阿里文娱多模态视频分类算法中的特征改进
分享嘉宾:蒋小森 阿里文娱 算法专家
编辑整理:王恩贵
内容来源:阿里文娱技术
出品平台:DataFun
导读: 类目体系是视频网站运营中的重要工具,也是推荐算法中提升冷启效果的重要手段。因此一套设计合理、准确率、覆盖率高的基础类目必不可少。阿里文娱类目体系建设团队与运营、审核一起建立的一二级类目体系,目前已全面应用于运营选品、盘货、数据分析及推荐冷启中。本次分享的主要是对多模态视频分类算法中图像特征的改进,特征表征能力的提升为分类性能的提升提供了扎实的基础。
本次分享的内容主要包括:
- 类目体系建设简介
- 多模态视频分类算法及图像特征改进
- 思考及后续规划
▌类目体系建设简介
1. 类目体系的理解与业务价值
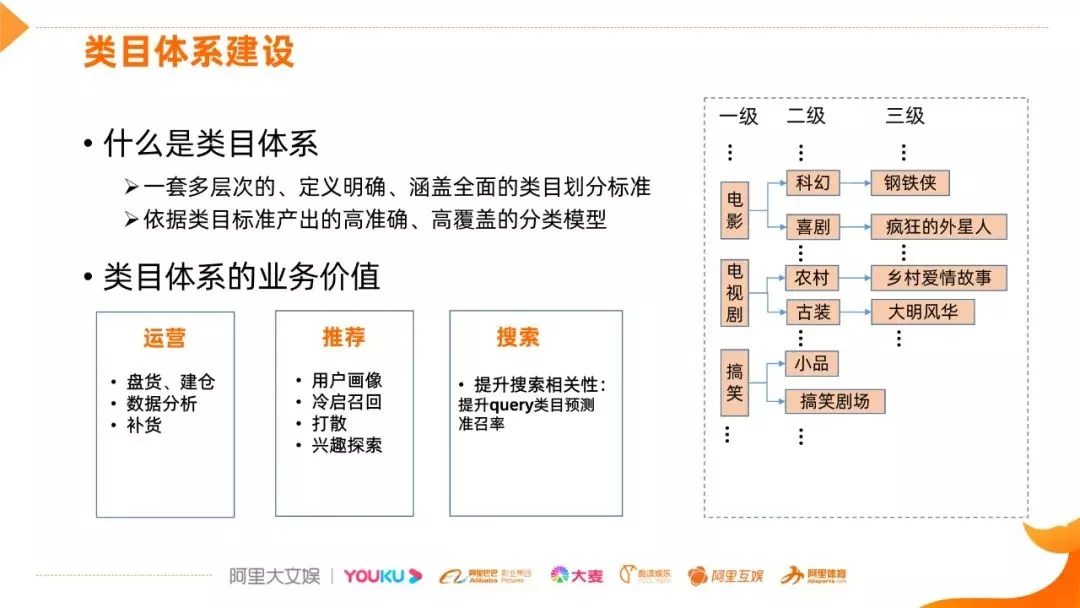
首先介绍一下对类目体系的理解,类目体系是一套类目的划分标准,这个标准具有多层次的、经过讨论定义明确的、视频内容涵盖全面的特点,另一个特点是依据这个类目标准产出一个高准确、高覆盖的分类模型,这样就得到了一个高效的类目体系,通过算法赋能,使得这个类目体系可以在各个业务方发挥价值。
类目体系是视频网站的基础设施,主要有以下三个业务应用方向:
运营: 类目体系的需求源于运营,有了这个类目体系后,方便盘货、建仓、提效,以及提升货品的质量,并且可以进行数据分析,辅助整体把握退货、补货等,提高运营水平。
推荐: 冷启召回,主要应用到二级类的粒度,对于新上传的视频没有任何属性,如类目、标签等,很难推荐给合适的用户,有了这个类目体系之后,可以根据历史数据,建立用户的画像,推荐给相应的人,短时间内可以把视频分发出去,另外在打散和兴趣探索方面也有一些应用,这两个应用主要是提高推荐的多样性。
