反向传播算法推导全连接神经网络
反向传播算法是人工神经网络训练时采用的一种通用方法,在现代深度学习中得到了大规模的应用。全连接神经网络(多层感知器模型,MLP),卷积神经网络(CNN),循环神经网络(RNN)中都有它的实现版本。算法从多元复合函数求导的链式法则导出,递推的计算神经网络每一层参数的梯度值。算法名称中的“误差”是指损失函数对神经网络每一层临时输出值的梯度。反向传播算法从神经网络的输出层开始,利用递推公式根据后一层的误差计算本层的误差,通过误差计算本层参数的梯度值,然后将差项传播到前一层。
反向传播算法是一个通用的思路。全连接神经网络给出的是全连接层的反向传播实现;卷积神经网络引入了卷积层和池化层,对这两种层的反向传播做了自己的处理;循环神经网络因为在各个时刻共享了权重矩阵和偏置向量,因此需要进行特殊处理,为此出现了BPTT算法,误差项沿着时间轴反向传播。
本文推导全连接神经网络的反向传播算法。首先推导一个简单神经网络的反向传播算法,接下来把它推广到更一般的情况,得到通用的反向传播算法。很多同学对市面上已有的推导过程讲解的困惑在于不清楚矩阵和向量的求导公式和来历,在这里我们避免此问题,直接根据几个浅显易懂的基本结论进行推导。在 SIGAI 后续的公众号文章中,我们将会推导卷积神经网络和循环神经网络的反向传播算法,感兴趣的读者可以关注我们的公众号。
算法的历史
反向传播算法最早出现于1986年,用于解决多层神经网络的训练问题,由Rumelhart和Hinton等人提出,这篇论文当时发表在Nature上:
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by back-propagating errors. Nature, 323(99): 533-536, 1986.
要知道,计算机的论文想发到Nature和Science上是非常困难的。笔者列举了一下发到这些期刊上的一些典型文章:
Roweis, Sam T and Saul, Lawrence K. Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500). 2000: 2323-2326.
这是流形学习的开山之作。
Tenenbaum, Joshua B and De Silva, Vin and Langford, John C. A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500). 2000: 2319-2323.
G.E.Hinton, et al. Reducing the Dimensionality of Data with Neural Networks, Science 313, 504,2006.
这是深度学习的开山之作。Hinton同志几十年如一日孜孜不倦的探索着神经网络,在最低谷的时候也毅然坚持,在这里我们先向他致敬!
下面是这篇论文的原貌(截图自原文):

单纯从数学的角度看,反向传播算法并没有什么创新,函数求导的链式法则是微积分的发明人莱布尼兹时代出现的成果。但用于多层神经网络却让这种机器学习算法真正具有了实用价值。
链式法则
在正式介绍神经网络的原理之前,先回顾一下多元函数求导的链式法则。对于如下的多元复合函数:
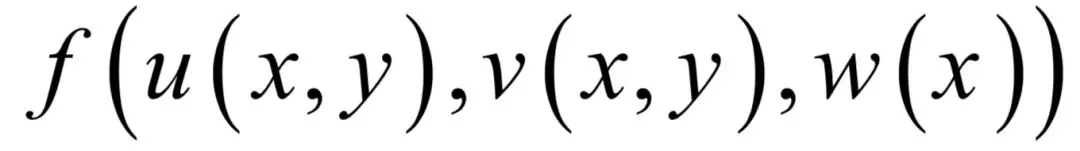
在这里,x和y是自变量。其中u,v,w是x的函数,u,v是y的函数,而f又是u,v,w的函数。根据链式法则,函数f对x和y的偏导数分别为:
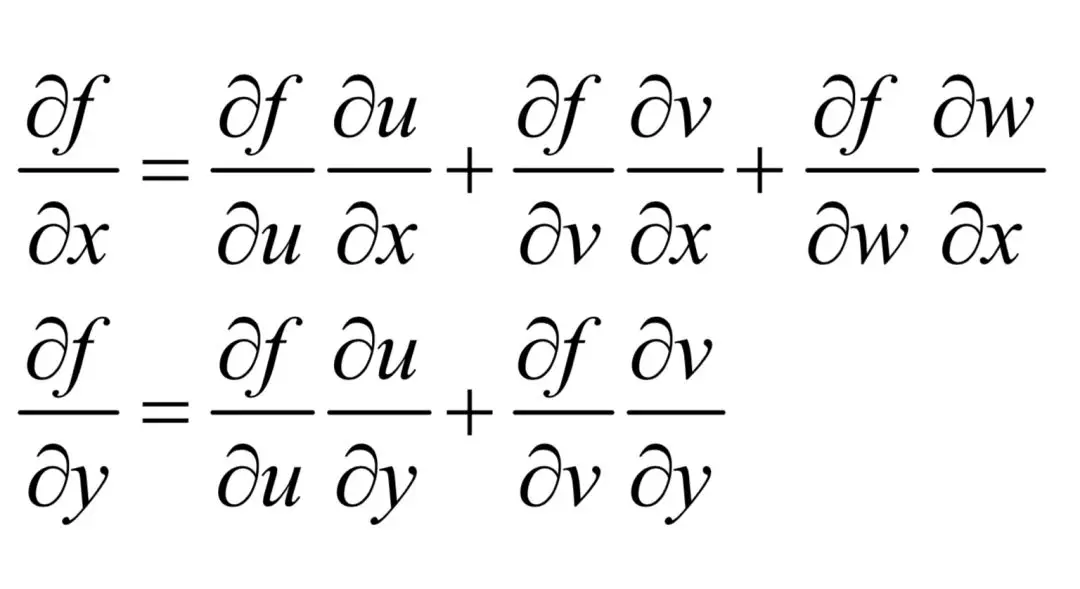
