同城技术在房产推荐中的应用

分享嘉宾:周彤 58同城 资深算法工程师
编辑整理:吴雪松
内容来源:58 推荐系统技术沙龙
出品平台:DataFunTalk
导读: 在深度学习的应用过程中,Embedding 这样一种将离散变量转变为连续向量的方式为神经网络在各方面的应用带来了极大的扩展,有"万物皆可 Embedding"的说法。本文将以 58 同城为例,分享 Embedding 相关技术的实践,将首先介绍 58 同城房产的相关业务和推荐场景,然后讲解 Embedding 的相关技术实践方案,最后会深入介绍 Embedding 技术在房产业务推荐上的落地。
主要内容包括:
- 房产业务及推荐场景
- Embedding 的相关技术
- Embedding 在推荐中的应用
01 房产业务及推荐场景
1. 房产业务介绍
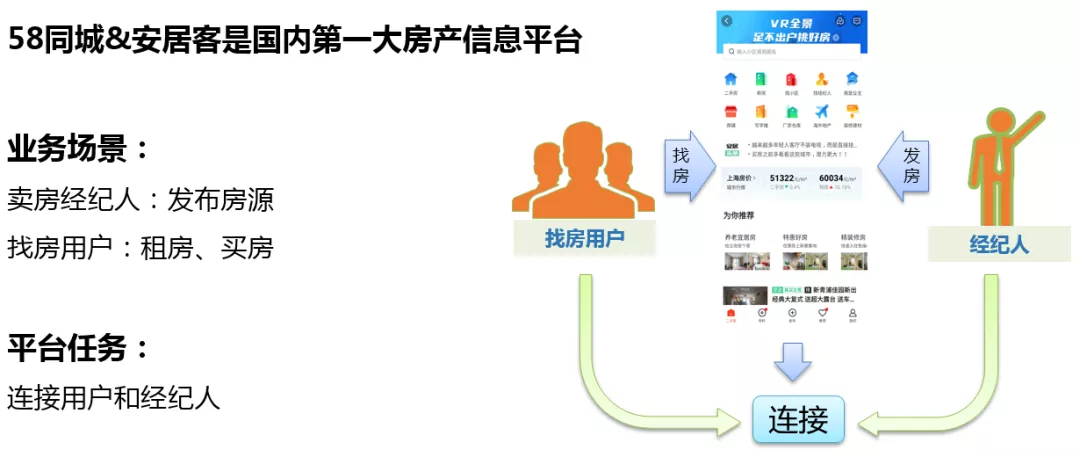
58 同城&安居客是国内第一大房产信息平台,作为第一大信息平台,主要有两种业务场景,服务于两类对象。
- 房产经纪人,当经纪人有卖房需求的时候,可以将房源发布到平台上,平台导入流量进行支持,当然前提是这个房源必须是真实的,如果是虚假房源,会被下架处理。
- 找房用户,用户可以在平台上浏览到丰富的房源信息。
平台的任务就是连接起用户和经纪人,帮助用户找到满意的房子,帮助经纪人卖掉手上的房子。
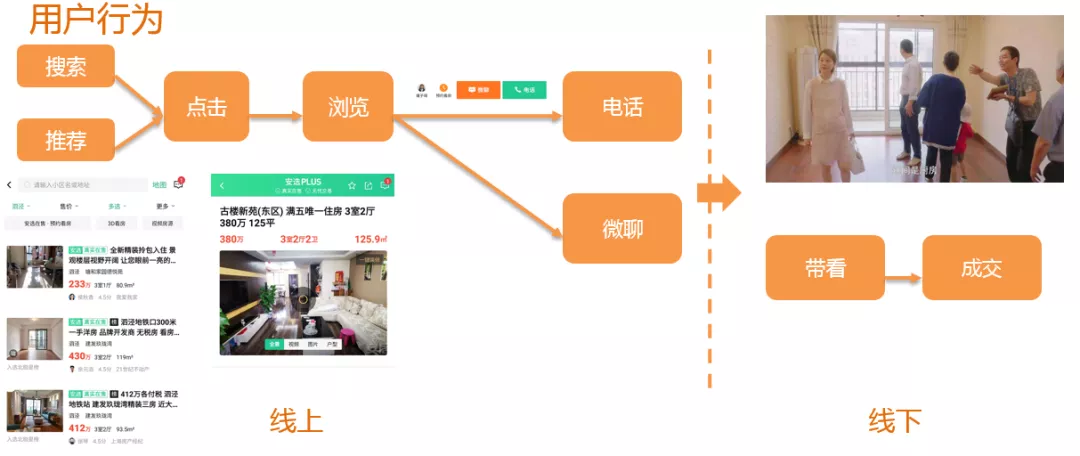
我们推荐的用户主要是找房用户,其行为包括:
- 当用户有找房的需求时,可以在列表页进行搜索和房源的筛选,也可以在推荐位浏览到推荐的房源。当看到中意的房源后,可以点击帖子进入房源的详情页浏览,如果用户感觉详情页的房源信息合适,就可以通过电话或者微聊的形式联系发布房源的经纪人,这个流程就是用户的线上行为。