搜索: 提高搜索内容和意图的相关性,相关性可以拆解到类目预测这样的维度,比如可以通过搜索的关键词可以预测想要搜索的类目,通过类目可以提升召回的内容,排除一些 bad case,从而提升搜索的相关性。
2. 类目体系的建设过程和建设成果
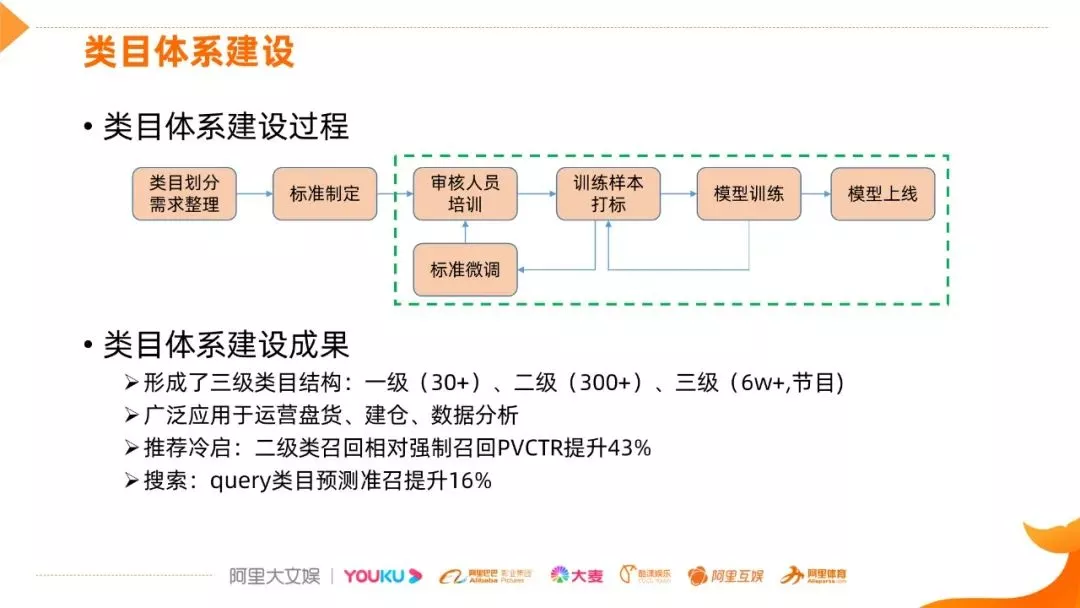
类目体系的建设过程: 首先整理类目划分需求,给出制定的标准,一般是一级或二级类目,一开始这个标准是比较粗的,依据这个标准培训审核人员,做训练样本的打标,针对具体的 CASE,会微调标准,这个绿色框标识的循环一直存在类目体系的建设和上线优化中,还有模型训练的自动化,提效类目体系的建设过程。
类目体系的建设成果: 形成了三级类目结果,广泛应用到运营盘活、建仓和数据分析中;推荐冷启的二级类找回相对强制召回 PVCTR 提升了 43%;搜索方面,类目预测准确率也有比较大的提升。
3. 节目分类及业务价值

节目分类也叫短长关联,也就是识别一个节目的片段和周边,来源于哪个节目,并与正片挂靠,这是一个分类的问题。在这里单独把节目分类分出来,主要是因为这样可以有更加细化和明确的价值。
在业务价值方面:
- 从运营角度,比如想找一些乡村爱情方面的短视频或周边内容,我们就可以根据分类结果来找,圈定一批质量比较好的视频
- 冷启阶段,包括刚才提到的二级召回,还包括节目关联召回
从算法模型方面,对模型细粒度的理解能力有更高的要求,因为目前有 6 万多个节目,就是一个细粒度的分类问题。
▌多模态视频分类算法及图像特征改进
1. 多模态视频分类算法
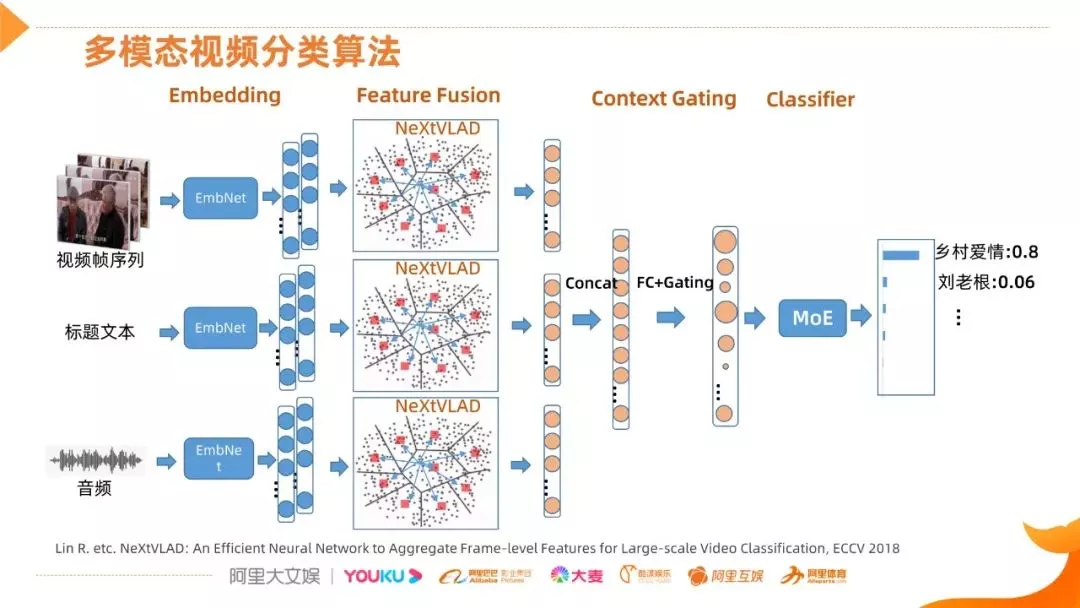
