一图胜千言解读阿里的
文章作者:石塔西
内容来源:小石的数据科学之旅@知乎专栏
出品社区:DataFun
注:欢迎投稿「行知」专栏,让您的行业知识,为行业者知。
本文是对阿里的论文《Image Matters: Visually modeling user behaviors using Advanced Model Server》 https://arxiv.org/abs/1711.06505 的解读。
初读此文的标题和摘要,又有image,又有CTR,我以为是一种新型的CNN+MLP的联合建模方法。读下来才知道,本文的重点绝不在什么图像建模上,压根就没CNN什么事。想像中的像素级别的建模根本没有出现,商品的图片利用网上可下载的预训练好的VGG16模型的某个中间层压缩成4096维向量,作为CTR模型的原始输入。
而将图片引入到推荐/搜索领域,也不是什么新鲜事。不说论文Related Works中提到的工作,我自己就做过基于图片的向量化召回,结构与论文图4中的Pre-Rank DICM结构很相似,只不过用户侧不包含他之前点击过的商品图片罢了,在此略下不表。
没有提出新的图像建模方法,也并非第一次在推荐算法中使用图片信息,那么此文的创新点到底在哪里?我觉得,本文的创新点有两个创新点:
-
之前的工作尽管也在推荐/搜索算法中引入了图片信息,可是那些图片只用于物料侧,用于丰富商品、文章的特征表示。而阿里的这篇论文,是第一次将图片用于用户侧建模,基于用户历史点击过的图片(user behavior images)来建模用户的视觉偏好。
-
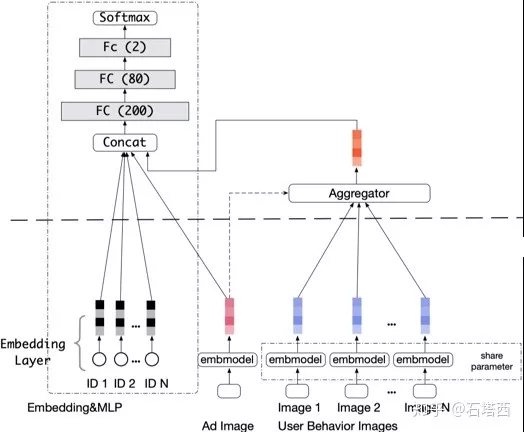
接下来会看到,将图片加入到用户侧建模,理论上并不复杂,理论上用传统PS也可以实现,起码跑个实验,发篇论文应该不成问题。但是,如果应用到实际系统,图片特征引入的大数据量成为技术瓶颈。为此,阿里团队为传统PS的server也增加了“模型训练”功能,并称新结构为Advanced Model Server (AMS)。
基于历史点击图片建模用户视觉偏好
先谈一下第一个“小创新”。之所以说其“小”,是因为通过预训练的CNN模型提取特征后,每张图片用一个高维(比如4096)稠密向量来表示。这些图片向量,与常见的稀疏ID类特征经过embedding得到的稠密向量,没有质的区别(量的区别,下文会提到),完全可以复用以前处理ID embedding的方法(如pooling, attention)来处理。
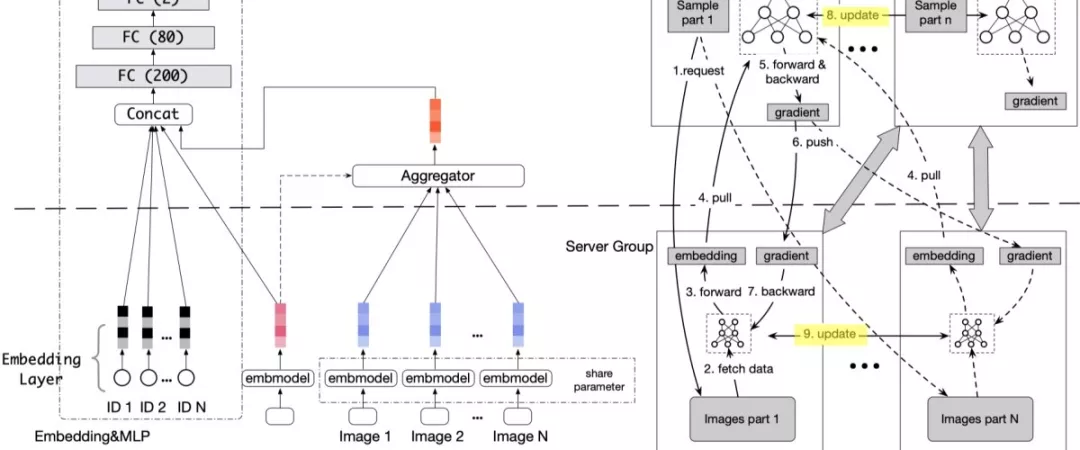
Deep Image CTR Model(DICM)的具体结构如下所示
DICM架构图
-
如果只看左边,就是推荐/搜索中常见的Embedding+MLP结构。注意上图中的Embedding+MLP结构只是实际系统的简化版本,实际系统中可以替换成Wide&Deep, DIN, DIEN等这些“高大上”的东西。
-
假设一个满足要求的图片embedding model已经ready,即图中的embmodel。商品的缩略图,经过embmodel压缩,得到商品的图片信息(图中的粉红色块)
-
右边部分,负责利用图片建模用户。将每个用户点击过的图片(user behavior image),经过embmodel进行压缩(图中的蓝色块)。它们与商品图片(ad image)的embedding结果(粉红色块)经过attentive pooling合并成一个向量(桔色块)表示用户的视觉偏好
-
将用户点击过的多张图片的向量(蓝色)合并成一个向量(桔色),其思路与Deep Interest Network 基于attention的pooling机制大同小异,只不过要同时考虑“id类特征”与“商品图片”对用户历史点击图片的attention,称为MultiQueryAttentivePooling。
-
第1步得到基于id特征的embedding结果,与第2步得到的商品图片(ad image)的embedding结果(粉红色),与第3步得到的表示用户兴趣偏好的向量(桔红色),拼接起来,传入MLP,进行充分的交互
这个模型的优势在于:
-
之前的模型只考虑了传统的ID类特征和物料的图像信息,这次加入了用户的视觉偏好,补齐了一块信息短板
-
不仅如此,通过MLP,将传统的ID类特征、物料的图像信息、用户的视觉偏好进行充分交互,能够发现更多的pattern。
-
基于用户历史访问的item id来建模用户的兴趣,始终有“冷启动”问题。如果用户访问过一个embedding matrix中不存在的item,这部分信息只能损失掉。而基于用户历史访问的图片来建模,类似于content-based modeling,商品虽然是新的,但是其使用的图片与模型之前见过的图片却很相似,从而减轻了“冷启动”问题。
