微信看一看推荐排序技术揭秘
本文转载自:微信AI,作者 xiafengxia
在微信 AI 背后,技术究竟如何让一切发生?微信 AI 公众号推出技术专题系列“微信看一看背后的技术架构详解”,干货满满,敬请关注。以下为专题的第一篇《微信看一看推荐排序》。
一、背景
微信公众平台作为目前用户量最大的互联网原创内容平台之一,每日新发表的文章可达几百万篇。用户可以通过关注公众号、朋友圈、聊天转发等渠道阅读文章。除了前述几种方式以外,用户很难再有其他方式发现更多有趣的文章。因此,看一看个性化推荐应运而生。我们利用用户在微信内的阅读、关注、分享等信息,结合目前最新的深度学习算法,为用户推荐最符合兴趣的文章。除了文章以外,我们也接入了腾讯视频、企鹅号、竖屏小视频等内容,大大丰富了推荐的内容多样性。
二、看一看整体架构
看一看的整体架构如图所示:
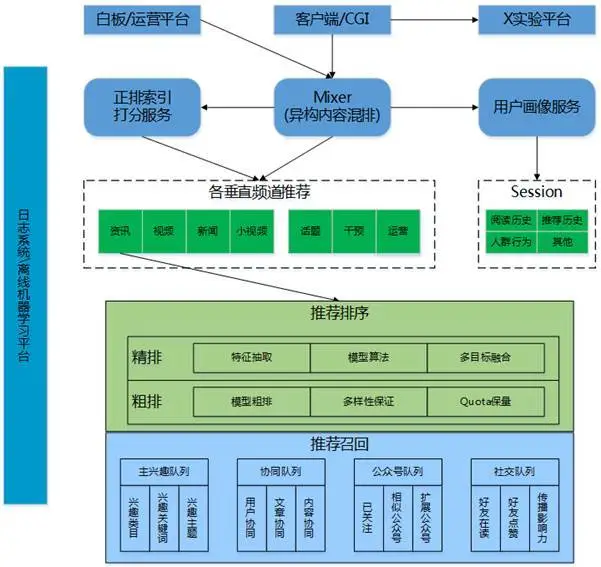
和大多数的推荐系统一样,我们最底层采用了经典的召回、粗排、精排三层结构,各阶段处理的候选集数量逐层递减,主要考虑是需要在实时性能和效果之间做 tradeoff。比较特别的一点是,我们在精排之后接了一层异构内容混排,主要是考虑到不同内容源的点击率、优化目标不尽相同,难以放在一起比较。目前,混排侧引入了强化学习模型,优化长期收益,实现快速实时反馈。
三、基础数据和召回
数据是推荐系统的天花板所在。简单来讲,推荐系统就是根据用户的行为,在千万级别的候选集中挑选最适合用户的 topN 条结果。对数据判断得越准确,越细致,数据的表达能力越强,推荐也越精准。整体上看,数据可以分为用户数据和内容数据。
通过基础数据,我们可以从多个纬度去判断用户需求,包括用户的一级类目兴趣,二级类目兴趣,兴趣关键词,topic 分布等。同时,在 embedding everything 的号召下,我们通过深度网络,对画像做了多种层面的 embedding。
内容数据泛指所有文档相关的数据。从业务层面看,内容数据分为图文、视频、新闻、小视频、人工干预等几个大类,每种业务都是一个独立的池子,有单独的数据清洗、质量评估流程,前期甚至有独立的分类体系。从来源看,内容数据分为公众平台文章、企鹅号号文章、外部链接文章、短视频、小视频。从时间上看,内容数据分为实时数据、15 天全量数据、历史优质数据。
每个文档都有丰富的基础属性,包括一级分类、二级分类、tag、实体词、topic、曝光数、点击数、质量分、色情分、垃圾分。我们还创新的提出了 people rank 算法,通过每个人的社交影响力,将每个人的社交影响力反馈到文章上,形成文章的权威分、精英分等,能较好的提炼出高质文章。
召回主要负责从百万级的海量候选集中选出万级别的候选集给到粗排。召回主要分为兴趣画像、协同、公众号、社交等几个大类召回。兴趣画像召回主要有一级/二级类目、topic、地域、关键词等召回;协同召回包括 Item 协同、内容协同、用户协同等召回;公众号召回包括关注公众号、扩展公众号召回。为了增加多样性,在以上召回之外还有一些试探、冷启动召回,对用户兴趣进行探索。
四、排序