我们采用的多模态视频分类网络结构,可分为 4 个阶段,首先是视频信息的多模态 Embedding,形成多帧的特征,然后经过一个基于聚类和残差的 NeXtVLAD 融合网络,这个网络目前比较常用和性能不错,融合出来就是一个单帧的 feature,然后将多模态信息进行连接,通过 FC 做映射,另外还有一个 Gating 的过程,Gating 过程的作用就是发掘各个维度之间关联的信息,然后有选择性地增强一些维度,抑制一些无关的维度,调整之后的信息会送到一个分类网络,这里比较常用就是 MoE ( 多专家的系统 ),最终会得到一个预测结果。
2. 多模态视频分类算法的改进

我们认为多模态特征是影响整个网络的基础,所以现在这个方面做了一些努力。改进思路主要包括特征、特征融合、LOSS 和一些训练技巧方面。从前期提到的问题来看,大家主要关注对特征融合的优化,对特征的改进比较少,我们之前使用的预训练的模型,效果也不错,一般是预训练的 V3 或 Xception 网络结构。
❶ 多模态视频分类算法的特征改进

但是,我们觉得基础特征肯定是影响整个网络性能的最基础信息。举个简单的例子,如上面两张图,在节目分类维度也是比较容易理解:人物的人脸、服饰、场景等信息,是区分节目的基础信息。我们需要一个高效、鲁棒性强的技术特征 Embedding 网络来提取这些信息。之前通过热力图的分析,Embedding 预训练模型多关注一些人脸和人体,对背景关注的不多,在有些依赖场景差异来区分的分类,预训练模型会容易达标性能的上限。
我们常用的模态有视频、文本和音频,所以我们对网络的提升也是基于对网络的影响和提升度,首先是图像帧、再次是文本,接下来是音频,音频在某些场合还是比较有用的,但总体它的影响度并不是特别大。
特征改进主要有这样几个目标:
- 细粒度的表征领域,特别是对节目分类
- 信息要涵盖全面
- 扩展性好:只有上述两项都做到,信息的扩展性才好,这里强调的扩展性也是针对节目分类的,因为每天都有新剧产生,要保证模型性能的基本稳定,这样就需要更精细全面的信息提取能力。