综上可见,DICM的思路、结构都很简单。但是,上面的描述埋了个大伏笔:那个图片嵌入模型embmodel如何设计?没有加入图片、只有稀疏的ID类特征时,Embedding+MLP可以通过Parameter Server来分布式训练。现在这个embmodel,是否还可以在PS上训练?在回答这个问题之前,让我们先看看稀疏ID特征Embedding+MLP在传统的PS上是如何训练的?
稀疏ID特征Embedding+MLP在传统的PS上是如何训练的?
介绍PS的论文、博客汗牛充栋,实在论不上我在这里炒冷饭,但是,我还是要将我实践过的“基于PS训练的DNN推荐算法”,在这里简单介绍一下,因为我觉得它与《Scaling Distributed Machine Learning with the Parameter Server》所介绍的“经典”PS还是稍稍有所不同,与同行们探讨。
基于PS的分布式训练的思想还是很简单的:
-
一开始是data parallelism。每台worker只利用本地的训练数据前代、回代,计算gradient,并发往server。Server汇总(平均)各worker发来的gradient,更新模型,并把更新过的模型同步给各worker。这里有一个前提,就是数据量超大,但是模型足够小,单台server的内存足以容纳。
-
但是,推荐/搜索系统使用超大规模的LR模型,模型参数之多,已经是单台server无法容纳的了。这时Parameter Server才应运而生,它同时结合了data parallelism与model parallelism
-
Data parallelism:训练数据依然分布地存储在各台worker node上,各worker node也只用本地数据进行计算。
-
Model parallelism:一来模型之大,单台server已经无法容纳,所以多台server组成一个分布式的key-value数据库,共同容纳、更新模型参数;二来,由于推荐/搜索的特征超级稀疏,各worker上的训练数据只涵盖了一部分特征,因此每个worker与server之间也没有必要同步完整模型,而只需要同步该worker的本地训练数据所能够涵盖的那一部分模型。
所以按照我的理解,PS最擅长的是训练稀疏数据集上的算法,比如超大规模LR的CTR预估。但是,基于DNN的推荐/搜索算法,常见模式是稀疏ID特征Embedding+MLP,稍稍有所不同
-
稀疏ID特征Embedding,是使用PS的理想对象:超大的embedding矩阵已经无法容纳于单台机器中,需要分布式的key-value数据库共同存储;数据稀疏,各worker上的训练数据只涵盖一部分ID特征,自然也只需要和server同步这一部分ID的embedding向量。
-
MLP部分,稍稍不同
-
和计算机视觉中动辄几百层的深网络相比,根据我的经验,纵使工业级别的推荐/搜索算法,MLP也就是3~4层而已,否则就有过拟合的风险。这等“小浅网络”可以容纳于单台机器的内存中,不需要分布式存储。
-
与每台worker只需要与server同步本地所需要的部分embedding不同,MLP是一个整体,每台worker都需要与server同步完整MLP的全部参数,不会只同步局部模型。
所以,在我的实践中
-
稀疏ID特征Embedding,就是标准的PS做法,用key-value来存储。Key就是id feature,value就是其对应的embedding向量;
-
MLP部分,我用一个KEY_FOR_ALL_MLP在server中存储MLP的所有参数(一个很大,但单机足以容纳的向量),以完成worker之间对MLP参数的同步。
实际上,对Embedding和MLP不同特性的论述,在《Deep Interest Network for Click-Through Rate Prediction》中也有所论述。阿里的X-DeepLearning平台
-
用Distributed Embedding Layer实现了分布式的key-value数据库来存储embedding。应该是标准的PS做法。
-
用Local Backend在单机上训练MLP。如何实现各worker(i.e., local backend)的MLP的同步?是否和我的做法类似,用一个key在server上存储MLP的所有参数?目前尚不得而知,还需要继续研究。
加入图片特征后,能否继续在PS上训练?
