多目标排序在爱奇艺短视频推荐中的应用
短视频具有 内容丰富、信息集中、用户粘性大 的特点,如何提高短视频 分发的效率 和 推荐精准度,有效提升 消费时长、留存 等关键业务指标,是 推荐系统 的核心能力和建模目标。
本文主要分享在 短视频推荐 场景下,爱奇艺基础推荐团队在 排序模型多目标优化 方面的 历史 和 进展。第一部分主要介绍 多目标建模的业务背景,第二部分介绍爱奇艺在短视频推荐业务 多目标建模方向 尝试和实践的 多种方案,最后是简单的 总结 和在多目标建模方向的 规划。
01 背景
在爱奇艺短视频推荐业务中,主要 流量形态 由 两个部分组成:
(1) 爱奇艺APP 底Tab的随刻视频 以及 顶导航的热点模块
(2) 爱奇艺 随刻APP 首页 短视频流推荐页面
图1:短视频推荐页面
用户在 feed流页面的行为 分为:
显示反馈: 点击播放,点击up主头像、关注、点击/发布评论、收藏、点击圈子、分享等正向互动行为,点击不喜欢、举报等负向行为。
隐式反馈:播放时长、完成率、用户快速划过等行为。
起初排序模型是以 点击+时长 的 多目标模型,随着业务发展和模型迭代,我们需要 兼顾用户评论、点赞等强互动行为 的生态收益, 减少用户短停等负向内容 的推荐。因此,我们在推荐系统多目标建模方向进行了一系列的尝试和实践,并在短视频推荐业务完成了技术落地,实现了 人均播放时长提升7%+、互动提升20%+ 等各项指标的正向收益。
02 多目标在短视频推荐业务中的实践
1.融合时长权重的点击率预估模型
在基于 ctr预估 的视频推荐中,普遍采用 YouTube的权重策略:
将正样本的播放时长作为样本权重,用加权的逻辑回归训练分类任务。
该策略会造成 长视频的权重较高,**模型偏向推出长视频。**综合来看,无论将播放时长还是完播率作为样本权重,都会导致模型对长短视频有所偏重。
因此,权重设计方案应 确定合理的假设: 视频推出质量与视频长度无关,且在视频时长的各区间下应近似均匀分布。 即在任何区间下,样本权重的均值大概相同。则有:
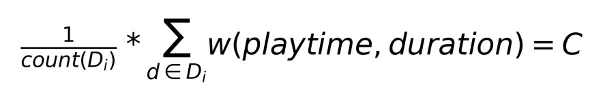
采用 等频分桶 的方式,对一定时间窗口内的播放样本按照 duration(视频时长) 排序分散到100个桶,确保同一桶中视频观看数相同。进一步地对每个duration桶按照playtime(播放时长)排序再次等频分散到100个桶, 并将权重归一化到[0,99]的区间整数。因此对所有样本,均可按照(duration,playtime)确定固定的分桶坐标 和 权值。
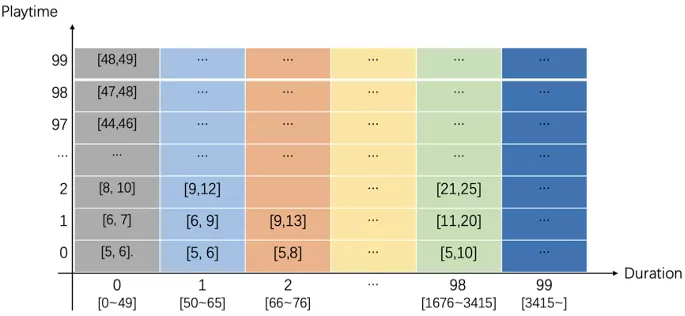
图2:对视频时长和播放时长进行分桶
在确定整体的权重计算框架后,进一步对playtime较高的样本权重进行整体提升。预期**优化消费时长的指标,同时控制长视频的偏向。**具体的boosting方案:
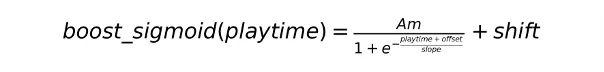
其中, Am是上界值,shift是下界值,offset是时长偏移量,slope是斜率。
为了完善视频生态,保证新老视频的权重具有一定的区分度。我们融合了 视频年龄(用户行为时间-视频发布时间)对样本降权**(年龄越大,权重越低) 。同时,为了能够使权重配置及时拟合整体用户最近的消费习惯,在保证任务产出效率的基础上,分别对不同平台用户生成 特定权重配置**,实现了 周期性更新。
线上收益:人均播放时长提升3%,UCTR提升0.2%
这种方案的优缺点:
**优点:**融合样本分布信息, 拟合近期消费习惯。模型调节简单, 可快速上线迭代。
缺点:将时长转为样本权重影响训练loss, 本质并非对多目标建模,而是将不同目标的信息转移到统一的目标上优化。而且时长信息利用不够充分, 收益有限。
2.多模型融合
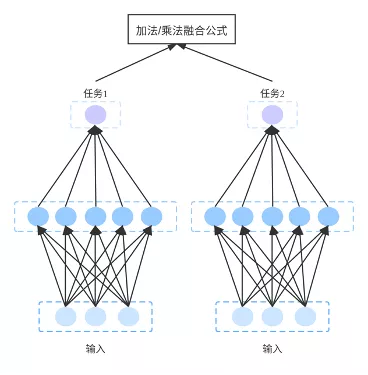
图3:多模型融合
多模型融合是指分别对每个目标训练一个模型,各预估得分根据目标重要性、业务指标需求等策略相加/相乘后进行融合排序**。**
在这里,我们分别训练纯点击的 二分类模型 以及 观看时长预估的回归模型。在离线调节融合参数时,采用 grid search 的方式选择更好的组合值。
这种方案的优缺点:
优点:模型单独训练, 只需要让单个模型达到“最好”,不需要考虑其它目标。
缺点:多个目标重要性难以估算,组合困难;考虑到数据集分布和模型训练的稳定性变化,需要评估模型更新和组合参数的更新时机;在线服务 计算量大,请求时长取决于较复杂的模型且 资源消耗巨大;如果增加的新目标数据比较稀疏, 难以进行有效的模型训练和迭代。
3.多任务学习-网络优化
随着爱奇艺随刻App朝着 社区化 的方向建设,要求feed流推荐效果在保证用户 观看时长、观看视频数、点击率 等基础指标稳定的情况下,引导用户评论、点赞等互动。基于业务现状和之前的迭代基础,我们在 多任务学习 上进行了一系列探索和实践。
在深度学习领域,多任务学习通常 共享底层表示,将多个任务放在一起学习,通过浅层的共享促进 相互学习。同时,由于 反向传播优化联合Loss,会兼顾 多任务间的约束关系,因此能够有效 防止过拟合。
目前工业界主要有 两种方法 对多任务进行建模:
(1)任务序列依赖关系建模;
(2)优化底层共享表示。
3.1任务序列依赖关系建模
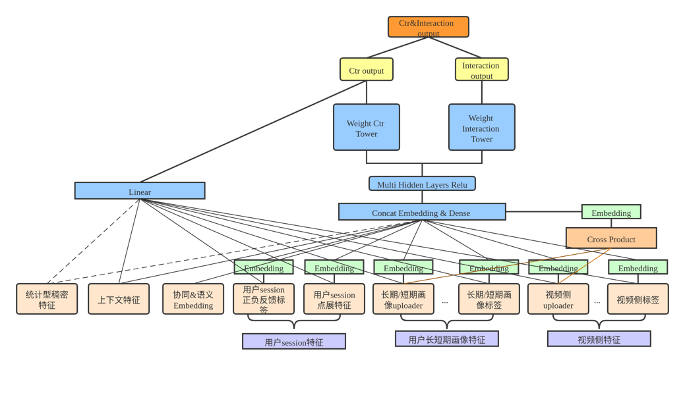
图4:基于ESMM的方案
推荐场景中,用户的行为通常具有 序列依赖关系,在阿里ESMM的文章[1]中,用户的 转化行为是发生在用户点击之后,因此基于序列依赖进行建模。如图4所示,对比feed流场景,点击是时长或者互动的前提,可以把 点击&时长,或者点击&互动作为ESMM迭代的方向。 实现上, 互动作为主任务,点击作为辅助任务,时长作为二者的正例权重,离线训练时两者loss直接相加。 我们曾经尝试过对两个目标预估值进行变化以及时长更多的Label制定方式,但线上效果均持平微正。
小结:点击和互动没有 绝对的联系, 点击&时长&互动,不适合ESMM应用场景; 互动行为非常稀疏, 训练效果较差; 多个目标的loss直接相加, 难以平衡对每个目标任务的影响,对模型训练造成扰动;不同目标可能 差异较大,难以共享底层表示。
3.2 MMOE+帕累托优化
我们分别对 观看时长 和评论数 Top 100 的视频进行对比分析,发现 重合度较低、排序差异很大,强制底层共享存在冲突。因此,我们采用了谷歌MMOE [2][3]的方案,但是考虑到联合Loss需要进行 大量超参调节,可能出现 目标一涨一跌 的现象,因此使用帕累托优化保证原有目标效果不降低的情况下,提升互动效果。
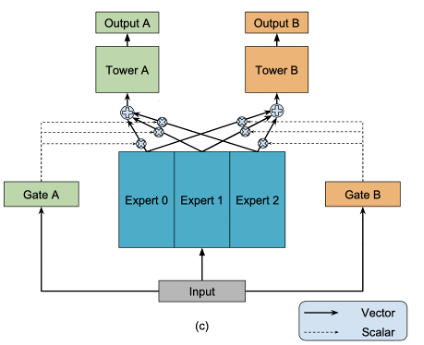
图5 MMOE模型结构
MMOE模型底层通过采用 Soft parameter sharing 方式,能够有效解决 两个任务相关性较差情况下的多任务学习。
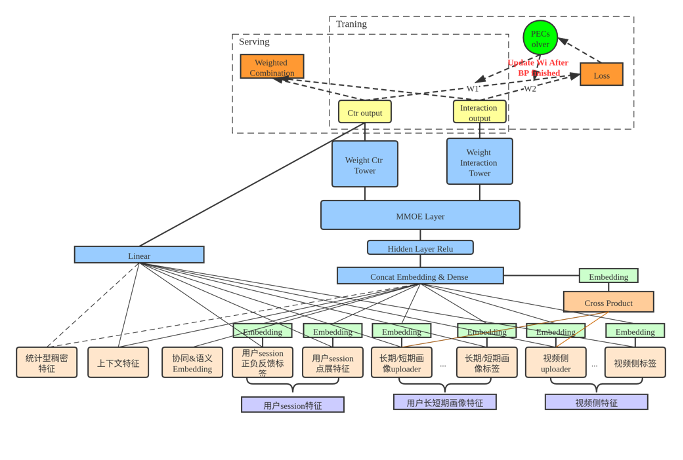
图6 基于MMOE+帕累托优化的方案