- 如果用户和经纪人进行沟通后,房产经纪人可以带着用户看房,如果用户感觉满意的话,最终完成交易,这个是属于用户的线下行为。
目前可以获得的数据是用户的线上行为数据,后续用于推荐的数据也主要是用户的点击数据,电话,微聊等数据。
2. 推荐场景介绍
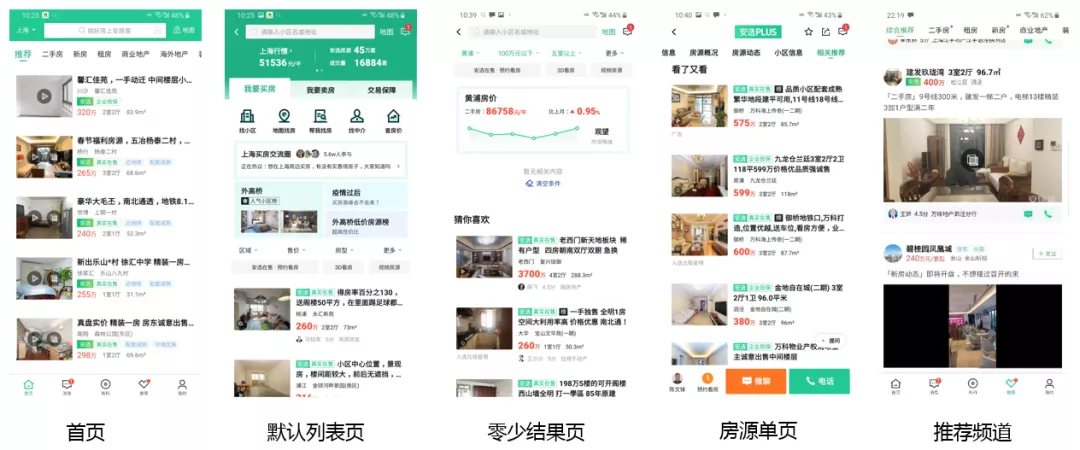
58 房产的相关推荐位还是比较丰富的,不同位置推荐的逻辑也有很大差异,在这里以安居客为例,列举安居客的 5 个主要推荐位:
- 首页,对于进入到首页的用户,首先判断用户类型,或者说用户来安居客的目的,比如说用户是来看二手房还是找新房的,针对不同类型的用户,我们会推荐合适的房源。
- 默认列表页,用户已经选定了自己的房产类型,这个时候基于用户的历史行为,给用户推荐一些房源。对于新用户,会基于当前用户的经纬度推荐一些附近的房源,或者热门的房源。进行新用户的冷启动。
- 零少结果页,在这里是可以拿到用户的筛选条件的,可以针对于用户的筛选条件进行相关房源的推荐。
- 房源单页,用户对单页的信息表示了一定的兴趣,在这里主要是推当前房源的相似房源。
- 推荐频道,使用 Feed 流技术,推拉结合,把用户感兴趣的最新的信息,推荐给用户。
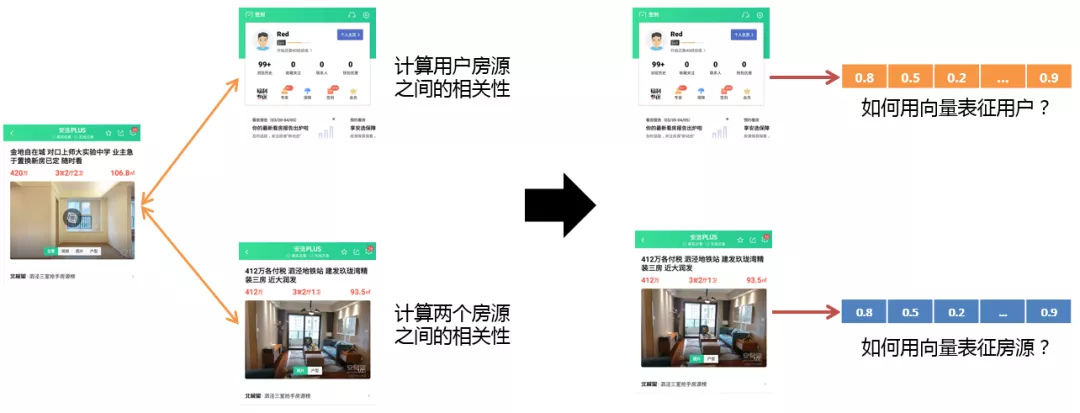
前面介绍了五种不同类型的推荐位,其实在这些场景中都离不开两类相似性的计算。一类是用户和房源之间的相关性,一类是两个房源之间的相关性。
相关性的计算:
- 将房源、用户或者说这种实体使用向量表征出来
- 通过计算向量之间的差异来衡量用户和房源、房源与房源之间是否相似
对于房源和用户的向量表征其实可以分为两类,一类是基于标签的向量表征,一类是基于关系的向量表征。
3. 基于标签的向量表征
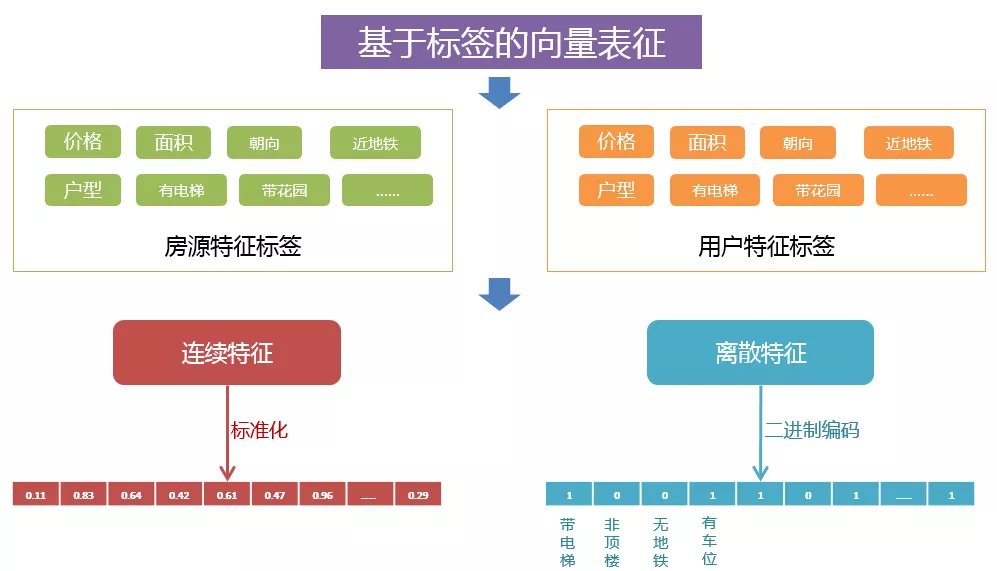
