不仅仅用通过人工评估得到更好的推荐
作者:Edwin Chen
编译:ronghuaiyang
导读
导读
用CTR来评估推荐算法是一个非常常用的度量,但并非是最好的度量。
假设你正在为一个新在线网站构建一个推荐算法。你如何衡量它的质量,以确保它发送给用户相关和个性化的内容?刚开始的时候,你希望点击率可以进行衡量,但经过一番思考,它到底是不是最好的衡量标准还不清楚。
以谷歌的搜索引擎为例 在很多情况下,提高搜索结果的质量会降低点击率!例如,对于像 Barack Obama 什么时候出生?用户永远不需要点击,因为问题在页面上就得到回答了。
以 Twitter 为例,有一天它可能会向你推荐有趣的 tweet 像点击率这样的指标,甚至是收藏和转发的数量,可能会优化以显示快速的笑话和有趣的猫的图片。但是,像 reddit 这样的网站是 Twitter 真正想要的吗?对很多人来说,Twitter 最初是一个新闻网站,所以用户可能更喜欢看到更深入、更有趣的内容的链接,即使他们不太可能点击每一条推荐。
以 eBay 为例,它可以帮你找到你想买的产品 CTR 是个好方法吗?也许不是:更多的点击可能表明你很难找到你要找的东西。收入怎么样?这可能也不太理想:从用户的角度来看,希望以尽可能低的价格进行购买,通过优化收益,eBay 可能会将你转向更昂贵的产品,从长远来看,这将使你成为非常用客户。
等等。
因此,在许多网站上,还不清楚如何使用诸如点击率、收入、停留时间等指标来衡量个性化和推荐的质量。工程师该做什么?
那么,考虑一下这样一个事实:其中许多是“相关性”算法。谷歌希望向你显示相关的搜索结果。Twitter 想向你展示相关的推文和广告,Netflix 想向你推荐相关的电影。LinkedIn 希望找到相关的人关注你。 那么,为什么我们不去衡量我们的模型的相关性呢?
所以为了解决这个问题,我要讲一个人类的评估方法来度量个性化和发现产品的性能。我会使用 Amazon 上相关书籍推荐的例子来贯穿文章的剩余部分。
Amazon,不再局限于基于日志的度量
(让我们继续讨论为什么基于日志的度量常常是不完善的相关性和质量度量,因为这一点很重要,但是很难理解。)
所以,以亚马逊的顾客为例,他们买了这个商品,也买了这个功能,它会向你展示相关的书籍。

要度量它的有效性,标准的方法是进行一个现场实验,并度量收入或 CTR 等指标的变化。
但想象一下,我们突然把亚马逊所有的图书推荐都换成了色情内容。会发生什么?
或者假设我们把亚马逊所有的相关书籍都换成更炫、更贵的商品。同样,随着更炫的内容吸引眼球,点击率和收入可能会增加。但这只是短期的刺激吗?从长远来看,这种变化可能会降低总销售额,因为消费者开始发现亚马逊的产品对他们的口味来说太贵了,于是他们转向了其他市场。
像这样的场景是机器学习的模拟,把广告变成闪烁的幕布。虽然一开始它们可能会增加点击量和浏览量,但它们可能不会为将来优化用户的幸福度或网站的质量。那么,我们如何才能避免这些问题,并确保我们的建议始终保持高质量呢?毕竟,这是一个与书籍相关的算法 —— 那么,为什么我们坚持使用实际的实验和类似于 CTR 的指标,却没有检查我们的推荐的相关性呢?
