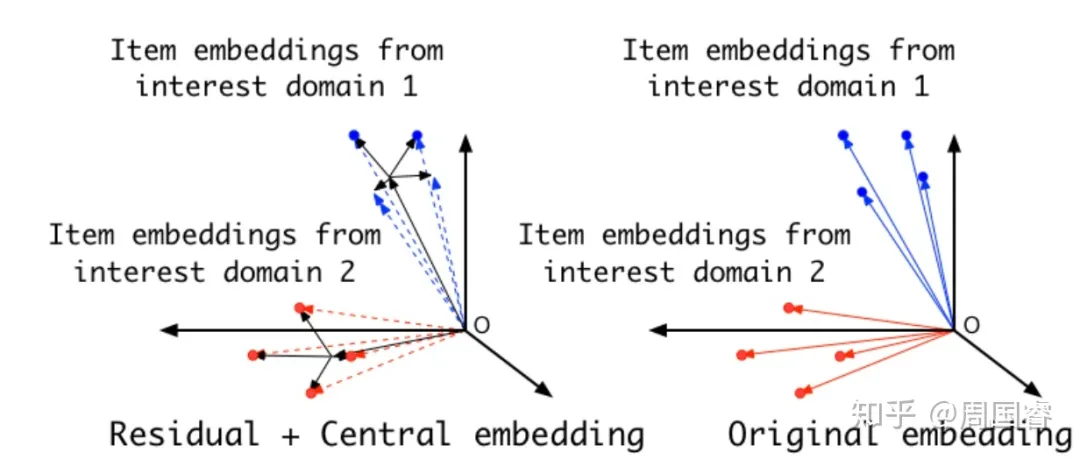
不过这个方案实际使用时在样本量几亿规模时非常有效,到几十亿上百亿规模时收效甚微,这说明我还是没找到更好的表征建模方案。
03 第三次冲锋
后续陆陆续续做了非常多碎的尝试,也学习了很多研究思路,包括GNN / Contrastive Learning / Information Bottleneck / Cognitive Rec等等,但是每次尝试我都发现要写论文很简单,很多方法在"小" ( 甚至几亿规模 ) 数据集上总是有效,但是在我面对的实际业务问题规模上,几乎都没什么效果。我甚至开始怀疑我所解的这个业务问题,到底需不需要研究表征建模这个问题,毕竟CV/NLP/语音的原始输入数据本身就是为表意而存在,天然具备一些连续相关性,而电商业务场景的数据并不是表意的。这到底是水平不够,还是说问题本身只是一个执念。后来我们做了一个简单的推演,CTR类模型的核心参数量都在embedding部分,而我们组的大部分工作和模型迭代都在后面的MLP部分,比如DIN/DIEN/MIMN。可是一旦embedding学习方式确定了,如果输入信息本身学习不够好,后面的模型空间是有限的。因此我们认为输入端信息建模应该是有一个比较大的潜在效果空间。然后就成立了一个项目组,搞了一年,没有完整的产出,成员们压力极大。
在第三次冲锋后期,我们推断出了一个对输入端信息做交互建模的方法,算是为我们团队找到了一个新的迭代路径,我个人也认为这个方法如果算作特征交互,算是一个新的思路。
04 回到特征交互
其实我对特征交互方面的工作一直以来态度都比较尴尬。一方面我认为手工交叉特征工程如果又能解决业务问题,又不影响迭代效率,其实挺好的,我们的业务模型里就有部分手工设计的交叉特征。技术都是为了解决问题而存在的,没有原罪,也没有原善,有克制的组合特征是能接受的,不能接受的是漫无目,无视迭代负担,冗余的大规模组合。另一方面,学术界一些比较熟知的工作,FM / NCF / deepFM / PNN / DCN等等 ( 说实话DCN不是很想提,不用看到实验部分,方法本身都有问题 ),这些工作以我浅薄的见解,我实在看不太出来和FM有啥区别,到效果上,我们的业务数据里确实都没效果,因为FM在我们的模型基础上叠加就没啥效果。虽然我一直很努力想理解这个在CTR建模领域比兴趣建模更为普适的路线到底在研究啥,这些工作一步步思路如何推进的。结果还是看不懂,也就不太想碰。
不过第三次冲锋,和之前一些同事的尝试倒是找到了一个比较有意思的实事:CTR预估建模问题里,把待预估的商品信息 ( 如item id ) 和用户历史行为序列信息 ( 如item id sequence ) 做笛卡尔积,形成一个新的id sequence,对其直接做embedding后pooling效果很好,会在DIN和DIEN的基础上再有比较明显的提升。
05 为何笛卡尔积有效