排序主要分为精排和粗排 2 个阶段,二者主要的区别在于候选集的量级不一样,粗排输入候选集在 1 万级别,精排只有 1 千级别。候选集的数量差异决定了粗排在性能上要求会更高,因此在特征上只能选取粗粒度、区分度较高的少量特征,而模型侧也只能选择线性模型,或者复杂度较低的深度模型。粗排其他部分的工作和精排比较类似,这里着重介绍精排。
精排阶段需要对粗排候选池中的 ItemList 进行打分,这个分数是针对每个用户对候选文章点击概率的预测,即 Ctr 预估。看一看业务中每天有海量活跃用户,这些海量日志可以用来进行模型训练以建模喜好。
LR/FM 大规模的 Ctr 预估系统中,Logistic Regression 因简单、易扩展、可解释的特性成为初期阶段使用最为广泛的一种模型。其 Ctr 预估模型公式为:
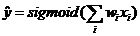
我们第一阶段的模型采用大规模分布式的 LR,使用自研的分布式训练平台 PanguX,通过人工特征工程提取十亿级的特征用于离线训练。但 LR 属于 Memorization 比较强的 model,主要记忆每个特征的历史点击率,在 Generalization 上有很大的缺陷,需要大量的人工特征工程来提高泛化能力。另外,这种线性模型特征与特征之间在模型中是独立的,无法学到在训练集中未出现过的交叉信息。因此第二阶段我们切换到了 FM(Factorization Machines),该模型可以在很少特征工程的情况下通过学习特征的 embedding 表示来学习训练集中从未见过的组合特征,FM 的模型公式如下:
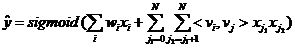
虽然理论上讲 FM 可以对高阶特征进行组合建模,但是我们一般在使用中受计算复杂度和参数维度的限制都是只用到了二阶特征。很自然的,对于更高阶的特征组合可以用多层神经网络去解决。
wide&deep
2016 年 Google 提出的 wide&deep 模型拉开了深度学习在 ctr 预估领域大规模应用的序幕,该模型包括两部分:线性模型
- DNN 部分,wide 部分通过 Cross-product transformation 在 Memorization 上增加低阶非线性,deep 部分聚焦 Generalization,对特征的 dense embedding 进行组合,学习更深层的隐藏特征。在我们的实际应用中, wide 部分增加 cross-product transformation 的组合特征,deep 部分主要由 embedding 化的离散特征及连续特征组成,对离散特征学习了一个低纬度的 embedding 向量(dense representation),Embedding vectors 随机初始化后根据最终的 loss 来反向训练更新。我们把同一个 field 内 embedding 向量进行 sum pooling,不同 field 得到的向量 concat 在一起作为第一个隐藏层的输入。wide&deep 作为我们进入深度学习领域的第一个模型在看一看精排场景中取得了很大的收益。
