对的深入解读

作者:Madison May
编译:ronghuaiyang
导读 Reformer 之前已经提过几次,这次带大家更加深入的了解一下这个方法的思想及背后的动机。
自从最初的"Attention is All You Need"论文在 NLP 社区掀起了 Transformer 热潮,似乎我们一直在不懈地追求更大的模型。在 2019 年夏天,英伟达发布了他们的 MegatronLM 论文 —— 83 亿参数。在 2020 年 2 月,微软再次加大赌注,发布了一篇关于 Turing-NLG 的博客文章,拥有 170 亿个参数。
理解当我们增加参数数量和训练数据的时候,这些模型能到什么程度肯定是有价值的,我很高兴有这些资源可以进行大规模实验的公司已经这么做了。但是,相比来说,我们在如何把 Transformer 架构变的更加高效这件事情上,投入的太少了。
“Reformer: The Efficient Transformer” 来自 Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya ,与过去两年的“越大越好”的趋势形成了鲜明的对比,并在 2020 年的 ICLR 进行了报告。Reformer 的论文读起来就像呼吸了一股清新的空气 —— 这篇文章主要关注自注意力操作是如何随序列长度扩展的,并提出了一种替代的注意了机制,可以将来自更长的上下文的信息整合到语言模型中。
使用 Reformer 对 Transformer 的改变,可以在单个加速器上对长度为 64000 的序列进行注意力操作,相比于 MegatronLM 和 TuringNLP 中的 1024 的上下文长度,形成了鲜明的对比。这两个模型都采用了模型并行管道来拷贝大量的参数。
Self-Attention 的回顾
在深入研究 Reformer 体系结构的细节之前,让我们简要回顾一下 self-attention 的形成过程,以获得一些在合并长上下文中所遇到的困难的背景知识。
为了简单起见,我们只讨论与单头的点积注意力,尽管在实践中使用了多头注意力。
如果你想要更深入的回顾一下 self-attention 机制,我强烈推荐 Alexander Rush 的 Annotated Transformer,还有 Jay Alammar 的 Illustrated Transformer。