按原论文的说法,自然是不能,所以才提出了AMS。一开始,我以为”PS不支持图片”是“质”的不同,即PS主要针对稀疏特征,而图片是稠密数据。但是,读完文章之后,发现之前的想法是错误的,稀疏ID特征与图片特征在稀疏性是统一的
-
某个worker node上训练样本集,所涵盖的item id与item image,只是所有item ids/images的一部分,从这个角度来说,item id/image都是稀疏的,为使用PS架构提供了可能性
-
item image经过pre-trained CNN model预处理,参与DICM训练时,已经是固定长度的稠密向量。Item id也需要embedding成稠密向量。从这个角度来说,item id/image又都是稠密的。
正因为稀疏ID特征与图片特征,本质上没有什么不同,因此PS无须修改,就可以用于训练包含图片特征的CTR模型(起码理论上行得通),就是文中所谓的store-in-server模式
-
图片特征存入PS中的server,key是image index,value是经过VGG16提取出来的稠密向量
-
训练数据存放在各worker上,其中图片部分只存储image index
-
训练中,每个worker根据各自本地的训练集所包含的image index,向server请求各自所需的image的embedding,训练自己的MLP
一切看上去很美好,直到我们审视VGG16提取出来的image embedding到底有多长?
-
原论文中提到,经过试验,阿里团队最终选择了FC6的输出,是一个4096长的浮点数向量。而这仅仅是一张图片,每次迭代中,worker/server需要通信的数据量是mini-batch size * 单用户历史点击图片数 (i.e., 通常是几十到上百) * 4096个浮点数。按照原论文中table 2的统计,那是5G的通讯量。
-
而一个ID特征的embedding才用12维的向量来表示。也就是说,引入image后,通讯量增长了4096/12=341倍。
(或许有心的读者问,既然4096的image embedding会造成如此大的通讯压力,那为什么不选择vgg16中小一些层的输出呢?因为vgg16是针对ImageNet训练好的,而ImageNet中的图片与淘宝的商品图片还是有不小的差距(淘宝的商品图片应该很少会出现海象与鸭嘴兽吧),因此需要提取出来的image embedding足够长,以更好地保留一些原始信息。原论文中也尝试过提取1000维的向量,性能上有较大损失。)
正是因为原始图片embedding太大了,给通信造成巨大压力,才促使阿里团队在server上也增加了一个“压缩”模型,从而将PS升级为AMS。
AMS的技术细节,将在下一节详细说明。这里,我觉得需要强调一下,由于加入图片而需要在AMS,而不是PS上训练,这个变化是“量”变引起的,而不是因为原来的ID特征与图片这样的多媒体特征在“质”上有什么不同。比如,在这个例子中,
-
使用AMS是因为image的原始embedding由4096个浮点数组成,太大了
-
之所以需要4096个浮点数,是因为vgg16是针对ImageNet训练的,与淘宝图片相差较大,所以需要保留较多的原始信息
-
如果淘宝专门训练一个针对商品图片的分类模型,那么就有可能拿某个更接近loss层、更小
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%80%E5%9B%BE%E8%83%9C%E5%8D%83%E8%A8%80%E8%A7%A3%E8%AF%BB%E9%98%BF%E9%87%8C%E7%9A%84/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