DeepFM
wide&deep 模型全量之后相比 FM 这种浅层模型点击率提升明显,但 wide 部分仍需要大量的人工特征工程来引入低阶组合信息。我们参考 DeepFM 在网络结构上引入因子分解机部分,通过 FM 的特征交叉学习浅层组合,dnn 部分挖掘特征间的深层非线性关联。标准的 DeepFM 网络结构如下:
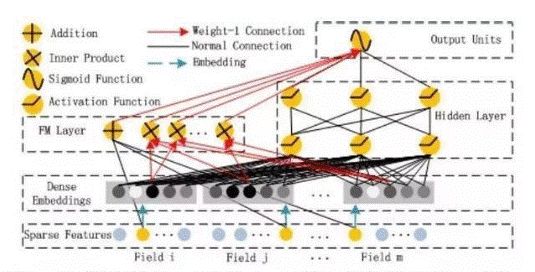
我们在引入 FM Layer 时,不同 field 间的交叉不再使用点积操作,而是通过哈达马积得到一个向量,用于上层的多模块融合。同时,引入 field-wise 的 Wide Layer 以防止共享 embedding 的训练有偏。对于 Show/Clk/Ctr 等统计特征,我们放弃了离线单独统计载入字典的模式,直接在 PanguX 训练平台框架层面引入该类型统计信息,server 针对每个特征保存一份实时的全局 show clk 信息,并且该数据随着训练的进行持续累计和随时间衰减。最后的模型框架结构如下:
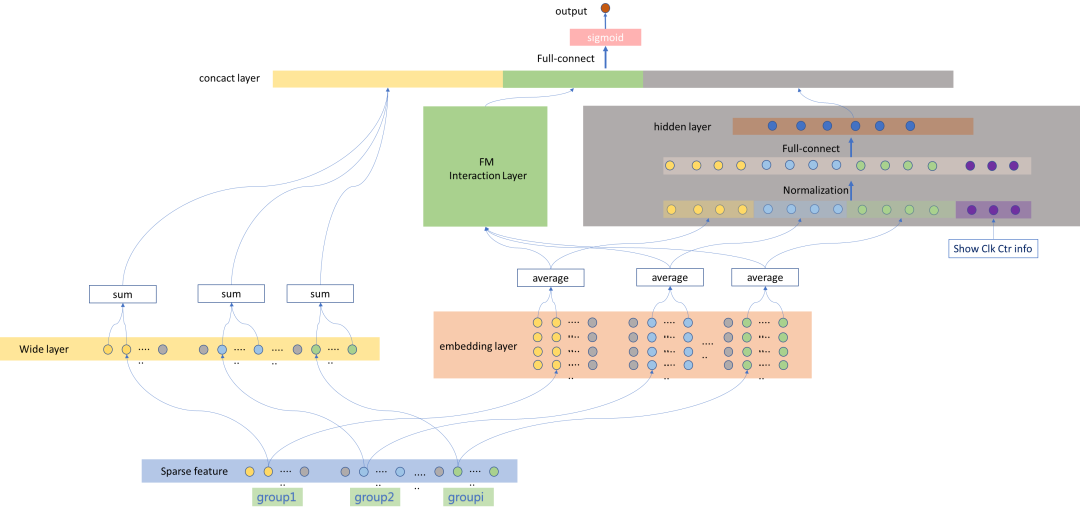 目前该优化过的 DeepFM 已经全量应用于看一看精排业务中,取得了非常不错的效果。
目前该优化过的 DeepFM 已经全量应用于看一看精排业务中,取得了非常不错的效果。
五、多目标
除了前述 ctr 预估,在微信看一看的排序中,我们非常重视多目标的推荐效果优化。这里多目标是指包括了点击目标之外的时长、分享、点赞、评论等其他跟用户体验息息相关的推荐指标。单纯以 pctr 为目标,会带来标题党问题。站在平台的角度,我们不仅希望在打造一款大众化的阅读产品,同时希望提升产品的社交属性,因此用户阅读外的其他互动行为,也是用户体验的重要衡量准则。站在内容的角度,被用户点赞、分享、评论的内容以及停留时长长的内容,往往质量比较高,因此引入这些目标有利于推荐过程中避免标题党等低质量内容的展现。站在用户的角度,从阅读、分享、点赞、评论等多个角度提升用户综合体验,有利于增加产品对用户的使用黏性。在创作者角度,作者会希望在多元的指标上看到自己微信平台上的内容作品的反馈效果的提升。
多目标问题业界常见的有方法有两种:
1.多任务联合建模:
阿里妈妈在广告的点击率-转化率预估任务中,提出了对点击率、转化率进行联合建模,并将转化率分解为点击率乘以点击后的转化率,从而对两个任务在目标输出层进行关联。优点是多个任务之间可以互相利用信息,点击数据弥补了转化数据过度稀疏造成的预估不稳定问题,不足之处是模型强依赖于点击-转化目标在业务递进关系,不能直接扩展到其他复杂场景。
2.各任务独立建模:
业界一些信息流推荐产品,对点击、时长、点赞和评论等目标采用独立训练模型,线上进行组合的 model combination 方案。优点是各任务完全解耦,加快了模型的迭代速度,也利于对具体任务的特征独立优化,不足之处是各任务之间无法互借信息。
3.其他方法:
一些通过修改样本权重体现多目标重要性的方法,以及一些通过增加正则项在损失函数中体现多目标价值的方法,因为在迭代的灵活性和模型效果上均不具有优势,此处不再详述。