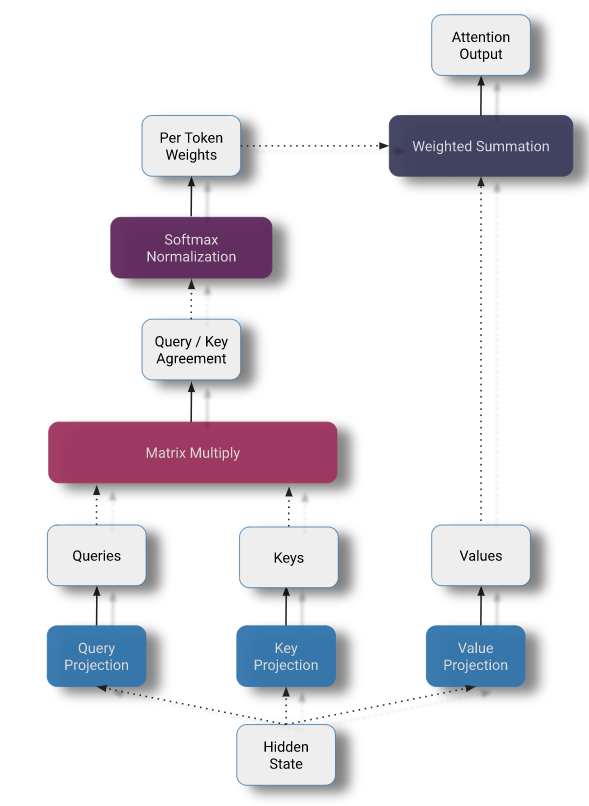
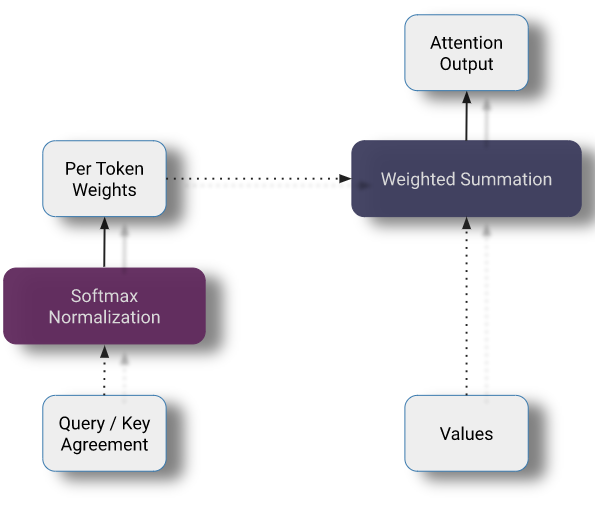
我们可以把 self-attention 分为三个主要部分:
Query - Key - Value 投影
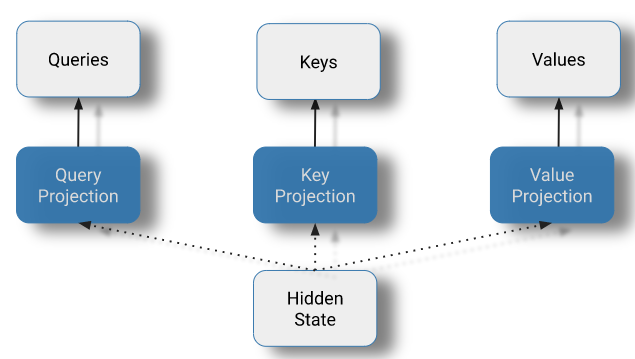
QKV 投影。尽管我们将这个操作画成三个独立的线性投影,但为了提高计算效率,它通常被实现为单个矩阵乘法。
在此阶段,每个 token 的当前隐藏状态通过线性投影分解为三个部分。
queries = np.matmul(query_weights, hidden) + query_bias
keys = np.matmul(key_weights, hidden) + key_bias
values = np.matmul(value_weights, hidden) + value_bias
Query / Key 矩阵乘法
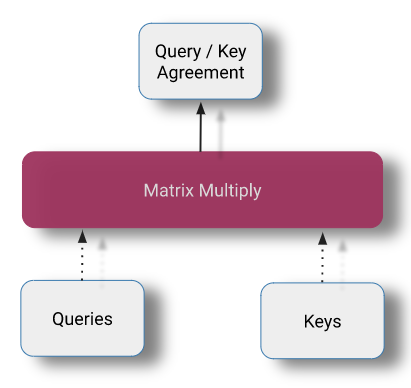
self-attention 操作的核心 —— 一个矩阵乘法计算我们的 keys 和 queries 之间的两两相似度得分。
在投影之后,将 queries 和 keys 相乘以计算两两的相似度。这是用矩阵乘法实现的。
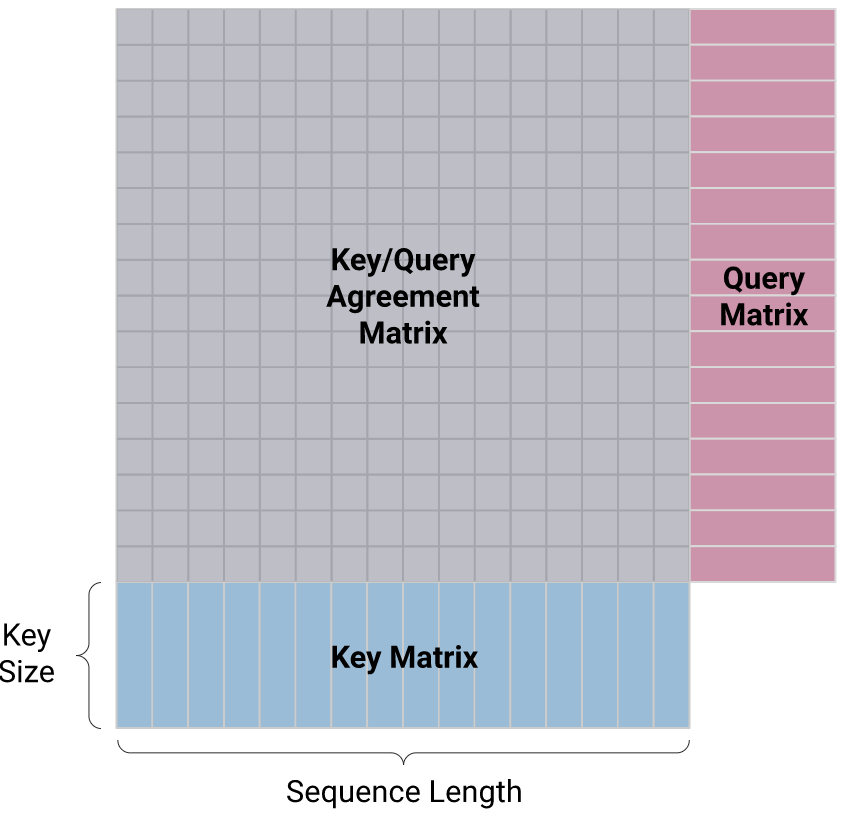
qk_agreement = np.matmul(queries, np.swapaxes(keys, -1, -2))
如果你的 keys 和 queries 是形状为 (batch, sequence_length, hidden_size) 的张量,那么矩阵乘法的输出就是形状为 (batch, sequence_length, sequence_length) 的张量。