基于标签的向量表征是比较好处理的,比如说对于房源,都有对应的价格、面积、朝向等信息;对于用户来说,同样具有其偏好的价格、面积、朝向等信息。针对于信息中连续特征,可以将其进行标准化作为特征标签向量的值。对于离散特征,可以进行二进制编码,然后加入标签向量。
基于标签向量表征的优点在于其实时性比较好,假设来了一个新房源,可以很容易将房源的属性转化为房源的标签向量。缺点是在计算相关性的时候,是基于现有的标签,没有一个自适应的能力,或者可以说学习新标签的能力。
4. 基于关系的表征
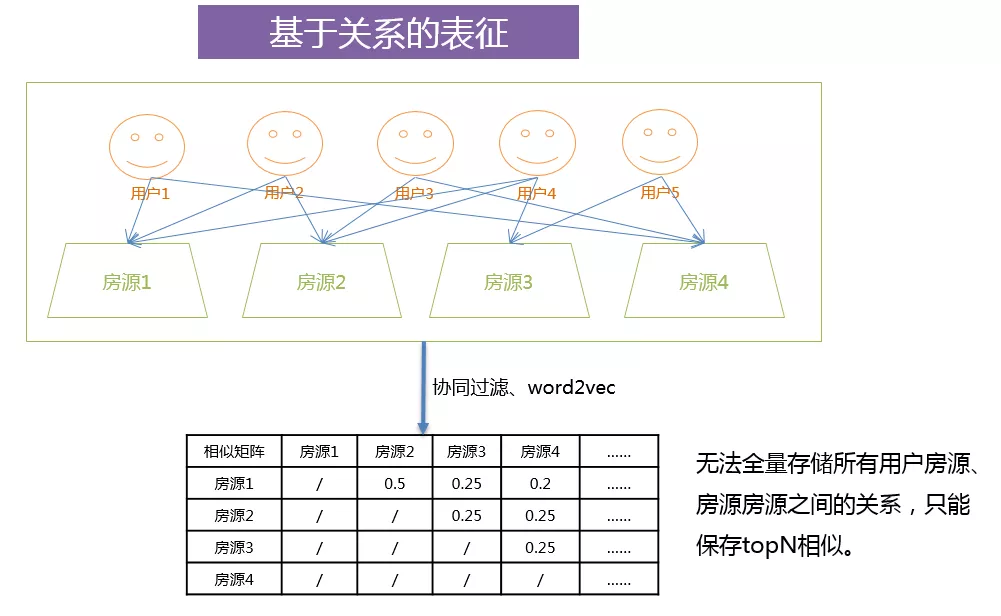
基于关系的表征,使用了群体智慧,拥有自适应的能力。比如图中的用户 2 和用户 4,他们同时都看了房源 1 和房源 2,这就说明房源 1 与房源 2 存在着某种潜在的关系。这种关系是可能他们价格相同,或者是在同一个小区,或者有可能有同样的对口学校,或者其它内在的联系。所以说,基于关系的表征可以发掘出用户和房源、房源与房源之间潜在的联系。
一般使用的协同过滤或者 word2vec 算法就是基于这种思想,对于这种关系表征,我们一般使用相似度表进行保存,但是由于相似度表无法保存全量用户和房源、房源与房源之间的相互关系,一般情况下只能使用 topN 相似结果进行保存。
这种保存方法存在一定的问题,比如前面提到的零少结果页的场景,根据用户已知搜索的标签,是可以召回一批房源的,但是这批房源与使用关系表征取得的 topN 相似房源交集可能会很小。所以在召回的大部分场景下都很难引入关系特征,因此我们就需要引入 Embedding 的思想,对关系进行量化。
02Embedding 的相关技术
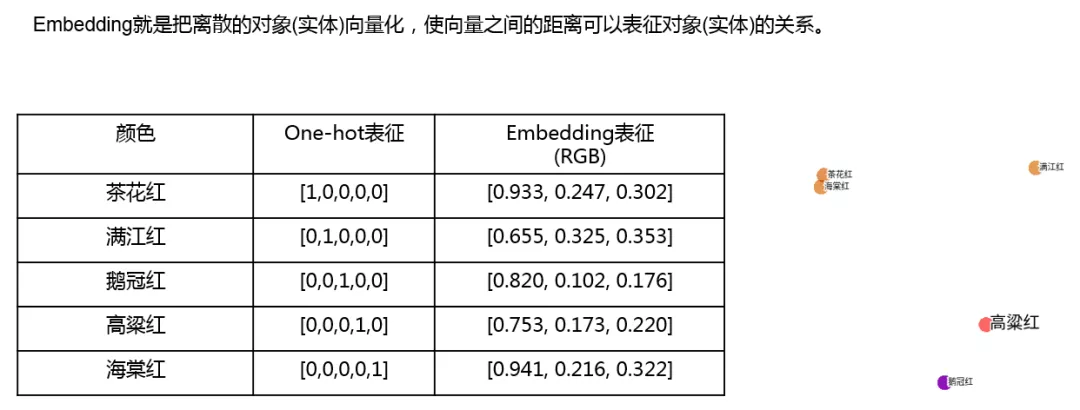
先来介绍下什么是 Embedding,Embedding 就是把离散的对象 ( 实体 ) 向量化,使向量之间的距离可以表征实体的关系。