人类的评估
解决方案:让我们将人员注入到流程中。计算机不能度量相关关系,但人当然可以。
例如,在下面的截图中,我让一名工作人员(在我自己建立的一个众包平台上)给前三名购买了这款产品的顾客评分,这些顾客既买了这本书,还买了推荐的书。
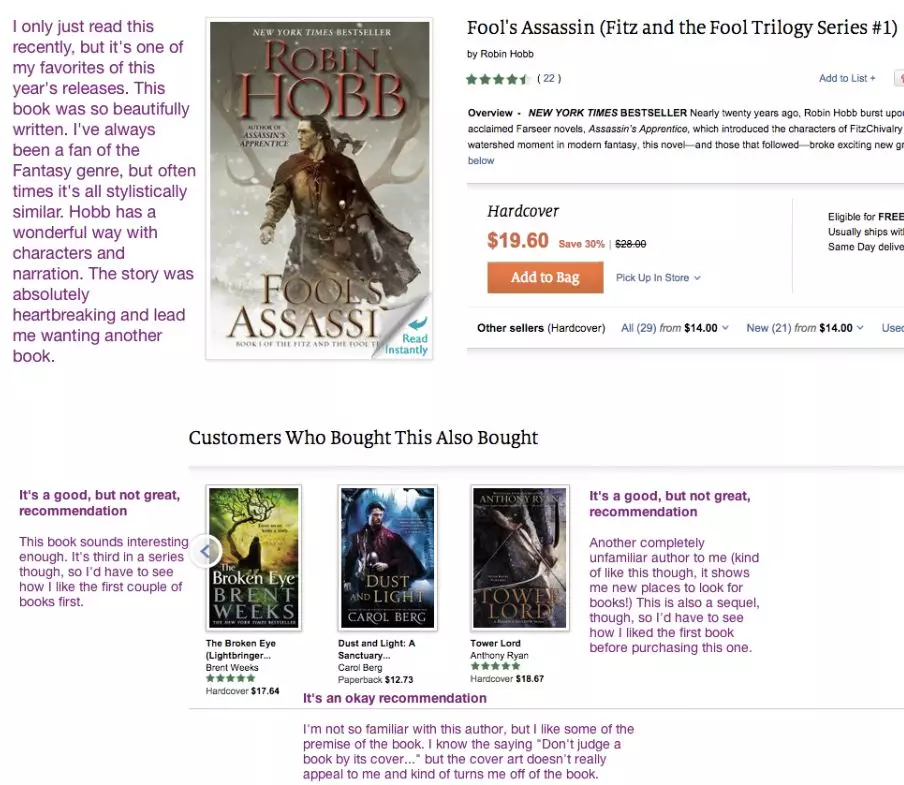
从截图中复制文本:
-
Fool’s Assassin, by Robin Hobb.。(原书),我最近才读到这本书,但它是我今年最喜欢的书之一。这本书写得真漂亮。我一直都是奇幻类型的粉丝,但很多时候在风格上都很相似。Hobb 对人物和叙事都有很好的处理方式。这个故事绝对令人心碎,让我想再看一本书。
-
The Broken Eye (Lightbringer Series #3), by Brent Weeks. (第一相关的书),这是一个好的推荐,但不是非常好。这本书听起来很有趣。不过它是一个系列的第三本,所以我得先看看我对前几本书的感觉如何。
-
Dust and Light: A Sanctuary Novel, by Carol Berg.* (第二相关的书) 这是个不错的推荐。我对这位作者不是很熟悉,但我喜欢这本书的一些前言。我知道“不要以貌取人”这句话。但封面设计并没有真正吸引我,反而让我对这本书失去了兴趣。
-
Tower Lord, by Anthony Ryan. (第三相关的书) 这是一个不错的推荐,但不是非常好。这是另一个我完全不熟悉的作者(有点像给我展示了一个寻找书籍的新地方)不过,这也是一部续集,所以在买这本书之前,我得先看看我对第一本书的感觉如何。
这些建议还不错,但我们已经看到了一些改进的方法:
-
首先,其中的两个推荐( the Broken Eye_和_Tower Lord)是一个系列的一部分,但不是第一本。因此,一个改进是确保只显示系列介绍,除非它们是书的后续内容。
-