这种看似无关紧要的矩阵乘法正是这种 self-attention 操作的计算复杂性问题的根源。对于序列长度的线性增加,计算输出所需的乘法次数以平方方式增加,因为我们需要为输入中每一对可能的 token 计算相似性。这 O(L ²)的复杂性意味着序列的长度超过 1024 的 token 使用原始的 transformer 结构是不切实际的。事实上,BERT 和它的继任者 RoBERTa 中所选择的上下文长度只有 512。
Softmax + Values 的加权和
key / value 协同矩阵中的项除以了一个缩放因子 sqrt(hidden_size),用来消除 hidden size 这个参数对注意力分布的影响。对于每个 query,我们在所有 keys 上计算一个 softmax,以确保矩阵的每一行和为 1—— 确保新的隐藏状态的大小不依赖于序列长度。最后,我们用我们的注意力矩阵乘以我们的 values 矩阵,为每个 token 生成一个新的隐藏表示。
attention_weights = softmax(qk_agreement / qk_agreement.shape[-1])
attention_outputs = np.matmul(attention_weights, values)
计算复杂度 — 解决方案
如前所述,虽然点积注意力方式非常好用,允许任意的 token 在我们的上下文中从任何其他的 token 中聚合信息,这种灵活性是有代价的,一个不幸的 O (L ²)计算复杂度。
有几篇论文提出了帮助解决这种计算复杂性的 transformer 的变体。“Generating Long Sequences With Sparse Transformers”建议使用成对的注意力操作和精心选择的注意力模式来分解注意操作。“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context"引入了一种循环机制,允许整合来自比自注意力操作的上下文更大的距离的信息。
The Reformer
“Reformer: The Efficient Transformer"的作者采用了一种完全不同的方法来处理序列长度问题。首先,他们观察到学习不同的 keys 和 queries 的投影并不是严格必要的。他们丢弃了 query 投影,并将注意力权重替换为 key 的函数。
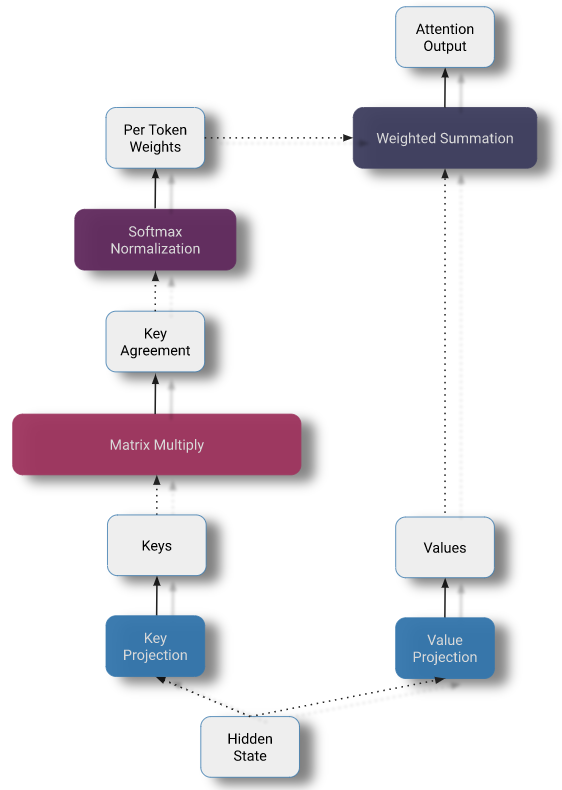