在改进措施方面,主要包括三个方面:
- 改进基础网络 backbone,我们会选择优秀高效的网络结构
- 选择优秀数据增广的策略,包括半监督和无监督,在数据增广也有比较多的应用
- 训练方法方面,主要尝试了分类监督的方法和无监督的方法
❷ 特征改进:backbone 选择–EfficientNet
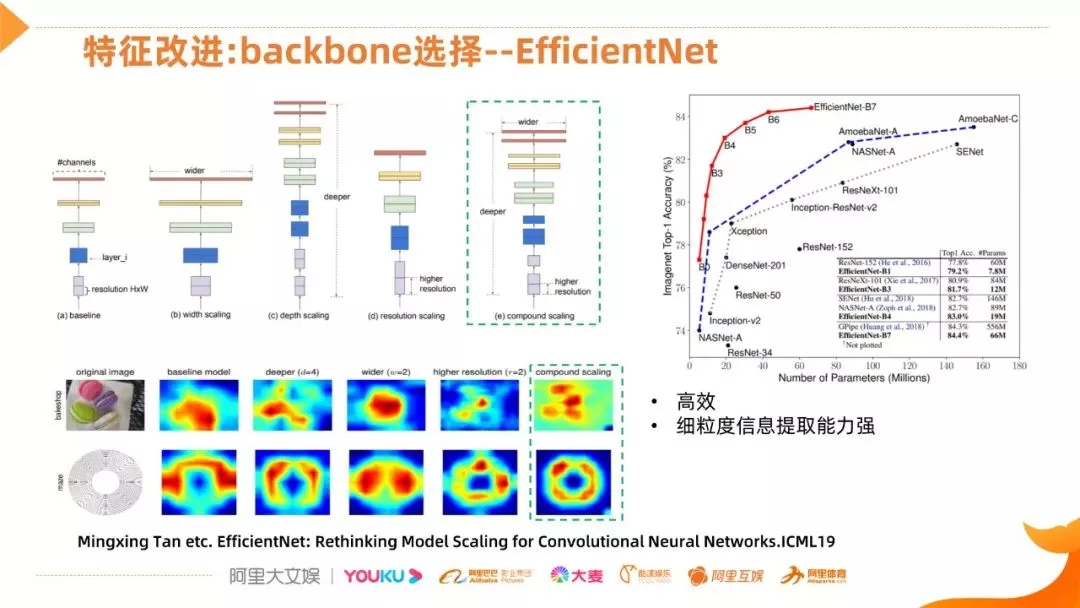
首选介绍一下我们在选择优秀 backbone 的尝试,最终选择了 EfficientNet 网络,主要有两点,它在性能和效率方面做了比较好的权衡,另外从文章可以看出对细粒度的抽取能力,也是比较好的。首先看一下右边的性能结果,横轴是网络参数,纵轴是 Top-1 的准确率,可以看出它的性价比远好于其他网络的,包括常用的 Xception 网络、残差网络,NAS 搜索的网络。EfficientNet 网络的思路也是比较简单、直接,因为它认为影响网络的三个维度,包括网络的深度、宽度和输入的分辨率,并不是独立的,是相互影响的,举个简单的例子,如果图像的分辨率不变的话,将这个网络进行加深的话,对后面更高层的计算是比较冗余的。EfficientNet 网络就是通过暴力搜索的方式,得到这三个方面的最佳配置,具体的搜索也是通过 NAS 的套路。最终的结果,效率还是比较 OK 的,对细粒度信息提取能力来说,通过比较论文中饼干和转盘两个例子,最后一列就是 EfficientNet 的热力图的表现,它的高显影区域跟物体比较切合。
❸ 特征改进:数据增广
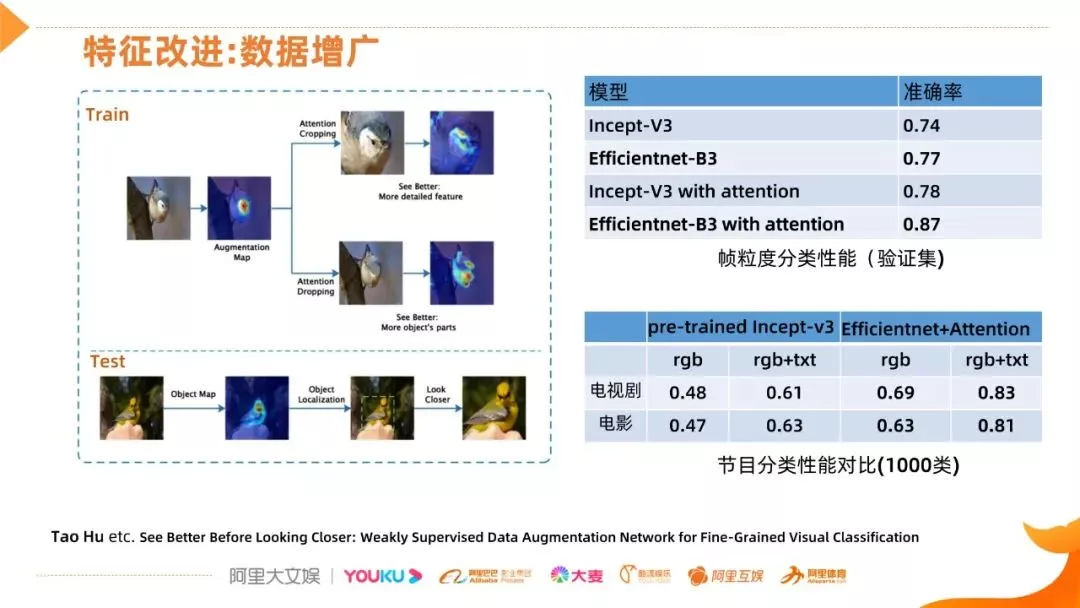