总结起来,函数自变量x的偏导数等于函数对它上一层的复合节点的偏导数(在这里是u,v,w)与这些节点对x的偏导数乘积之和。因此,我们要计算某一个自变量的偏导数,最直接的路径是找到它上一层的复合节点,根据这些节点的偏导数来计算。
神经网络原理简介
在推导算法之前,我们首先简单介绍一下人工神经网络的原理。大脑的神经元通过突触与其他神经元相连接,接收其他神经元送来的信号,经过汇总处理之后产生输出。在人工神经网络中,神经元的作用和这类似。下图是一个神经元的示意图,左侧为输入数据,右侧为输出数据:
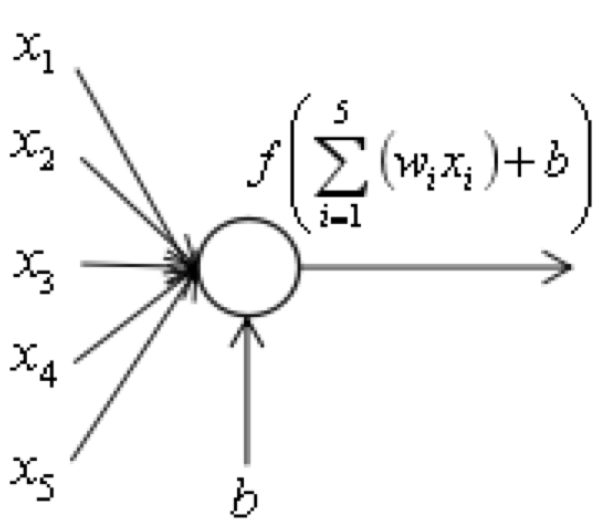
这个神经元接受的输入信号为向量(x1,x2,x3,x4,x5),向量(w1,w2,w3,w4,w5)为输入向量的组合权重,b为偏置项,是标量。神经元对输入向量进行加权求和,并加上偏置项,最后经过激活函数变换产生输出:
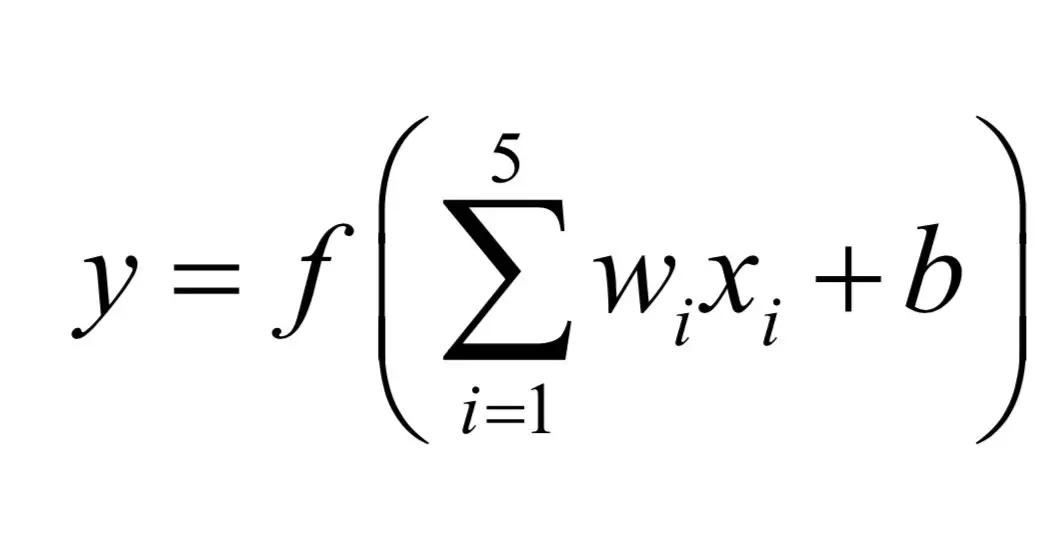
为表述简洁,我们把公式写成向量和矩阵形式。对每个神经元,它接受的来自前一层神经元的输入为向量x,本节点的权重向量为w,偏置项为b,该神经元的输出值为:
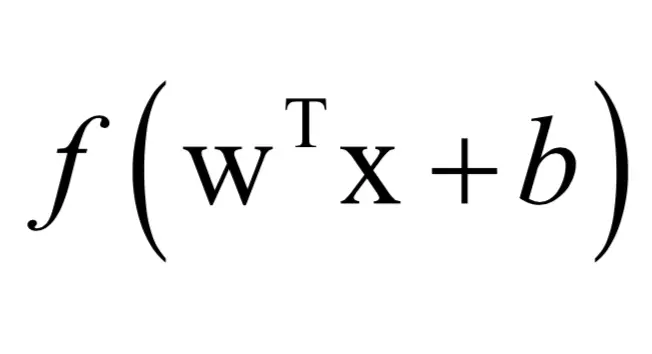
先计算输入向量与权重向量的内积,加上偏置项,再送入一个函数进行变换,得到输出。这个函数称为激活函数,典型的是sigmoid函数。为什么需要激活函数以及什么样的函数可以充当激活函数,在 SIGAI 之前的公众号文章“ 理解神经网络的激活函数”中已经进行了介绍。
神经网络一般有多个层。第一层为输入层,对应输入向量,神经元的数量等于特征向量的维数,这个层不对数据进行处理,只是将输入向量送入下一层中进行计算。中间为隐含层,可能有多个。最后是输出层,神经元的数量等于要分类的类别数,输出层的输出值被用来做分类预测。
下面我们来看一个简单神经网络的例子,如下图所示:
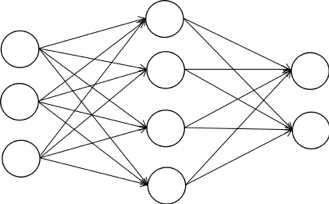
这个网络有3层。第一层是输入层,对应的输入向量为x,有3个神经元,写成分量形式为(x1,x2,x3)它不对数据做任何处理,直接原样送入下一层。中间层有4个神经元,接受的输入数据为向量x,输出向量为y,写成分量形式为(y1,y2,y3,y4,y5)。第三个层为输出层,接受的输入数据为向量y,输出向量为z,写成分量形式为(z1,z2)。第一层到第二层的权重矩阵为W(1),第二层到第三层的权重矩阵为W(2)。权重矩阵的每一行为一个权重向量,是上一层所有神经元到本层某一个神经元的连接权重,这里的上标表示层数。
如果激活函数选用sigmoid函数,则第二层神经元的输出值为:
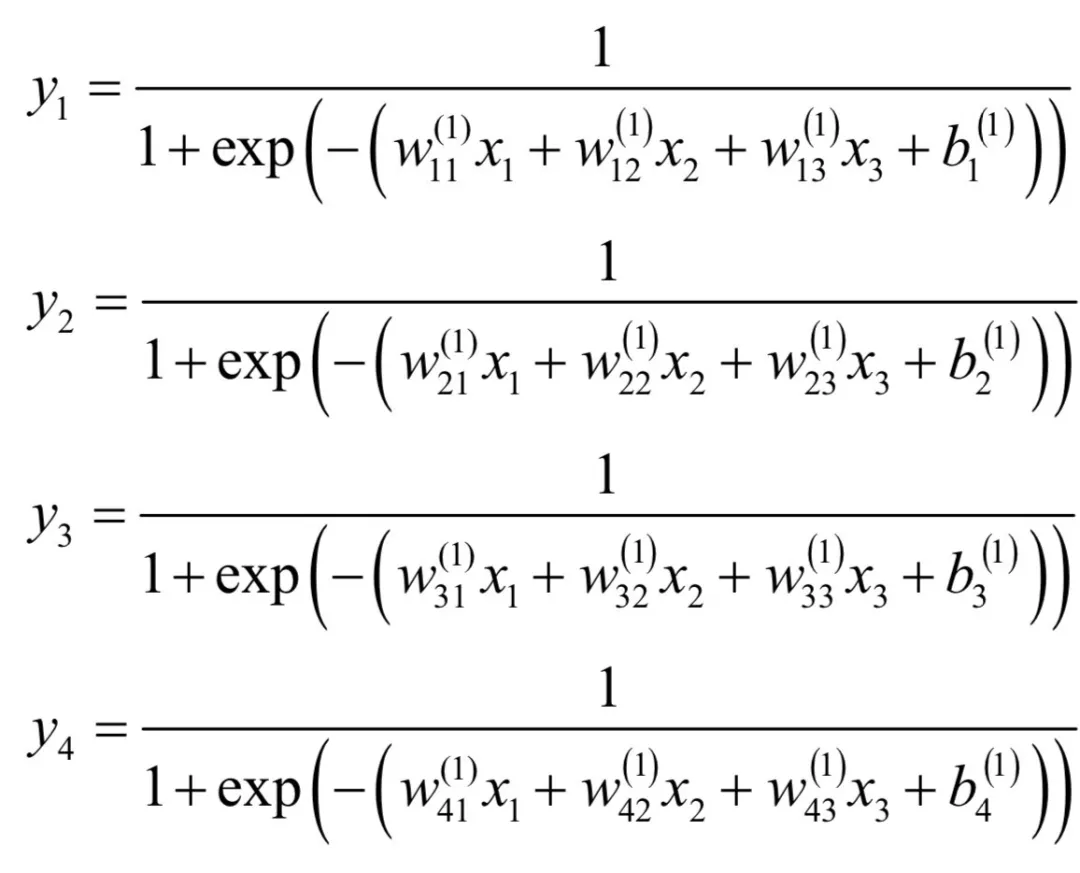
第三层神经元的输出值为:
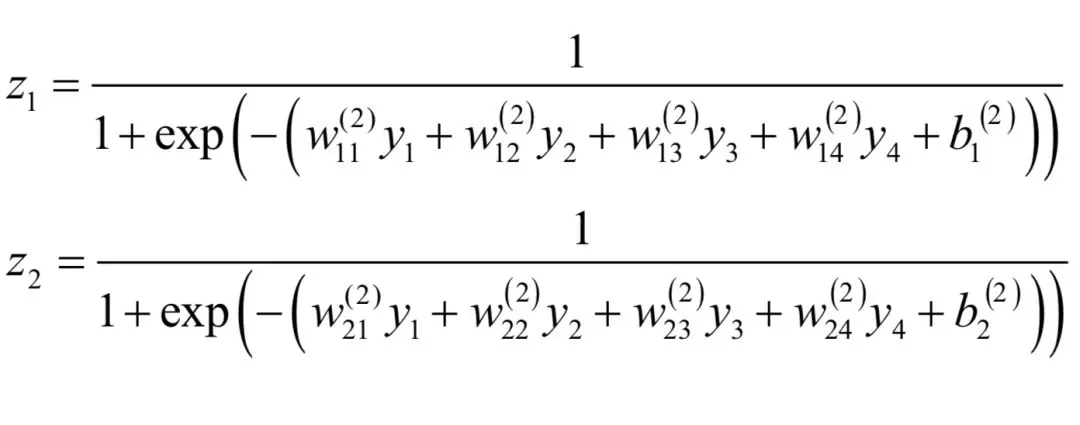
如果把yi代入上面二式中,可以将输出向量z表示成输出向量x的函数。通过调整权重矩阵和偏置项可以实现不同的函数映射,因此神经网络就是一个复合函数。
需要解决的一个核心问题是一旦神经网络的结构(即神经元层数,每层神经元数量)确定之后,怎样得到权重矩阵和偏置项。这些参数是通过训练得到的,这是本文推导的核心任务。
一个简单的例子
首先以前面的3层神经网络为例,推导损失函数对神经网络所有参数梯度的计算方法。假设训练样本集中有m个样本(xi,zi)。其中x为输入向量,z为标签向量。现在要确定神经网络的映射函数:
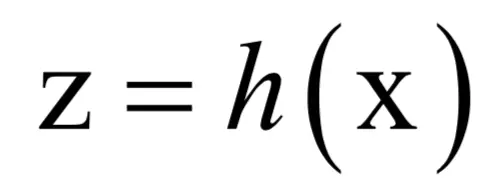
什么样的函数能很好的解释这批训练样本?答案是神经网络的预测输出要尽可能的接近样本的标签值,即在训练集上最小化预测误差。如果使用均方误差,则优化的目标为:
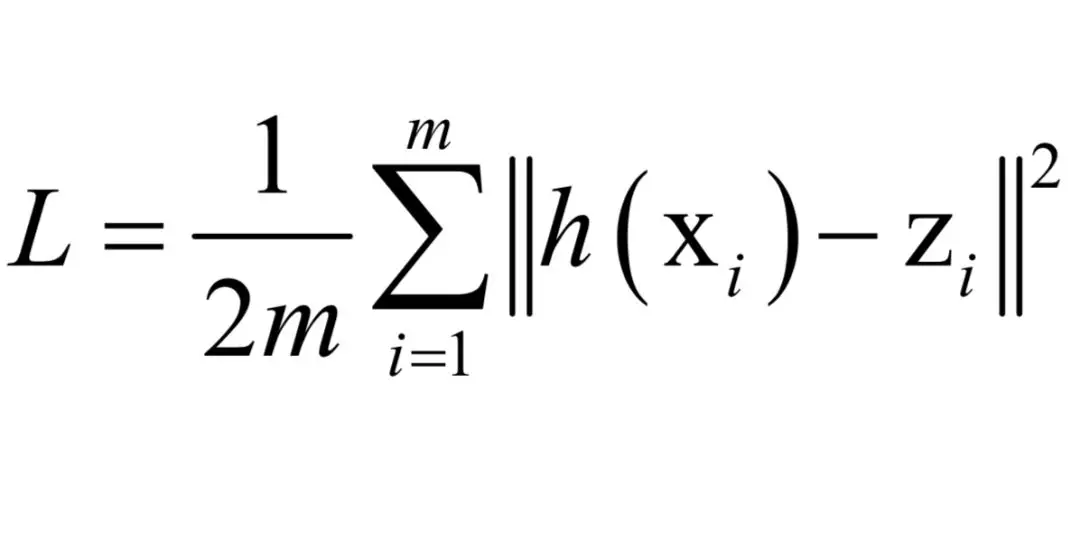
其中h(x)和zi都是向量,求和项内部是向量的2范数平方,即各个分量的平方和。上面的误差也称为欧氏距离损失函数,除此之外还可以使用其他损失函数,如交叉熵、对比损失等。
优化目标函数的自变量是各层的权重矩阵和梯度向量,一般情况下无法保证目标函数是凸函数,因此这不是一个凸优化问题,有陷入局部极小值和鞍点的风险(对于这些概念和问题, SIGAI 之前的公众号文章“ 理解梯度下降法”,“ 理解凸优化”中已经做了详细介绍),这是神经网络之前一直被诟病的一个问题。可以使用梯度下降法进行求解,使用梯度下降法需要计算出损失函数对所有权重矩阵、偏置向量的梯度值,接下来的关键是这些梯度值的计算。在这里我们先将问题简化,只考虑对单个样本的损失函数:
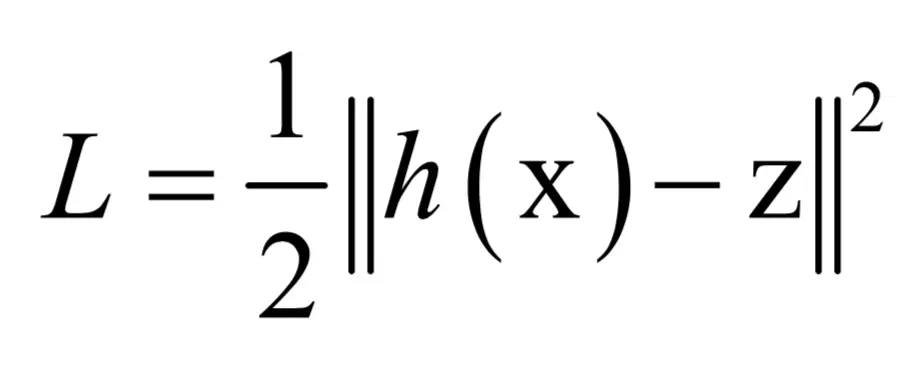
后面如果不加说明,都使用这种单样本的损失函数。如果计算出了对单个样本损失函数的梯度值,对这些梯度值计算均值即可得到整个目标函数的梯度值。
W(1)和b(1)要被代入到网络的后一层中,是复合函数的内层变量,我们先考虑外层的W(2)和b(2)。权重矩阵W(2)是一个2x4的矩阵,它的两个行分别为向量
 ,b(2)是一个2维的列向量,它的两个元素为
,b(2)是一个2维的列向量,它的两个元素为
 。网络的输入是向量x,第一层映射之后的输出是向量y。
。网络的输入是向量x,第一层映射之后的输出是向量y。
首先计算损失函数对权重矩阵每个元素的偏导数,将欧氏距离损失函数展开,有:
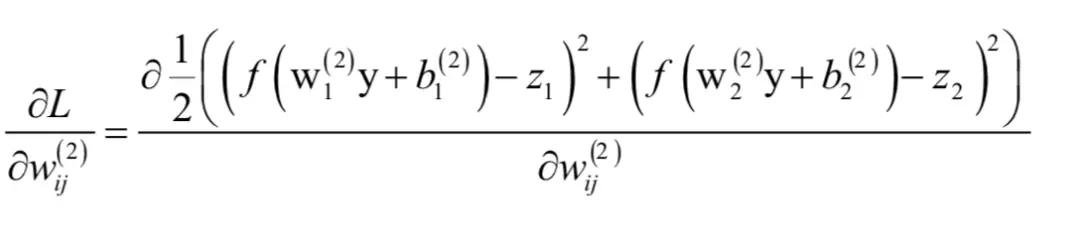
如果i = 1,即对权重矩阵第一行的元素求导,上式分子中的后半部分对wij来说是常数。根据链式法则有:
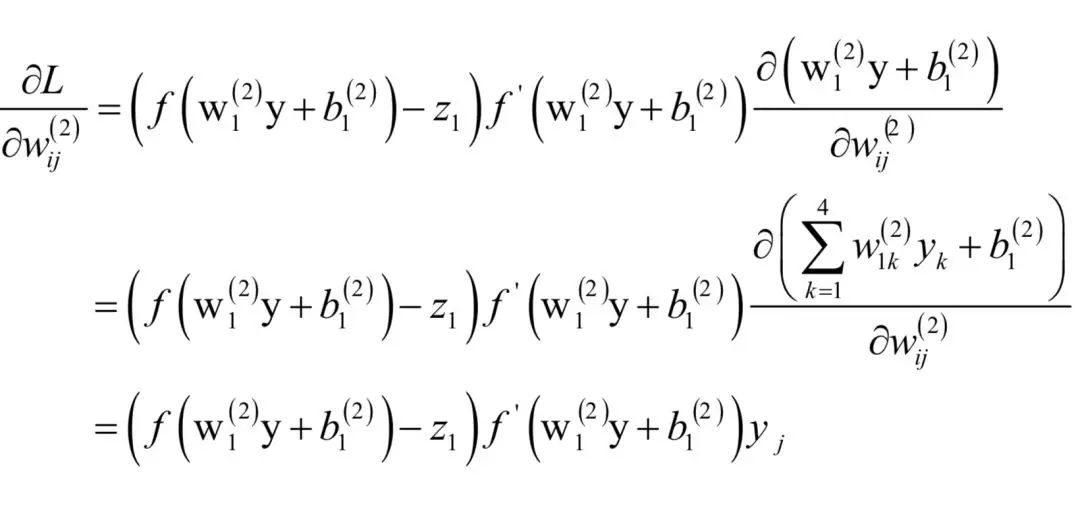
如果i = 2,即对矩阵第二行的元素求导,类似的有:
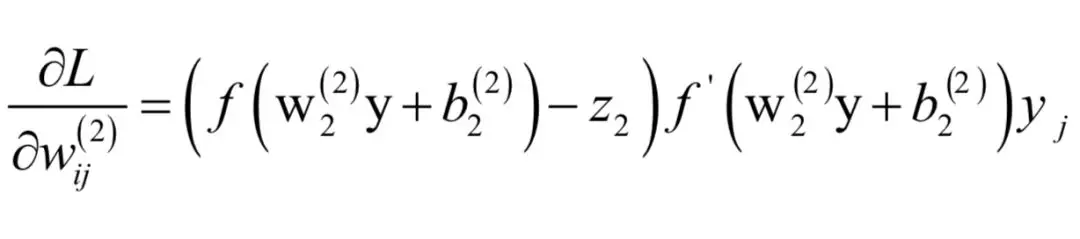
可以统一写成:
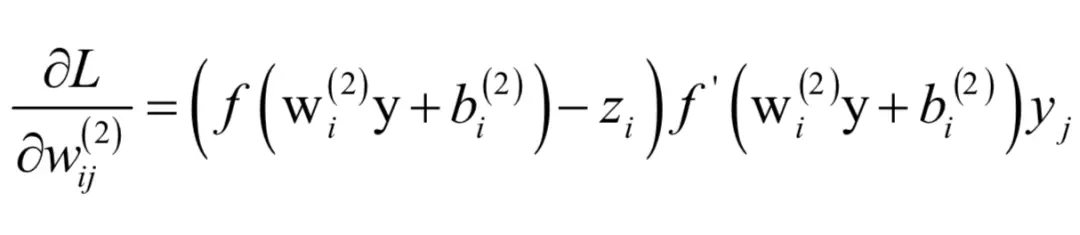
可以发现,第一个下标i决定了权重矩阵的第i行和偏置向量的第i个分量,第二个下标j决定了向量y的第j个分量。这可以看成是一个列向量与一个行向量相乘的结果,写成矩阵形式为:
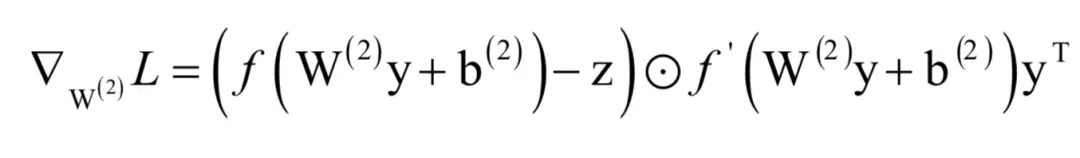
上式中乘法
 为向量对应元素相乘,第二个乘法是矩阵乘法。
为向量对应元素相乘,第二个乘法是矩阵乘法。
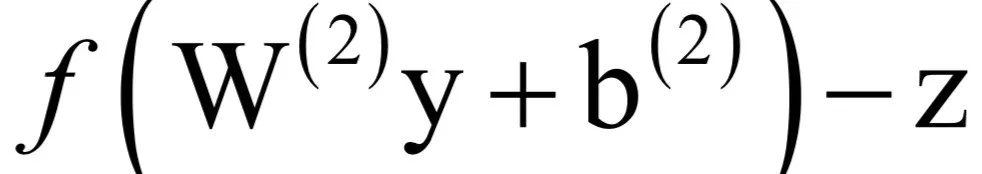 是一个2维列向量,
是一个2维列向量,
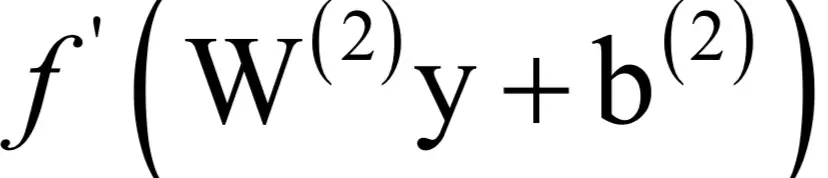 也是一个2维列向量,两个向量执行
也是一个2维列向量,两个向量执行
 运算的结果还是一个2维列向量。y是一个4元素的列向量,其转置为4维行向量,前面这个二维列向量与yT的乘积为2x4的矩阵,这正好与矩阵W(2)的尺寸相等。在上面的公式中,权重的偏导数在求和项中由3部分组成,分别是网络输出值与真实标签值的误差
运算的结果还是一个2维列向量。y是一个4元素的列向量,其转置为4维行向量,前面这个二维列向量与yT的乘积为2x4的矩阵,这正好与矩阵W(2)的尺寸相等。在上面的公式中,权重的偏导数在求和项中由3部分组成,分别是网络输出值与真实标签值的误差
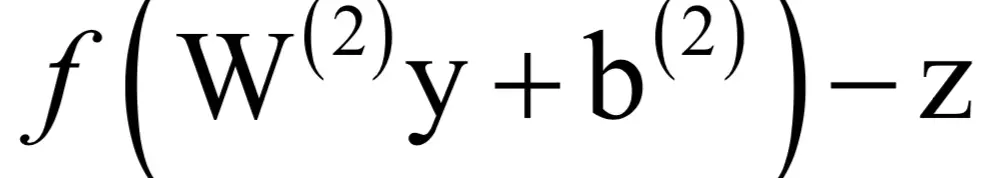 ,激活函数的导数
,激活函数的导数