共享的 QK-Attention
有点令人惊讶的是,尽管他们从注意力模块中移除了一些参数,他们的模型在 enwiki8 上的性能并没有下降。
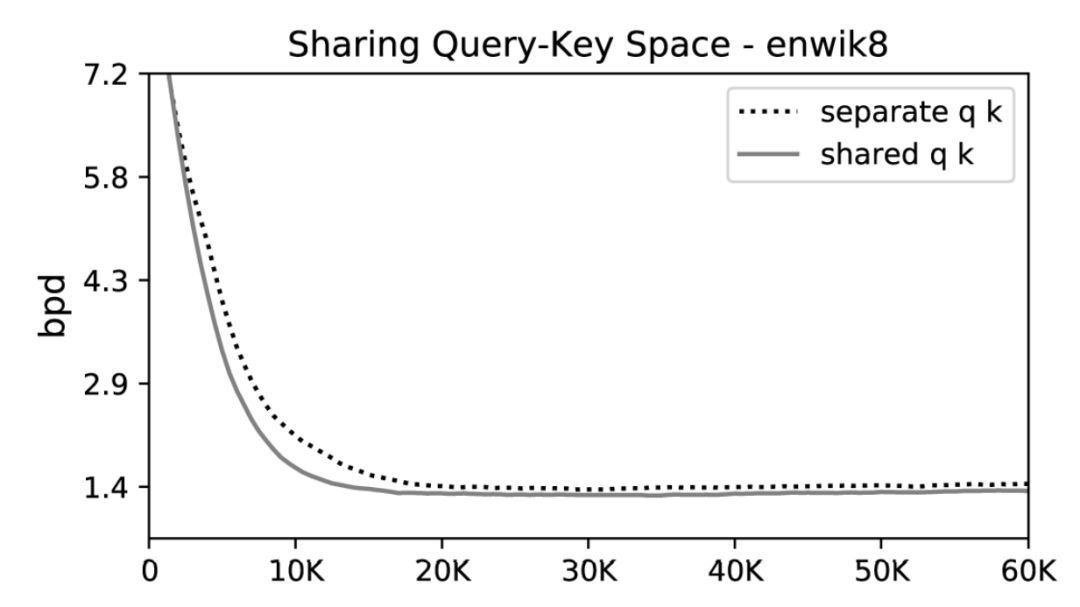
在 enwiki8 上把 key 和 query 的投影放到一起做可以获得相同的性能。
现在,注意力块不再包含 queries 的单独投影,我们只有 key 和 value 对。然而,计算 key 的协同矩阵(通过将每个 key 与其他 key 进行比较)仍然是非常昂贵的。
不幸的是我们可能并没有利用好所有的这些计算。softmax 的输出通常由几个关键元素控制 — 其余的往往在噪声中消失。我们在计算 softmax 的时候,并不一定需要那些注意力权重很小的 token。
在编写传统软件时,我们总是会遇到这个问题。如果我们想找到与给定 key 对应的 value,我们通常不会遍历所有 key 的列表并检查每个 key 是否匹配。相反,我们使用散列映射数据结构来执行 O(1)的查找,而不是 O(n)比较。
方便的是,向量空间的哈希映射确实存在类似的情况,它被称为“局部敏感哈希”(LSH)。正是基于这种方法,Reformer 的论文的作者们希望产生一个 transformer 的替代方案,以避免使用点积注意力的平方复杂性。
局部敏感哈希 (LSH)
局部敏感哈希是一组将高维向量映射到一组离散值(桶/集群)的方法。它最常用来作为近似最近邻搜索的一种方法,用于近似的重复检测或视觉搜索等应用。
局部敏感哈希方法尝试将高维空间中相近的向量以高概率分配到相同的哈希。有效的哈希函数有很多种,最简单的可能是随机投影。
lsh_proj = np.random.randn(hidden_size, hash_size)
hash_value = np.sign(np.dot(x, lsh_proj.T))
换句话说,我们选择一个随机的向量集合,观察输入向量在每个向量上的投影是正的还是负的,然后使用这个二值向量来表示给定向量的预期存储区。下图说明了 LSH 投影矩阵“u”中单个向量的处理过程。绿色的正号表示与向量 u 点积为正的点,而红色的负号表示与向量 u 点积为负的点。
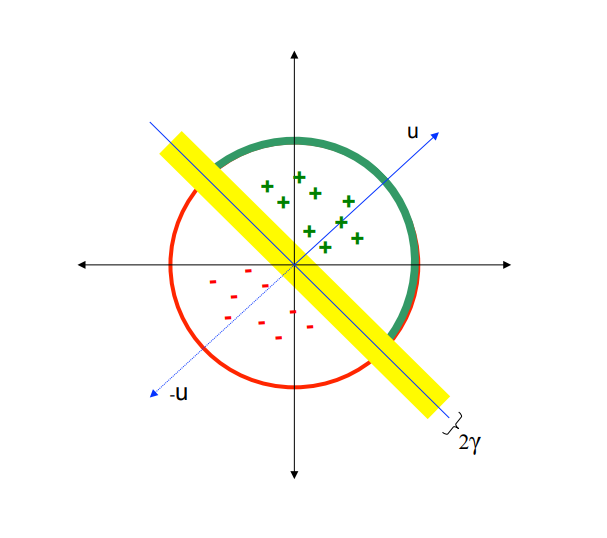
