在线学习在爱奇艺信息流推荐业务中的探索与实践
2019 年 11 月 16 日 08:00
奇文
概述
爱奇艺的信息流推荐业务每天会产生数十亿规模的 feed 浏览,如此大规模的数据给模型训练带来了很大的挑战。同时,信息流这类用户与推荐系统的强交互场景也引入了很多有趣的研究课题。对于信息流推荐产品来说,用户和产品交互性高,用户兴趣变化也很快。若模型不能及时更新,排序模型部署上线后,性能会缓慢下降。而对于排序模型来说,如何用较低成本完成百亿样本、千亿参数 DNN 排序模型的及时更新是需要解决的首要问题。
引入在线学习是解决此类问题的首选方式。在线学习(Online Learning)能捕捉用户的动态行为模式,实现模型的快速自适应,它对数据 pipeline 的稳定性、流式样本的分布纠偏、模型训练的稳定性以及模型部署的性能都提出了很高的要求,成为提升推荐系统性能的利器。在线学习为爱奇艺多个信息流推荐场景都带来了明显的效果增益,对新内容的分发也起到了明显正向的作用,验证了“唯快不破”的真理。
本文就来介绍一下爱奇艺技术团队我们的相关成功实践。基于学术界和工业界的经验,探索出一套比较适合工业化实践的 W&D 深度排序模型的在线学习范式,实现了消费流式数据、DNN 模型的实时训练和及时更新。
在短视频信息流推荐和图文信息流推荐方面,完成了 AB 实验和全流量上线,推荐效果和用户体验较之前的离线模型都获得了较大的提升,短视频信息推荐消费指标 +1.5%,图文信息流推荐消费指标 +3.8%。此外,数据证明在线学习的上线对于新内容的分发有比较明显的助益,也能在新内容上线当天进行快速试探,判别内容的优劣。以图文信息流推荐为例,新 Feed 的平均分发量增益在 **10%**以上,而且这些 feed 的点击率也有明显提升。
信息流推荐排序模型目前的挑战
目前,业界主流的信息流个性化推荐的排序模型目前基本都已转向 DNN 模型,如 W&D、DeepFM 等,相比以往以 GBDT/LR/FM 为典型模型的浅层模型来说, 产生了下面几个新的问题:
1. 模型更重
模型的宽度和深度,决定了模型参数空间的规则。DNN 模型是多层感知模型。亿级别的 ID 特征 (UserID、ItemId、用户行为序列等) 和 Dense 特征(统计特征、Session 特征、多模态 Embedding 特征)输入,经过一个 1024 个激活 Cell 的 Hidden Layer, 模型参数可以很容易达到千亿级别。
2. 训练成本更高
有更多的训练数据,迭代次数更多,DNN 模型才能收敛到最佳状态。从样本准备到整个模型训练完成,周期更长,模型更新效率不高。而且训练需要的硬件资源更多,目前基本是 GPU 训练平台为主,即使换成 CPU,还是需要数十倍的 CPU 资源才能匹配 GPU 训练的效率。
3. 训练收敛性问题
训练一个百亿样本,千亿参数的 DNN 模型要想要达到理想的效果,会遇到很多超参数调优问题,如 batch size,、学习率、正则系数、优化器的选择等。这些参数组合的变化都可能会影响模型的最佳潜能。
从上面可以看出,要完成一个 DNN 模型的实时更新并非易事。而在传统机器学习时代,只需要给模型最新的数据,通过在线学习算法(如 FTRL)做到模型的实时更新,实现了浅层模型的实时更新 [3,4,6]。在线学习需要的数据,训练资源都明显低于离线训练场景。