书的封面很重要!事实上,第二个建议看起来更像是奇幻爱情小说,而不是 Robin Hobb 倾向于写的那种奇幻。
CTR 和 revenue 当然不会给我们提供这么多的信息,也不清楚他们是否能告诉我们,我们的算法在一开始就产生了不相关的建议。并没有地方明确指出其中两本书是系列的一部分,因此这两本书的 CTR 将与系列介绍一样高。如果收入较低,就不清楚这是因为推荐不好,还是因为我们的定价算法需要改进。
所以一般来说,这里有一个方法来理解一个算法的质量:
拿一堆商品(比如 Amazon 或 Barnes & Noble 的书),生成和它们相关的兄弟书籍。
把这些生成的兄弟书籍发给一群评委(比如,通过使用 Hybrid 这样的众包平台),让他们评价这些书的相关性。
分析返回的数据。
亚马逊、Barnes & Noble 和谷歌的算法相关性
让我们把这个过程具体化。假设我是负责亚马逊客户推荐购买产品的新副总裁,我想了解产品的缺陷和亮点。
我首先让我的几百名员工拿一本他们去年喜欢的书,然后在亚马逊上找到它。然后他们会从不同的作者那里得到前三个相关书籍的推荐,在接下来的表中对它们进行评分,并解释他们的评分。
-
非常好的推荐。我一定会买的。(高 positive)
-
还不错的推荐。我可能会买。(中 positive)
-
这个推荐不太好。我可能不会买它。(中 negative)
-
很差的推荐。我绝对不会买的。(高 negative)
(注:我通常更喜欢 3 分或 5 分的表来度量)
例如,下面是一位评审人员对 Anne Rice 的_The Wolves of Midwinter_相关书籍的评论。

那么亚马逊的推荐有多好呢?事实上,相当不错:47%的评分员说他们肯定会买第一本相关的书,另外 29%的评分员说他们可能会买,只有 24%的评分员不喜欢这个推荐。
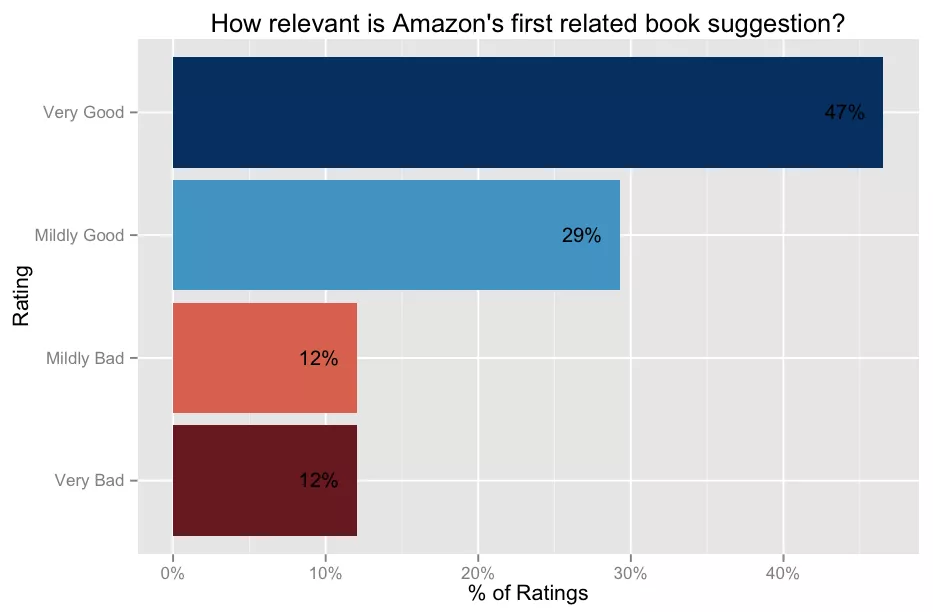