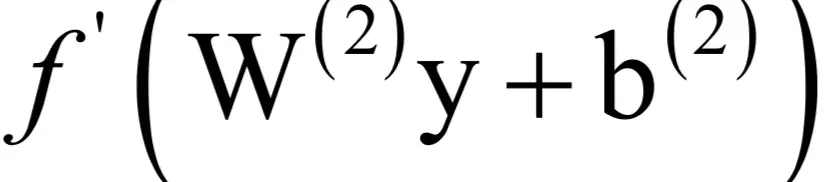 ,本层的输入值y。神经网络的输出值、激活函数的导数值、本层的输入值都可以在正向传播时得到,因此可以高效的计算出来。对所有训练样本的偏导数计算均值,可以得到总的偏导数。
,本层的输入值y。神经网络的输出值、激活函数的导数值、本层的输入值都可以在正向传播时得到,因此可以高效的计算出来。对所有训练样本的偏导数计算均值,可以得到总的偏导数。
对偏置项的偏导数为:
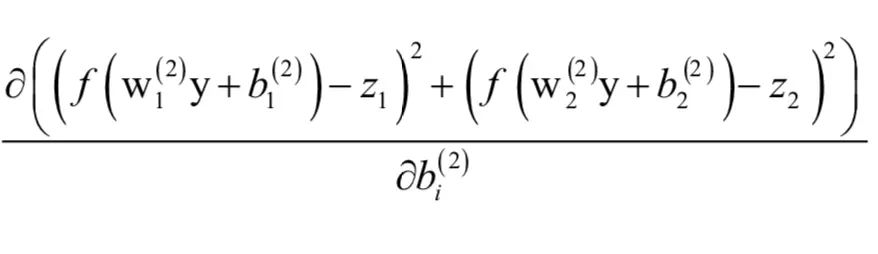
如果i = 1,上式分子中的后半部分对b1来说是常数,有:
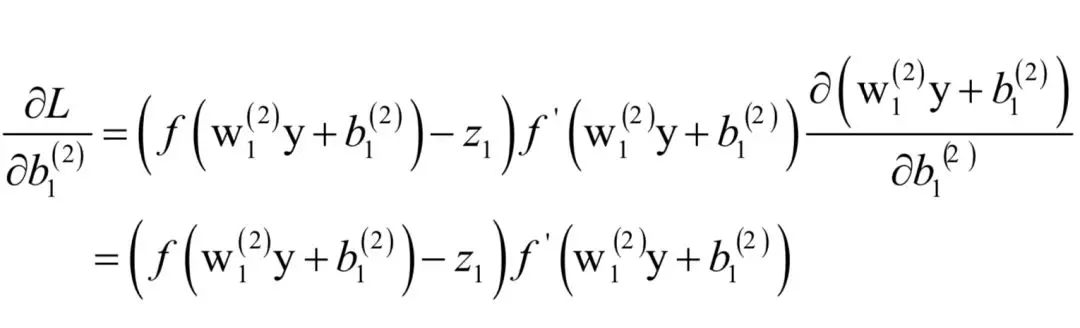
如果i = 2,类似的有:
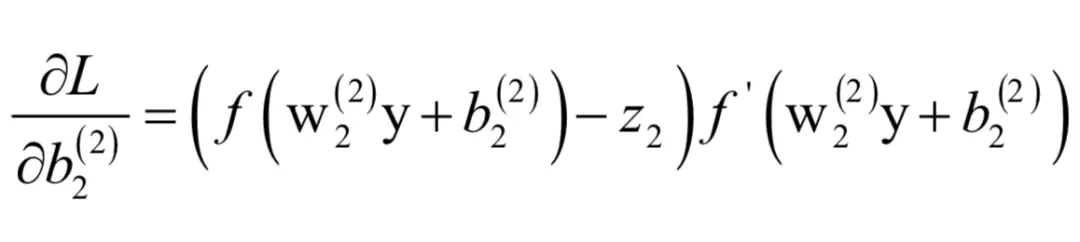
这可以统一写成:
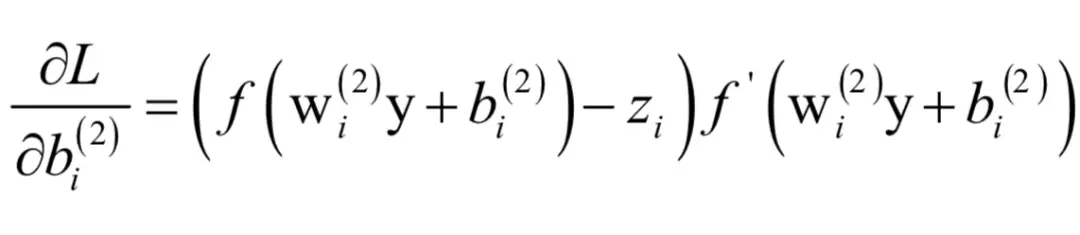
写成矩阵形式为:
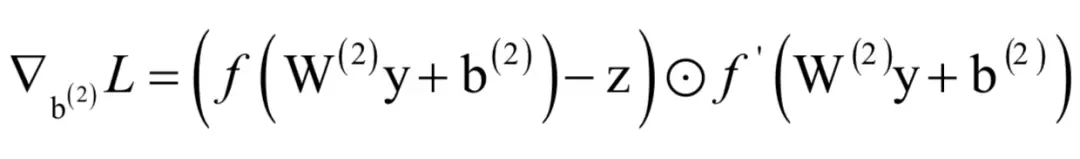
偏置项的导数由两部分组成,分别是神经网络预测值与真实值之间的误差,激活函数的导数值,与权重矩阵的偏导数相比唯一的区别是少了yT。接下来计算对W(1)和b(1)的偏导数,由于是复合函数的内层,情况更为复杂。W(1)是一个4x3的矩阵,它的4个行向量为
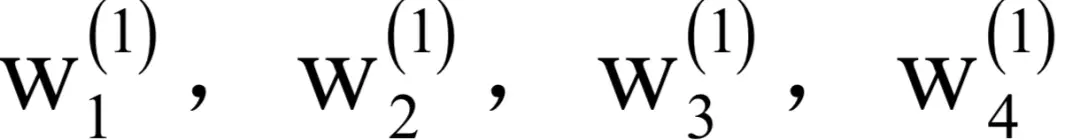 。偏置项b(1)是4维向量,4个分量分别是
。偏置项b(1)是4维向量,4个分量分别是
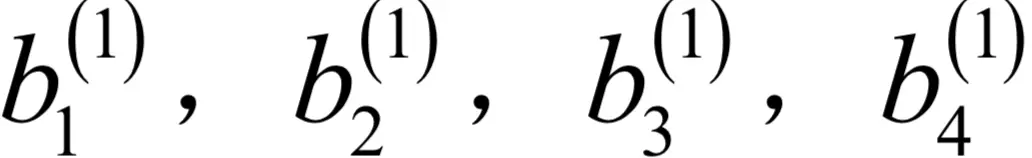 。首先计算损失函数对W(1)的元素的偏导数:
。首先计算损失函数对W(1)的元素的偏导数:
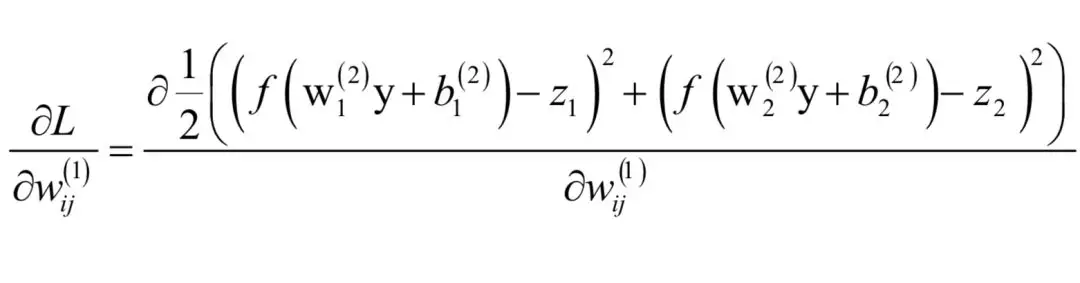
而:
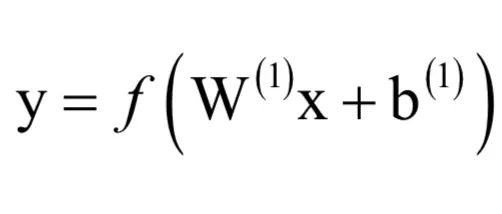
上式分子中的两部分都有y,因此都与W(1)有关。为了表述简洁,我们令:
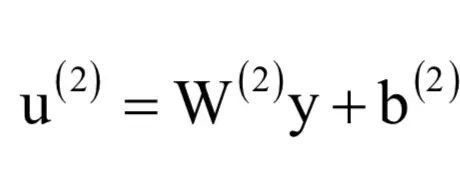
根据链式法则有:
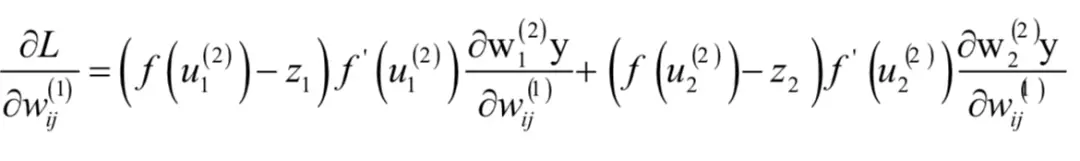

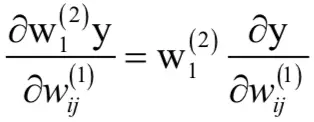
这里的
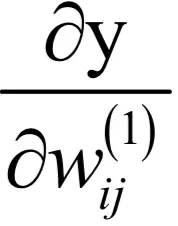 是一个向量,表示y的每个分量分别对
是一个向量,表示y的每个分量分别对
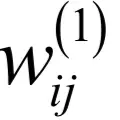 求导。当i = 1时有:
求导。当i = 1时有:
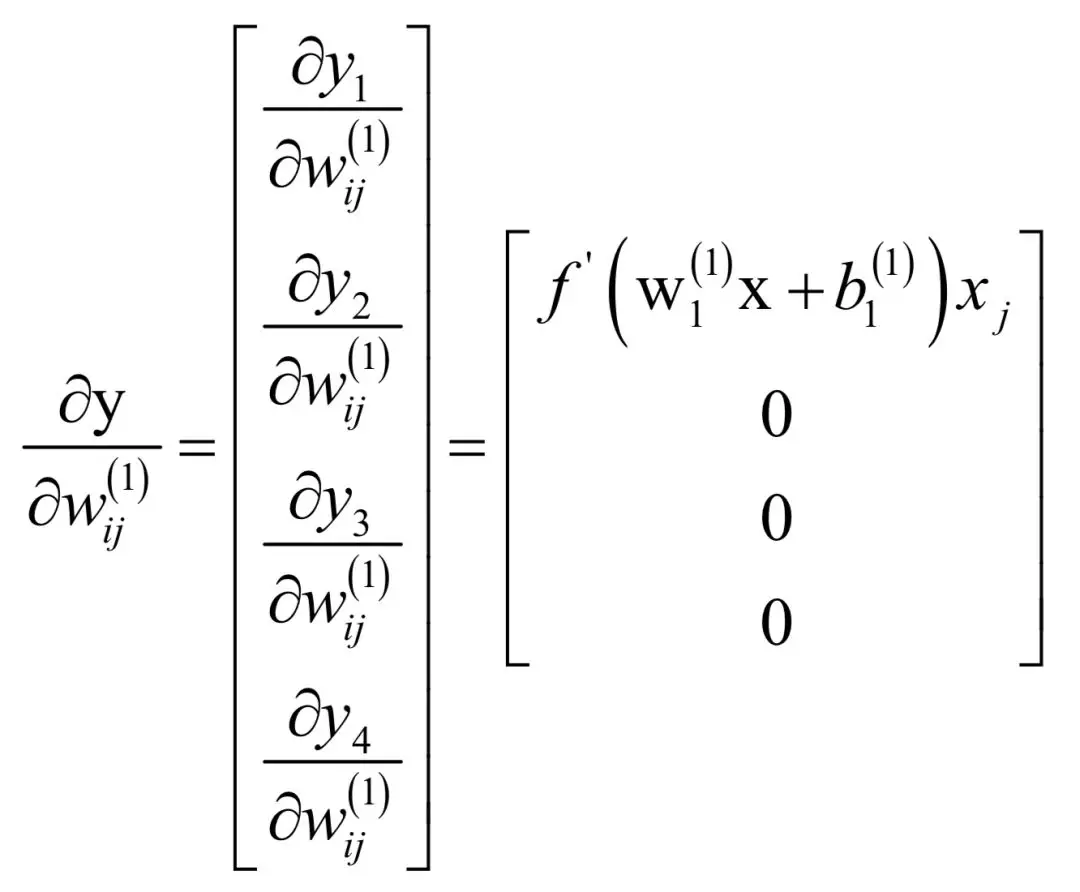
后面3个分量相对于求导变量
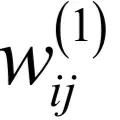 都是常数。类似的当i = 2时有:
都是常数。类似的当i = 2时有:
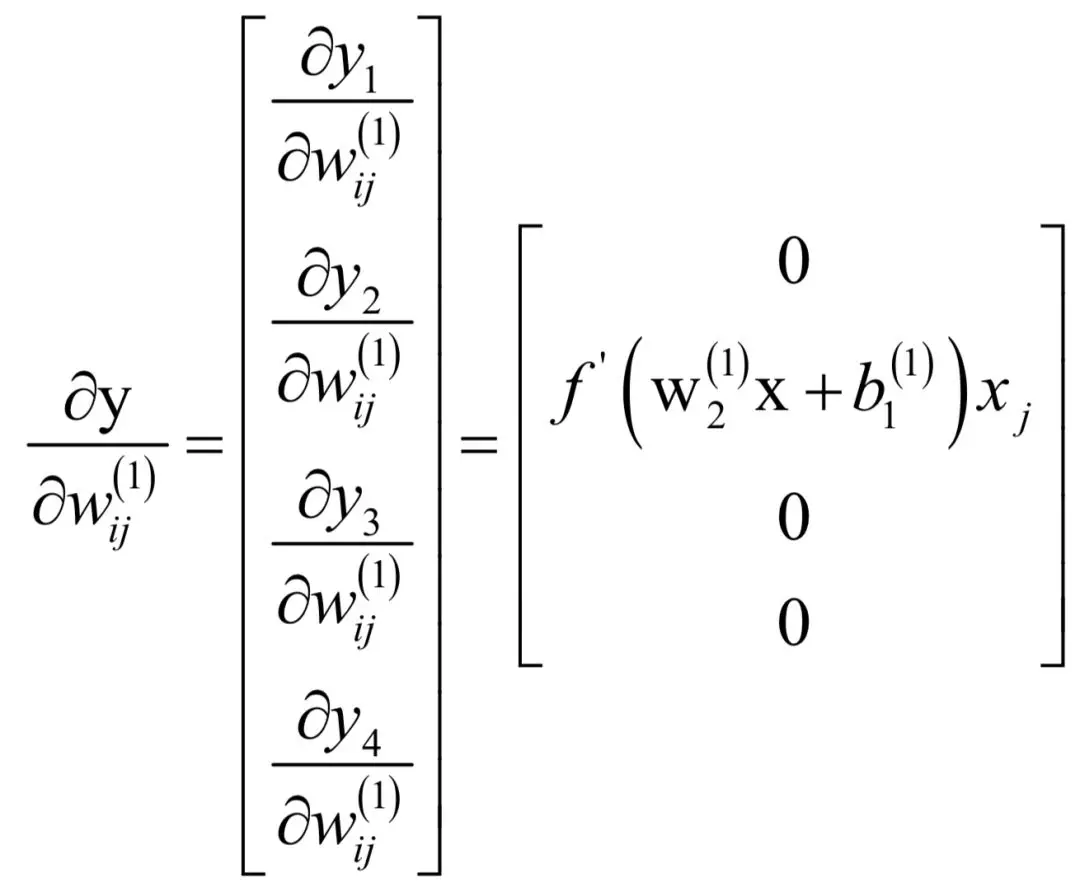
i = 3和i = 4时的结果以此类推。综合起来有:
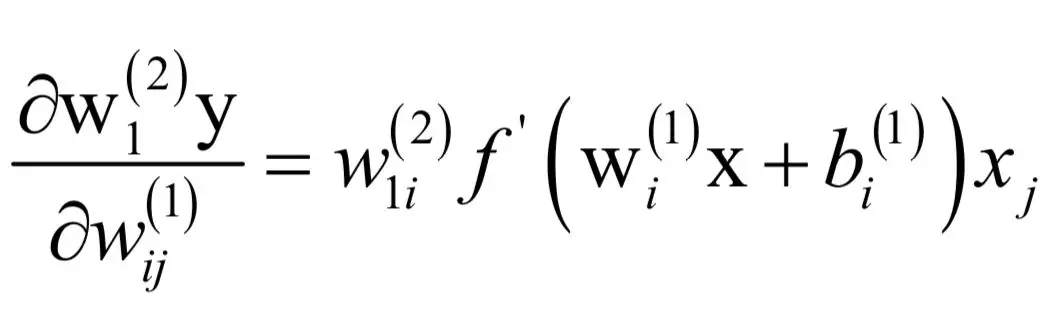
同理有:
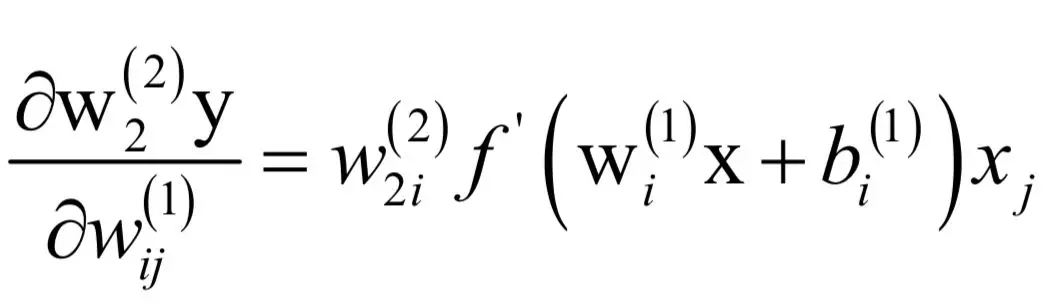
如果令:
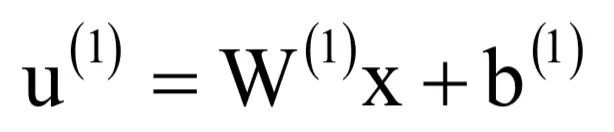
合并得到:
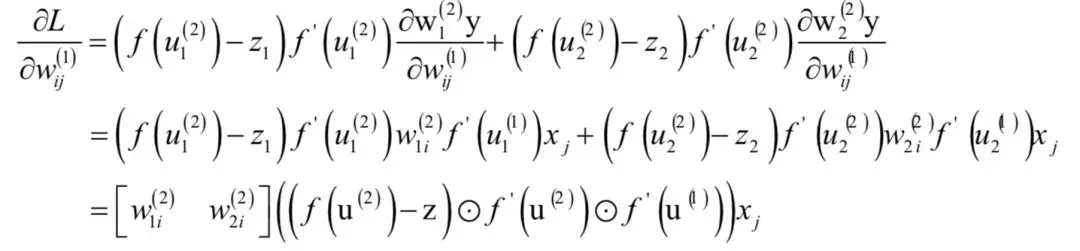
写成矩阵形式为:
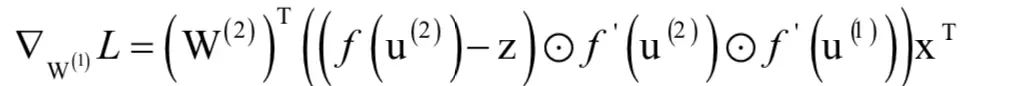
最后计算偏置项的偏导数:
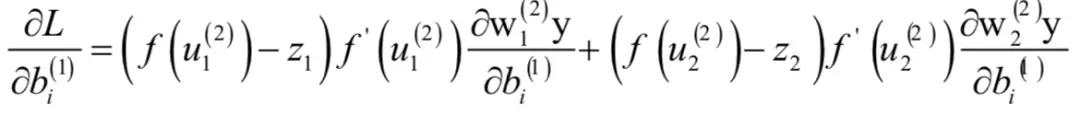
类似的我们得到:
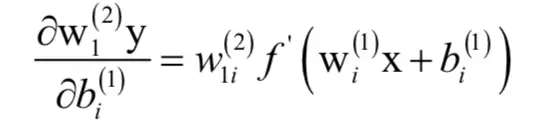
合并后得到:
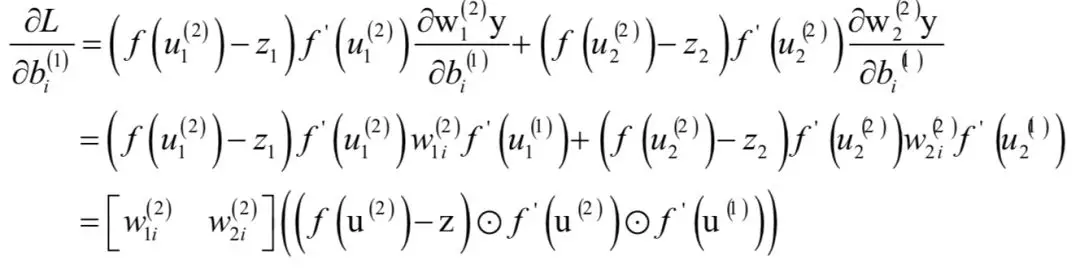
写成矩阵形式为:
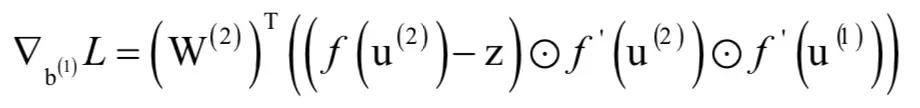
至此,我得到了这个简单网络对所有参数的偏导数,接下来我们将这种做法推广到更一般的情况。从上面的结果可以看出一个规律,输出层的权重矩阵和偏置向量梯度计算公式中共用了
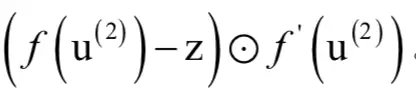 。对于隐含层也有类似的结果。
。对于隐含层也有类似的结果。
完整的算法
现在考虑一般的情况。假设有m个训练样本(xi,yi),其中xi为输入向量,yi为标签向量。训练的目标是最小化样本标签值与神经网络预测值之间的误差,如果使用均方误差,则优化的目标为:
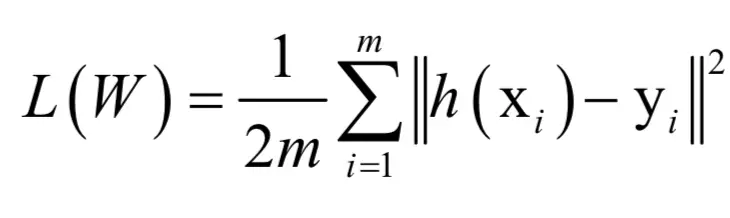
其中W为神经网络所有参数的集合,包括各层的权重和偏置。这个最优化问题是一个不带约束条件的问题,可以用梯度下降法求解。
上面的误差函数定义在整个训练样本集上,梯度下降法每一次迭代利用了所有训练样本,称为批量梯度下降法。如果样本数量很大,每次迭代都用所有样本进计算成本太高。为了解决这个问题,可以采用单样本梯度下降法,我们将上面的损失函数写成对单个样本的损失函数之和:
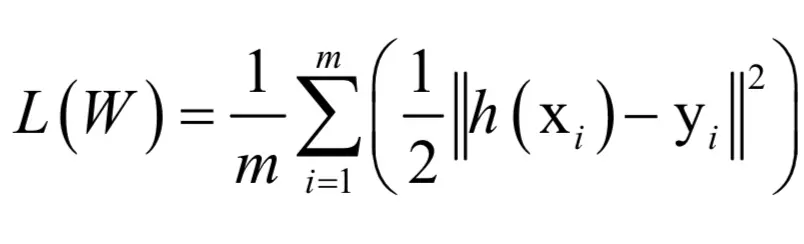
定义对单个样本(xi,yi)的损失函数为:
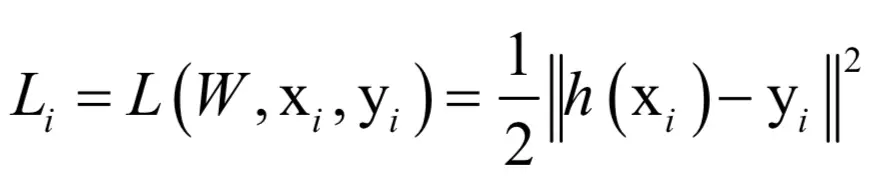
如果采用单个样本进行迭代,梯度下降法第t + 1次迭代时参数的更新公式为:
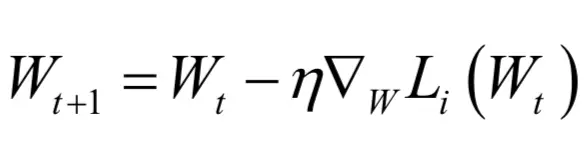
如果要用所有样本进行迭代,根据单个样本的损失函数梯度计算总损失梯度即可,即所有样本梯度的均值。
用梯度下降法求解需要初始化优化变量的值。一般初始化为一个随机数,如用正态分布
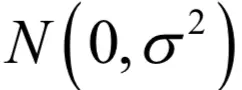 产生这些随机数,其中
产生这些随机数,其中
 是一个很小的正数。
是一个很小的正数。
到目前为止还有一个关键问题没有解决:目标函数是一个多层的复合函数,因为神经网络中每一层都有权重矩阵和偏置向量,且每一层的输出将会作为下一层的输入。因此,直接计算损失函数对所有权重和偏置的梯度很复杂,需要使用复合函数的求导公式进行递推计算。
几个重要的结论
在进行推导之前,我们首先来看下面几种复合函数的求导。又如下线性映射函数:
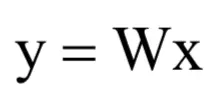
其中x是n维向量,W是mxn的矩阵,y是m维向量。
问题1:假设有函数f(y),如果把x看成常数,y看成W的函数,如何根据函数对y的梯度值
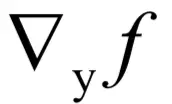 计算函数对W的梯度值
计算函数对W的梯度值
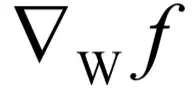 ?根据链式法则,由于wij只和yj有关,和其他的yk,
?根据链式法则,由于wij只和yj有关,和其他的yk,
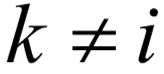 无关,因此有:
无关,因此有:
对于W的所有元素有:
写成矩阵形式为:
问题2:如果将W看成常数,y将看成x的函数,如何根据
 计算
计算
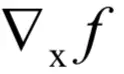 ?由于任意的xi和所有的yi都有关系,根据链式法则有:
?由于任意的xi和所有的yi都有关系,根据链式法则有:
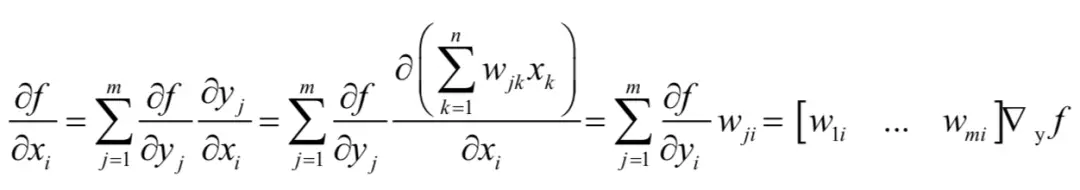
写成矩阵形式为:
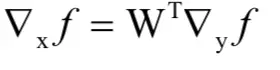
这是一个对称的结果,在计算函数映射时用矩阵W乘以向量x得到y,在求梯度时用矩阵W的转置乘以y的梯度得到x的梯度。
问题3:如果有向量到向量的映射:
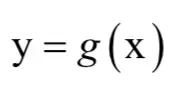
写成分量形式为:
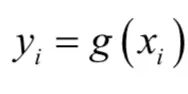
在这里每个yi只和对应的xi有关,和其他所有
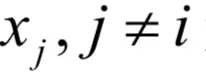 无关,且每个分量采用了相同的映射函数g。对于函数f(y),如何根据
无关,且每个分量采用了相同的映射函数g。对于函数f(y),如何根据
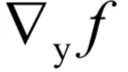 计算
计算
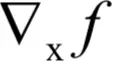 ?根据链式法则,由于每个yi只和对应的xi有关,有:
?根据链式法则,由于每个yi只和对应的xi有关,有:
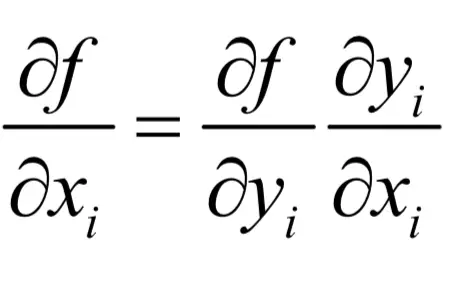
写成矩阵形式为:
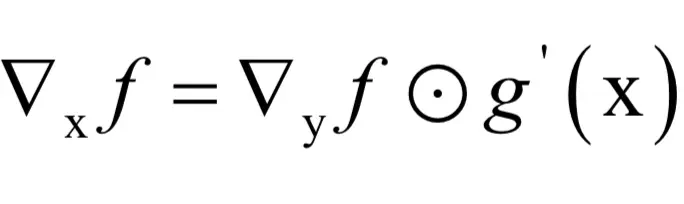
即两个向量对应元素相乘,这种乘法在上一节已经介绍。
问题4:接下来我们考虑更复杂的情况,如果有下面的复合函数:
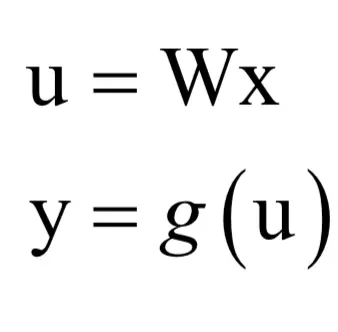
其中g是向量对应元素一对一映射,即:
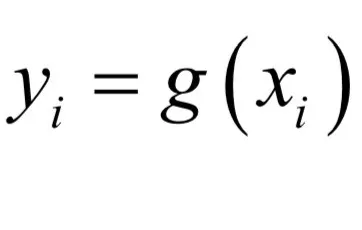
如果有函数f(y),如何根据
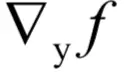 计算
计算
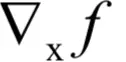 ?在这里有两层复合,首先是从x到u,然后是从u到y。根据问题2和问题3的结论,有:
?在这里有两层复合,首先是从x到u,然后是从u到y。根据问题2和问题3的结论,有:
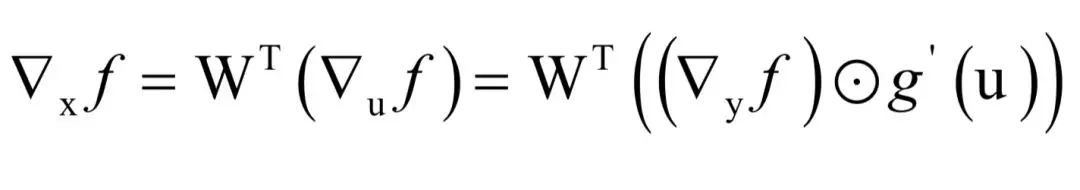
问题5:x是n维向量,y是m维向量,有映射y=g(x),即:
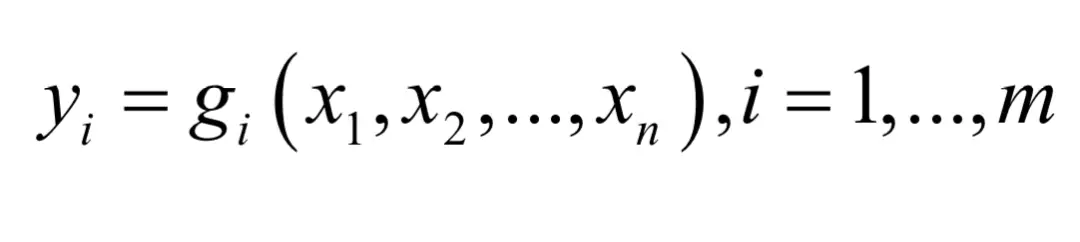
这里的映射方式和上面介绍的不同。对于向量y的每个分量yi,映射函数gi不同,而且yi和向量x的每个分量xj有关。对于函数f(y),如何根据
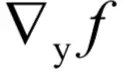 计算
计算
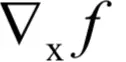 ?根据链式法则,由于任何的yi和任何的xj都有关系,因此有:
?根据链式法则,由于任何的yi和任何的xj都有关系,因此有:
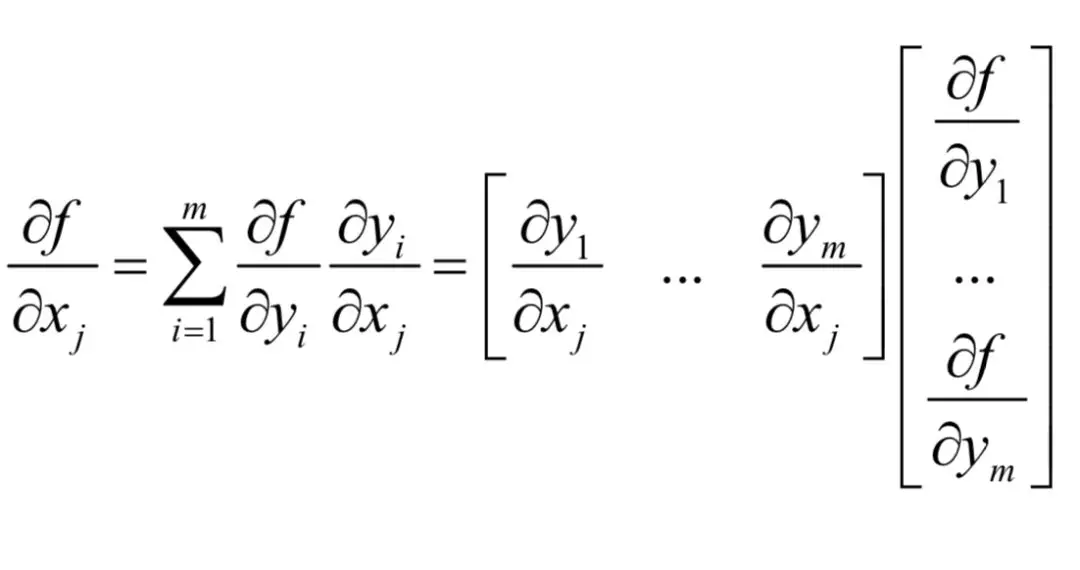
对于所有元素有:
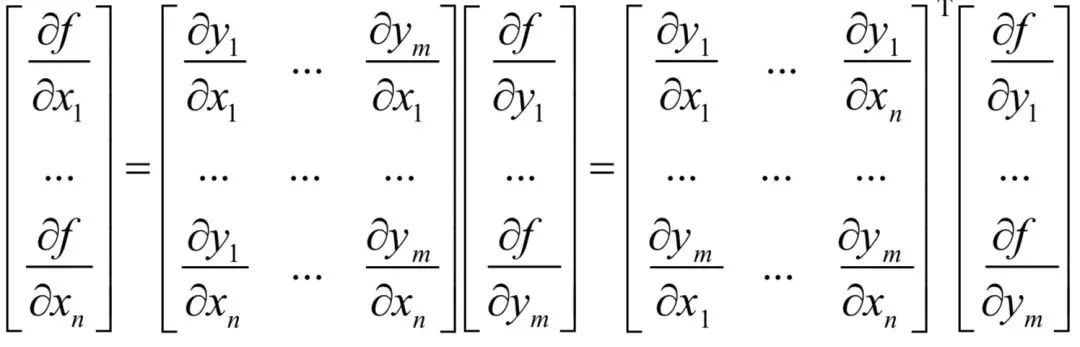
写成矩阵形式有:
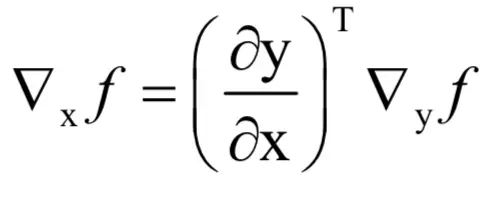
其中