在数据增广方面,主要参考这篇文章,基本思路想通过一些措施使这个网络能学习到更丰富、更细节的信息,比如看下面这个分支,它首先得到 Augmentation Map,然后擦除高显影的区域,这里叫 Attention Dropping,Dropping 之后的图像再送到网络学习,眼睛和嘴是直接有帮助的,但其他部位也是有区分信息的,这样网络可以学习更多其他部位的信息。另外还有一个分支,就是 Cropping,就是对网络辨析能力有帮助的部位进行放大,这样可以看得更清楚,也是提升网络对细节分分辨能力的措施。下面就是测试阶段,也是根据热力图响应,扣出高显影区域,也会提取特征,这样两个特征结合,得到很好的细粒度理解。我们主要借鉴训练阶段的这两个操作。我们从图像分类和节目分类两方面来展示了性能的提升情况,从对比结果看,首先好的 backbone 能带来不错的性能提升 ( 0.74->0.77 ),加入 attention 之后又带来了更大的提升 ( 0.77->0.87 ),而且也显示出了优秀 backbone 的巨大提升潜力 ( 0.04 vs 0.10 )。
❹ 特征改进:训练方法

在训练方式上,主要是基于分类和无监督,在基于分类任务的训练方式有一些缺点,不像 imagenet 中每个类都有共同的特点,节目分类问题中,同一节目视频帧的信息方差比较大,比如说,《乡村爱情故事》和《女人当官》有主要人物的帧,也有背景的帧,这两种帧的信息差异非常大,如果强制分成一类的话,Embedding 就比较接近,对网络产生一些困惑,从结果看也会丢失了一些信息,比如说丢失背景。另一个是基于分类的任务,可能学到一些非本质的信息,如 Logo 或黑边,这样会导致特征的扩展性比较差,在大类别的分类上很快就达到性能上限。
对比来看,按无监督方式的训练,前面的缺点就没有了。目前一个基本的思路就是 instance 级别的区分,比如这四张图,每一帧都是不同的类,会尽量提取里面的信息,这样可以得到更丰富的信息,比较好的扩展性。