第二和第三本书的推荐,虽然有点糟糕,但似乎也表现得很好:大约 65%的评分者对它们的评价是正面的。
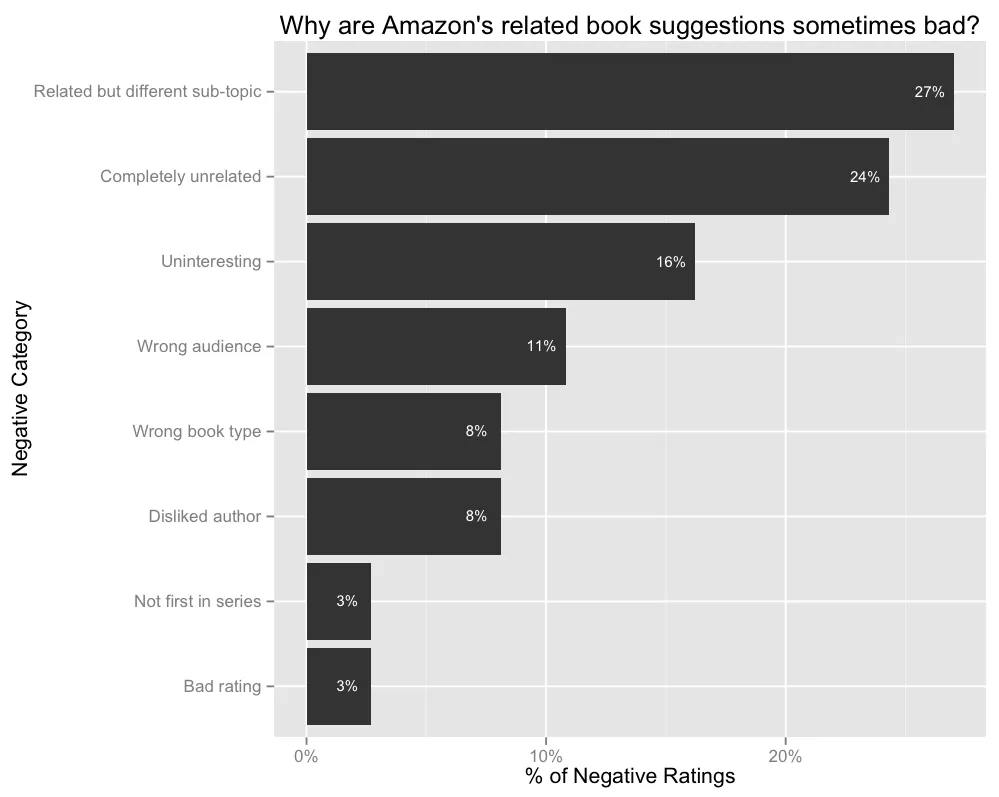
我们能从糟糕的评级中学到什么?我进行了一项后续任务,要求工作人员对相关的不好的推荐书籍进行分类。
-
**相关但是属于不同的子主题。**这些书的推荐一般都与原著相关,但属于不同的子主题,作者并不感兴趣。例如,第一个和书《孙子兵法》(名义上是一本关于战争的书,但现在已经变成了一种生活黑客的书)相关的书是_On War_,但实际上用户并不是对军事感兴趣方面:”我不会买这本书,因为它只专注于军事战争。我对那个不感兴趣。我对能帮助我在生活中成功的心理战术感兴趣。“
-
完全不相关。这些都是与原著完全无关的书籍推荐。例如,一本词典出现在《孙子兵法》的页面上。
-
不感兴趣。这些书都是相关的推荐,但它们的故事情节并不吸引评分者。“故事情节似乎不那么激动人心。我不喜欢狗,这是关于狗的。”
-
错误的受众。这些推荐的书,它们的目标读者与原著的读者有很大的不同。例如,在很多情况下,相关的推荐的书籍是一本儿童书籍,但原来的书是针对成年人的。“这似乎是一本儿童读物。如果我有个孩子,我一定会买这个,可惜我没有,所以我不需要它。”
-
错误的类型。这一类的推荐是教科书出现在小说旁边。
-
不喜欢作者。这些推荐是通过相似的作者提出的,但这个作者用户不喜欢。“我不喜欢 Amber Portwood。我绝对不想读一本她的书。“
-
不是系列的第一本。一些推荐的书可能是作者不熟悉的系列,但它们不是这个系列的第一本书。
-
评分不好。这些推荐的书在亚马逊上的评分特别低。
因此,为了改善他们的推荐,亚马逊可以尝试改进其主题模型,在其图书中添加基于年龄的特征,区分教科书和小说,并投入资源做一个系列检测器。(当然,据我所知,他们已经这么做了。)
竞争性分析
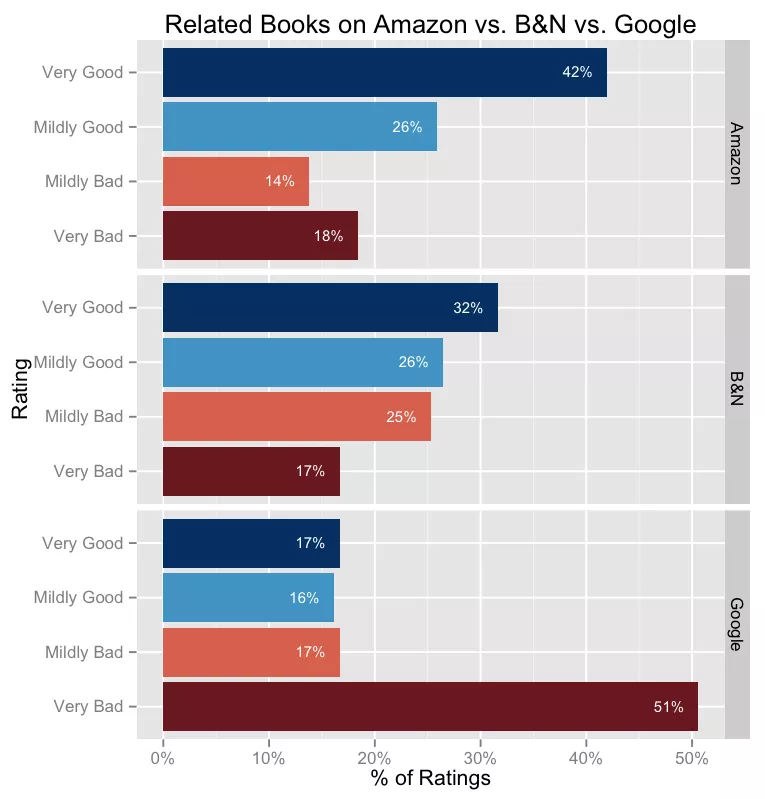