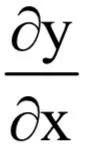 为雅可比矩阵。对于如下向量到向量的映射函数:
为雅可比矩阵。对于如下向量到向量的映射函数:
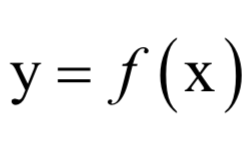
其中向量
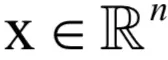 ,向量
,向量
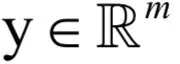 这个映射写成分量形式为:
这个映射写成分量形式为:
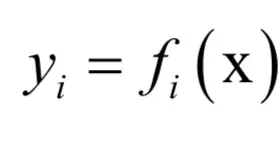
即输出向量的每个分量是输入向量的函数。雅克比矩阵定义为输出向量的每个分量对输入向量的每个分量的偏导数构成的矩阵:
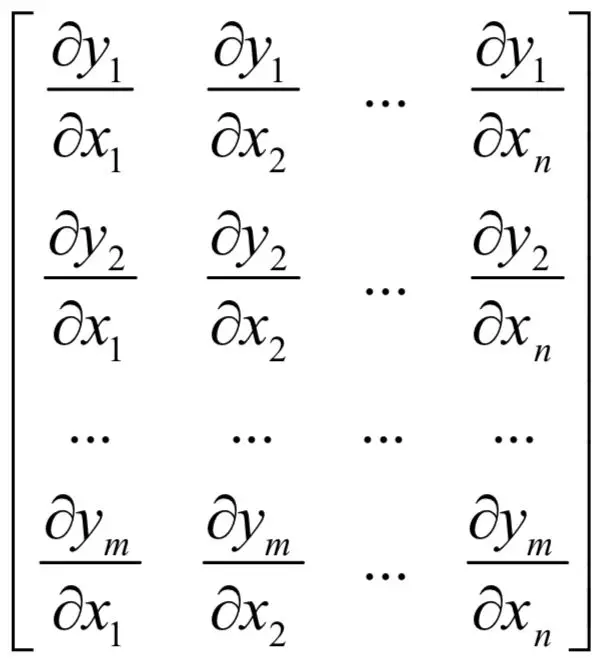
这是一个m行n列的矩阵,每一行为一个多元函数的梯度。对于如下向量映射函数:
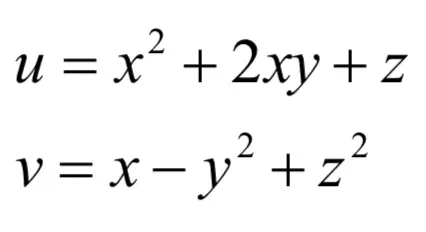
它的雅克比矩阵为:
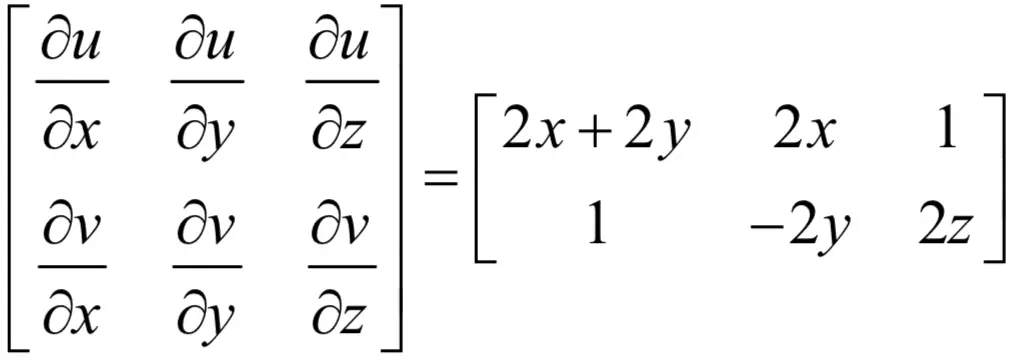
前面介绍的几个问题都是这个映射的特例。
完整的算法
根据上面的结论可以方便的推导出神经网络的求导公式。假设神经网络有nl层,第l层神经元个数为Sl。第1层从第l-1层接收的输入向量为x(l-1),本层的权重矩阵为W(l),偏置向量为b(l),输出向量为x(l)。该层的输出可以写成如下矩阵形式:
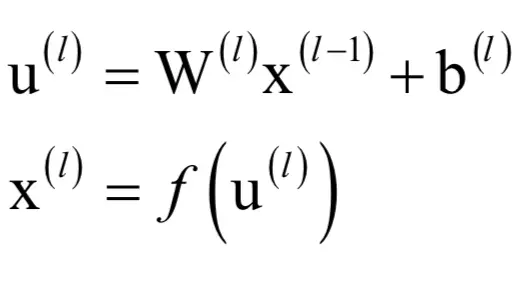
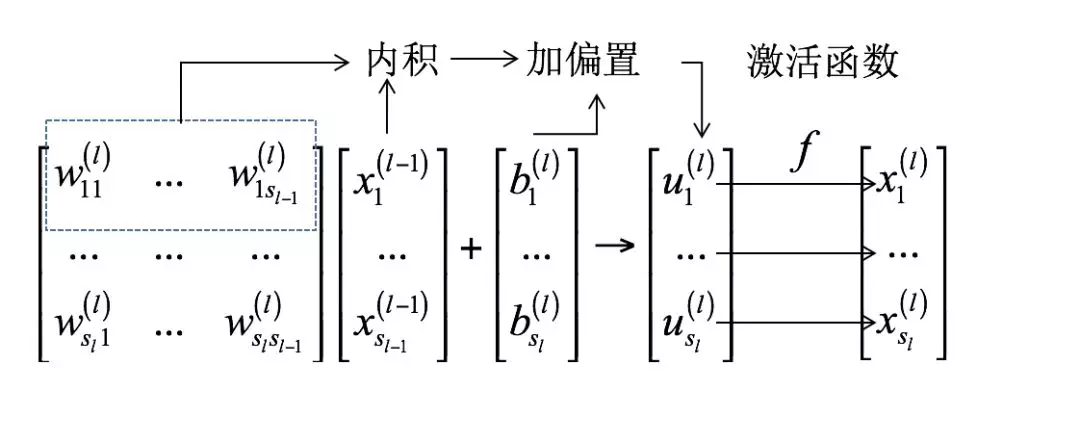
其中W(l)是slxsl-1的矩阵,u(l)和b(l)是sl维的向量。神经网络一个层实现的变换如下图所示:
如果将神经网络按照各个层展开,最后得到一个深层的复合函数,将其代入欧氏距离损失函数,依然是一个关于各个层的权重矩阵和偏置向量的复合函数:
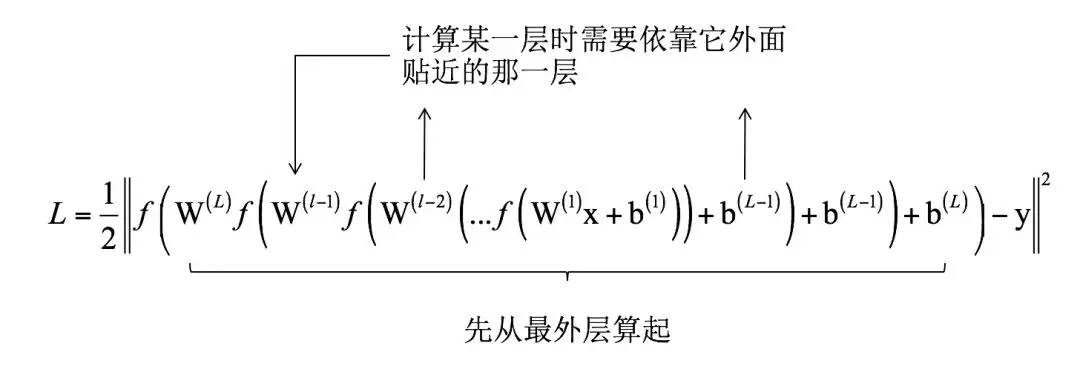
要计算某一层的权重矩阵和偏置向量的梯度,只能依赖于它紧贴着的外面那一层变量的梯度值,通过一次复合函数求导得到。
根据定义,w(l)和b(l)是目标函数的自变量,u(l)和x(l)可以看成是它们的函数。根据前面的结论,损失函数对权重矩阵的梯度为:
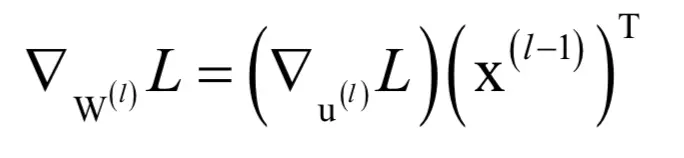
对偏置向量的梯度为:
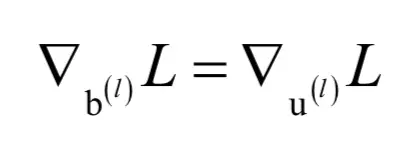
现在的问题是,梯度
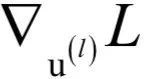 怎么计算?我们分两种情况讨论,如果第l层是输出层,在这里只考虑对单个样本的损失函数,根据上一节推导的结论,这个梯度为:
怎么计算?我们分两种情况讨论,如果第l层是输出层,在这里只考虑对单个样本的损失函数,根据上一节推导的结论,这个梯度为:
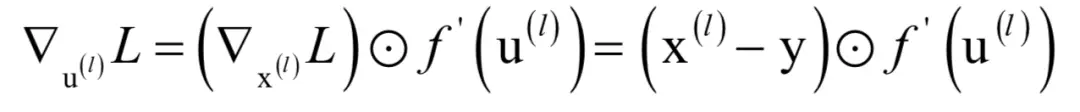
这就是输出层的神经元输出值与期望值之间的误差。这样我们得到输出层权重的梯度为:
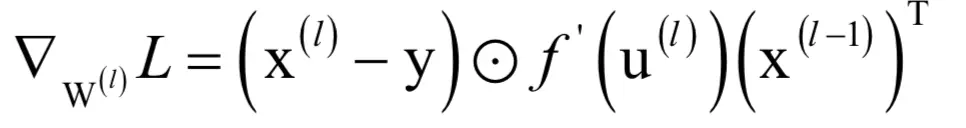
等号右边第一个乘法是向量对应元素乘;第二个乘法是矩阵乘,在这里是列向量与行向量的乘积,结果是一个矩阵,尺寸刚好和权重矩阵相同。损失函数对偏置项的梯度为:
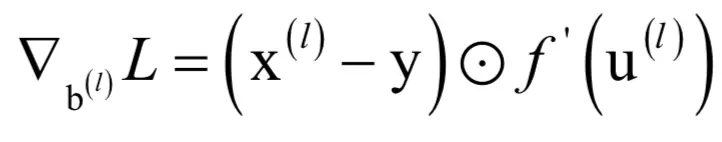
下面考虑第二种情况。如果第l层是隐含层,则有:
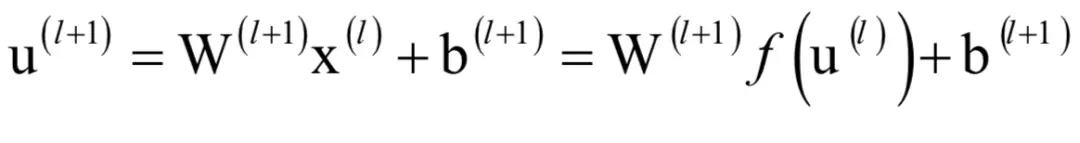