举例说明:上面的图中有五种颜色,总体来说的话是五种红色,但是对我们大多数人来说,并没有什么概念,也不清楚哪些红色比较相近,如果我们能知道颜色的 RGB 值,就可以很轻松的了解这些颜色之间的关系。比如通过 RGB 值我们知道茶花红和海棠红是比较接近的,其实颜色的 RGB 值就可以理解为对于颜色实体的 Embedding。
那么具体有哪些方式可以进行 Embedding 呢,下面举一些具体的例子。
1. ALS
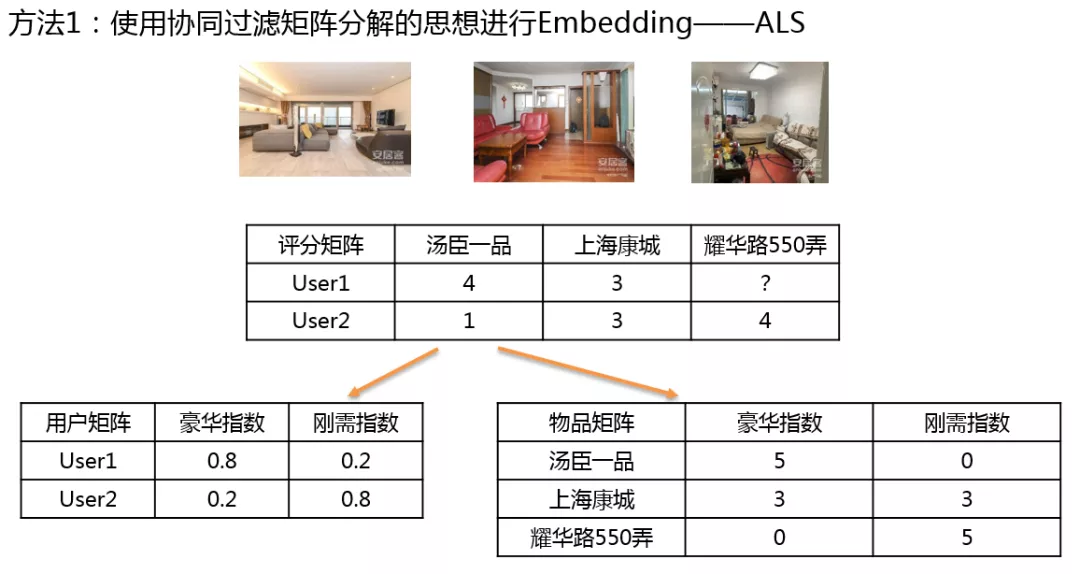
第一种,使用 ALS 进行 Embedding,ALS 是通过矩阵分解实现协同过滤的一种方式。
首先构造一个评分矩阵,可以看出 User1 对于汤臣一品的打分是 4 分,对于上海康城是 3 分,耀华路 550 弄分数暂不清楚。User2 对于汤臣一品的打分是 1 分,对于上海康城是 3 分,对于耀华路 550 弄为 4 分。使用 ALS 可以将 2 3 的矩阵分解为一个 2 2 与 2 3 的矩阵,其中 2 2 的矩阵为用户矩阵,2*3 的矩阵为物品矩阵。怎样来求解呢?
可以先对用户矩阵进行一个随机的赋值,使用最小二乘法得到物品矩阵的值,然后再固定物品矩阵,反过来求用户矩阵,通过交替使用最小二乘法,可以使两个矩阵数值逐渐趋于平稳,我们就可以认为最上面 2*3 的矩阵是用户矩阵与物品矩阵的乘积。可以看到用户矩阵与物品矩阵都有豪华指数、刚需指数两个维度,当然这两个维度是在矩阵分解之后人为总结的,其中用户矩阵就可以理解为用户对于房源的 Embedding。
分析可知,在用户矩阵中,用户 User1 对于房子的豪华的偏好程度比较高,刚需指数较低,所以他对于耀华路 550 弄不太感兴趣。在物品矩阵中,汤臣一品和上海康城的相似度要比汤臣一品与耀华路 550 弄的相似度要高。
2. Skip-gram
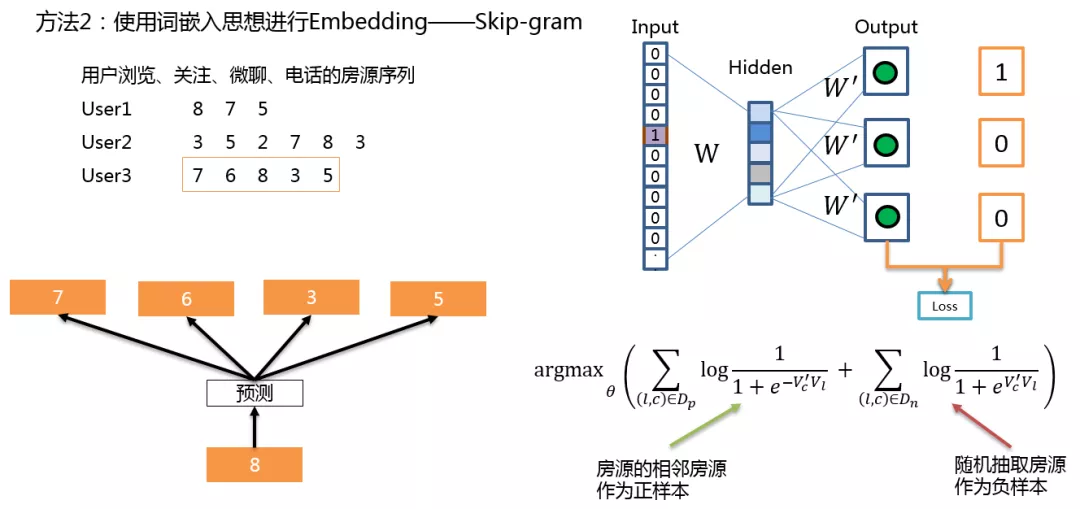