现在,我们已经大致了解了亚马逊的相关书籍推荐,以及如何改进这些推荐,就像我们可以引用一个类似于 6.2%的点击率之类的指标一样,我们现在也可以引用一个“相关性得分”,为 0.62(或其他)。那么,让我们来看看亚马逊与其他在线书店如 Barnes & Noble 和谷歌 Play 相比如何。
我采取了与上述相同的任务,但这次要求评分员也审查这两个网站的相关推荐。
简单来说
-
Barnes & noble 的算法几乎和亚马逊的一样好:前三个推荐的正确率为 58%,而亚马逊的正确率为 68%。
-
但 Play Store 的推荐非常差:谷歌的相关书籍推荐中,有高达 51%被标为很差。
为什么 Play Store 的推荐这么差?让我们看几个例子。
这是 John Green 的_The Fault in Our Stars_的页面,这是一本深受评论家喜爱的关于癌症和爱情的书(现在也是一部电影)。
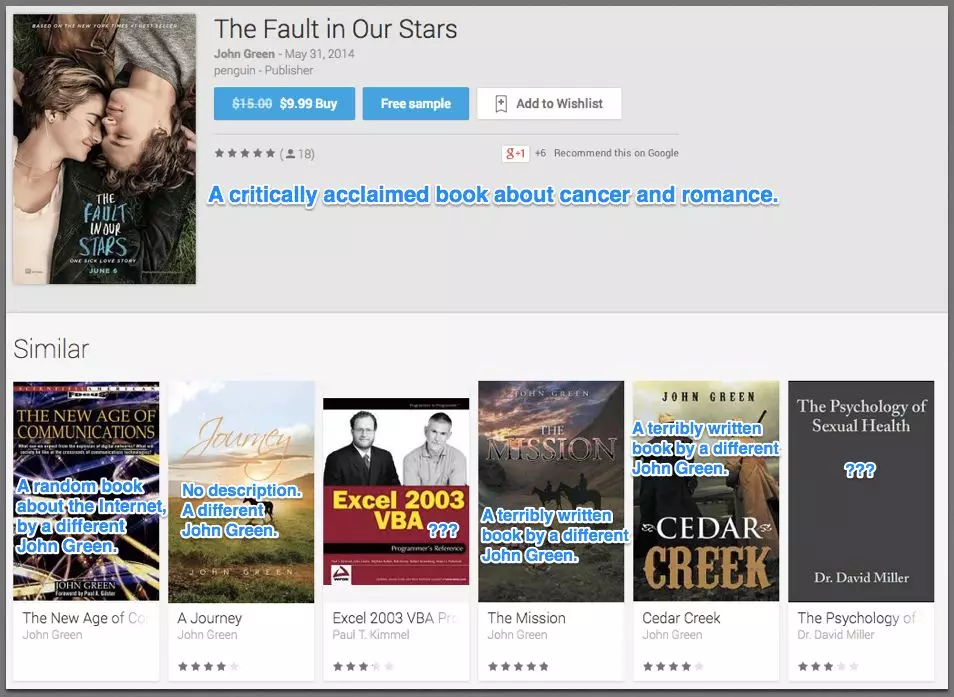
其中两个建议完全是随机的:一个是评级很差的 Excel 手册,另一个是评价很差的性健康教科书。其他的则是完全不相干的牛仔书,作者是另一位 John Green。
这是 _The Strain_的页面。这里,所有的推荐都是不同的语言的书!而且只有四个。
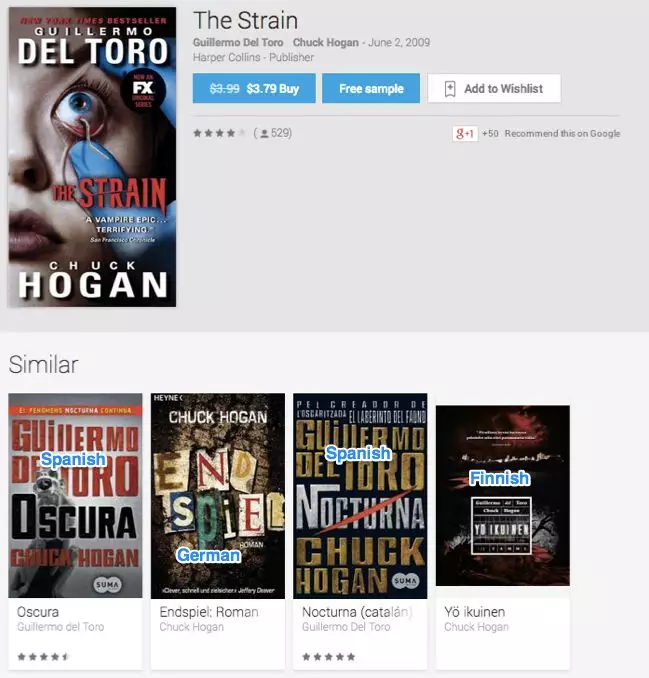
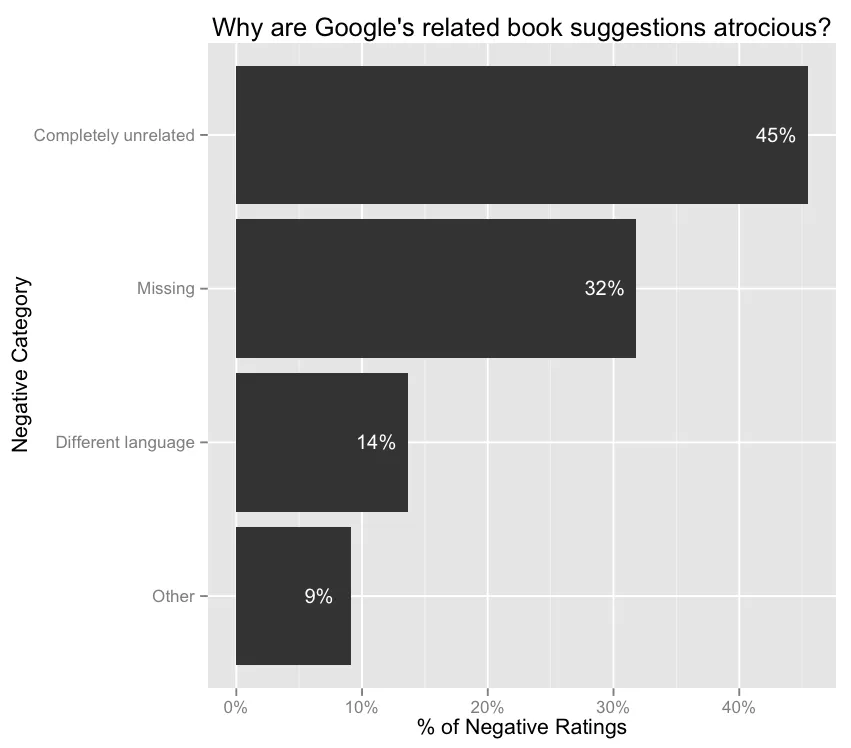
再一次要求评分员将 Play Store 所有不好的推荐进行分类……
-
45%的情况下,相关的书籍建议推荐与原书完全无关。例如:在浪漫小说的页面上显示一本物理教科书。
-
32%的情况下,根本就没有关于书的推荐。(我猜书的目录一定很有限。)
-
14%的情况下,相关书籍是不同的语言。