假设梯度
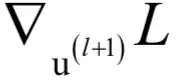 已经求出,根据前面的结论,有:
已经求出,根据前面的结论,有:
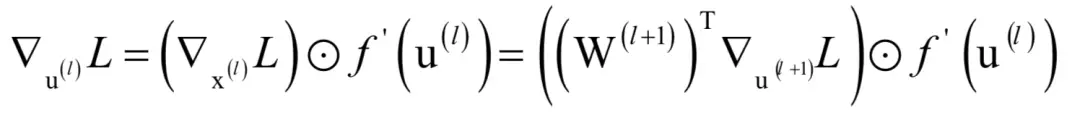
这是一个递推的关系,通过
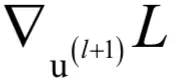 可以计算出
可以计算出
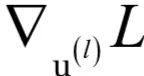 ,递推的终点是输出层,而输出层的梯度值我们之前已经算出。由于根据
,递推的终点是输出层,而输出层的梯度值我们之前已经算出。由于根据
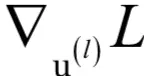 可以计算出
可以计算出
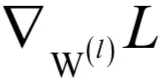 和
和
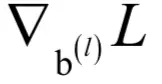 ,因此可以计算出任意层权重与偏置的梯度值。
,因此可以计算出任意层权重与偏置的梯度值。
为此我们定义误差项为损失函数对临时变量u的梯度:
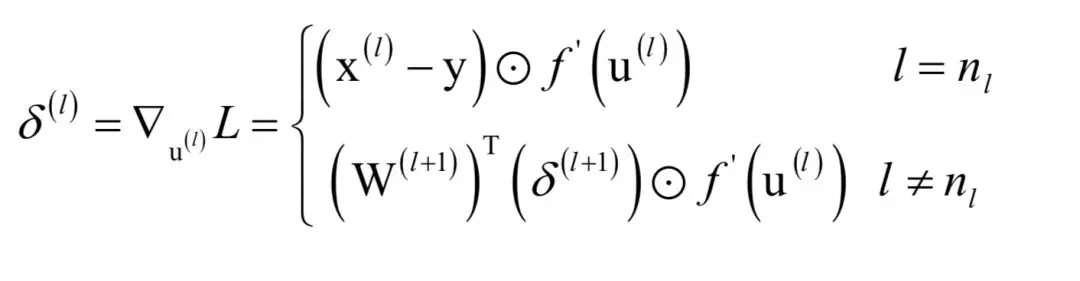
向量
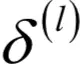 的尺寸和本层神经元的个数相同。这是一个递推的定义,
的尺寸和本层神经元的个数相同。这是一个递推的定义,
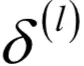 依赖于
依赖于
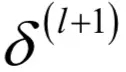 ,递推的终点是输出层,它的误差项可以直接求出。
,递推的终点是输出层,它的误差项可以直接求出。
根据误差项可以方便的计算出对权重和偏置的偏导数。首先计算输出层的误差项,根据他得到权重和偏置项的梯度,这是起点;根据上面的递推公式,逐层向前,利用后一层的误差项计算出本层的误差项,从而得到本层权重和偏置项的梯度。
单个样本的反向传播算法在每次迭代时的流程为:
1.正向传播,利用当前权重和偏置值,计算每一层对输入样本的输出值
2.反向传播,对输出层的每一个节点计算其误差:
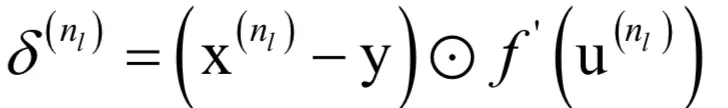
3.对于
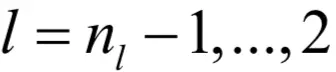 的各层,计算第l层每个节点的误差:
的各层,计算第l层每个节点的误差:
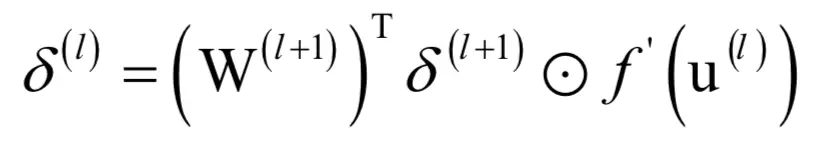
4.根据误差计算损失函数对权重的梯度值:
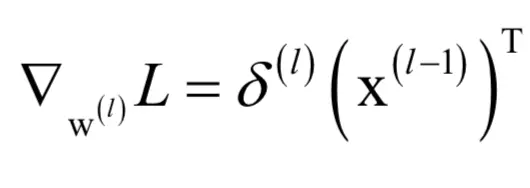
对偏置的梯度为:

5.用梯度下降法更新权重和偏置:
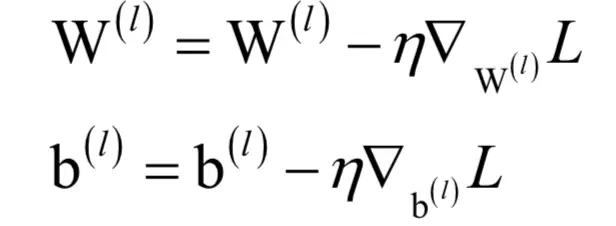
实现时需要在正向传播时记住每一层的输入向量x(l-1),本层的激活函数导数值
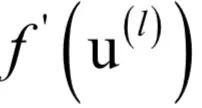 。
。
神经网络的训练算法可以总结为:
复合函数求导+梯度下降法
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8F%8D%E5%90%91%E4%BC%A0%E6%92%AD%E7%AE%97%E6%B3%95%E6%8E%A8%E5%AF%BC%E5%85%A8%E8%BF%9E%E6%8E%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