DNN 模型的在线学习挑战
DNN 模型的在线学习不能直接硬搬 LR+FTRL,主要的挑战如下几方面
:1. 解决 OOV 问题
目前已有的 DNN 模型基本都加入了 ID 特征来加强模型的记忆性。如何将新的 ID 快速加入模型的词典,并通过在线学习更新其权重以及如何快速淘汰老的 ID,避免在 long running 场景下,模型词典文件不会快速膨胀而不够用,是一个较大的挑战。
2. 非凸模型的在线梯度下降的收敛问题
目前还不能确定 Adam 家族是否还能应对 DNN 模型的在线学习场景,过一遍数据是否能收敛。
3. 正样本 delay 实时数据分布不是真实分布时需要纠偏
广告的场景如 CPA 类广告,转化类正样本 delay 现象比较明显。在爱奇艺短视频推荐场景下,视频的 label 逻辑不只与点击相关,还要关联到时长。用户在观看一个视频结束后,才会上报时长日志。若点击没有关联到时长,是不能作为正样本的,需要等待时长日志到来。
DNN 模型的在线学习业界的解决方案
DNN 模型的在线学习其实已经在业界很多公司落地,阿里 XPS 平台上通过在线学习训练和更新的小时级 XNN 深度模型,在 2017 年的双 11 期间应用在淘宝猜你喜欢和天猫推荐场景 [7]。阿里蚂蚁金服团队也在 2018 年基于类似底层平台上线了在线学习深度模型。[1]
以阿里 XPS 为例,基于 C++ 实现了动态扩缩容的 embedding lookup 算子,底层是基于 C++ 实现的 XPS-ArrayHashMap,支持 ID 特征的增删, 自适应的解决了 OOV 问题。其针对 DNN 模型,提出了 XNN 深度学习算法,自适应于 streaming data 的深度模型训练。
现有的模型结构及训练范式介绍
参考已有的业界的实践,我们基于公司的深度模型训练平台,实现了在线学习在短视频信息流和图文信息流推荐的成功落地,下面介绍关于爱奇艺的实践方案:
1. 主模型结构
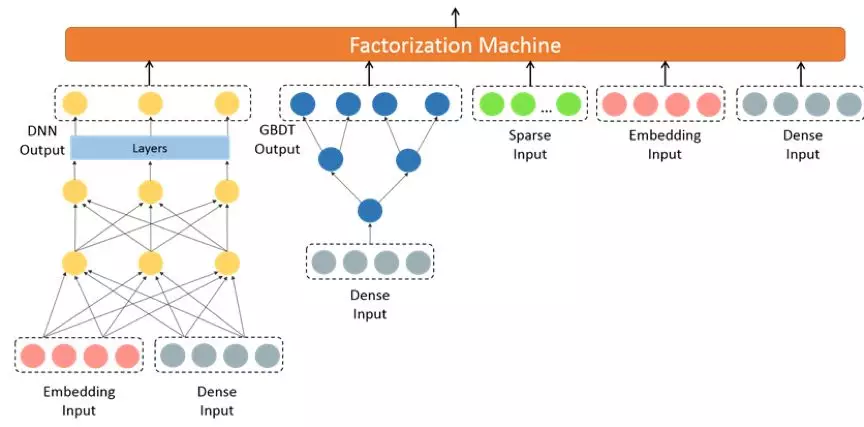
这是一个 W&D 模型变种,但是 Wide 侧和 Deep 侧是各自经过一个 FM 后再进行结果融合:
- Deep 的输入包括 Embedding 特征和 Dense 特征, Wide 侧包括 GBDT 叶子节点,ID 类的 Sparse 特征, Embedding 特征和 Dense 特征;
- GBDT 的输入主要是以统计特征为代表的 Dense 特征, 是一种基于模型的显示特征组合;
- DNN 的优化器是 Adam, Wide 侧优化器是 FTRL;
- 基于公司内部的深度学习平台训练离线模型。
2. 现有的模型迁移到在线学习的局限
- DNN 部分迁移到在线学习,可能不像 wide 侧线性模型那么容易收敛。对于 DNN 深度模型的在线学习优化,目前还没有成熟的优化器,FTRL 更适合线性简单模型;
- GBDT 不适合增量 / 在线学习;
- 在线学习训练持续 running 的情况下,Wide 侧的输入 ID 特征,在线学习训练持续 running 的情况下, oov 几率会显著提升。