因此,尽管谷歌在其他地方拥有最先进的机器学习技术,但它的 Play Store 推荐实在是糟透了。
并排比较
让我们后退一步。到目前为止,我一直专注于一种“绝对”的判断范式,在这种范式中,法官在绝对范围内评估一本书与原著的相关性。这个模型对于理解 Amazon 相关书籍算法的整体质量非常有用。
然而,在许多情况下,我们希望使用人类评价来“比较”实验。例如,在很多公司里,这样的事情很常见:
-
在进行现场实验之前进行“人工评估 A/B 测试”,既可以避免意外地向用户发送错误百出的实验,也可以避免现场测试所需的长时间等待。
-
在进行启动决策时,使用人工生成的相关性评分作为实时实验指标的补充。
对于这类任务,更可取的往往是并排模式,即给评委两个选项,然后问他们哪个更好。毕竟,比较判断往往比绝对判断容易得多,而且我们可能希望在比绝对尺度更精细的层次上发现差异。
我们的想法是,我们可以给每一个评级赋值(例如,如果评分者更喜欢控制项,则为负,如果评分者更喜欢实验项,则为正),我们将这些数据汇总,形成并排的总分。然后,就像 CTR 的下降可能会阻碍实验的启动一样,负的人工评估分数也应该引起人们的担忧。
不幸的是,我没有一个简单的方法来生成并排的数据(尽管我可以在 Amazon 和 Barnes & Noble 上并排执行),所以我将省略一个例子,但是思想应该很清楚。
个性化
这是另一个微妙变化。在上面的例子中,我让评分员自己挑选一本书(一本他们在过去一年中读过并喜欢的书),然后评分,他们个人是否愿意阅读相关的推荐。
另一种方法是为评分者挑选书籍,然后更客观地对相关推荐进行评分,方法是试着设身处地为那些对起始书籍感兴趣的人着想。
哪种方法更好?正如你可能猜到的,没有明确的答案——这取决于手头的任务和目标。
第一种方法的优点:
- 更微妙。你很难设身处地地为别人着想:读《哈利·波特》的人会对《暮光之城》感兴趣吗?一方面,它们都是奇幻小说,另一方面,《暮光之城》似乎更适合女性观众。