帕累托优化 主要参考阿里2019年发表于RecSys上的一篇文章[4],对比手动调节联合Loss,该论文使用 kkt条件来负责各目标权重的生成。大体步骤(如图中Training虚线框内所示):
(1) 均匀设置 目标权重值(可更新的),同时 设置权重边界值超参,运行 PE-LTR算法 在训练过程中不断更新权重值;
(2) 通过设置 不同的权重边界值超参,多次运行训练任务,根据 目标的重要性 挑选效果最好的模型。
线上收益:互动率提升20%,人均播放时长提升1.4%。
小结:实际使用中 权重边界值对模型效果影响较大,需要多次调优确定;多目标权重在前期已基本收敛, 中后期浮动较小;此 帕累托优化方案应用于离线训练,在线服务部分仍需要其它策略。
4.多任务学习-融合优化
除了对 网络结构 进行优化,我们对 模型推理阶段的多目标输出组合进行了优化,同时,加入了 完播率 和 时长目标,模型Serving时,通过融合各预估分实现多目标的协调和折中处理,保证模型 对各个子目标的排序均有较好的效果。 因此在进行多目标建模时, 首先优化联合Loss,保证各目标的离线效果均较优; 然后对各子目标进行融合排序,实现多目标的权衡和整体提升。
4.1 乘法融合升级
在线推理 时,使用可适配多种融合方案的 超参配置。在多目标融合初期,我们采用了加权和的方式。由于最终的排序得分对 各子目标的得分值域 很敏感,因此我们增加α和β两个超参,来联合调节各子目标得分的 灵敏度与提升比例。
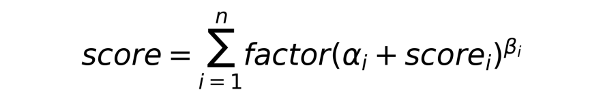
其中,αi: 超参,灵敏度;scorei: 模型i的输出;βi: 超参,提升比例,非线性处理;factor: 超参,组合权重;n: 模型数量。
在业务的目标较少时,通过 加法方式 融合新增目标可以短期内 快速获得收益。但随着 目标逐渐增多时,加法的融合排序能力会逐渐受限。主要包括:
(1)对于 新增目标, 乘法融合具有一定的目标独立性,无需考虑旧目标集的值域分布;
(2)随着目标逐渐增多, 加法融合会逐步弱化各子目标的重要性影响。
因此我们对多目标的融合方式升级为乘法:
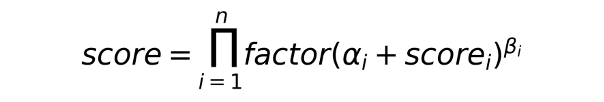
线上收益:CTR提升1.5%,人均播放时长提升1%。
4.2任务序列依赖关系建模
为了提升短视频的 播放渗透,促使用户 深度消费,我们新构造了 三个目标:
(1) 通过限定完播率阈值构造完播二分类目标,以近似满足逻辑回归的假设条件;
(2) 拟合平滑后的播放时长作为回归目标;
(3) 限定播放时长阈值,构建有效播放的二分类目标。
对于 回归目标,采用 正逆序对比(PNR,positive-negative-ration)来评估多目标预估值融合后的排序效果。最终在随刻首页feed流和爱奇艺沉浸式场景中均取得播放量和人均时长的显著提升。
线上收益:UCTR提升1%,CTR提升3%,人均播放时长提升0.6%。
4.3 PSO[5]进化优化算法
无论对预估分使用加法还是乘法方式融合,模型Serving时的超参均是通过 Grid Search 得到离线较优的几组解。需要 离线搜参 以及 线上AB �
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A4%9A%E7%9B%AE%E6%A0%87%E6%8E%92%E5%BA%8F%E5%9C%A8%E7%88%B1%E5%A5%87%E8%89%BA%E7%9F%AD%E8%A7%86%E9%A2%91%E6%8E%A8%E8%8D%90%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