训练范式
1. 在线学习 + 离线模型热启动的范式
爱奇艺技术团队通过实践探索,形成了一个比较成熟的在线学习框架——在线学习 + 离线模型热启动的范式。这里来先介绍下框架:
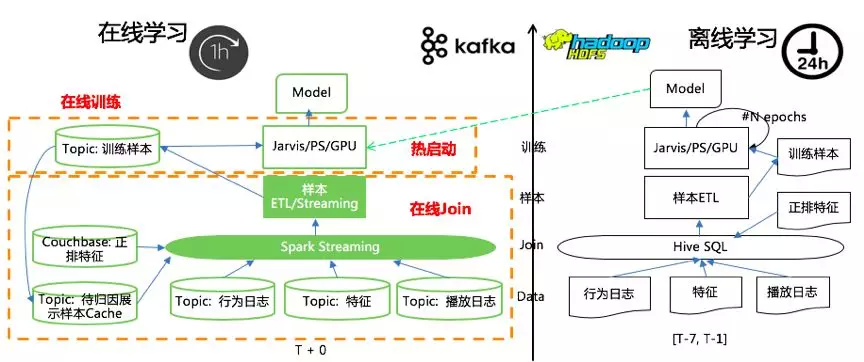
- 左侧是在线学习,右侧是离线学习:离线训练仍然保留,它基于 7 天历史数据训练,主要是用于在线学习模型每天的热启动重启。在线学习消费 Kafka 实时数据流,实时训练模型;
- 数据实时化:在线学习的数据流从用户行为数据到模型训练样本的生产都是在线进行的,实现了样本、特征和时长数据的在线 Join, 数据流都通过 Kafka 向后传递;
- 模型训练实时化:在线训练任务消费训练数据的 Kafka Topic,且只消费一次(one pass)。模型除了每天基于最新离线模型热启动重启一次,当天都是 long running 的;
- 模型同步:模型按小时例行化导出模型文件同步给引擎,这里的同步效率可以自行调节。
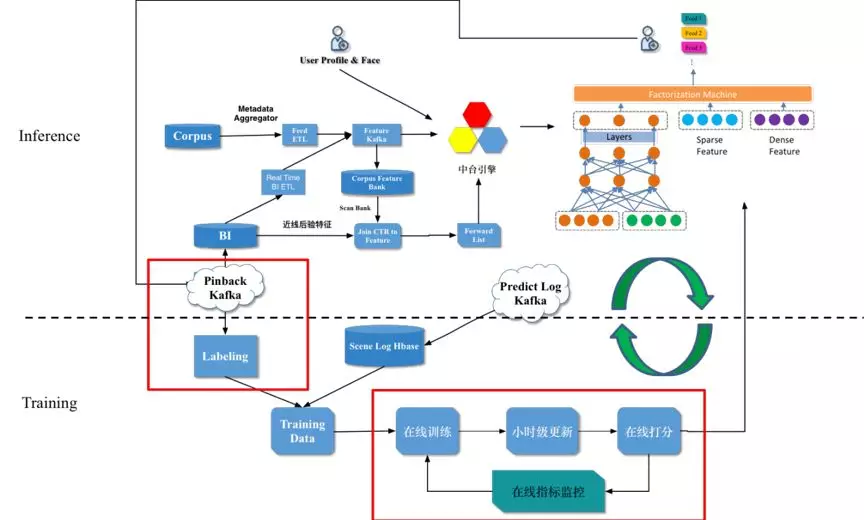
以图文信息流推荐为例,在线学习引入前后的整体数据流图如下:
2. 数据实时化难点
- 多路实时数据的在线 Join,包括用户行为数据, 特征等。
- 样本归因。因为行为上报的天然串行化,会导致 Label 的滞后性:用户展示行为 « 用户点击行为 « 用户播放日志。同一个用户在同一个 feed 上产生的展示数据和点击数据先后到达时,需要确定如何归因样本 label 和更新模型。
样本归因实践
一个视频 item 上的负样本一般会先到达,后续同样视频上的正样本到达,对于这两个样本在流式到达时如何处理并更新模型,目前有两种范式:
- Facebook 的做法 [34]:负样本会先 cache, 等待潜在的正样本到达,若后续正样本到达,则只保留正样本,更新模型一次。
- Twitter 的做法 [3]:两条样本都会保留,都会去更新模型,这样实时性最高。
我们对两种方法都进行了尝试,结论是后者更适合现有的工程架构,通过 loss 修正效果上并不弱于前者。
2. 实践逻辑及困难解决
负样本 Cache 策略:最终确定的 Cache 窗口为 10 分钟,基于 impression 和 vv 的时间差分布统计,10 分钟的窗口内有点击的 impression 和 vv 的 join 成功率达 90%+。
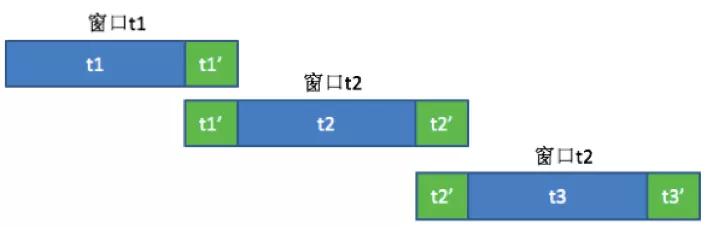
基于 Cache 窗口的 Join 逻辑示意图如下:
假定时间窗口大小 t1 是 20min,cache 保留窗口 t1’是 10min:
第一个时间窗口,我们结合 t1 和 t1’来统计信息,即 label 的归因;
第二个时间窗口,我们结合 t1’,t2 和 t2’来统计 label。
没有 cache, 每条最新样本都去更新模型,这样会存在 False Negative 或者说无法确定 Label 的样本也更新了模型这样的问题。Twitter 2019 最新的一篇论文 [6] 提出了如何在进行纠正,主要包括以下四种方法:
- 样本重要性采样 (importance sampling):机器学习模型一般是假设样本符合一个特定数据分布,模型训练就是一个搜索最佳的数据分布参数的过程。观察到实时样本流样本分布由于包含了 FN 样本,其实是一个有偏的分布。类似于强化学习等场景,会使用到重要性采样方法对给予每个观察到的样本权重进行纠正,近似一个无偏数据分布。
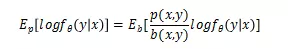
- FN 矫正:模型拟合当前观察到的有偏分布 b, 经过论文推导,无偏预测 p(y|x) 和有偏预测 b(y|x) 的关系如下。因此用包含 FN 的实时样本训练模型 b 后,预测时用下面的公式进行矫正即可。
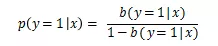
- PU loss (Positive-unlabeled loss): 本质就是认为所有观察到的负样本都是 unlabeled. 因此对 loss 进行了如下改造,核心思想就是在观察到一个实例的正样本到达时,除了使用正样本进行梯度下降,还会对相应的负样本进行一个反向的梯度下降,抵消之前观察到的 FN 样本对 loss 的影响。
- 延迟反馈 Loss: 使用一个额外的模型去建模当前样本的真实 Label 确定时的时间延迟,基于当前样本距离上次展示的时间距离去评估当前样本的 Label,是一个 true label 的概率。这个时间延迟模型和 pCTR 模型联合训练,优化 loss 如下,其中 Wd 就是时间延迟模型的参数。
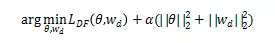
我们尝试了上面的第二种和第三种方法,目前线上使用的版本是第三种方法,论文实验中效果最好的是第二种方法,这个可能和业务数据分布不一致有关。
模型实时化
在线学习场景下模型结构虽然和基线一致,但训练方式和离线训练存在一些不同
:1. GBDT 不适合在线学习
我们固定了 GBDT 部分,实验期间 GBDT 不再更新,用作特征抽取器。所以这里需要定期更新,目前我们是按月更新,通过 AB 实验看,更新是有一定收益的,所以这也促使我们正在实验 DNN 的高阶特征交叉方式来替换掉 GBDT。
2. 模型会基于离线模型进行热启动重启。
因为 GBDT 固定,因此模型的热启动可以做到直接加载最新离线模型的 checkpoint,然后开始进行在线学习,持续更新模型参数。
a) 热启动的原因 1: 在线学习是 one pass 的,如果持续 long running,模型可能会因为一些局部 pattern 而被带偏,基于离线模型热启动可以对其进行矫正。
b) 热启动的原因 2: 如果模型训练是 long running 的,会导致 OOV 概率越来越大。实验期间深度学习训练平台还不能做到自适应的动态 ID 增删 [1],因此需要显示的手动重启,扩大 ID 空间。训练平台最新的版本已经支持了动态增加,后续会进行 long running 实验。
3. 数据源不同。训练采用和离线一样的训练框架,但是数据源是 Kafka, 每条训练数据只进行一次梯度下降。
效果调优经验分享