第二种,使用自然语言处理中的 Skip-gram 算法进行向量表征。首先将用户产生的浏览、关注、微聊、电话等信息生成房源序列,一个用户的行为序列就相当于一个句子,序列的房源就相当于词。Skip-gram 算法认为相邻的房源是有相关性的房源,这些房源的相互关系可以作为正样本,图中左下角的 8,可以认为与 7、6、3、5 是具有正相关性的,这是正样本。我们也可以抽取一些随机出现频率比较高,但是不相邻的房源作为负样本。模型主要有三层,输入是房源的 one-hot 表示,通过输入的参数矩阵 W 转化为隐层固定维度的向量,再乘上输出参数矩阵 W’ 转化为输出值,在输出层没有使用 softmax 函数,因为加入了负采样,就没有必要计算所有词与目标词之间的相似度,所以这里就使用 sigmoid 函数计算目标词与正负样本之间的相似度,对比真实的标签,构造损失函数。
图中右下角为目标函数,需要通过优化参数来极大化这个函数,当 c 是 l 的正样本的时候,l 的输入向量与 c 的输出向量内积要尽量的大;当 c 是 l 的负样本的时候,l 的输入向量与 c 的输出向量内积要尽量的小,然后我们可以通过随机梯度上升来求解这个参数。
3. DeepWalk
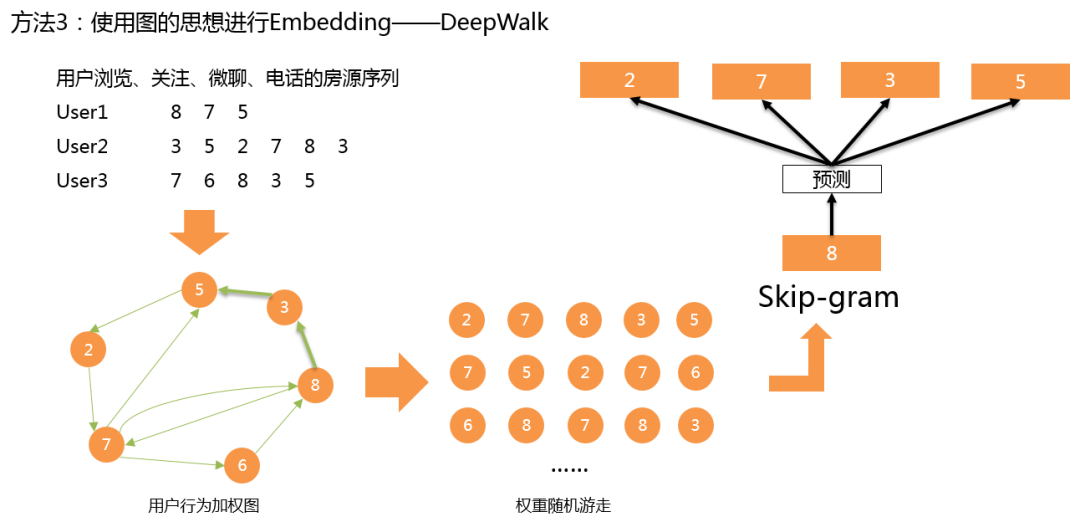
第三种,使用图的思想进行 Embedding。将用户的房源序列抽象成一个有向带权图,然后轮流以每个结点为出发点,根据权重进行随机游走,就可以形成新的房源序列。然后对于新的房源序列继续使用 Skip-gram 算法得到不同房源的 Embedding 向量。
4. 效果展示

这里就是以上三种不同 Embedding 的效果展示,使用 T-SNE 进行降维,不同颜色代表不同的区域,我们可以看到 Embedding 的效果还是比较不错的,分的比较清晰的区域就是当前城市比较偏远的区域,这些区域和其它区域重合的可能性比较小,所以分的比较清;对于图中重合的区域,就是城市的中心相邻区域,由于交通比较便利的原因,可能用户中心区域的房源都会看,在颜色上也会有比较大的交叉。