看一看的推荐场景和其他推荐产品有相似之处,也有自己独特的一面。例如,点击目标和阅读时长、分享、乃至关注公众号等目标构成业务场景上的递进关系,这一点是共通的;但在“好看”上线以后,用户的点赞和评论行为则不必须依赖于点击也可以发生,这些目标和点击目标既有递进关系,也有平行的关系。
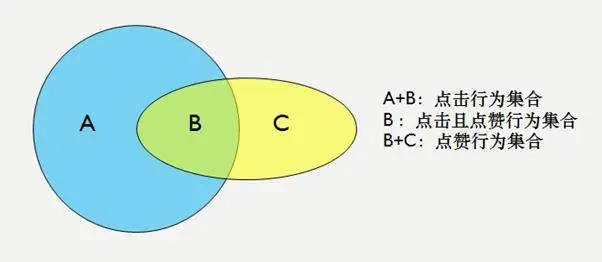
此外,用户在阅读中的社交互动行为数据也是微信看一看的特色,共同阅读一篇文章、观看一个视频的好友上下文信息,对用户行为的引导起到了很大的作用。
看一看中多目标优化方法:
1.多目标模型的网络结构:
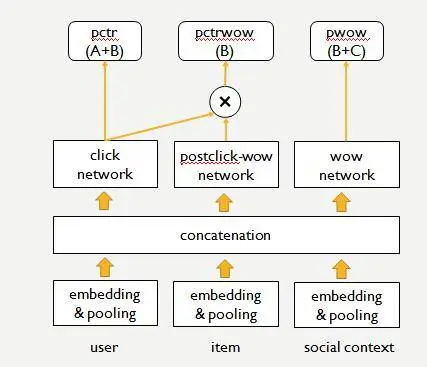
整体的多目标建模方法论层面,我们也采用了多任务联合建模的方案,各个任务共享底层特征 embedding 表示,独享各自的神经网络和目标输出。
在对多目标之间的联结方式上,我们在对点击目标和点击后的递进行为进行全空间建模之外,增加了对非依赖点击行为目标的独立输出。以“好看”业务为例,即对图中的点击(A+B),点击并点赞(B),点赞(B+C)做三路输出。这样做的好处是既能受益于点击目标和递进的 postclick 目标互相借用信息,又能通过独立网络将非依赖点击的行为目标完整的考虑进来。
在底层特征表示方面,我们将特征种类划分为三部分进行研究,包括用户属性和兴趣特征,内容属性特征,和社交关系上下文特征,我们目前是通过模型自动学习不同目标的预估任务下应该如何配置特征之间的交互关系的,这一部分的扩展性是可以很强的,比如可以加入人工的先验知识,或者定制化的网络结构进行特征组选择。
2.多目标在线融合方式:
多目标预估值的在线融合方式非常重要,是决定看一看产品的综合用户体验的最后一环,我们通过离线、在线两部实验获得最终的权重融合参数。在离线阶段,我们通过 grid search 设置多组融合权重方案,观察每种融合参数对各目标的离线排序 AUC 得分,选择 AUC trade off 比较平衡的一些权重组合作为候选集,上线进行 ABTEST。在线阶段,通过观察各个实验的留存率、产品使用时长、用户行为互动率、以及内容分发量和多样性等,选择和产品价值导向最一致的权重组合作为最终的融合方案。
六、重排与多样性
重排主要负责多路异构推荐结果混合排序,最终决定推荐给用户的 10 条结果。除了负责策略混排,重排还负责整体的多样性控制、规则重排、人工干预等。重排这里是业务的最终出口,我们的最终目标是提升分发量,即 pv+vv。
重排有几个难点:
- 数据是异构的,包含多种业务,不同业务数据包含不同的特征,并且点击率差异也很大;
- 不同内容的优化目标不尽相同,很难做统一的内容排序;
- 不同内容的点击率不同,比如视频点击率超过 20%,会挤压低点击率的业务。
我们尝试了通过 pctr 来统一排序:
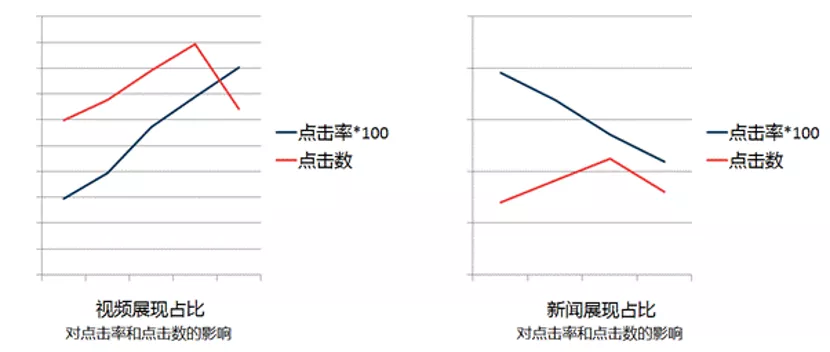 看一看中,视频点击率最高,新闻最低。当我们提高视频的展现占比,整体点击数并不是持续升高,而是会有一个拐点。同样,不断降低新闻的占比,点击数也会迎来拐点。因此,提高高点击率业务,降低低点击率业务,整体的内容点击率会提高,但不会提高整体的点击数。