LSH 注意力
Reformer 的论文选择了局部敏感哈希的 angular 变体。它们首先约束每个输入向量的 L2 范数(即将向量投影到一个单位球面上),然后应用一系列的旋转,最后找到每个旋转向量所属的切片。
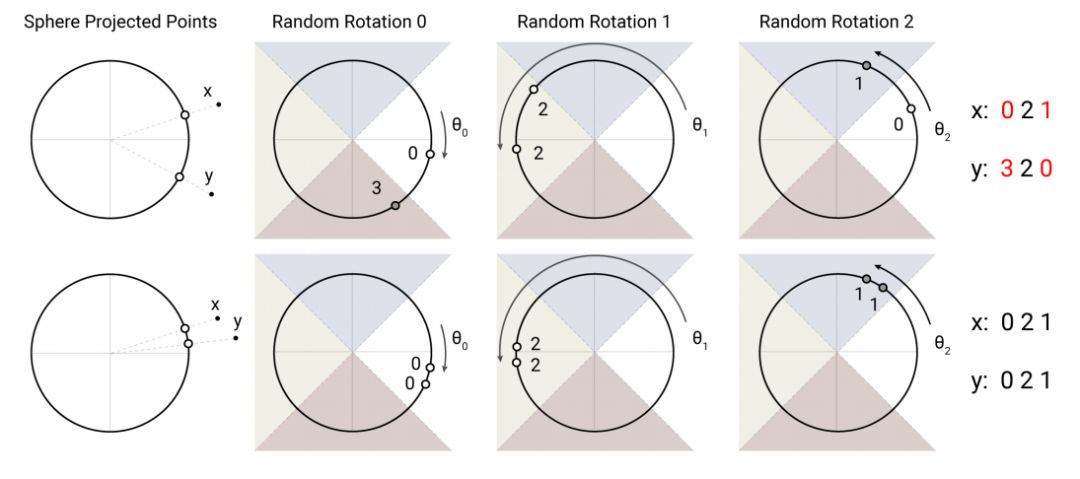
该图演示了一个用 4 个桶进行 3 轮哈希的设置。下面的图中的向量映射到了同一个 bucket,因为它们的输入很接近,而上一张图中的向量映射到第一个和最后一个 bucket。
找到给定的向量选择之后属于哪个桶也可以看成是找到和输入最一致的向量 —— 下面是 Reformer 的代码:
# simplified to only compute a singular hash
random_rotations = np.random.randn(hidden_dim, n_buckets // 2)
rotated_vectors = np.dot(x, random_rotations)
rotated_vectors = np.hstack([rotated_vectors, -rotated_vectors])
buckets = np.argmax(rotated_vectors, axis=-1)
在为每个 token 计算一个桶之后,将根据它们的桶对这些 token 进行排序,并将标准的点积注意力应用到桶中的 token 的块上。
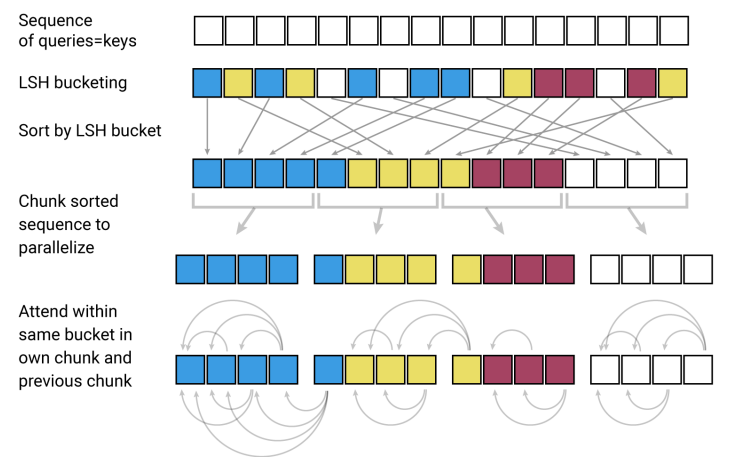
有了足够多的桶,这就大大减少了所有的给定的 token 需要处理的 token 的数量 —— 在实验中,Reformer 的论文运行的模型被配置为使用 128 块大小的块。因此,LSH 操作将昂贵的 key 协同矩阵乘法的上下文大小限制为更易于管理的值。
我们现在的时间复杂度为 O (L*log(L)) ,而不是时间复杂度成正比 O (L ²), 这允许我们把注意力操作扩展到更长的序列的时候不会由于运行时间而受到影响。
因为这个分桶过程是随机的,所以 Reformer 有选择地多次运行这个过程,以减少两个在输入空间很近的向量被随机地放在不同的桶中的可能性。当所有的事情都做了之后,你就有了一个完全替代标准的多头注意力的方法,它可以与计算完整的注意力矩阵相媲美。