❺ 特征改进:基于无监督的特征学习方式

目前无监督的特征学习方式主要参考 Kaiming He 团队的论文,现在主要流行 instance 的分类框架,首先利用数据增广产生不同的 view,学习目标是同一图片不同 view 的 embedding 距离尽量近,不同图片的 embedding 距离尽量远。
大致介绍一下这篇文章的流程,增广后的图像利用 encoder 生成 embedding,在 embedding 空间用对比 loss 来更新 encoder 的参数进行学习。这篇文章的主要特点之一是:query 和 key 对应了两个不同的 encoder,key 对应的 encoder 是将 queue 对应的 encoder 参数用滑动平均的方式得到的 ( momentum encoder )。这样做的原因是,如果两个 encoder 一样,因为一般训练的时候采用 batch 的方式,它们生成的 embedding 浮动比较大,这样可比性比较差。对于采用平均方式得到的 encoder 生成的特征会更加稳定,可比性比较好,更有利于参数的学习。
Loss 采用的是比较常用的对比 Loss,这里 q 和 k+ 代表正样本对,k+ 是 q 这个图片通过数据增广生成的,q 和k_i是不同的图片,是负样本对。同一个数据源的两张图片是同一个类,不同图片的是不同的类,这样就可以通过 softmax 的方式进行监督,最终转换成了一个非常极端的分类任务。
另一个创新是,采用 embedding 的队列,保留了最新的特征,这样有比较好的可比性,得到一个更精细的特征提取网络,最终输出的是 momentum encoder。
❻ 特征改进:实验结果和结论
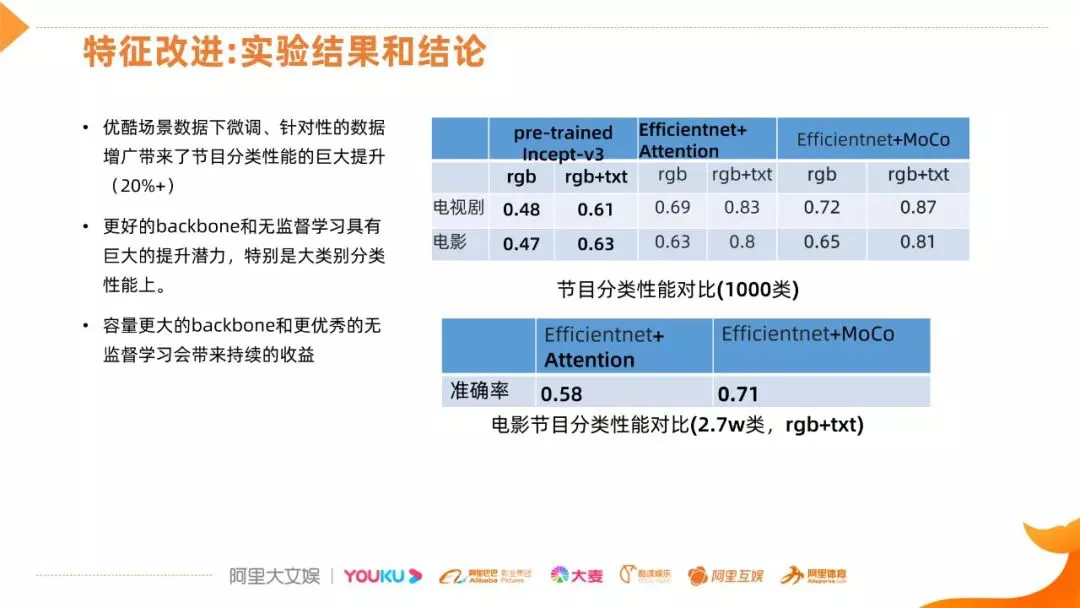