第二种方法的优点:
-
有时候,客观性是件好事。(如果有人因为爱德华让她想起了她的男朋友而不喜欢《暮光之城》,推荐系统真的应该在乎吗?)
-
允许人们选择他们的起始书可能会对某些指标产生偏见。例如,人们更有可能选择流行的书籍进行评分,而我们可能希望在更广泛、更有代表性的目录中衡量亚马逊推荐的质量。
回顾
让我们回顾一下到目前为止所讨论的内容。
-
像点击率和收入这样的基于日志的在线指标并不一定是发现算法质量的最佳度量。例如,高点击率的项目可能只是活跃和浮华的,而不是最相关的。
-
因此,与其依赖这些代理,不如让我们通过询问一群人来直接衡量我们的推荐的相关性。
-
有两种不同的方法来发送要判断的项目。我们可以让评分者选择项目(这是个性化算法经常需要的一种方法),或者我们可以自己生成项目,通常用于更客观的任务,如搜索。这样做还有一个好处,就是可以更容易地得出受欢迎程度加权或均匀加权的相关性指标。我们也可以采取绝对判断的方法,或者使用并排的方法。
-
通过分析来自我们评估的数据,我们可以做出更好的启动决策,发现我们的算法表现很好或很差的例子,并找到改进的模式。
有什么好处和应用?
-
如前所述,像点击率和收入这样的基于日志的指标并不总是能捕捉到我们想要的信号,因此,人为生成的相关性评分(或其他维度)是有用的补充。
-
人工评�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%8D%E4%BB%85%E4%BB%85%E7%94%A8%E9%80%9A%E8%BF%87%E4%BA%BA%E5%B7%A5%E8%AF%84%E4%BC%B0%E5%BE%97%E5%88%B0%E6%9B%B4%E5%A5%BD%E7%9A%84%E6%8E%A8%E8%8D%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