看一看中,视频点击率最高,新闻最低。当我们提高视频的展现占比,整体点击数并不是持续升高,而是会有一个拐点。同样,不断降低新闻的占比,点击数也会迎来拐点。因此,提高高点击率业务,降低低点击率业务,整体的内容点击率会提高,但不会提高整体的点击数。
基于上面的考虑,我们选择使用强化学习来进行多业务混排。用户在推荐场景浏览可以建模成 ov Progress,Agent 是我们的推荐系统,Action 是我们推荐了什么内容,Reward 是用户的反馈信息,包括点击、负反馈、退出等,每次我们的推荐系统 Agent 采取某个 Action,给用户推荐了内容,用户给到我们相应的反馈,通过最优化总点击数来获得最佳效果。
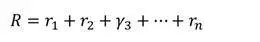
未来有不确定因素,所以要对未来的收益做衰减:
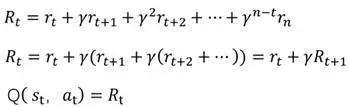 DQN
DQN
梯度下降求解 MSE 的 LOSS:
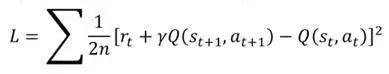
初版 DQN 上线后,对比 baseline 规则,总点击数有大幅提高。为了利用 Session 内短期信息,我们将 DQN 内的 state 用 RNN 的 hidden 来描述,结构如下:
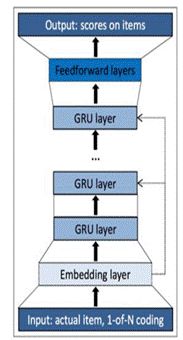
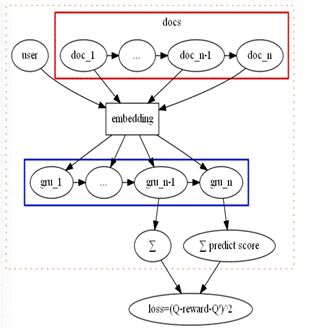
采用 RNN 结构的强化学习模型上线后效果得到了进一步提升。基于 RL 混排,我们在 reward 的设计上也进行了多轮迭代,如加入时长、负反馈、多样性。下面重点介绍一下多样性。
多样性在推荐系统中是一个重要的优化目标,但是相比于 ctr 等指标,学术界、工业界都并没有一个明确指标来指导多样性优化。为了更好的理解、分析和优化多样性策略,我们设计了 10+中多样性相关指标,如展示/点击类目数、展示类目熵,用户主兴趣覆盖率,符合用户主兴趣文章比例等。
第一版的多样性策略采用启发式的方法,限制相同类目/Topic/Tag 等个数上限,结合离线平台/abtest 数据调整参数。这里最大的问题是个性化策略是全局的,没有个性化。

通过 Submodular 的边际效应递减特性,对重复度高的类目、关键词进行打压,同时引入 pctr,体现了一定的个性化,上线取得了不错的效果,在损失较少的 ctr 的情况下大幅提
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BE%AE%E4%BF%A1%E7%9C%8B%E4%B8%80%E7%9C%8B%E6%8E%A8%E8%8D%90%E6%8E%92%E5%BA%8F%E6%8A%80%E6%9C%AF%E6%8F%AD%E7%A7%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