看一下通过 MoCo 方法得到的一个性能,相对于 Attention 的方法,moco 特征有所提升,但是提升不是特别的明显 ( 0.69->0.72 ),但是将分类数从 1000 类增加到 2.7 万类,分类性能提升了 13 个点。从对比的结果来看,有三点结论:
- 对比预训练的模型下,在优酷场景数据下微调,针对性的数据增广在节目分类问题上带来了 20% 以上的提升;
- 更好的基础网络和无监督学习具有巨大的提升潜力的,特别是在大类别分类性能上;
- 后续优化的方向,采用容量更大的网络和更优秀的无监督学习,会带来更持续的收益。
❼ 特征改进:Case 分析

经过这些优化后,特征的细粒度的区分能力有了很大的增强。上面两张图是预训练网络和 EffiNet+Attention 网络的结果,第一张图实际上是产科男医生,PreTrained 识别为急诊科医生,第二张的甄嬛传识别为康熙王朝。后面这两图对比了更难的图片,加勒比海盗 2 和 3 需要更精细的区分能力,才能得到更好的分类结果。
❽ 特征改进:踩坑记
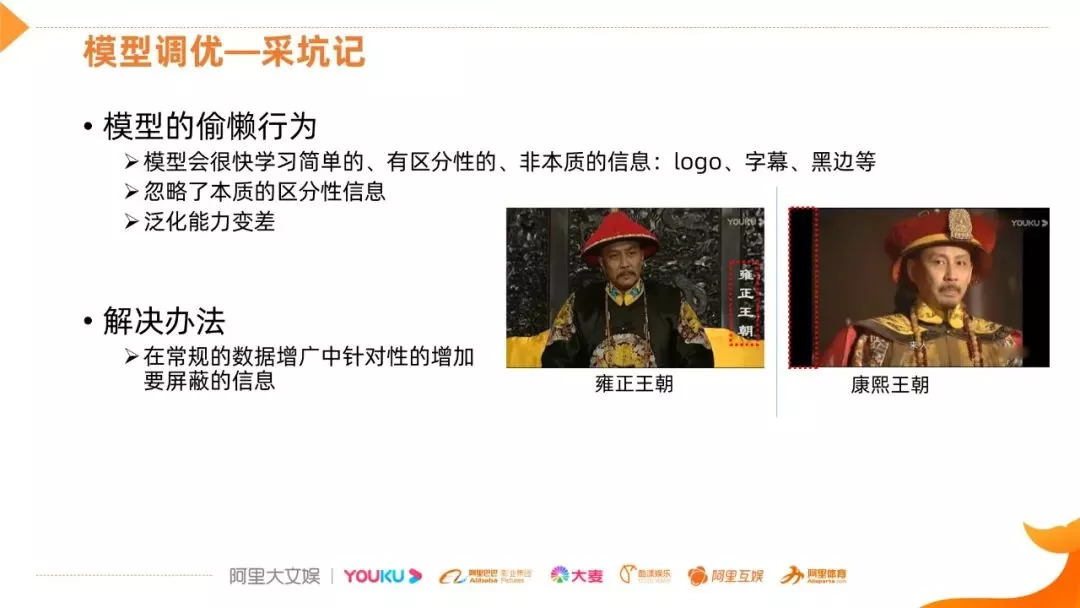
最后,分享下我们在模型调优过程中踩的坑,首先模型的偷懒行为,所谓的偷懒,特别是对于分类任务来说,模型会很快学习到一些简单的,有区分性的信息,但这些信息可能是非本质的,比如字幕信息、黑边、logo 的信息,对雍正王朝和康熙王朝两个类,网络很容易就学到了黑边这个区分性很强的信息,如果不对这些信息做处理,得到的模型的泛化能力会很差的。解决的方法,一个是在常规的数据增广中针对性的增加要屏蔽的信息,像前面提到的 Attention Dropping 和 Augmentation Map 等方法,另一种方法是我们会对所有的数据加一些黑边或 logo,就是你想抑制哪些信息,就普遍性的增加这些信息,使其没有差别性。