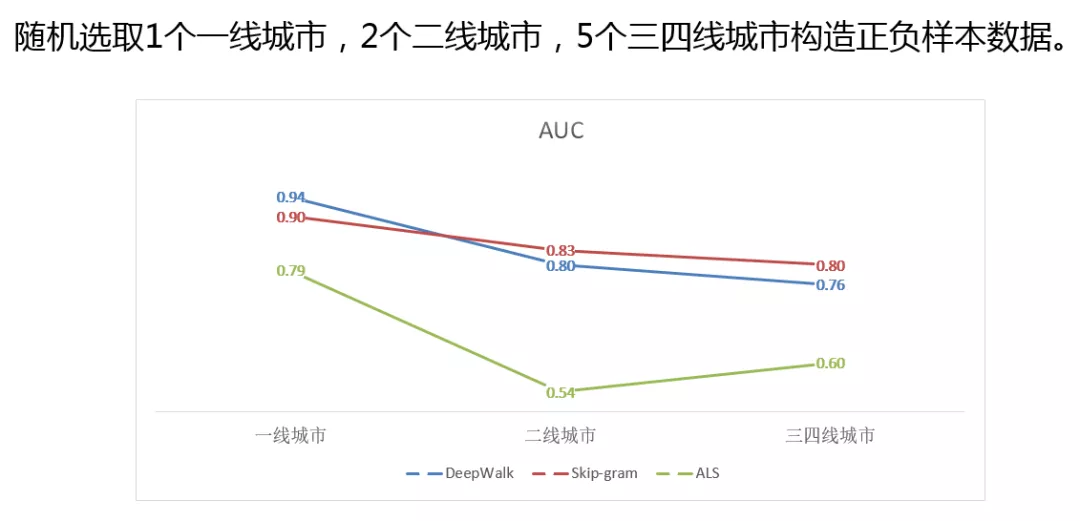
因为上面的图并不能直观的展示出哪种 Embedding 效果好,所以我们构造了一批正负样本,通过样本数据的 AUC 值来评测 Embedding 的效果,正样本取共现次数比较多的房源对,将这些房源设为正样本,取没有共现的高频房源作为负样本。可以看到 DeepWalk 在一线城市是比较好的,可能是因为一线用户量比较大,对于模型来说可以得到充分的训练,可以随机游走出比较好的房源序列。在二三线城市,Skip-gram 算法要优于 DeepWalk,可能是因为小城市数据量比较少,DeepWalk 模型差一些。看 ALS 模型的话,其在一线城市还可以,但是二三线城市降低了很多,应该还是由于打分矩阵过于稀疏,无法做很好的训练。
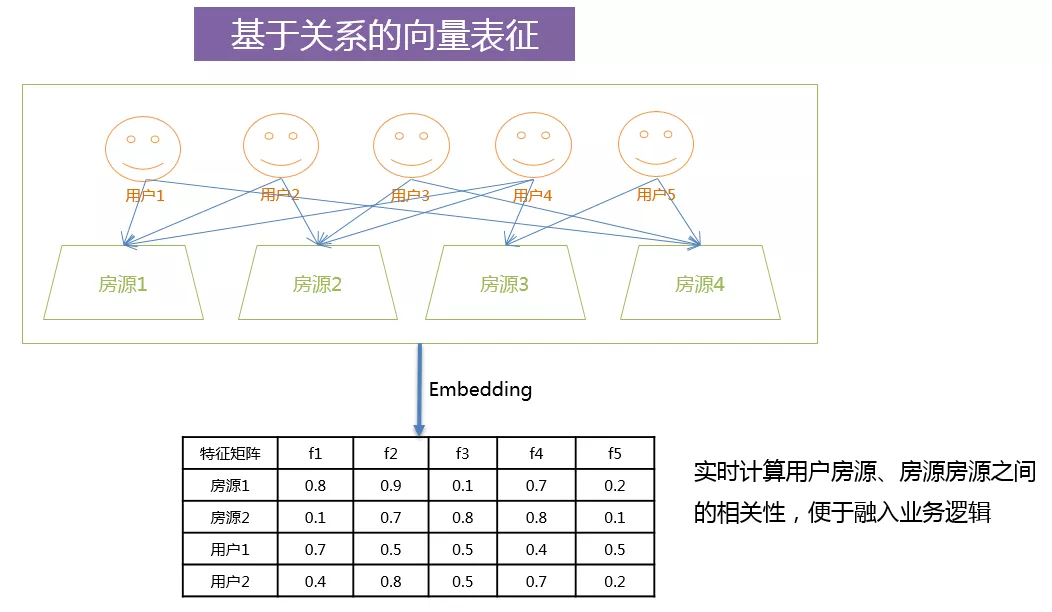
通过以上列举的三种方式,我们可以将用户和房源之间的关系进行向量化,通过计算出向量之间的余弦相似度,就可以实时计算出用户和房源之间的相似度。这样,就可以将基于关系的推荐,不仅应用于房源的召回阶段,也可用在精排阶段,作为输入的数据。
03Embedding 在推荐中的应用
下面详细介绍下 Embedding 技术在线上的具体应用:
1. Skip-gram 模型的应用
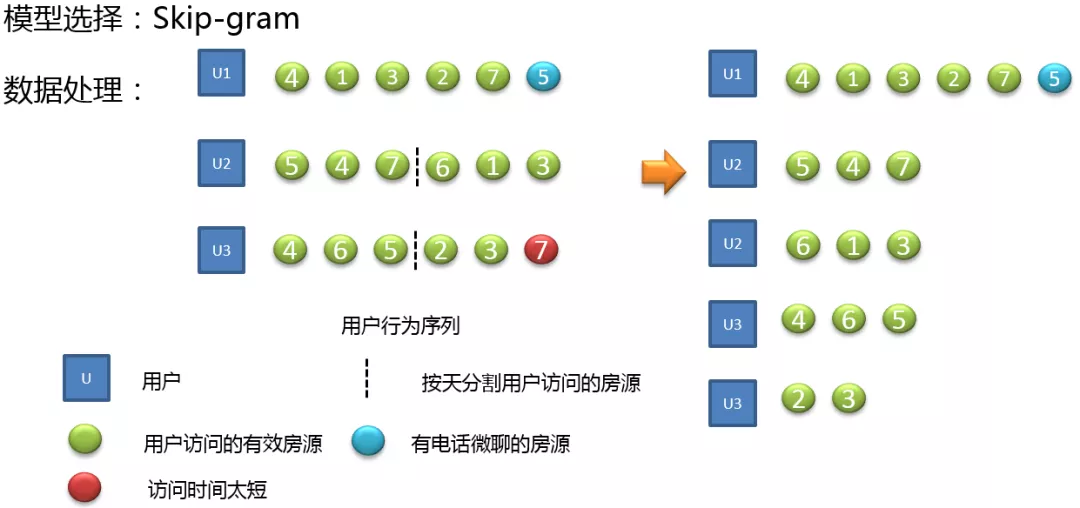
首先我们需要对数据进行预处理,区分了房源和用户之间的关系,如果只有访问的话,我们认为是一种弱关系,用绿色表示;电话和微聊是一种强关系,使用蓝色表示;同时我们还会去掉一些停留时间比较短的房源,其有可能为用户的误触。对于用户多天的行为序列我们会进行按天进行分割,因为两天的房源跳跃会比较大,会影响模型的计算。经过处理后,左面的房源序列将转变为右面的房源序列。