内存复杂度
不幸的是,实现更好的时间复杂度只是问题的一半。如果我们将新的 LSH 注意力块替换为标准的多头注意力,并尝试输入新长度的信息,我们将很快认识到系统中的下一个瓶颈 — 内存复杂性。
即使我们已经非常小心地最小化了注意力操作的计算复杂度,我们仍然必须将所有的 key 和 value 存储在内存中,更糟糕的是,在训练期间,我们需要缓存激活以计算参数更新。
Reformer 论文使用了序列长度为 64k 的 enwiki8 语言建模数据集来做实验,隐藏单元的大小为 1024,层数为 12 层,这意味着存储 key 和 value 需要 2 * 64000 * 1024 * 12 = ~ 1.5B 个浮点数,大约是 6GB 的内存。使用这种内存使用方式,我们将无法在训练期间使用大的批处理大小,从而影响我们的运行时间。
一个选择是实现 gradient checkpoint 来帮助限制我们的内存使用。允许我们减少内存使用,只存储从正向传递中的关键的激活,剩余的在反向传递中重新计算。因此,我们可以选择只在 key 和 value 投影之前存储隐藏状态,而不是存储 key 和 value,然后第二次重新投影隐藏状态来计算梯度。
不幸的是,这使我们的后向传递的成本增加了一倍,因此我们能够支持更大的批处理大小所获得的好处将通过重新计算得到部分缓解。更重要的是,即使我们选择只存储输入的一小部分,存储单个层的激活需要 250MB 的空间,这意味着我们很难在 12GB 的 GPU 上支持超过 12 个样本的批处理大小。
Re vN ets
幸运的是,我们还有其他方法来减少内存使用。RevNet。
RevNets 有个非常聪明的计算技巧,通过以一种特定的方式构造每一层,使内存使用与网络深度保持一致。每一层分为两个部分,X ₁和 X ₂,前
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%AF%B9%E7%9A%84%E6%B7%B1%E5%85%A5%E8%A7%A3%E8%AF%BB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