当时细想一下,笛卡尔积有效并不神奇,同时一定能找到参数量更少的模型方案来替代笛卡尔积这种hard的id组合方式。比如用户行为序列中有一个商品ID为A,待预估商品为B,笛卡尔积形成新的ID A&B,A&B每次在一条样本里出现,训练时都会更新独立属于自己的embedding。而这个A&B的embedding,我们认为其学习的是A,B两个ID在一条样本共现后对Label的co-action信息。
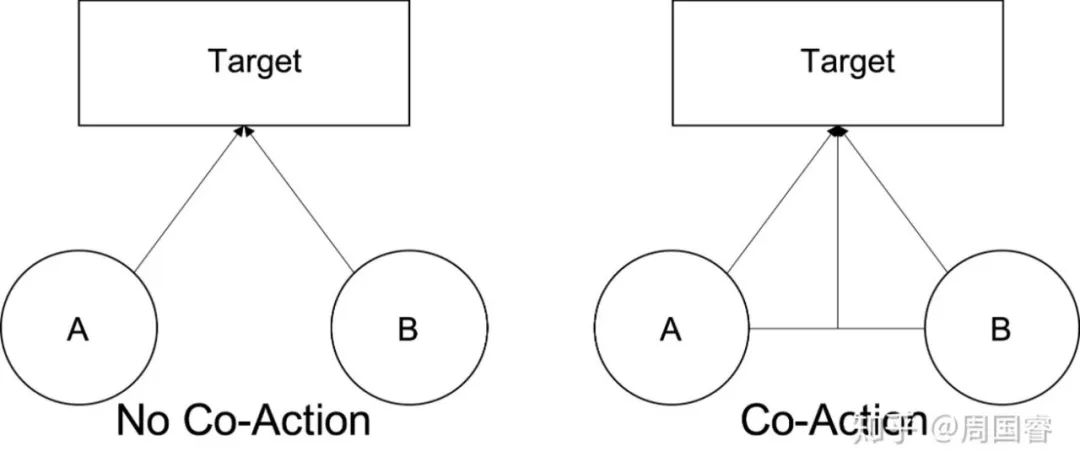
这个co-action信息为什么重要其实很好理解,比如CTR预估问题,要解决的本来就是每条样本最后预测是否点击,其实解的问题就是所有输入信息X条件下点击的概率 P(Y|X) 。建模co-action信息就是单独建模P(Y|A,B)。具体的,如果A和B分别是待预估的商品ID,和用户行为序列里的商品ID。如果我们对行为序列做SUM/AVG pooling就等于忽视了ID间的co-action,对序列做DIN/DIEN类似的aggregation,在co-action的视角下可以看做是一个scalar的co-action,没有方向,且只能对原始行为序列ID的embedding做一个纯量的修正。那么每个序列的ID都和预估商品ID做一个笛卡尔积呢,把原始的序列变成一个笛卡尔积ID序列,再给每个ID都学习一个embedding。这个时候co-action就是用向量来建模,且这个新的embedding和原始序列的embedding完全独立,自由度更大,模型capacity更大。如果原始ID的co-action信息建模本身有用,那么笛卡尔积就是建模co-action最直接的方式。笛卡尔积+端到端学习的embedding其实很像一个大的memory network,只不过写入和读出的索引相同,都是笛卡尔积化后的ID。这样的模式下这些代表co-action的笛卡尔积ID的embedding在训练时,具备样本穿越性。训练时,任意一个笛卡尔积ID A&B的embedding都是独立学习的,同时强保证了,在下一条A&B出现的样本里,这个embedding能把当前学到的co-action信息无损的带入。而简单的特征cross方法,比如把A_1的embedding和B_1的embedding做外积,这个时候A_1&B_1的co-action为Emb_{A_1} * Emb_{B_1},它在训练时也会被B_1 embedding本身的学习和A_1&B_2等更新,很难保证学习到的co-action信息在下一次出现时,还保留上一次学习的信息。
06 笛卡尔积不是终局
笛卡尔积其实是非常常用也比较好理解其实现方式的一个方案。不过对用户行为序列item seq和待预估item做笛卡尔积组合其实有蛮多弊端,即使已经看到了离线的部分提升,我对着急把这样的方案推进全面生产化不是很感兴趣。
-
这种序列笛卡尔积在训练端和在线服务端其实成本蛮大的。训练可能比较好解决,但是在线服务会有比较明显的瓶颈,因为每一次预估需要生成的ID,和查询embedding的ID会急剧膨胀,而这些操作是需要CPU计算的,这部分的可优化空间也比较小。算下来成本比一个计算复杂型模型要高不少,至少对于我们,一个熟知如何优化计算复杂型的团队是这样。
-