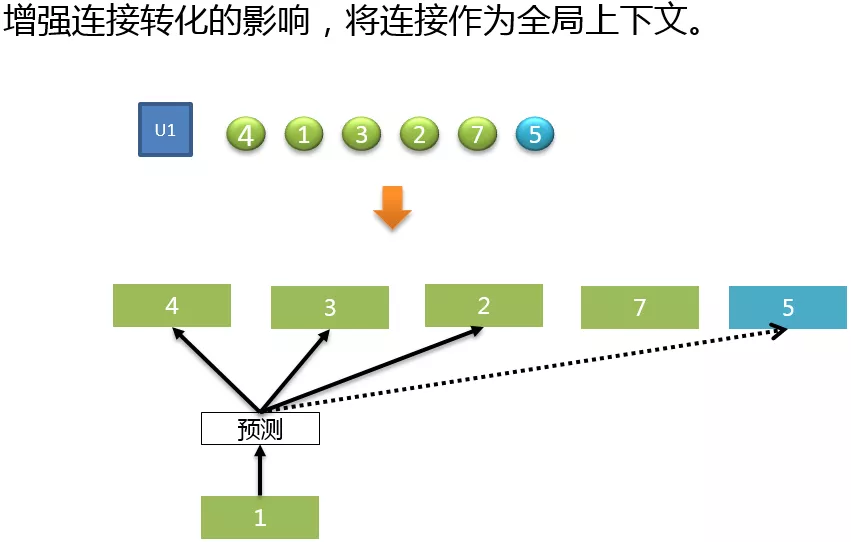
参考了 Airbnb 在 2018 年关于 Embedding 实时搜索排序中应用的论文,为了增强连接转化的影响,也把用户有电话、微聊等连接行为的房源作为一个房源序列的全局上下文进行训练。
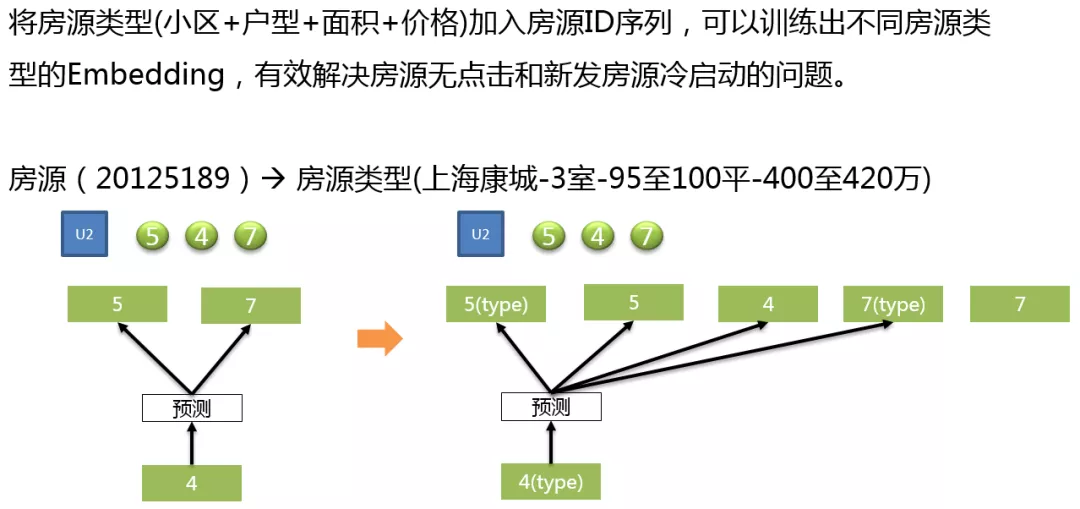
为了解决用户的冷启动问题,我们还在用户的房源序列中加入了房源 Type 类型,如上图,房源 ( 20125189 ) 就对应着房源类型是 ( 上海康城-3 室-95 至 100 平-400 至 420 万 ),通过加入这种类型,我们在训练房源 Embedding 的同时,也可以得到这种类型房源的 Embedding。当一个房源没有算出具体的向量时,就可以使用房源对应的类型向量进行一个补充。这里把房源对应的类型放在了房源前面,也是有一定的思想在里面,可以认为在用户的看房行为中,用户首先看到房源列表页的房源信息描述,表示用户对于这种小区、户型、面积、价格的组合特征感兴趣了,之后才会点到房源单页。故是先对与房源类型感兴趣,然后才是到单页,对房源有行为,这是存在先后关系的。
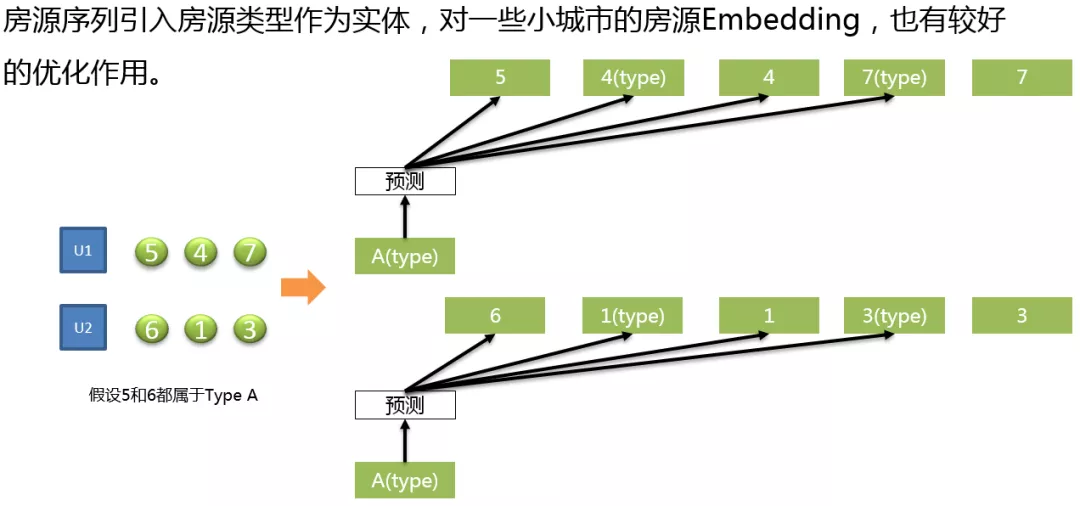
引入房源类型作为实体,对于一些小城市的房源序列 Embedding,有比较好的优化作用。
如图所示:用户 1 看了房源 547,用户 2 看了房源 613,如果房源 5、6 在其它房源序列中没有出现 5、6 共现的情况,那么 Embedding 是无法学习到房源 5、6 之间的关系,但是如果我们引入一个 type 类型,假设 5 和 6 都属于类型 A,就可以知道房源 5、6 之间是有一定相似性的。