- 典型的在线学习对于训练数据的消费是 One Pass 的,而离线模型的训练是 multi-pass。从优化角度讲,深度模型的在线学习是要解决在线非凸优化问题。FTRL 本身是一个适合在线学习的优化器。离线模型的 wide 侧实际上已经是 FTRL, 只有 DNN 部分是 Adam。我们尝试过把 DNN 部分的优化器也变为 FTRL,但效果是负向的,FTRL 比较适合稀疏线性模型的在线学习;
- 按小时例行的更新模型 vs 当模型性能超过基线时才更新模型:前者对于点击率的指标更有利,该策略下 uctr 正向明显。持续更新模型,能推出用户最近感兴趣的内容,点击率容易高;
- 模型长期不热启动重置,效果是呈现下降的趋势;
- 在线训练消费样本的轮数,我们做了下实验对比,过多遍会更好一些,这可能要结合实际业务数据进行优化。
实践效果
实践证明,在线学习对于推荐效果和用户体验都有比较明显的提升,爱奇艺短视频信息流推荐消费指标提升 1.5%, 图文推荐信息流消费指标相对提升 3.8%。
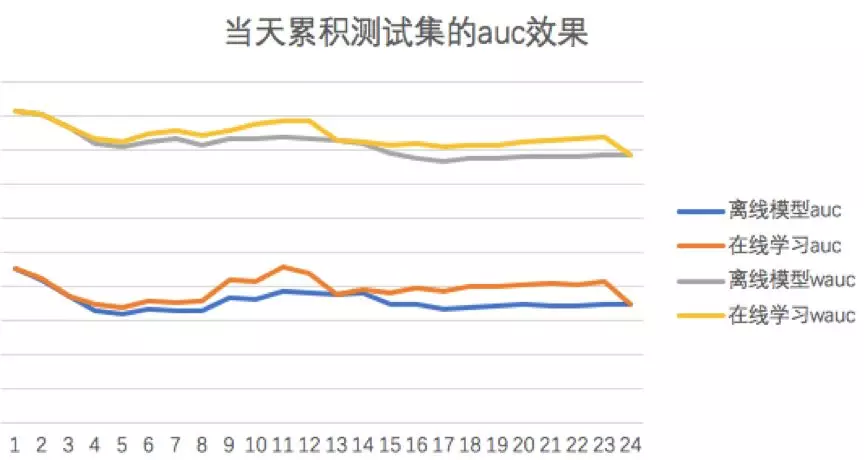
下图给出了短视频信息流产品推荐当天累积测试集的离线模型和在线学习每个小时推出的在线模型的 auc/wauc 对比,在线学习在当天测试集上表现优于离线模型。
1. 累积测试集:每个小时实时样本流不放回抽样 1.5% 加入累积测试集。T-1 小时的模型预测 T+1 hour 的数据,在线学习 AUC 是基于每个小时测试集的累积预测结果计算。
2. 离线模型:基于历史 7 天数据训练的离线模型,同时用于当天在线学习的热启动。
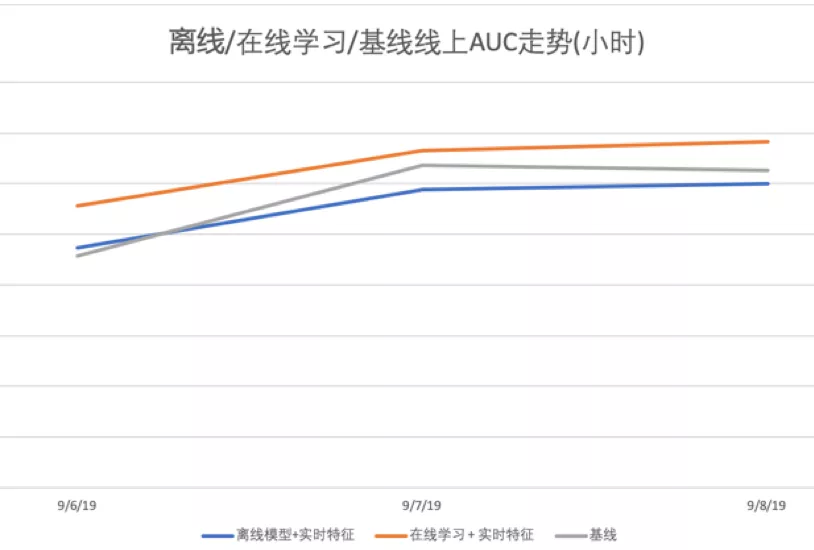
在图文信息流推荐产品上,我们论证了实时特征 + 在线学习的组合更能发挥出实时特征的最大化效果。下图是三个实验的多天在线 AUC 走势,可见实时特征 + 在线学习的 AUC 明显高于基线,优于实时特征 + 离线训练的组合。
后续优化
- 作为特征交叉组合的 GBDT 组件不太适合在线学习,后续切换模型为端到端的深度模型,去掉对 GBDT 的依赖。
- 探索更适合在线学习范式的深度模型和优化器,如 [2] 中的方法,在线学习的过程中自适应调整模型的深度,模型结构由浅向深的进行进化,避免模型过深带来的收敛慢和模型过浅带来的欠拟合。
- 尝试对实时数据流中的 ID 进行频次过滤,高维数据中大部分特征都是稀疏的,有必要进行低频过滤,离线有做这方面的内容,但在线学习还没有进行实践,如 [1, 5] 中的方法: 柏松分布或 Bloom Filter。
- 探索更高频率的更新模型,如半小时、分钟级。
参考文献:
- 蚂蚁金服核心技术:百亿特征实时�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9C%A8%E7%BA%BF%E5%AD%A6%E4%B9%A0%E5%9C%A8%E7%88%B1%E5%A5%87%E8%89%BA%E4%BF%A1%E6%81%AF%E6%B5%81%E6%8E%A8%E8%8D%90%E4%B8%9A%E5%8A%A1%E4%B8%AD%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