笛卡尔积意味着强记忆性,是比较hard的方案,对于一些样本里未出现的ID组合,是直接无法学习的。同时稀疏的组合和稀疏的ID,学习效果也很差,大部分情况下只能选择过滤。
-
笛卡尔积的参数膨胀本身就会带来模型无论从性能还是维护迭代上鲁棒性的进一步降低。
下面我们来推演一下在笛卡尔积有效的情况下,我们有没有机会找到参数量更少的模型方案来替代笛卡尔积这种hard的id组合方式。
第一条线索,参数空间视角:
前文提到二维笛卡尔积的方式,如果我们局限以对Item ID做co-action建模分析,可以看做是一个全参数空间为 N*N*D 的方法,N为item ID的数量,D是embedding的维度。这个参数空间是非常大的,N在淘宝是十亿以上的规模。当然了实际上训练时不需要那么大的空间,因为并不是所有ID的组合都会在样本中出现,但是笛卡尔积这个方法的假设参数空间依旧是 N*N*D。意味着在它有效的状态下,也是存在大量的参数空间冗余的,再考虑到稀疏出现的笛卡尔积,如出现次数个位数的笛卡尔积embedding无法有效学习。笛卡尔积方法,大部分的假设参数空间都是无效的。
第二条线索,学习难度视角:
前文提到,笛卡尔积的方式保障了任意一组co-action组合的学习是独立且强记忆能实现样本穿越的。而如直接外积的方式很难建模co-action,因为没有参数来稳定维持对co-action的建模学习信息。虽然笛卡尔积的方式是有效且看上去对co-action建模最直接的,但是难以忽视的一点是比如在电商场景,商品与商品之间是有联系的,是有相似性的,任意两个商品之间的co-action信息也应该有overlap的部分,不应该是完全独立的。直接外积的方式呢,共享的维度过大,单侧ID的信息完全共享,参数空间为 N*D 。如果我们能有效利用不同co-action之间有信息可共享,我们就有机会找到把参数空间降低到 N*T*D 的方法,其中 T«D。
07 CAN:Co-Action Net
最开始我们从memory net的视角想了一种方案,把item id的参数从D扩展到 T*D,即把embedding变成一个有T个slot的矩阵,这种方案下任意一个ID都有T个slot,每个slot存放维度为D的vector。这时候可以借attention的思路来建模co-action并保持不同组合co-action学习的部分独立性。比如在建模co-action时,让不同的slot对另一个ID的所有slot做attention aggregation,并和aggregation后的结果做外积 ( element wise乘法 ):
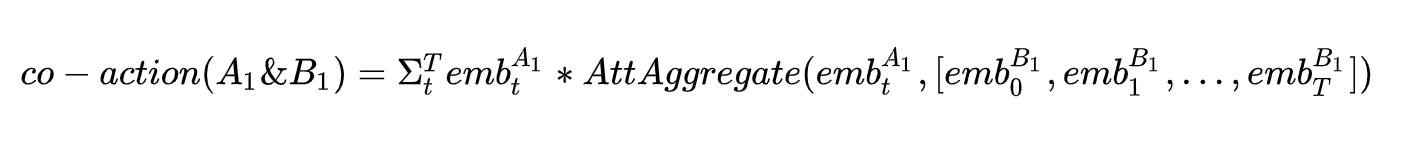
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E6%83%B3%E4%B8%BA%E7%89%B9%E5%BE%81%E4%BA%A4%E4%BA%92%E8%B5%B0%E4%B8%80%E6%9D%A1%E6%96%B0%E7%9A%84%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