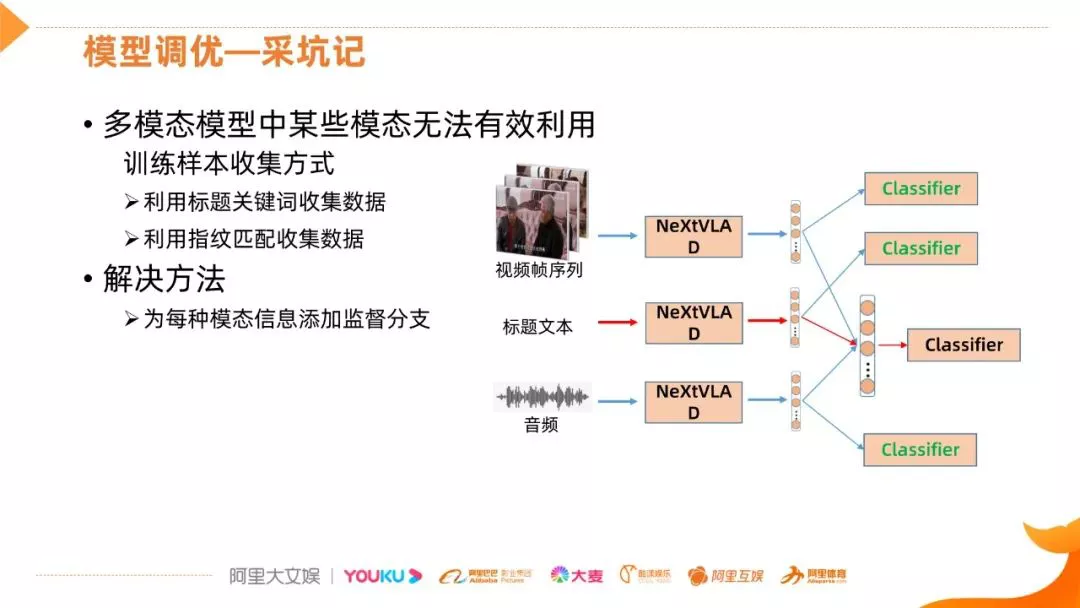
第二点是多模态模型中的偷懒行为,主要跟训练样本的收集有关,运营一般会利用标题关键词收集数据,比如收集相声的数据,会用"德云社"、“郭德纲"等来收集样本,这些样本扔到多模态网络的话,标题信息的分支会很快收敛的,虽然网络的分类性能比较好,但最终学习到的网络会忽略其他维度的信息,这样对标题中没有这些关键词的视频,分类性能就很差,泛化能力差;同样,我们的训练样本也会用到指纹匹配的数据,指纹匹配得到的样本相对于那些经过编辑的视频,画面的多样性就稍差一些,分类网络学习中也会出现类似标题关键词的问题,但并不很严重。解决方法是为每类模态信息增加监督分类器,它们的 Loss 会加在一起训练,这样的好处是其中的一个分支的 Loss 比较小的话,其他分支的 Loss 比较大,最终优化的结果是,各个信息分支的 loss 都很低,这样就能促使网络充分利用各个模态的信息。
▌思考与后续规划
1. 总结和思考
总结来说,多模态模型可以通过基础特征的优化大幅提升分类性能,是基础中的基础。 我们认为特征优化的核心目标是提升特征模型对本质信息的提取能力。

另外,对于基于 ins
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E9%98%BF%E9%87%8C%E6%96%87%E5%A8%B1%E5%A4%9A%E6%A8%A1%E6%80%81%E8%A7%86%E9%A2%91%E5%88%86%E7%B1%BB%E7%AE%97%E6%B3%95%E4%B8%AD%E7%9A%84%E7%89%B9%E5%BE%81%E6%94%B9%E8%BF%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


