优酷提出基于图执行引擎的算法服务框架系统架构概览
背景
在阿里的业务中,有广泛的算法应用场景,也沉淀了相关的算法应用平台和工具:基础的算法引擎部分,有成熟的召回和打分预估引擎、在线实时特征服务;推荐算法应用领域,有算法实验平台 TPP(源于淘宝个性化平台),提供 Serverless 形式的算法实验平台,包括资源弹性伸缩、实验能力(代码在线发布、AB 分流、动态配置)、监控管理(完善的监控报警、流控、降级)等能力,是算法在线应用的基石。
但在实际的算法应用业务中(如优酷推荐业务),算法应用场景众多(100+ 活跃场景),需求灵活多变,如果没有一套通用业务框架抽象出通用和定制化的部分来提高算法组件的复用度,会严重拖慢算法实验的节奏。基于图引擎的算法服务框架就是为了封装这样一套框架,抽象算法在线服务的通用算子,支持运行时算法流程的装配,提升算法服务场景搭建的效率。
设计概览
算法推荐典型的在线处理执行流程是:多路粗排召回、合并、预估、打散策略。推荐服务根据用户的设备 ID 等其他必要信息进行多路并行召回,在召回引擎中粗排后,经过必要的过滤处理,截取一定数量的内容调用 Rank 引擎进行精排预估,预估结果经过一系列算法策略处理后输出最终结果。
整个过程中召回、合并、预估、打散等业务处理既有并行处理也有串行处理,可以根据业务需要灵活配置。基于图的推荐业务执行引擎是运行在算法实验平台上的执行引擎,它的典型处理流程是:在 AB 实验分桶上,通过图形化交互页面配置数据源、业务算子的执行依赖关系,并配置每个算子的运行时动态参数。
系统总体结构如下图所示,共分成五个主要模块(DAG 图执行引擎、图执行算子元件、图形化配置 DAG、图配置动态解析、Debug 调试)。
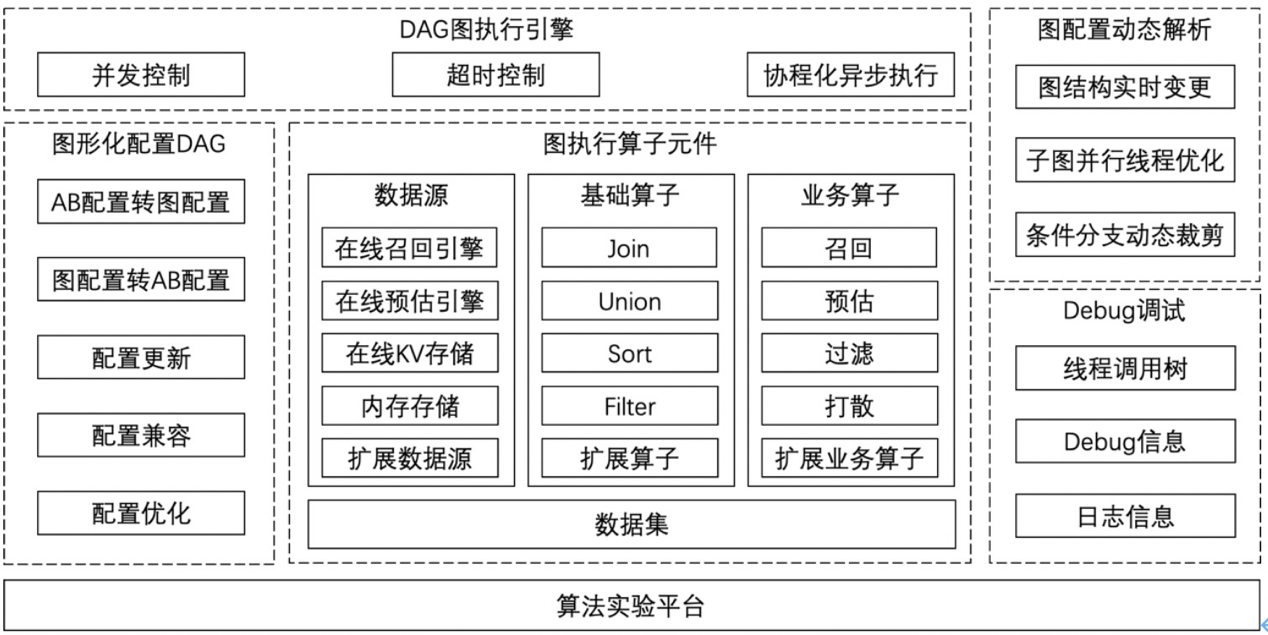
图:系统总体架构
当推荐请求到达时,引擎读取 AB 参数,根据参数上配置的算子信息,通过反射机制创建算子实例,动态组装成可运行的 DAG。根据条件分支配置,动态裁剪运行时的 DAG 实例,根据图运行占用最大线程数配置,动态调整线程复用。算子通过算法实验平台的底层协程池并行运行。
关键模块
1 图执行算子元件
1) 数据集
在 DAG 图中流转的数据统一封装为 DataSet 数据集,数据集是结构化多行二维数据的封装,在数据集上封装便利的基础算子操作。
数据集上一系列处理操作基于 Java 的 Stream API 来处理,以此达到集合处理的最好性能,将非 Action 操作延迟到最后数据处理时运行。
2) 数据源
将能够返回数据或者数据交互的二方服务封装为通用数据源,所有业务算子围绕数据源的数据进行业务开发,通用数据源包括召回数据集、在线算法需要的辅助数据集(如存放在 KV 内存存储的旁路召回数据、特征等数据)、打分预估结果集、内存数据源等。
数据源的封装通过动态参数配置方式实现通用性和可扩展性。数据查询只需要修改配置即可实现数据获取,不需要开发代码。
3) 基础算子
在 DataSet 数据集上封装的基本操作作为基础算子,比如 Join、Union、Filter、Sort、Map、Collect 等流式操作。在 DataSet 上重新封装 Stream 相关 API,便于对 DataSet 进行�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BC%98%E9%85%B7%E6%8F%90%E5%87%BA%E5%9F%BA%E4%BA%8E%E5%9B%BE%E6%89%A7%E8%A1%8C%E5%BC%95%E6%93%8E%E7%9A%84%E7%AE%97%E6%B3%95%E6%9C%8D%E5%8A%A1%E6%A1%86%E6%9E%B6%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E6%A6%82%E8%A7%88/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