可能有的同学会担心这样标签的引入会有标签泄露的问题,我个人觉得这种相同的小区、户型、面积、价格这种组合下的房源相似度很高,这其实是房产业务中的一种专家逻辑。在这里加入这种逻辑可以更好的帮助 Skip-gram 模型进行 Embedding 的训练。
2. DeepWalk 模型的应用
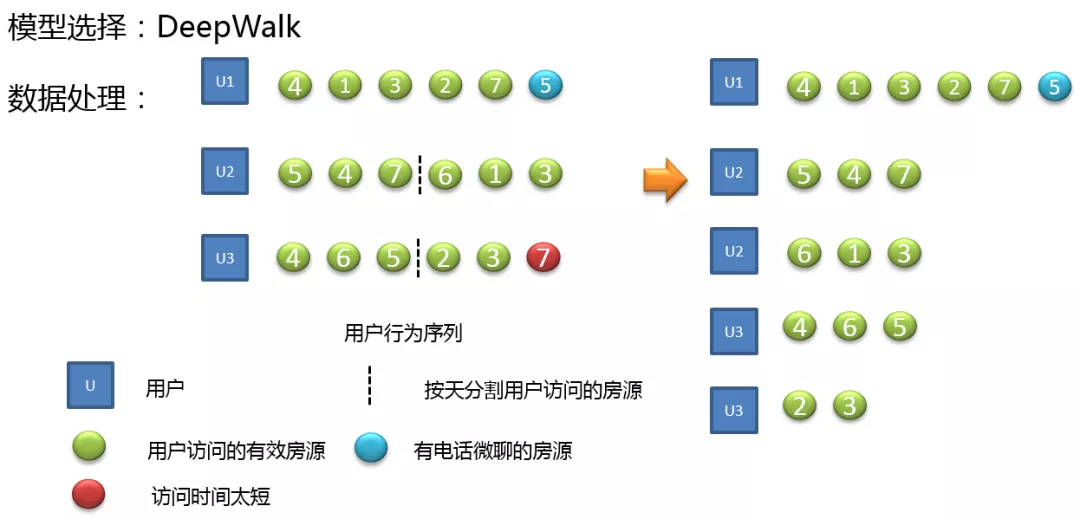
通过之前的实验,我们知道 DeepWalk 在数据充足的情况下,Embedding 的效果要好于单纯使用 Skip-gram,所以在大城市,我们会使用 DeepWalk 进行 Embedding,这里我们还使用相同的方式进行数据清洗及预处理,
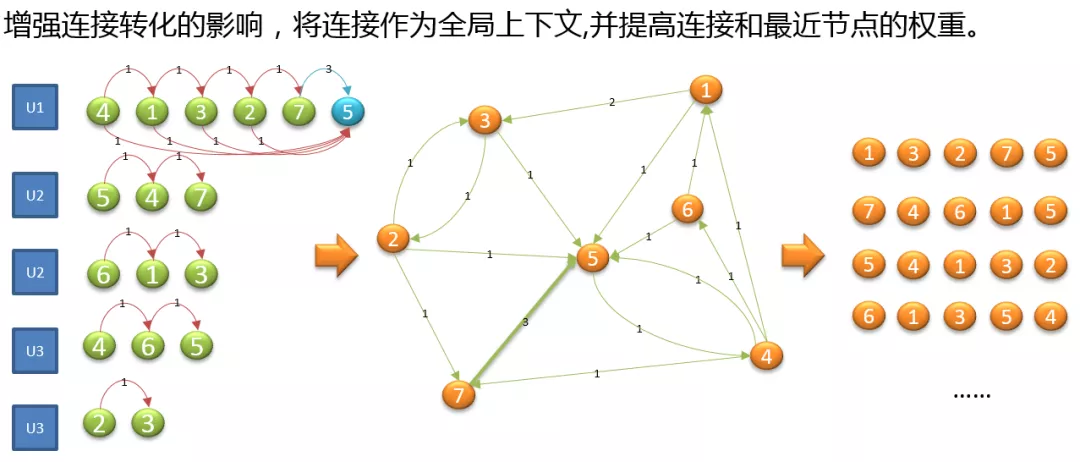
为了增加连接转化的影响,我们将连接作为全局的上下文,提高连接和最近节点的权重。图中,对于用户 1 的房源序列,5 是一个连接节点,这样将 4 到 5,1 到 5,3 到 5,2 到 5 都增加了一个转化权重;因为 7 到 5 最近,所以转化权重设置为 3。通过转化,构造有向带权图,最后随机游走,构建出新的房源序列。
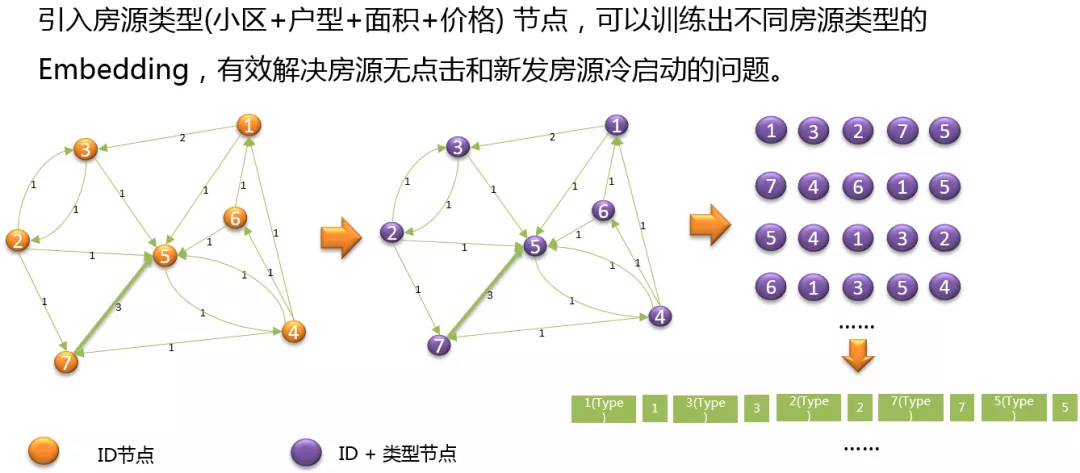
同样的引入 Type 类型,将 ID 节点图,转化为 ID + 类型节点的图,然后在通过随机游走,得到 ID + 类型的序列,得到 Type id 的序列,训�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E6%8A%80%E6%9C%AF%E5%9C%A8%E6%88%BF%E4%BA%A7%E6%8E%A8%E8%8D%90%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


